Elasticsearch文档操作:初学者指南(2023年最新版包含DSL语句的使用和RestHighLevelClient在Java中的使用)
2023年还没有学习Elasticsearch?,那么您将错过最强大、最通用的编程语言之一。
本文将介绍在Elasticsearch对文档分别使用DSL语句和Java High Level REST ClientAPI来对文档进行操作。获取更多信息查看官网帮助文档

运行环境:
Linux,docker
简介
Elasticsearch是一个分布式的RESTful搜索和分析引擎。它是建立在Lucene之上的,Lucene是一个强大的全文搜索引擎。Elasticsearch被设计为可伸缩、容错和易于使用。它被各种各样的组织使用,包括eBay、思Cisco和Spotify。
1.安装和启动elasticsearch和所需组件kibana
在docker中安装和配置Elasticsearch和Kibana版本控制在7.12.1,
相关配置的操作文档参考我另外一篇如何使用Elasticsearch构建强大的搜索和分析应用程序(2023年最新ES新手教程)目录1.2.1
1.1.docker中运行成功
![]()
1.2.访问Linux的IP地址对应Kibana的端口号5601
访问网页“Linux的IP地址:5601/app/dev_tools#/console,kibana提供的可以控制ES的控制台
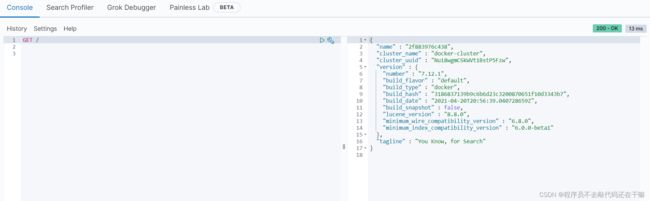
GET /
GET测试运行的到的信息和访问端口9200得到结果相同,则之前的配置文件生效,运行成功。
2.快速入门DSL语句和REST API的编写
在此之前也可以参考如何使用Elasticsearch构建强大的搜索和分析应用程序(2023年最新ES新手教程) 目录1.1.3 ,了解什么是索引?,什么是文档。
2.1.创建索引
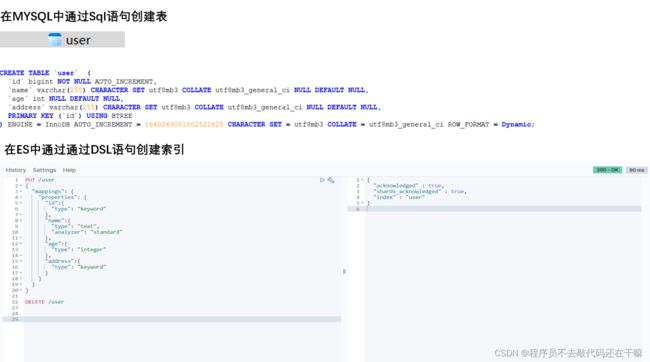
PUT /user
{
"mappings": {
"properties": {
"id":{
"type": "keyword"
},
"name":{
"type": "text",
"analyzer": "standard"
},
"age":{
"type": "integer"
},
"address":{
"type": "keyword"
}
}
}
}
得到以下结果
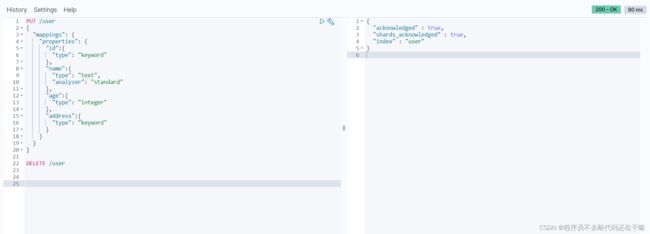
以数据库为例,一个表有数据结构,和字段。Elasticsearch同样也有索引和文档,下表方便理解ES的索引结构,当然本身这两个技术并没有什么关系,这里只是用Mysql做例子方便理解。
| MySql | Elasticsearch | 说明 |
|---|---|---|
| Table(table structure) | Index | 索引,就是文档的集合,类似数据库的表 |
| Row | Document | 文档,就是一条条的数据,类似数据库中的行(Row),文档都是JSON格式 |
| Column | Field(字段) | 字段,就是JSON文档中的字段,类似数据库的列 |
| Schema | Mapping | Mapping是索引中文档的约束,列如字段类型约束。类似数据库的表结构 |
| SQL | DSL | DSL是elasticsearch提供的JSON风格的请求语句,用来操作elasticsearch,实现CRUD |
2.2.DSL语句实现CRUD
DSL是elasticsearch提供的JSON风格的请求语句,用来操作elasticsearch,实现CRUD,DSL代表领域特定语言。在Elasticsearch上下文中,DSL指的是一组工具和技术,这些工具和技术可以用一种更简洁、更富有表现力的方式与Elasticsearch交互。
2.2.1.DSL_新增文档
给指定的数据流或索引添加JSON文档使其可搜索,如果索引和文档已经存在,则会更新文档。
| 请求方式 | 用法 |
|---|---|
| POST | 创建文档 |
| PUT | 重写和创建文档 |
POST /user/_doc/1
{
"id":1,
"name":"王五",
"age":19,
"address":"北京市海淀区颐和园路5号"
}
或者
PUT /user/_doc/1
{
"id":1,
"name":"王五",
"age":19,
"address":"北京市海淀区颐和园路5号"
}
结果图
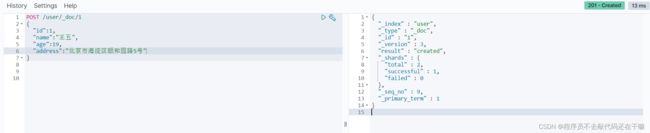
PUT效果相同
2.2.1.DSL_新增文档扩展
| 请求参数 | 在POST中的用法 | 在PUT中的用法 |
|---|---|---|
| _doc | 在添加一个索引(Index)不存在的文档时,ES会自动创建索引并且当请求方式为POST的时候文档允许省略ID,ES自动生成ID的同时生成索引。2.2.1.演示1 | 在添加一个索引(Index)不存在的文档时,ES会自动创建索引并且当请求方式为PUT创建文档须指定ID,ES才会自动生成索引 |
| _create | 在添加一个索引(Index)不存在的文档(Document)时,ES也会自动创建索引,但是两种都不允许省略ID。2.2.1.演示2 |
POST+_doc的请求格式,无ID的情况下,可以看到创建ES自动生成一个很复杂的ID并且索引自动创建
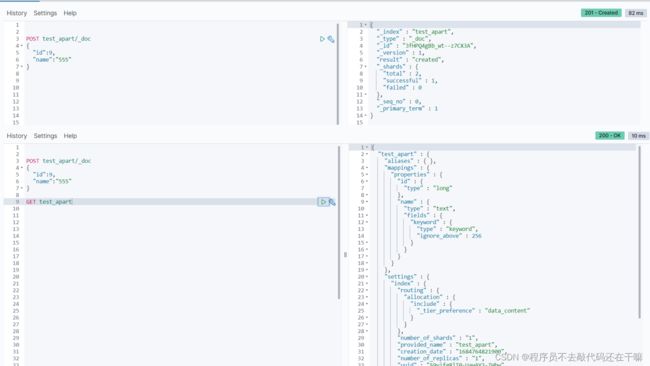
加上ID之后响应的ID为自定义的ID,索引也是自动创建
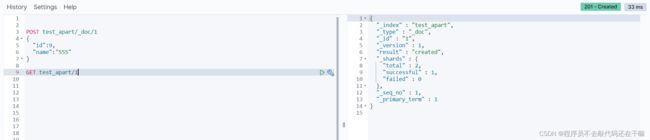
PUT+_doc的请求格式,无ID的情况下,

测试结果报错
当PUT携带ID的时候,添加成功并且自动创建对应的索引结构
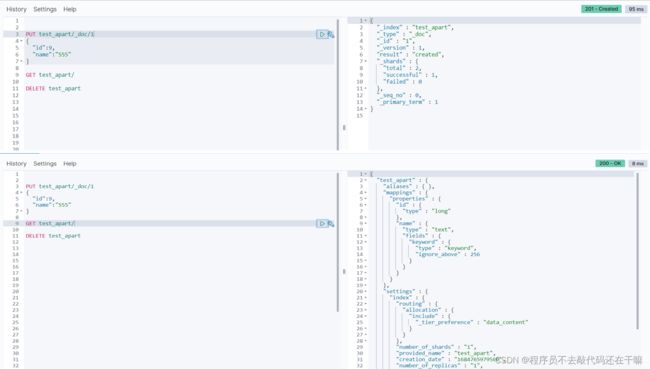
警告:索引名不能有大写字母

非法索引名[testApart],必须小写,ES支持下划线的写法test_apart
**警告:**在默认情况下新建使用POST ,并且需要指定id,并且创建文档必须建立在已经创建了索引的基础上,ES自动生成不能保证索引结构能达到预期的结果。
2.2.2.DSL_删除文档
使用DELETE从索引中删除文档。必须指定索引名称和文档ID。
DELETE /索引名/_doc/id
2.2.3.DSL_更新文档
使用指定的脚本更新文档,修改有两种方法
-
局部修改
更新文档(优先用于更新)
POST /索引名/_update/文档id { "doc":{ "字段名":"新的值" } } -
全局修改
删除旧文档,添加新文档
PUT /索引名/_doc/id { "字段1":xxx, "字段2":xxx, }
2.2.4.DSL_查看文档
-
GET API
从索引中检索指定的JSON文档。
-
请求类型
GET/_doc/<_id> GET /_source/<_id> HEAD /_doc/<_id> HEAD /_source/<_id> -
描述
使用GET从特定索引中检索文档和文档源或存储字段。使用HEAD验证文档是否存在。也可以使用_source资源只检索文档源或验证是否存在。
-
测试
-
GET

-
HEAD
HEAD查到数据左图,查无数据右图
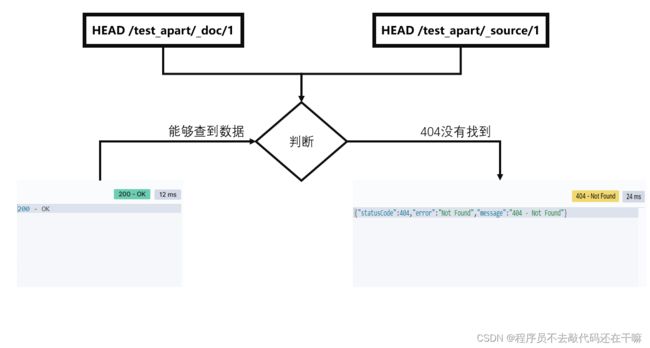
-
2.3.RestAPI中JAVA语言实现CRUD
Java高级REST客户端工作在Java低级REST客户端之上。它的主要目标是公开特定于API的方法,这些方法接受请求对象作为参数并返回响应对象,这样请求编组和响应反编组就由客户机自己处理了。
2.3.1.配置maven依赖
org.elasticsearch.client
elasticsearch-rest-high-level-client
设定与docker中启动的ES版本一致,以7.12.1版本为例
1.8
7.12.1
2.3.2.建立与ES的连接
-
在SpringBoot启动类中编写一个方法通过@Bean注入SpringFactory,推荐
@Bean public RestHighLevelClient client(){ //IP服务器的地址 9200是elasticsearch的端口 return new RestHighLevelClient(RestClient.builder(HttpHost.create("192.168.26.131:9200"))); }需要时自动注入
@Autowired private RestHighLevelClient client; -
在类中编写一个方法。
private RestHighLevelClient client; public void setUp(){ client=new RestHighLevelClient(RestClient.builder(HttpHost.create("192.168.26.131:9200"))); }
2.3.3.RestAPI_新增文档
新增总的来说有两种生成方式,一种是由字符串提供的文档源,另外是由Map提供的文档源
-
由字符串(String)提供的文档源的新增
package com.cn; import org.apache.http.HttpHost; import org.elasticsearch.action.index.IndexRequest; import org.elasticsearch.client.RequestOptions; import org.elasticsearch.client.RestClient; import org.elasticsearch.client.RestHighLevelClient; import org.elasticsearch.common.xcontent.XContentType; import org.junit.jupiter.api.AfterEach; import org.junit.jupiter.api.BeforeEach; import org.junit.jupiter.api.Test; import org.springframework.boot.test.context.SpringBootTest; import java.io.IOException; import java.util.HashMap; import java.util.Map; @SpringBootTest class TestForRestApiApplicationTests { private RestHighLevelClient client; @BeforeEach void startUp(){ client=new RestHighLevelClient(RestClient.builder(HttpHost.create("192.168.26.131:9200"))); } @AfterEach void tearDown() throws IOException { client.close(); } @Test void contextLoads() { System.out.println(client); } @Test void add1() throws IOException { IndexRequest request=new IndexRequest("user").id("1"); String jsonString="" + "{\n" + " \"id\":1,\n" + " \"name\":\"张三\",\n" + " \"age\":18,\n" + " \"address\":\"北京市朝阳区\"\n" + "}"; request.source(jsonString,XContentType.JSON); client.index(request,RequestOptions.DEFAULT); } }下图剖析执行流程与DSL语句的对应关系

-
由Map提供的文档源的新增,在官方文档中说明了Map可以自动转换为JSON格式
package com.cn; import org.apache.http.HttpHost; import org.elasticsearch.action.index.IndexRequest; import org.elasticsearch.client.RequestOptions; import org.elasticsearch.client.RestClient; import org.elasticsearch.client.RestHighLevelClient; import org.junit.jupiter.api.AfterEach; import org.junit.jupiter.api.BeforeEach; import org.junit.jupiter.api.Test; import org.springframework.boot.test.context.SpringBootTest; import java.io.IOException; import java.util.HashMap; import java.util.Map; @SpringBootTest class TestForRestApiApplicationTests { private RestHighLevelClient client; @BeforeEach void startUp(){ client=new RestHighLevelClient(RestClient.builder(HttpHost.create("192.168.26.131:9200"))); } @AfterEach void tearDown() throws IOException { client.close(); } @Test void contextLoads() { System.out.println(client); } @Test void add2() throws IOException { Map剖析关系图

总结:在开发中一般会定义一个与ES索引结构相同的实体类(User.java),封装所需参数,返回值类型为User.java
2.3.4.RestAPI_删除文档
删除比较简单
@Test
void delete() throws IOException {
//准备DeleteRequest方法,指定索引名,和文档ID
DeleteRequest request=new DeleteRequest("user").id("1");
//发送删除请求
client.delete(request,RequestOptions.DEFAULT);
}
2.3.5.RestAPI_更新文档
-
使用部分文档更新
-
String字符串的更新
和新增逻辑相同,只不过请求参数变成UpdateRequest
@Test void update() throws IOException { //准备request UpdateRequest request=new UpdateRequest("user","1"); //准备Json数据 String jsonString="" + "{\n" + " \"id\":3,\n" + " \"name\":\"张胜男\",\n" + " \"age\":12,\n" + " \"address\":\"武汉市\"\n" + " }"; request.doc(jsonString,XContentType.JSON); client.update(request,RequestOptions.DEFAULT); }代码分析图

-
Map数组的更新
@Test void update2() throws IOException { Map这里就和使用Map新增的方法大同小异了
-
-
使用脚本更新
这里先引用一下官方的例子,等有空了在做详细的脚本更新
//1 Map这段代码来自官方文档,可以看出
- 作为对象映射提供的脚本参数
- 使用简单的语言和前面的参数创建内联脚本
- 将脚本设置为更新请求
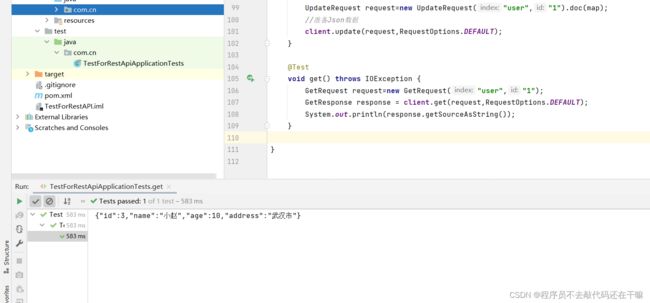
2.3.6.RestAPI_查看文档
@Test
void get() throws IOException {
GetRequest request=new GetRequest("user","1");
GetResponse response = client.get(request,RequestOptions.DEFAULT);
System.out.println(response.getSourceAsString());
}
以上是查看的代码
3.总结
本文提供了在ES中的分别使用原始DSL语句和JavaRestClient实现的CRUD的概述。最后,本文概述了Elasticsearch如何分别使用DSL语句和RestHighLevelClient处理文档。Elasticsearch是一个强大的工具,可以用来存储和搜索大量的数据。在DSL语句和RestHighLevelClient的帮助下,可以以各种方式与文档进行交互。如果你有兴趣学习更多关于Elasticsearch的知识.关注我,更新更多有用的免费的知识。