深度学习之超分辨率算法(pytorch)——ESPCN
先回忆一下:
SRCNN缺点
- 依赖于图像区域
- 收敛速度慢哈
- 尺度固定
- 计算量大
模型输入:原始低分辨率图片
核心:亚像素卷积。在网络的最末端实现LR到HR的分辨率
背景:之前的SRCNN,通过双三次插值得到的高分辨率的图像,直接从低分辨率LR得到了高分辨率的图片。(输入是双三次插值的高分辨率图像(类似于粗糙的高分辨率图像)),那么在网络卷积中就会造成,粗糙的高分辨率图和标签进行计算。这样计算时间复杂度较大。
ESPCN网络模型

# 网络模型代码
import math
import torch
from torch import nn
class ESPCN(nn.Module):
def __init__(self, scale_factor, num_channels=1):
super(ESPCN, self).__init__()
self.first_part = nn.Sequential(
nn.Conv2d(num_channels, 64, kernel_size=5, padding=5//2),
nn.Tanh(),
nn.Conv2d(64, 32, kernel_size=3, padding=3//2),
nn.Tanh(),
)
self.last_part = nn.Sequential(
nn.Conv2d(32, num_channels * (scale_factor ** 2), kernel_size=3, padding=3 // 2),
nn.PixelShuffle(scale_factor)
)
self._initialize_weights()
def _initialize_weights(self):
# 权重初始化
for m in self.modules():
if isinstance(m, nn.Conv2d):
if m.in_channels == 32:
nn.init.normal_(m.weight.data, mean=0.0, std=0.001)
nn.init.zeros_(m.bias.data)
else:
nn.init.normal_(m.weight.data, mean=0.0, std=math.sqrt(2/(m.out_channels*m.weight.data[0][0].numel())))
nn.init.zeros_(m.bias.data)
def forward(self, x):
x = self.first_part(x)
x = self.last_part(x)
return x
if __name__ == '__main__':
model = ESPCN(scale_factor=3)
x = torch.randn(1,1,224,224)
print(model(x).shape)
思路:网络末端实现LR到HR的分辨率实现,并且网络前部分都是对低分辨率部分进行操作,并没有添加任何关于高分辨率的先验信息。到了亚像素卷积层,网络才将低分辨空间映射到高分辨率层。原始得到的图像为 r r rx w w wx h h h大小,通过亚像素卷积重新排列之后之后,得到的 r 2 r^2 r2x w w wx h h h重排序 1 1 1x r H rH rHx r W rW rW,亚像素卷积层如图:
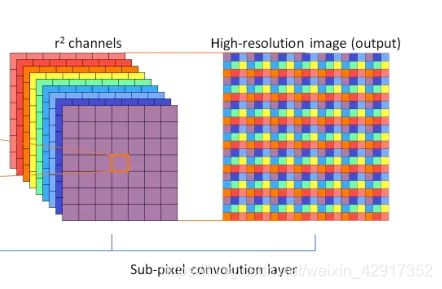
备注
- 亚像素卷积层,**并没有做卷积操作,**而是直接将 r 2 r^2 r2个通道的特征图,重新进行排列,这样就完成了LR到HR的恢复。在张量维度上直接操作,并不需要计算。
总结:
ESPCN的创新点:
- 重点就是亚像素卷积重排列
- 激活函数由Tanh替换了Relu,可以获得更多的非线性特征。
上代码阶段
数据集:github上高星的代码,我试了需要本地服务器还是啥的,没整OK,不过利用VOC212数据集是个好点子。于是 我采用了VOC数据集
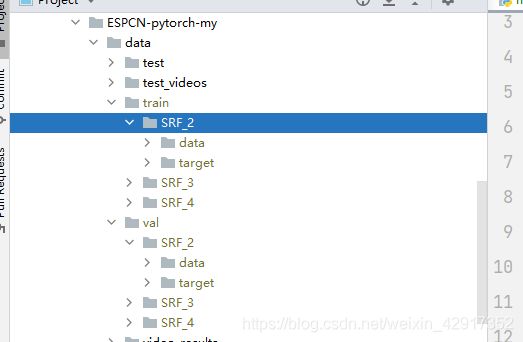
train中SRF_2(代表scale)下data和target分别代表低分辨率图放大2之后的高分辨率标签。
val:验证集
data_utils.py
import argparse
import os
from os import listdir
from os.path import join
from PIL import Image
from torch.utils.data.dataset import Dataset
from torchvision import transforms
from tqdm import tqdm
def is_image_file(filename):
# 判断image
return any(filename.endswith(extension) for extension in ['.png', '.jpg', '.jpeg', '.JPG', '.JPEG', '.PNG'])
def is_video_file(filename):
# 判断是否是视频文件
return any(filename.endswith(extension) for extension in ['.mp4', '.avi', '.mpg', '.mkv', '.wmv', '.flv'])
def calculate_valid_crop_size(crop_size, upscale_factor):
return crop_size - (crop_size % upscale_factor)
def input_transform(crop_size, upscale_factor):
# 对输入的处理
return transforms.Compose([
transforms.CenterCrop(crop_size),
transforms.Resize(crop_size // upscale_factor, interpolation=Image.BICUBIC)
])
def target_transform(crop_size):
return transforms.Compose([
transforms.CenterCrop(crop_size)
])
class DatasetFromFolder(Dataset):
def __init__(self, dataset_dir, upscale_factor, input_transform=None, target_transform=None):
super(DatasetFromFolder, self).__init__()
self.image_dir = dataset_dir + '/SRF_' + str(upscale_factor) + '/data'
self.target_dir = dataset_dir + '/SRF_' + str(upscale_factor) + '/target'
self.image_filenames = [join(self.image_dir, x) for x in listdir(self.image_dir) if is_image_file(x)]
self.target_filenames = [join(self.target_dir, x) for x in listdir(self.target_dir) if is_image_file(x)]
self.input_transform = input_transform
self.target_transform = target_transform
def __getitem__(self, index):
image, _, _ = Image.open(self.image_filenames[index]).convert('YCbCr').split()
target, _, _ = Image.open(self.target_filenames[index]).convert('YCbCr').split()
if self.input_transform:
image = self.input_transform(image)
if self.target_transform:
target = self.target_transform(target)
return image, target
def __len__(self):
return len(self.image_filenames)
def generate_dataset(data_type, upscale_factor):
images_name = [x for x in listdir('data/VOC2012/' + data_type) if is_image_file(x)]
crop_size = calculate_valid_crop_size(256, upscale_factor)
lr_transform = input_transform(crop_size, upscale_factor)
hr_transform = target_transform(crop_size)
root = 'data/' + data_type
if not os.path.exists(root):
os.makedirs(root)
path = root + '/SRF_' + str(upscale_factor)
if not os.path.exists(path):
os.makedirs(path)
image_path = path + '/data'
if not os.path.exists(image_path):
os.makedirs(image_path)
target_path = path + '/target'
if not os.path.exists(target_path):
os.makedirs(target_path)
for image_name in tqdm(images_name, desc='generate ' + data_type + ' dataset with upscale factor = '
+ str(upscale_factor) + ' from VOC2012'):
image = Image.open('data/VOC2012/' + data_type + '/' + image_name)
target = image.copy()
image = lr_transform(image)
target = hr_transform(target)
image.save(image_path + '/' + image_name)
target.save(target_path + '/' + image_name)
if __name__ == "__main__":
parser = argparse.ArgumentParser(description='Generate Super Resolution Dataset')
parser.add_argument('--upscale_factor', default=2, type=int, help='super resolution upscale factor')
opt = parser.parse_args()
UPSCALE_FACTOR = opt.upscale_factor
generate_dataset(data_type='train', upscale_factor=UPSCALE_FACTOR)
generate_dataset(data_type='val', upscale_factor=UPSCALE_FACTOR)
- 修改main下的scale运行可以制作出不同尺寸的数据集。DatasetFromFolder类表示数据的读取方式。
utils.py 工具类,图片的格式转换,psnr计算
import torch
import numpy as np
def calc_patch_size(func):
def wrapper(args):
if args.scale == 2:
args.patch_size = 10
elif args.scale == 3:
args.patch_size = 7
elif args.scale == 4:
args.patch_size = 6
else:
raise Exception('Scale Error', args.scale)
return func(args)
return wrapper
def convert_rgb_to_y(img, dim_order='hwc'):
if dim_order == 'hwc':
return 16. + (64.738 * img[..., 0] + 129.057 * img[..., 1] + 25.064 * img[..., 2]) / 256.
else:
return 16. + (64.738 * img[0] + 129.057 * img[1] + 25.064 * img[2]) / 256.
def convert_rgb_to_ycbcr(img, dim_order='hwc'):
if dim_order == 'hwc':
y = 16. + (64.738 * img[..., 0] + 129.057 * img[..., 1] + 25.064 * img[..., 2]) / 256.
cb = 128. + (-37.945 * img[..., 0] - 74.494 * img[..., 1] + 112.439 * img[..., 2]) / 256.
cr = 128. + (112.439 * img[..., 0] - 94.154 * img[..., 1] - 18.285 * img[..., 2]) / 256.
else:
y = 16. + (64.738 * img[0] + 129.057 * img[1] + 25.064 * img[2]) / 256.
cb = 128. + (-37.945 * img[0] - 74.494 * img[1] + 112.439 * img[2]) / 256.
cr = 128. + (112.439 * img[0] - 94.154 * img[1] - 18.285 * img[2]) / 256.
return np.array([y, cb, cr]).transpose([1, 2, 0])
def convert_ycbcr_to_rgb(img, dim_order='hwc'):
if dim_order == 'hwc':
r = 298.082 * img[..., 0] / 256. + 408.583 * img[..., 2] / 256. - 222.921
g = 298.082 * img[..., 0] / 256. - 100.291 * img[..., 1] / 256. - 208.120 * img[..., 2] / 256. + 135.576
b = 298.082 * img[..., 0] / 256. + 516.412 * img[..., 1] / 256. - 276.836
else:
r = 298.082 * img[0] / 256. + 408.583 * img[2] / 256. - 222.921
g = 298.082 * img[0] / 256. - 100.291 * img[1] / 256. - 208.120 * img[2] / 256. + 135.576
b = 298.082 * img[0] / 256. + 516.412 * img[1] / 256. - 276.836
return np.array([r, g, b]).transpose([1, 2, 0])
def preprocess(img, device):
img = np.array(img).astype(np.float32)
ycbcr = convert_rgb_to_ycbcr(img)
x = ycbcr[..., 0]
x /= 255.
x = torch.from_numpy(x).to(device)
x = x.unsqueeze(0).unsqueeze(0)
return x, ycbcr
def calc_psnr(img1, img2):
return 10. * torch.log10(1. / torch.mean((img1 - img2) ** 2))
class AverageMeter(object):
def __init__(self):
self.reset()
def reset(self):
self.val = 0
self.avg = 0
self.sum = 0
self.count = 0
def update(self, val, n=1):
self.val = val
self.sum += val * n
self.count += n
self.avg = self.sum / self.count
train.py
import argparse
import os
import copy
import torch
from torch import nn
import torch.optim as optim
import torch.backends.cudnn as cudnn
from torch.utils.data.dataloader import DataLoader
from torchvision import transforms
from tqdm import tqdm
from models import ESPCN
from data_utils import DatasetFromFolder
from utils import AverageMeter, calc_psnr
if __name__ == '__main__':
parser = argparse.ArgumentParser()
parser.add_argument('--train-file', type=str,default="./data/train")
parser.add_argument('--eval-file', type=str, default="./data/val")
parser.add_argument('--outputs-dir', type=str, default="./outputs")
parser.add_argument('--weights-file', type=str)
parser.add_argument('--scale', type=int, default=3)
parser.add_argument('--lr', type=float, default=1e-3)
parser.add_argument('--batch-size', type=int, default=16)
parser.add_argument('--num-epochs', type=int, default=200)
parser.add_argument('--num-workers', type=int, default=8)
parser.add_argument('--seed', type=int, default=123)
args = parser.parse_args()
args.outputs_dir = os.path.join(args.outputs_dir, 'x{}'.format(args.scale))
if not os.path.exists(args.outputs_dir):
os.makedirs(args.outputs_dir)
# cudann加速
cudnn.benchmark = True
device = torch.device('cuda:0' if torch.cuda.is_available() else 'cpu')
torch.manual_seed(args.seed)
model = ESPCN(scale_factor=args.scale).to(device)
criterion = nn.MSELoss()
optimizer = optim.Adam([
{'params': model.first_part.parameters()},
{'params': model.last_part.parameters(), 'lr': args.lr * 0.1}
], lr=args.lr)
# 训练集
train_dataset = DatasetFromFolder(args.train_file, upscale_factor=args.scale, input_transform=transforms.ToTensor(),
target_transform=transforms.ToTensor())
# 验证集
train_dataloader = DataLoader(dataset=train_dataset,
batch_size=args.batch_size,
shuffle=True,
num_workers=args.num_workers,
pin_memory=True)
eval_dataset =DatasetFromFolder(args.eval_file, upscale_factor=args.scale, input_transform=transforms.ToTensor(),
target_transform=transforms.ToTensor())
eval_dataloader = DataLoader(dataset=eval_dataset, batch_size=1)
best_weights = copy.deepcopy(model.state_dict())
best_epoch = 0
best_psnr = 0.0
for epoch in range(args.num_epochs):
for param_group in optimizer.param_groups:
param_group['lr'] = args.lr * (0.1 ** (epoch // int(args.num_epochs * 0.8)))
model.train()
epoch_losses = AverageMeter()
with tqdm(total=(len(train_dataset) - len(train_dataset) % args.batch_size), ncols=80) as t:
t.set_description('epoch: {}/{}'.format(epoch, args.num_epochs - 1))
for data in train_dataloader:
inputs, labels = data
inputs = inputs.to(device)
labels = labels.to(device)
preds = model(inputs)
# print(preds.shape,labels.shape)
loss = criterion(preds, labels)
epoch_losses.update(loss.item(), len(inputs))
optimizer.zero_grad()
loss.backward()
optimizer.step()
t.set_postfix(loss='{:.6f}'.format(epoch_losses.avg))
t.update(len(inputs))
torch.save(model.state_dict(), os.path.join(args.outputs_dir, 'epoch_{}.pth'.format(epoch)))
model.eval()
epoch_psnr = AverageMeter()
for data in eval_dataloader:
inputs, labels = data
inputs = inputs.to(device)
labels = labels.to(device)
with torch.no_grad():
preds = model(inputs).clamp(0.0, 1.0)
epoch_psnr.update(calc_psnr(preds, labels), len(inputs))
print('eval psnr: {:.2f}'.format(epoch_psnr.avg))
if epoch_psnr.avg > best_psnr:
best_epoch = epoch
best_psnr = epoch_psnr.avg
best_weights = copy.deepcopy(model.state_dict())
print('best epoch: {}, psnr: {:.2f}'.format(best_epoch, best_psnr))
torch.save(best_weights, os.path.join(args.outputs_dir, 'best.pth'))
测试效果
import argparse
import torch
import torch.backends.cudnn as cudnn
import numpy as np
import PIL.Image as pil_image
from models import ESPCN
from utils import convert_ycbcr_to_rgb, preprocess, calc_psnr
if __name__ == '__main__':
parser = argparse.ArgumentParser()
parser.add_argument('--weights-file', type=str, default="./outputs/x3/best.pth")
parser.add_argument('--image-file', type=str, default="test_images/BSD100_001.png")
parser.add_argument('--scale', type=int, default=3)
args = parser.parse_args()
cudnn.benchmark = True
device = torch.device('cuda:0' if torch.cuda.is_available() else 'cpu')
model = ESPCN(scale_factor=args.scale).to(device)
state_dict = model.state_dict()
for n, p in torch.load(args.weights_file, map_location=lambda storage, loc: storage).items():
if n in state_dict.keys():
state_dict[n].copy_(p)
else:
raise KeyError(n)
model.eval()
image = pil_image.open(args.image_file).convert('RGB')
print(image.size)
image_width = (image.width // args.scale) * args.scale
image_height = (image.height // args.scale) * args.scale
hr = image.resize((image_width, image_height), resample=pil_image.BICUBIC)
# lr = hr.resize((hr.width // args.scale, hr.height // args.scale), resample=pil_image.BICUBIC)
lr = hr.resize((hr.width // args.scale, hr.height // args.scale), resample=pil_image.BICUBIC)
bicubic = lr.resize((lr.width * args.scale, lr.height * args.scale), resample=pil_image.BICUBIC)
bicubic.save(args.image_file.replace('.', '_bicubic_x{}.'.format(args.scale)))
lr, _ = preprocess(lr, device)
hr, _ = preprocess(hr, device)
_, ycbcr = preprocess (bicubic, device)
with torch.no_grad():
print(lr.shape)
preds = model(lr).clamp(0.0, 1.0)
# preds = model()
print("size:",preds.shape)
psnr = calc_psnr(hr, preds)
print('PSNR: {:.2f}'.format(psnr))
preds = preds.mul(255.0).cpu().numpy().squeeze(0).squeeze(0)
print(preds.shape)
output = np.array([preds, ycbcr[..., 1], ycbcr[..., 2]]).transpose([1, 2, 0])
output = np.clip(convert_ycbcr_to_rgb(output), 0.0, 255.0).astype(np.uint8)
output = pil_image.fromarray(output)
output.save(args.image_file.replace('.', '_espcn_x{}.'.format(args.scale)))
原图:

=
- 对三次插值结果:

ESPCN网络效果:

训练3倍的200轮,最好的psnr为25.36。看来还是需要多训练一下。
有问题的小伙伴欢迎添加微信一起讨论哦
