《C和指针》读书笔记(第十一章 动态内存分配)
目录
- 0 简介
- 1 为什么使用动态内存分配
- 2 malloc和free
- 3 calloc和realloc
- 4 使用动态分配的内存
- 5 常见的动态内存错误
- 6 内存分配实例
-
- 6.1 排序一列整型值
- 6.2 复制字符串
- 6.3 变体记录的创建与销毁
- 7 总结
0 简介
在实际开发中(C语言),数组的元素存储于内存中连续的位置上。但是用数组存储数据有个弊端,就是在程序运行之前我们就要知道其大小,在实际开发中,我们并不总能对需要申请的内存做到精准把握,若不采取其他手段,会让开发人员焦头烂额。
作为C语言的老大哥,C++显然可以高枕无忧,在面临很多复杂的场景时,往往可以采用容器从容应对,游刃有余。具体可参考链接:C++常见容器一网打尽
这样的问题,C语言也有自己的应对措施,为了打破这样的僵局,今天的主角轻施脂粉,深情款款地向我们走来,这就是动态内存分配(C++中同样适用)。
本篇内容概览:
1 为什么使用动态内存分配
如上所述,很多时候,我们并不知道我们需要申请多大的内存来存放数据,太大浪费空间,太小不够用。
2 malloc和free
malloc和free是一对亲兄弟,前者负责申请内存,后者 负责释放内存。分工明确,简单高效。这两个函数的原型如下:
void *malloc(size_t size);
void free(void *pointer);
malloc分配的就是一块连续的内存。同时,实际分配的内存可能比我们申请的稍微多一点,具体的大小取决于编译器。
如果内存池是空的,或者可用内存无法满足请求,malloc函数向操作系统请求,要求得到更多的内存,并在这块新内存上执行分配任务。如果操作系统无法向malloc提供更多的内存,就会返回一个NULL指针。
free的参数必须要么是NULL,要么是一个先前从malloc、calloc或realloc返回的值。向free传递一个NULL不会产生任何效果。
具体的案例会在后续内容中提及。
3 calloc和realloc
另外还有两个内存分配函数calloc和realloc。它们的原型如下所示:
void *calloc(size_t num_elements, size_t element_size);
void *realloc(void *ptr, size_t new_size);
calloc和malloc有两个区别:
- 从形式上看,
malloc传入的是总字节数,而calloc传入的是元素数和每个元素所占的字节数。 - 从作用上看,
malloc只负责申请内存空间,而calloc不仅仅申请了内存空间,还将其初始化为0。
从名称上也可以看出来: calloc = clear + malloc,意为清零and申请内存。
realloc则是修改/重新申请一块内存。
- 如果p指向的空间之后有足够的空间可以追加,则直接追加,返回的是
p原来的起始地址。 - 如果p指向的空间之后没有足够的空间可以追加,则
realloc函数会重新找一个新的内存区域,重新开辟一块new_size个字节的动态内存空间,并且把原来内存空间的数据拷贝回来,释放旧的内存空间还给操作系统,最后返回新开辟的内存空间的起始地址。
第一种情况如下图所示:
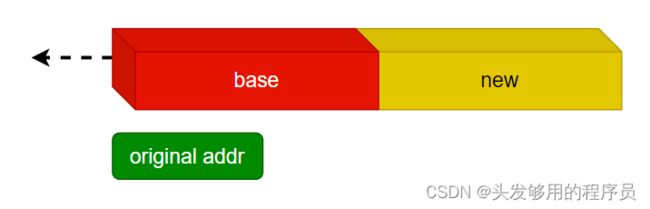
第二种情况如下图所示:

从名称上也可以看出来: realloc = re + malloc,意为重新申请内存。
4 使用动态分配的内存
书中有个例子,如下:
int *pi;
pi = malloc(100);
if (pi == NULL)
{
printf("Out of memory!\n");
exit(1);
}
这个例子很好懂,我们分配一个100字节的内存,如果分配失败了,就打印输出错误,并退出当前正在执行的程序。
当然,我们也可以自己写一个简单的程序,如下:
#include这就是一个比较完整的案例,分配内存,初始化,并验证内存分配是否成功。
5 常见的动态内存错误
常见的动态内存错误有两种:
- 一种是根本没有判断内存是否申请成功,就直接使用,这样可能会出现意想不到的问题。
- 一种是操作时超出了分配内存的边界,同样也可能会出现意想不到的问题。
内存错误不好写具体的案例,只需平时编程注意即可。
6 内存分配实例
6.1 排序一列整型值
排序算法是工程开发中最常见,最经典的算法,常见的排序算法有十种,感兴趣的请移步:
十大经典排序算法(C语言实现)
下面给的例子是书中给的,用的是库函数qsort进行排序,据说底层采用的是快速排序算法。
#include 运行,打印输出:

基本上没有什么难点,唯一的难点是compare_integers函数的返回值用了嵌套的条件表达式,条件表达式就是简化版的条件语句(并非所有情况下都可以“简化”),稍微有点绕,关于条件表达式,可以参考《C和指针》读书笔记(第五章 操作符和表达式)的2.1.8小节。
6.2 复制字符串
复制字符串也有现成的库函数可以用,书上的例子仅仅是给新的字符串开辟了空间,仅此而已(略有改动)。
#include 运行,打印输出:

可以看到,字符串复制成功。从这个例子也可以看出动态内存分配在开发中的方便之处。
6.3 变体记录的创建与销毁
最后一个例子说明了可以怎样使用动态内存分配来消除使用变体记录造成的内存空间浪费。程序中用到了结构体和联合体的知识,想了解相关知识,请移步:《C和指针》读书笔记(第十章 结构和联合)
先创建一个头文件,定义需要用到的结构体
#pragma once
//包含零件专用信息的结构
typedef struct {
int cost;
int supplier;
}Partinfo;
//存储配件专用信息的结构
typedef struct {
int n_parts;
struct SUBASSYPART{
char partno[10];
short quan;
} *part;
}Subassyinfo;
//存货记录结构,一个变体记录
typedef struct {
char partno[10];
int quan;
enum {PART, SUBASSY} type;
union {
Partinfo *part;
Subassyinfo *subassy;
}info;
}Invrec;
再写创建变体记录的相关程序:
#include 还有变体记录销毁的相关程序:
#include 这个例子比较复杂,其中有结构体的嵌套,这就关系到了内存的层层申请,然后再层层释放。
7 总结
本章内容不是很多,但却非常实用。当数组被声明时,必须在编译时知道它的长度。动态内存分配允许程序为一个长度在运行时才知道的数组分配内存空间。