原文链接:http://tecdat.cn/?p=22273
动机
如果你了解数据科学领域,你可能听说过LASSO。LASSO是一个对目标函数中的参数大小进行惩罚的模型,试图将不相关的变量从模型中排除。它有两个非常自然的用途,第一个是变量选择,第二个是预测。因为通常情况下,LASSO选择的变量会比普通最小二乘法(OLS)少得多,其预测的方差会小得多,代价是样本中出现少量的偏差。
LASSO最重要的特点之一是它可以处理比观测值多得多的变量,我说的是成千上万的变量。这是它最近流行的主要原因之一。
实例
在这个例子中,我使用最流行的LASSO,glmnet。我们可以非常快速地估计LASSO,并使用交叉验证选择最佳模型。根据我的经验,在时间序列的背景下,使用信息准则(如BIC)来选择最佳模型会更好。它更快,并避免了时间序列中交叉验证的一些复杂问题。
本文估计LASSO,并使用信息标准来选择最佳模型。我们将使用LASSO来预测通货膨胀。
## == 数据分解成样本内和样本外
y.in=y\[1:100\]; y.out=y\[-c(1:100)\]
x.in=x\[1:100,\]; x.out=x\[-c(1:100),\]
## == LASSO == ##
glmnet(x.in,y.in,crit = "bic")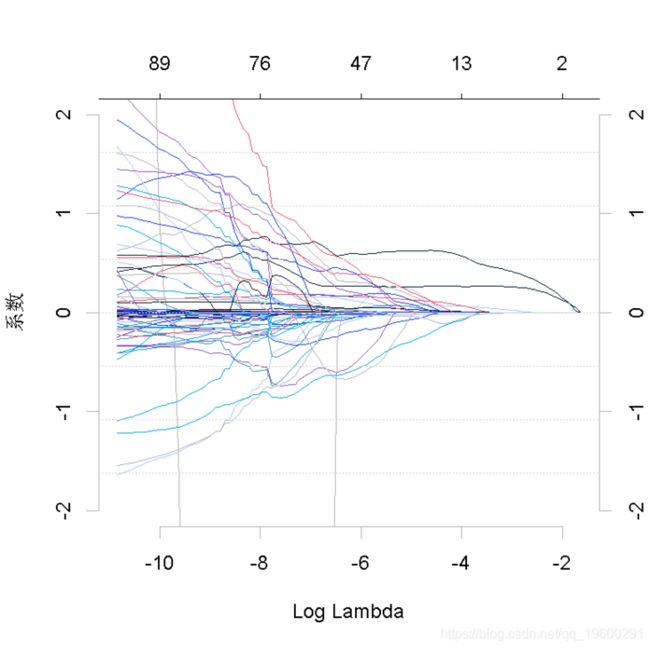
plot(lasso)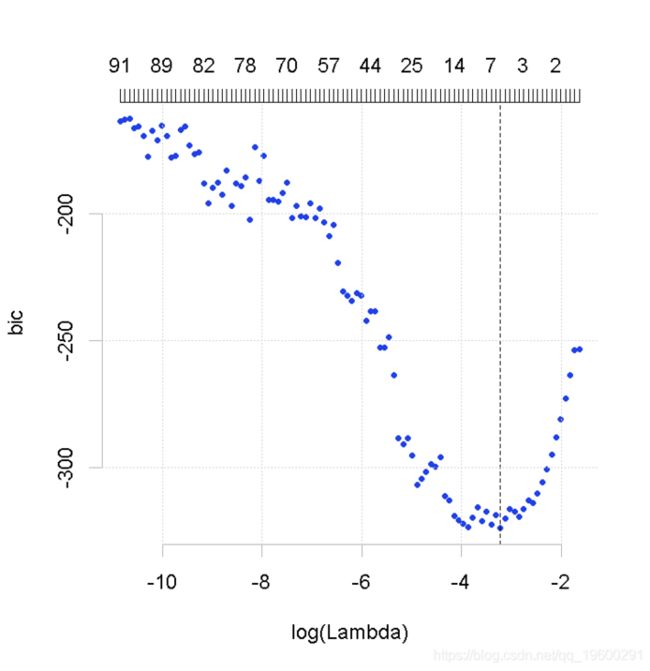
上面的第一个图显示,当我们增加LASSO目标函数中的惩罚时,变量会归零。第二张图显示了BIC曲线和选定的模型。现在我们可以计算预测了。
## == 预测 == ##
predict(lasso,x.out)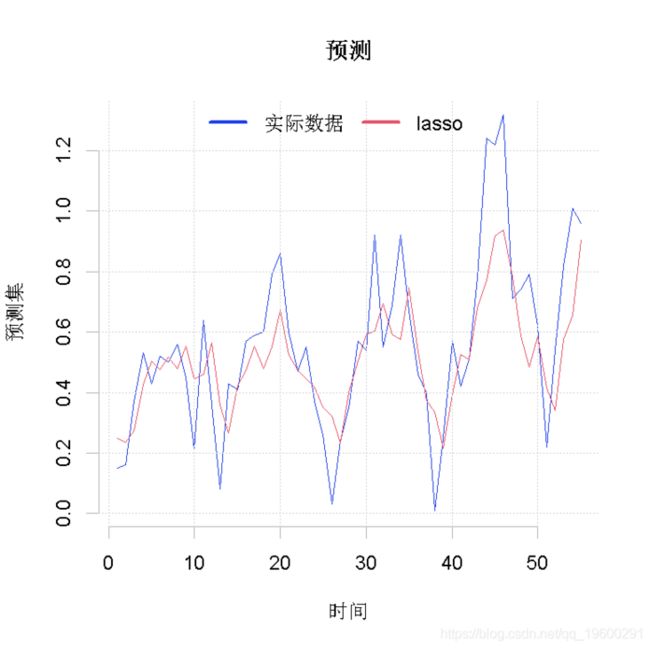
adaptive LASSO
LASSO有一个自适应版本,在变量选择方面有一些更好的特性。请注意,这并不总是意味着更好的预测。该模型背后的想法是使用一些以前知道的信息来更有效地选择变量。一般来说,这些信息是由LASSO或其他一些模型估计的系数。
## = adaLASSO = ##
adalasso(x.in,y.in,crit="bic",penalty=factor)
predict(adalasso, x.out)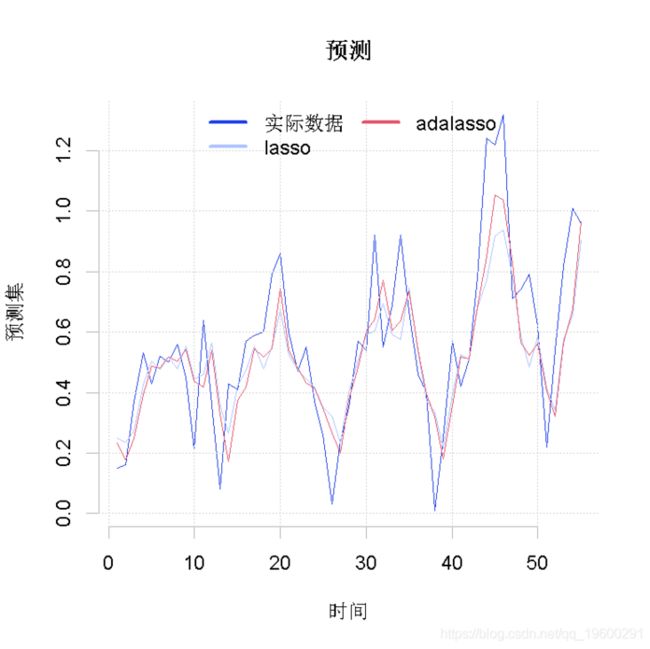
## = 比较误差 = ##
sqrt(mean((y.out-pred.ada)^2)![]()
在这种情况下,adaLASSO产生了一个更精确的预测。一般来说,adaLASSO比简单的LASSO的预测效果更好。然而,这不是一个绝对的事实。我见过很多简单LASSO做得更好的案例。
参考文献
[1] Bühlmann, Peter, and Sara Van De Geer. Statistics for high-dimensional data: methods, theory and applications. Springer Science & Business Media, 2011.
[2] Jerome Friedman, Trevor Hastie, Robert Tibshirani (2010). Regularization Paths for
Generalized Linear Models via Coordinate Descent. Journal of Statistical Software, 33(1), 1-22. URL http://www.jstatsoft.org/v33/i01/
[3] Marcio Garcia, Marcelo C. Medeiros , Gabriel F. R. Vasconcelos (2017). Real-time inflation forecasting with high-dimensional models: The case of Brazil. Internationnal Journal of Forecasting, in press.

最受欢迎的见解
1.在python中使用lstm和pytorch进行时间序列预测
2.python中利用长短期记忆模型lstm进行时间序列预测分析