RabbitMQ高频面试题
文章目录
- 1. 如何保证消息不丢失
-
- a. 生产者弄丢了数据
- b. RabbitMQ 弄丢了数据
- c. 消费端弄丢了数据
- 2. 如何保证消息的有序性
- 3. 如何避免重复消费
- 4. 消息积压
- 5. RabbitMQ实现超时未支付订单取消
1. 如何保证消息不丢失
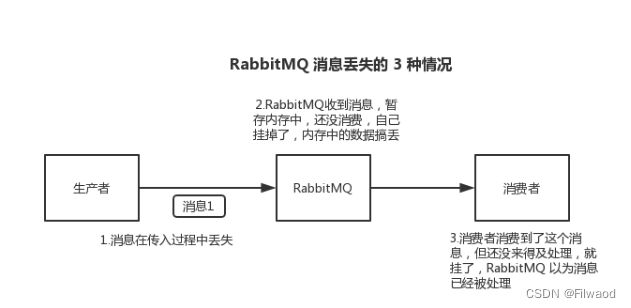
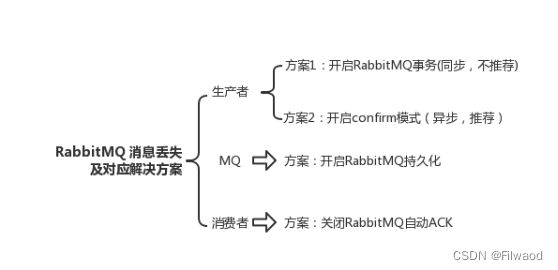
a. 生产者弄丢了数据
生产者将数据发送到 RabbitMQ 的时候,可能数据就在半路给搞丢了,因为网络问题啥的,都有可能。
此时可以选择用 RabbitMQ 提供的事务功能,就是生产者发送数据之前开启 RabbitMQ 事务 channel.txSelect ,然后发送消息,如果消息没有成功被 RabbitMQ 接收到,那么生产者会收到异常报错,此时就可以回滚事务 channel.txRollback ,然后重试发送消息;如果收到了消息,那么可以提交事务 channel.txCommit 。
// 开启事务
channel.txSelect
try {
// 这里发送消息
} catch (Exception e) {
channel.txRollback
// 这里再次重发这条消息
}
// 提交事务
channel.txCommit
但是问题是,RabbitMQ 事务机制(同步)一搞,基本上吞吐量会下来,因为太耗性能。
所以一般来说,如果你要确保说写 RabbitMQ 的消息别丢,可以开启 confirm 模式,在生产者那里设置开启 confirm 模式之后,你每次写的消息都会分配一个唯一的 id,然后如果写入了 RabbitMQ 中,RabbitMQ 会给你回传一个 ack 消息,告诉你说这个消息 ok 了。如果 RabbitMQ 没能处理这个消息,会回调你的一个 nack 接口,告诉你这个消息接收失败,你可以重试。而且你可以结合这个机制自己在内存里维护每个消息 id 的状态,如果超过一定时间还没接收到这个消息的回调,那么你可以重发。
事务机制和 confirm 机制最大的不同在于,事务机制是同步的,你提交一个事务之后会阻塞在那儿,但是 confirm 机制是异步的,你发送个消息之后就可以发送下一个消息,然后那个消息 RabbitMQ 接收了之后会异步回调你的一个接口通知你这个消息接收到了。
所以一般在生产者这块避免数据丢失,都是用 confirm 机制的。
b. RabbitMQ 弄丢了数据
就是 RabbitMQ 自己弄丢了数据,这个你必须开启 RabbitMQ 的持久化,就是消息写入之后会持久化到磁盘,哪怕是 RabbitMQ 自己挂了,恢复之后会自动读取之前存储的数据,一般数据不会丢。除非极其罕见的是,RabbitMQ 还没持久化,自己就挂了,可能导致少量数据丢失,但是这个概率较小。
开启持久化有两个步骤:
-
创建 queue 的时候将其设置为持久化
这样就可以保证 RabbitMQ 持久化 queue 的元数据,但是它是不会持久化 queue 里的数据的。 -
发送消息的时候将消息的 deliveryMode 设置为 2
就是将消息设置为持久化的,此时 RabbitMQ 就会将消息持久化到磁盘上去。
RabbitMQ的队列(Queue)的元数据包含以下信息:
队列名称(Name):队列的唯一标识符,用于在RabbitMQ中进行队列的创建、订阅和发送消息等操作。
持久性(Durable):指示队列是否是持久化的。如果队列被声明为持久化的,那么队列的元数据将存储在磁盘上,以防止服务器重启时的数据丢失。
排他性(Exclusive):指示队列是否是排他的。如果队列被声明为排他的,那么只有声明该队列的连接可以使用它,一旦连接关闭,队列将被自动删除。
自动删除(Auto-delete):指示队列是否是自动删除的。如果队列被声明为自动删除的,那么当没有消费者订阅该队列时,队列将被自动删除。
队列参数(Arguments):一些额外的参数可以与队列关联,例如消息的存活时间、最大长度等。这些参数可以通过队列的元数据进行设置。
要注意的是,持久化队列和持久化消息需要一起使用,才能实现完整的持久性保证。持久化队列确保在服务器重启后,队列的元数据仍然可用,而持久化消息则确保消息在发送和接收过程中的持久性。
注意,哪怕是你给 RabbitMQ 开启了持久化机制,也有一种可能,就是这个消息写到了 RabbitMQ 中,但是还没来得及持久化到磁盘上,结果不巧,此时 RabbitMQ 挂了,就会导致内存里的一点点数据丢失。
所以,持久化可以跟生产者那边的 confirm 机制配合起来,只有消息被持久化到磁盘之后,才会通知生产者 ack 了,所以哪怕是在持久化到磁盘之前,RabbitMQ 挂了,数据丢了,生产者收不到 ack ,你也是可以自己重发的。
c. 消费端弄丢了数据
RabbitMQ 如果丢失了数据,主要是因为你消费的时候,刚消费到,还没处理,结果进程挂了,比如重启了,那么就尴尬了,RabbitMQ 认为你都消费了,这数据就丢了。
这个时候得用 RabbitMQ 提供的 ack 机制,简单来说,就是你必须·关闭 RabbitMQ 的自动 ack· ,可以通过一个 api 来调用就行,然后每次你自己代码里确保处理完的时候,再在程序里 ack 一把。这样的话,如果你还没处理完,不就没有 ack 了?那 RabbitMQ 就认为你还没处理完,这个时候 RabbitMQ 会把这个消费分配给别的 consumer 去处理,消息是不会丢的。
2. 如何保证消息的有序性
消息中间件(MQ)本身并不能保证消息的绝对有序性,因为分布式系统中消息的处理涉及多个节点和并发处理。然而,可以采取一些措施来尽量保证消息的有序性:
-
单一消费者:为了保证消息的有序性,可以
将每个队列限定为只有一个消费者来处理消息。这样,每个消息只能被一个消费者按照顺序处理,从而实现有序性。 -
消费者端有序处理:在
消费者端,可以通过串行化消费的方式来保证消息的有序性。即每个消费者从队列中逐个获取消息,并按照顺序进行处理,确保消息的顺序性。 -
消息标识和排序:在消息中
携带一个唯一标识符或序号,并在消费者端进行排序处理。消费者可以根据标识符或序号对消息进行排序,确保按照预期的顺序进行处理。
需要注意的是,上述方法都是尽力保证消息的有序性,但在高并发或分布式环境下,仍然可能存在一定程度的乱序。因此,在设计分布式系统时,应该根据具体业务需求和实际情况来选择适合的消息处理策略,并在系统设计中考虑乱序带来的影响
3. 如何避免重复消费
为了确保消息不被重复消费,可以采取以下几种方法:
-
消息去重:在消费者端
记录(redis,mysql)已经消费过的消息的唯一标识符(如消息ID),并在处理新消息之前,检查该消息是否已经被处理过。如果消息已经被消费过,则可以选择丢弃重复消息或执行相应的处理逻辑。 -
幂等性处理:在设计
消费者的处理逻辑时,要保证处理操作是幂等的,即无论执行多少次,结果都是一致的。这样即使消息被重复消费,其影响也是可控的。通过设计幂等性的处理逻辑,可以避免重复消费导致的副作用。 -
消费确认机制:一些消息中间件(如RabbitMQ)提供了
消费确认机制。消费者在处理完消息后,向消息中间件发送确认消息,通知中间件该消息已经被成功消费。中间件在接收到确认消息后,将该消息标记为已消费,以确保不会再次将其分发给消费者。
综合使用以上方法可以有效地避免消息的重复消费。但需要注意的是,在分布式系统中,由于网络故障、消息重复传递等原因,仍然存在一定概率的消息重复消费。因此,在设计分布式系统时,应该考虑到这种情况,并在业务逻辑上进行幂等性处理,以保证系统的正确性和一致性。
4. 消息积压
处理消息积压的方法取决于具体的情况和需求。以下是一些常见的解决方法:
-
增加消费者数量:如果消息积压是由于
消费者的处理速度跟不上消息产生的速度导致的,可以通过增加消费者的数量来提高消息处理的并发性。这样可以分担每个消费者的负载,加快消息的处理速度。 -
扩展消息队列:如果
消息队列成为瓶颈导致消息积压,可以考虑扩展消息队列的容量和性能。这包括增加队列的节点数、调整队列的配置参数、增加队列的分区等。通过提升消息队列的吞吐能力,可以更好地应对高峰时段的消息流量。 -
监控和预警机制:
建立消息积压的监控系统,实时监测消息队列的长度和消费者的处理速度。当消息积压超过阈值时,触发预警机制,及时采取相应的调整措施,防止问题进一步扩大。
需要根据具体的业务需求和系统情况选择适合的解决方法。同时,定期进行容量规划和性能优化,合理设计系统架构,也是预防和解决消息积压问题的重要手段。
5. RabbitMQ实现超时未支付订单取消
要实现超时未支付订单的取消功能,可以借助RabbitMQ的延时消息特性。下面是一种基本的实现思路:
1.创建两个队列:一个用于接收新订单消息,另一个用于处理取消订单消息。
2.当有新的订单生成时,将订单信息发送到新订单消息队列,并设置订单的超时时间。
3.在新订单消息队列上设置消息的过期时间,确保订单消息在一定时间后自动过期。
4.创建一个消费者,监听新订单消息队列。当收到新订单消息时,启动一个定时器,等待订单的超时时间。
5.如果订单在超时时间内未支付,定时器触发后,消费者将发送一个取消订单消息到取消订单消息队列。
6.创建另一个消费者,监听取消订单消息队列。当收到取消订单消息时,执行相应的取消订单逻辑,如更新订单状态为取消,释放相关资源等。
通过上述步骤,可以实现超时未支付订单的自动取消功能。关键在于利用RabbitMQ的消息过期机制和延时消息的特性,配合消费者的定时器,确保在订单超时后触发取消订单的操作。这样可以减少系统的负载,提高订单处理的效率,并自动处理超时未支付的订单。
public class TimeoutOrderCancellation {
private static final String NEW_ORDER_QUEUE = "new_orders";
private static final String CANCEL_ORDER_QUEUE = "cancel_orders";
private static final Map<String, Timer> orderTimers = new HashMap<>();
public static void main(String[] args) throws Exception {
ConnectionFactory factory = new ConnectionFactory();
factory.setHost("localhost");
// 连接RabbitMQ服务器
Connection connection = factory.newConnection();
Channel channel = connection.createChannel();
// 创建新订单消息队列
channel.queueDeclare(NEW_ORDER_QUEUE, false, false, false, null);
// 创建取消订单消息队列
channel.queueDeclare(CANCEL_ORDER_QUEUE, false, false, false, null);
// 监听新订单消息队列
channel.basicConsume(NEW_ORDER_QUEUE, true, new DefaultConsumer(channel) {
@Override
public void handleDelivery(String consumerTag, Envelope envelope, AMQP.BasicProperties properties, byte[] body) throws IOException {
String order = new String(body, "UTF-8");
System.out.println("Received new order: " + order);
// 获取订单超时时间,假设以秒为单位
long timeout = Long.parseLong(properties.getExpiration());
// 设置定时器,超时后发送取消订单消息
Timer timer = new Timer();
timer.schedule(new TimerTask() {
@Override
public void run() {
try {
// 发送取消订单消息
channel.basicPublish("", CANCEL_ORDER_QUEUE, null, order.getBytes("UTF-8"));
System.out.println("Cancelled order: " + order);
} catch (IOException e) {
e.printStackTrace();
}
}
}, timeout * 1000);
// 将订单定时器添加到Map中,用于支付成功时取消定时器
orderTimers.put(order, timer);
}
});
// 监听取消订单消息队列
channel.basicConsume(CANCEL_ORDER_QUEUE, true, new DefaultConsumer(channel) {
@Override
public void handleDelivery(String consumerTag, Envelope envelope, AMQP.BasicProperties properties, byte[] body) throws IOException {
String order = new String(body, "UTF-8");
System.out.println("Cancelled order: " + order);
// 执行取消订单逻辑
cancelOrder(order);
}
});
// 模拟订单支付成功
String paidOrder = "123456"; // 假设订单号为"123456"
// 执行订单支付逻辑
// ...
// 取消对应订单的定时器
Timer timer = orderTimers.get(paidOrder);
if (timer != null) {
timer.cancel();
orderTimers.remove(paidOrder);
}
}
private static void cancelOrder(String order) {
// 执行取消订单逻辑
System.out.println("Canceling order: " + order);
// ...
}
}
在上述代码中,添加了一个orderTimers的HashMap用于存储订单号和对应的定时器对象。当收到新订单消息时,创建订单对应的定时器,并将其存储在orderTimers中。当订单支付成功时,根据订单号取消对应的定时器,以防止订单被误取消。
请注意,在实际应用中,可能需要根据具体的业务逻辑和需求进行调整和完善。