sequence2sequence
1. 基本模型
所谓的Seq2seq模型从字面上理解很简单,就是由一个序列到另一个序列的过程(比如翻译、语音等方面的应用):

那么既然是序列模型,就需要搭建一个RNN模型(神经单元可以是GRU模型或者是LSTM模型)
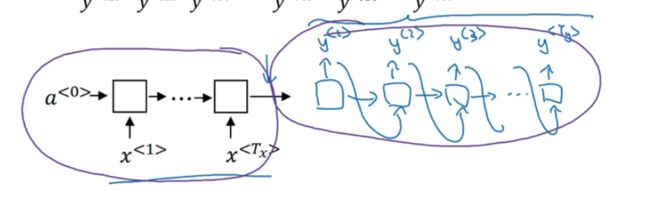
下面两篇文章提出了这样的seq2seq的模型设计,引入了encode和decode机制。
[Sutskever et al.,2014.Sequence to sequence learning with neural networks]
[Cho et al., 2014.Learning phrase representations using RNN encoder-decoder for statistical machine translation]
同样类似的设计方法还有image2sequence
就是根据一张图片来生成文字,效果如下图所示:

那么根据上图中的网络结构可以看出,就是先用一个ALexnet(去掉最后的softmax)的输出作为RNN的输入,进而输出文字。
下面是三篇文章介绍了这个工作。
[Mao et.al.,2014. Deep captioning with multimodal recurrent neural networks]
[[Vinyals et.al.,2014.Show and tell: Neural image caption generator]
[Karpathy and Fei Fei, 2015.Deep visual-semantic alignments for generating image descriptions]
2. 选择最可能的句子
先说一下这个标题的意思,为什么说是“选择最可能的句子”?
因为在翻译的过程中,比如谷歌翻译就是会翻译出3个左右的结果让用户来选择,至于哪一个是最优的结果,算法只能根据概率来推断。因此说是“选择最可能的句子”。
言归正传,机器翻译的模型和我们前面讲到的语言模型有很多相似的地方,同时也有很多重要的区别,下面就来看看有什么地方的异同点。
从下面的模型中可以看出:
- 语言模型是根据一个零向量作为的输入,然后去预测的结果;
- 机器翻译的模型是有一个编码器(会生成一系列的向量结果)和译码器组成的,其中译码器就是是语言模型的框架,因此也叫做
条件语言模型。
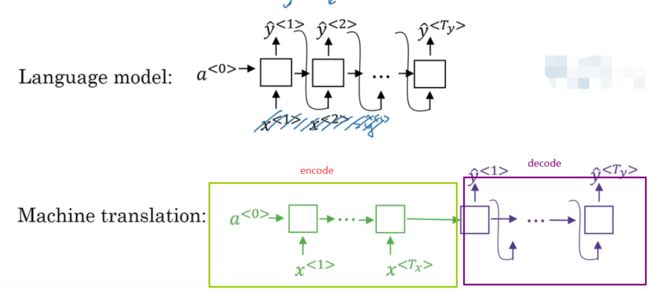
我们以翻译法语到英语的例子为例,说一说什么是“选择最可能的句子”的含义,以及如何选择“最可能”的句子。
如下图所示,X是入门输入的法语,Y是我们需要翻译出来的结果,那么这个结果有很多种。

那么如何选择最优的结果就是算法需要衡量的。

那么根据解码器输出的结果(是一个softmax分类的结果),假设我们的字典中有10000个,那么最后的输出结果是10个单词左右,如何选择最优的翻译结果呢(不可能是全部的排列组合,这样的计算量是 1000 0 10 10000^{10} 1000010)?
有一种很容易就可以想到的方法就是,每次选择预测结论更大的,这样最后的概率乘积结果也是最大的(看上图的最后面提到的公式),这样做是否是可行的呢,看下面的例子:
我们从概率的角度上来考虑的话,肯定是第二个翻译的结果的概率成绩是最大的,因为 P ( v i s i t i n g ∣ J a n e , i s ) < P ( g o i n g t o b e ∣ J a n e i s ) P(visiting| Jane, is)
但是从语义结果上来看就发现第一个句子更加简单,那么就出现了我们前面提到的问题——如何选择一个最可能的结果呢?其实有一种近似的搜索算法可以达到比较好的翻译结果,那就是——Beam search。
3. Beam search
不仅仅是考虑第二个单词最大的可能性,还需要考虑第一个单词和第二个单词对的最大可能性(本质上还是利用了贪心的思想)。
- 第一步
Beam search算法的第一步就是需要定一个Beam width,这个变量是用于确定每一步选择前Beam width个最大的概率的结果。
在下面的步骤中,我们定义Beam width的宽度是3,这就意味着该算法需要考虑前三个可能性。
假设我们有10000个单词,那么第一步就是让decode部分来输出整个词库的可能性,然后选取概率最大的前三个作为结果(假设选择了in,jane,september),并存入内存中,进行下一步的分析。

- 第二步
第二步就是需要用到第一步中保存的三个信息,我们要考虑一个联合的概率问题,就是让解码器的第一个输出设定为我们第一步选择的单词,比如当判断单词in的时候,设定 y ~ < 1 > \tilde y^{<1>} y~<1>=in,效果如下图所示。
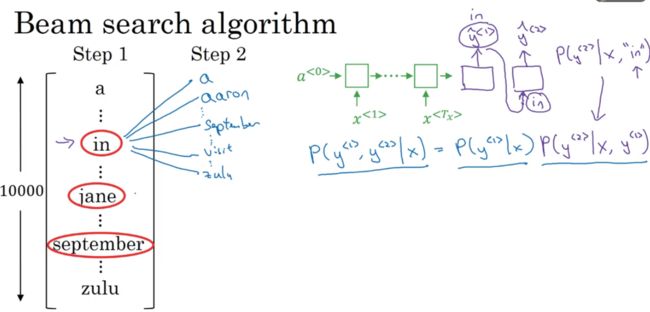
那么这次就获得了所有的第一个单词为in的前提下,10000个单词的所有概率结果。同理,剩下的单词也是做同样的处理。
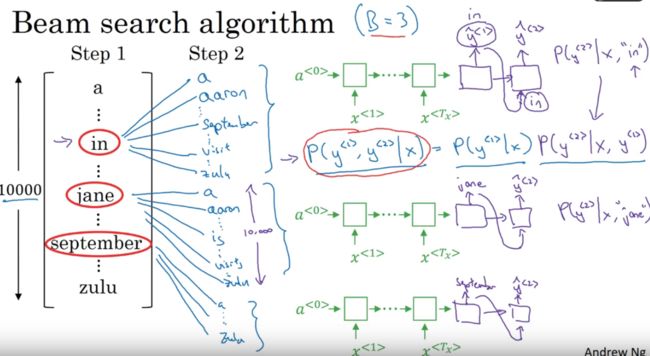
这样就获得了30000个概率,然后再选择概率最大的前三个作为下一步的输入。
- 第三步
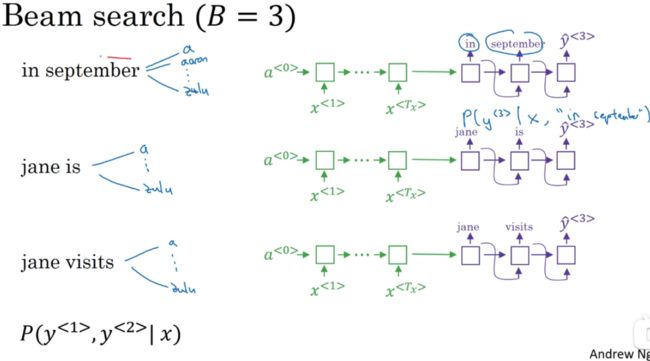
剩下的就是每一步重复添加一个单词,然后输出最后的结果。
当然目前这个算法还是有一些改进的地方的,这里就不阐述了。
4.误差分析
我们在使用Beam search的时候,难免会做误差分析,因为我们想知道预测结果不如意的原因是怎么回事,到底是RNN的结构出了问题还是Beam search算法出了问题需要调参等等。
那么具体来说如何判断呢?
看下面的例子,假设模型输出的结果是 y ^ \hat{y} y^,人工翻译的结果是 y ∗ y^{*} y∗

可以看出,模型输出的效果不尽如意,因此我们需要做一个误差分析。
具体的工作是这样的,我们将 y ^ \hat{y} y^和 y ∗ y^{*} y∗两个输出序列分别在decode里面做概率的乘积计算,最后发现结果是有两种可能情况的,一种是 P ( y ^ ∣ x ) > P ( y ∗ ∣ x ) P(\hat{y}|x)>P(y^{*}|x) P(y^∣x)>P(y∗∣x);另一种结果就是 P ( y ^ ∣ x ) < P ( y ∗ ∣ x ) P(\hat{y}|x)
那么这两种结果分别是什么意思呢?

那么上图只是一个过程,整个分析过程应该如下图所示:

通过分析整篇文章的句子来得出一个结论表格,通过这个表格来分析出是RNN(简称R)的出错比例大,还是Beam search(简称B)的出错比例大,从而有针对性的解决这个问题。
如何判断一个翻译结果的好坏,其实是有一个叫做BLEU得分的东西来评判的。这里就先不做出阐述。有时间再去看了。https://zhaojichao.blog.csdn.net/article/details/106649367
5. Attention model intuition(直观上)
什么是注意力机制呢?
注意力模型源于[Bahdanau et.al.,2014.Neural machine translation by jointly learning to align and translate]虽然这个模型源于机器翻译,但它也推广到了其他应用领域。吴老师认为在深度学习领域,这个是个非常有影响力的,非常具有开创性的论文。
看下面的这个例子,我们知道,前面一直在说的机器翻译的过程是一个将所有文本记住,然后输出的过程,但是对于人来说并非这样的,也不现实。人翻译的时候是根据自己注意的地方来一点点翻译的,因此注意力机制就是仿照着这样的思想来实现的。

下面就举一个简单的例子来从直观上理解Attention机制的工作过程。
还是一个法语的句子,这里先使用一个双向RNN(Bidirectional RNN)来作为生成法语单词的特征集。
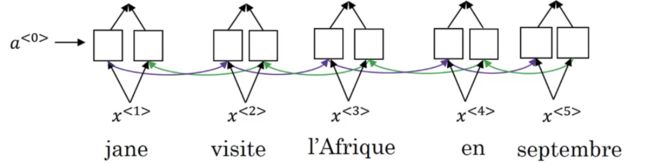
我们要对单词做的就是,对于句子里的每五个单词,计算一个句子中单词的特征集,也有可能是周围的词,让我们试试,生成英文翻译。
我们将使用另一个RNN生成英文翻译,这是我平时用的RNN记号。不用 A 来表示感知机(the activation),这是为了避免和这里的感知机(the activations)混淆。会用另一个不同的记号,我会用 S来表示RNN的隐藏状态(the hidden state in this RNN),不用 A < 1 > A ^{< 1 >} A<1>,而是用 $ S^{<1>}$
我们希望在这个模型里第一个生成的单词将会是Jane,为了生成Jane visits Africa in September。于是等式就是,当你尝试生成第一个词,即输出,那么我们应该看输入的法语句子的哪个部分?似乎你应该先看第一个单词,或者它附近的词。但是你别看太远了,比如说看到句尾去了。
所以注意力模型就会计算注意力权重(a set of attention weights):
- 我们将用 a < 1 , 1 > a^{<1,1>} a<1,1>来表示当你生成第一个词时(或者说在第1步的时候)你应该放多少注意力在这个第一块信息处。
- a < 1 , 2 > a^{<1,2>} a<1,2> 它告诉我们当你尝试去计算第一个词Jane时,我们应该花多少注意力在输入的第二个词上面.
- 同理 a < 1 , 3 > a^{<1,3>} a<1,3>就是预测第一个单词的是,应该在第3个单词上投放多少注意力。
RNN的第二步,我们将有一个新的隐藏状态 S < 2 > S^{<2>} S<2>,我们也会用一个新的注意力权值集(a new set of the attention weights),我们将用 a < 2 , 1 > a^{<2,1>} a<2,1> 来告诉我们在生成第二个词, 应该花多少注意力在输入的第一个法语词上。然后同理 a < 2 , 2 > a^{<2,2>} a<2,2>也是跟第一步中讨论的一样。接下去也同理。
不过和第一步不同的地方就是,我们需要将第一步的结果作为输入传给隐藏状态 S < 2 > S^{<2>} S<2>。
这一节主要是说了关于注意力模型的一些直观的东西。我们现在可能对算法的运行有了大概的感觉,下一节将会说一些细节的东西。
注意:上面图中这样的双层图,其实就是encode和decode的变形,只不过没有那样画出来罢了,如果按照下图中这样来画,那么就更好理解了。


注意力模型可以看作一种通用的思想,本身并不依赖于特定框架,这点需要注意。
比如如果Source是中文句子,Target是英文句子,那么这就是解决机器翻译问题的Encoder-Decoder框架;如果Source是一篇文章,Target是概括性的几句描述语句,那么这是文本摘要的Encoder-Decoder框架;如果Source是一句问句,Target是一句回答,那么这是问答系统或者对话机器人的Encoder-Decoder框架。由此可见,在文本处理领域,Encoder-Decoder的应用领域相当广泛。
Encoder-Decoder框架不仅仅在文本领域广泛使用,在语音识别、图像处理等领域也经常使用。比如对于语音识别来说,图2所示的框架完全适用,区别无非是Encoder部分的输入是语音流,输出是对应的文本信息;而对于“图像描述”任务来说,Encoder部分的输入是一副图片,Decoder的输出是能够描述图片语义内容的一句描述语。一般而言,文本处理和语音识别的Encoder部分通常采用RNN模型,图像处理的Encoder一般采用CNN模型。
6. Attention model detail(细节上)
我们还是回归到下面的这个图上:
对这个图再做一些细致化的符号说明:
- t ′ t' t′表示输入语句中第t个词;
- a < t ′ > = ( a → < t ′ > , a ← < t ′ > ) a^{
- α < t , t ′ > \alpha^{
- C表示隐藏层的输入的上下文,其中 C < 1 > = ∑ t ′ α < t , t ′ > a < t ′ > C^{<1>}=\sum_{t'}\alpha ^{
那么详细的过程如下图(仅考虑第1步的输出过程):

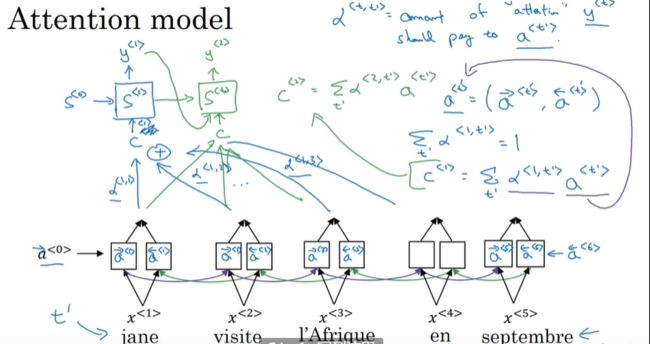
第2步,第3步……的过程以此类推。
那么现在出现了一个细节需要考虑的就是,权重 α < t , t ′ > \alpha^{
还是先回归定义:
![]()
再放公式:
α < t , t ′ > = e x p ( e < t , t ′ > ) ∑ t ′ = 1 T x e x p ( e < t , t ′ > ) \alpha^{
仔细观察,其实就是一个softmax层的输出(这也就解释了为什么 ∑ t ′ α < t , t ′ > = 1 \sum_{t'}\alpha^{
那么e这个项是怎么计算的呢?
是通过一个小的神经网络(有的地方采用了函数操作)来实现组合:
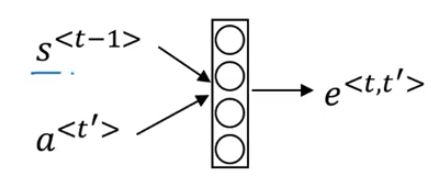
就是采用前一个状态的输出来于这次的输入做某种运算,从而得到了e。
这篇文章讲到了注意力机制在翻译中的应用:[Bahdanau et. al.,2014.Neural machine translation by jointly learning to align and translate]
这篇文章讲到了注意力机制在图像中的应用:[Xu et. al., 2015.Show, attend and tell:Neural image caption generation with visual attention]-
至此注意力机制的概念,简单地介绍完了,但是还是有一些不太理解的地方,比如如何求出e的,权重是怎么求的,如何从抽象的角度上理解,为此我准备写一篇关于【注意力机制】的文章。
u et. al.,2014.Neural machine translation by jointly learning to align and translate]
这篇文章讲到了注意力机制在图像中的应用:[Xu et. al., 2015.Show, attend and tell:Neural image caption generation with visual attention]-
至此注意力机制的概念,简单地介绍完了,但是还是有一些不太理解的地方,比如如何求出e的,权重是怎么求的,如何从抽象的角度上理解,为此我准备写一篇关于【注意力机制】的文章。