sql优化基数和耗费_基数估计在SQL Server优化过程中的位置
sql优化基数和耗费
In this blog post, I’m going to look at the place of the Cardinality Estimation Process in the whole Optimization Process. We’ll see some internals, that will show us, why the Query Optimizer is so sensitive to the cardinality estimation. To understand that we should observe the main steps that a server performs when the query is sent for execution.
在这篇博客文章中,我将介绍基数估计过程在整个优化过程中的位置。 我们将看到一些内部结构,这些内部结构将向我们展示查询优化器为何对基数估计如此敏感。 为了理解这一点,我们应该观察发送查询执行时服务器执行的主要步骤。
计划施工过程 (Plan Construction Process)
Below you may see the picture of the general plan-building process in SQL Server from the moment when a server receives a query till the storage engine is ready to retrieve the data. Take a quick look first, and next I’ll provide explanations.
从服务器接收查询到存储引擎准备好检索数据的那一刻,您可能会在下面看到SQL Server中总体计划制定过程的图。 首先快速看一下,接下来我将提供解释。
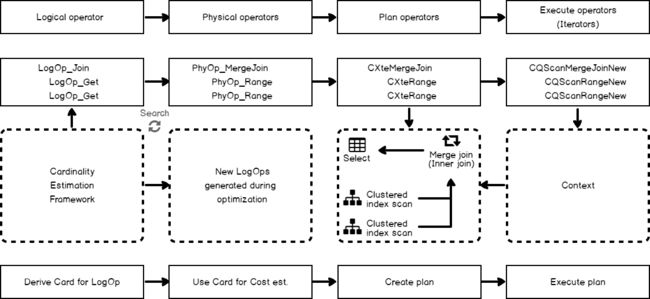
There are a lot of nuances and sub-steps left behind this illustration, but they are not important here.
此插图后面有许多细微差别和子步骤,但在这里并不重要。
From the cardinality estimation prospection the process consists of the four main steps:
从基数估计的前景来看,该过程包括四个主要步骤:
- Derive cardinality for the logical operators 逻辑运算符的派生基数
- Use cardinality to cost the physical operators 使用基数为物理运营商带来成本
- Pick the most cheap physical operators and build a compiled plan 选择最便宜的物理操作员并制定汇总计划
- Convert a compiled plan to an executable plan 将已编译的计划转换为可执行计划
Now, let’s talk about each step of this process in more details.
现在,让我们更详细地讨论此过程的每个步骤。
Logical Operators Tree
逻辑运算符树
The process begins when the query is first sent to a server. When it is received and read from the TDS protocol, the Parser component comes in. It validates text and parses it into a query tree of logical operators (the other actions are also done on that stage like binding, view or computed columns expansion and so on). You may see the tree as the first green block in the picture.
当查询第一次发送到服务器时,该过程开始。 收到TDS协议中的内容并从中读取时,Parser组件就会进入。它会验证文本并将其解析为逻辑运算符的查询树(其他操作也在该阶段完成,例如绑定,视图或计算列扩展等上)。 您可能会看到树是图片中的第一个绿色块。
Next, this tree is simplified (also a lot of work is done here, but not relevant to the post’s topic and abandoned). After that, the first, initial cardinality estimation occurs. It should be done very early to determine the initial join order, that order might be next modified during the query optimization.
接下来,简化这棵树(这里也完成了很多工作,但与帖子主题无关,因此被放弃了)。 之后,首先进行初始基数估计。 应该非常早地确定初始连接顺序,该顺序可能会在查询优化期间进行下一步修改。
You may observe this tree using undocumented TF 8606, to add some details about cardinality estimation to that output this TF might be combined with another undocumented flag TF 8612. It is interesting to include the TF 2372, that outputs some optimization stage memory info and may be used to view some details about the process. We also need TF 3604 to direct output to console.
您可能会使用未记录的TF 8606观察这棵树,向该输出添加有关基数估计的一些详细信息,该TF可能会与另一个未记录的标志TF 8612结合使用。有趣的是,TF 2372包含了输出一些优化阶段的内存信息,并且可能用于查看有关该过程的一些详细信息。 我们还需要TF 3604将输出定向到控制台。
Let’s perform a simple query in the “opt” database, using these flags:
让我们使用以下标志在“ opt”数据库中执行一个简单的查询:
use opt;
go
set showplan_xml on
go
select * from t1 join t2 on t1.a = t2.b
option
(
querytraceon 3604, -- Output to console
querytraceon 2372, -- Optimization stage memory info
querytraceon 8606, -- Logical operators trees
querytraceon 8612 -- Add aditional cardinality info
)
go
set showplan_xml off
go
Now, if you switch to the Message tab in SQL Server Management Studio, you may observe various trees of logical operators. Each tree representation in this diagnostic output reflects the result of the particular plan constructing phase. I’ve described each of them a few years ago in my Russian blog and hope there will be time to do the same in this blog, however not now, because it is not relevant to the topic. If you are interested, you may look through my presentation from SQL Saturday 178, to have an idea what’s going on.
现在,如果切换到SQL Server Management Studio中的“消息”选项卡,则可能会观察到各种逻辑运算符树。 诊断输出中的每个树表示均反映了特定计划构建阶段的结果。 几年前,我已经在我的俄语博客中描述了它们中的每一个,希望该博客中有时间做同样的事情,但是现在不行,因为它与该主题无关。 如果您有兴趣,您可以浏览我在SQL Saturday 178上的演讲,以了解发生了什么。
Here, our focus is on cardinality estimation and we are interested in two outputs Simplified Tree (the tree after various simplifications, e.g. contradiction detection or redundancy removing) and Join-collapsed Tree (the tree after initial join reordering and removing unnecessary joins).
在这里,我们的重点是基数估计,并且我们对两个输出“简化树”(经过各种简化后的树,例如,冲突检测或冗余删除)和“连接折叠树”(初始连接重新排序并删除不必要的连接后的树)感兴趣。
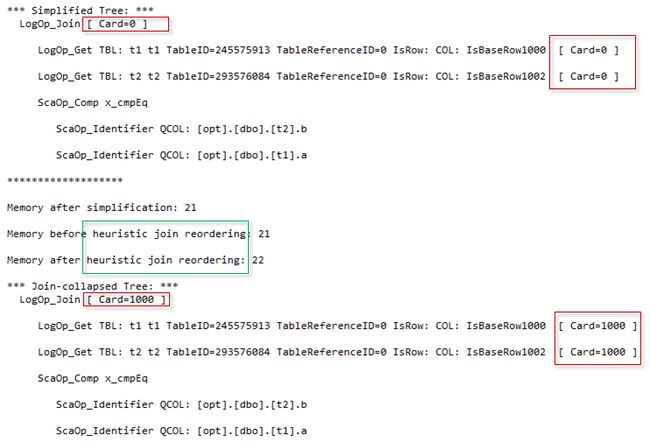
You may notice that Simplified Tree has cardinality equals zero ([Card = 0]), and Join-collapsed tree already has cardinality set to 1000 ([Card = 1000]). Between the two moments, when those trees were output the cardinality estimation process occured.
您可能会注意到,简化树的基数等于零([Card = 0]),并且Join-collapsed树已经将基数设置为1000([Card = 1000])。 在这两个时刻之间,当输出这些树时,便进行了基数估计过程。
It should be done before join reordering and it makes sense, because the optimizer may apply reordering heuristics only after it knows what is the expected cardinality and what join order is expected to be better. Later, during the optimization, the initial join order might be changed using various exploration rules, but the more Joins there are, the less percent of changes of the initial order is expected.
这应该在联接重新排序之前完成,并且这样做很有意义,因为优化器只有在知道什么是预期的基数以及期望哪种联接顺序更好之后才可以应用重新排序试探法。 稍后,在优化过程中,可以使用各种探索规则来更改初始联接顺序,但是联接越多,则预期初始顺序变化的百分比就越小。
This step is depicted as the first, the green one, in the picture above.
在上图中,此步骤被描述为第一个步骤,即绿色步骤。
- LogOp_Get – stands for the logical operation get a table LogOp_Get –代表逻辑操作获取表
- LogOp_Join – stands for the logical operation inner join
- LogOp_Join –代表逻辑操作内部联接
- ScaOp_Comp x_cmpEq – stands for scalar operator compare equal, because we have an equality in the join ON clause ScaOp_Comp x_cmpEq –表示标量运算符比较相等,因为我们在join ON子句中具有相等
- ScaOp_Identifier – stands for the column identifier because we joined on two columns ScaOp_Identifier –代表列标识符,因为我们在两列上联接
Physical Operators Tree
物理操作员树
Next goes the optimization itself. A lot of alternatives are explored, among them are physical implementations of the logical operators (e.g. Logical inner join to Physical inner merge join), new logical operators, that are equivalent to the one we have so far (e.g. A join B to B join A), or completely new logical operators. You may see this tree as the red block in the picture.
接下来是优化本身。 探索了许多替代方法,其中包括逻辑运算符的物理实现(例如,逻辑内部联接到物理内部合并联接),新的逻辑运算符,它们等效于我们到目前为止所拥有的(例如,A联接B到B联接) A)或全新的逻辑运算符。 您可能会将此树视为图片中的红色块。
On that stage cardinality estimations are also present, if the new logical alternative appears – it should be estimated. It is also very important part, if something goes wrong here all the next optimization process might be useless.
在该阶段,如果出现新的逻辑替代方案,也将提供基数估计–应该对其进行估计。 这也是非常重要的部分,如果这里出了问题,则所有下一个优化过程可能都没有用。
After that server has a Physical Operators tree that was chosen among the others based on a cost. Cost is assigned only to physical operators. It’s also worth saying, that there are a lot of techniques to avoid exploring high cost alternatives or spending a lot of time exploring all the possible plans. You may have heard of pruning, time out, optimization stages and so on.
之后,该服务器具有一个物理操作员树,该树是根据成本选择的。 成本仅分配给物理运营商。 值得一提的是,有很多技术可以避免探索高成本的替代方案,或者花费大量时间探索所有可能的计划。 您可能听说过修剪,超时,优化阶段等。
When this step is completed, a server has a tree of physical operators. We may observe it in the diagnostic output, if we enable TF 8607, similar as we did before for the logical operators tree.
完成此步骤后,服务器将具有物理操作员树。 如果启用TF 8607,我们可能会在诊断输出中观察到它,类似于之前对逻辑运算符树所做的操作。

- PhyOp_MergeJoin x_jtInner 1-M – stands for the physical operator of the one-to-many inner merge join
- PhyOp_MergeJoin x_jtInner 1-M –代表一对多内部合并联接的物理运算符
- PhyOp_Range – stands for the physical data access operator PhyOp_Range –代表物理数据访问运算符
That tree is not the query plan yet. Next comes the rewrite process, that, for example, combines together filters and scan into scan with residual predicate and does some other useful rewrites.
那棵树还不是查询计划。 接下来是重写过程,例如,将筛选器组合在一起,并扫描到带有残留谓词的scan并进行其他一些有用的重写。
Plan Operators Tree
计划运营商树
A plan operator tree, is a structure that we used to call a Compiled Plan and what is saved internally to a plan cache if needed. The other names of this structure are: Query Plan, Execution Plan either Estimated or Actual.
计划运算符树是我们用来调用已编译计划的结构,并且在需要时将其内部保存到计划缓存中。 该结构的其他名称是:查询计划,估计的或实际的执行计划。
When we demand an execution plan, the internal methods of the plan tree nodes are called and return an XML output. That might be interpreted later by the client (SQL Server Management Studio, for example) and show us a graphical view.
当我们需要执行计划时,将调用计划树节点的内部方法并返回XML输出。 客户端(例如,SQL Server Management Studio)稍后可能会对此进行解释,并向我们显示图形视图。
A tale of two different plans
两个不同计划的故事
A small interesting note about the differences between an Estimated Execution Plan and an Actual Execution Plan. In some sources, I saw them treated like separate objects, because they may be different. Well, yes, they may be different, however, they are both Compiled Plans.
关于估算的执行计划和实际的执行计划之间的区别的有趣小注释。 在某些来源中,我看到它们被视为独立的对象,因为它们可能有所不同。 好吧,是的,它们可能有所不同,但是它们都是已编译的计划。
Consider the following example.
考虑以下示例。
use opt;
go
-- Get the Estimated Plan
set showplan_xml on
go
declare @a int = 0;
select *, case when @a = 1 then (select top(1) b from t2) end from t1 option(recompile);
go
set showplan_xml off
go
-- Get the Actual Plan
set statistics xml on
go
declare @a int = 0;
select *, case when @a = 1 then (select top(1) b from t2) end from t1 option(recompile);
go
set statistics xml off
go
The plans would be different:
计划将有所不同:
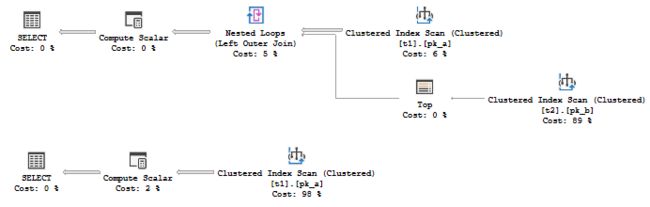
You see, that the second (the Actual one) doesn’t access table t2 at all!
您会看到,第二个(实际的)根本不访问表t2!
This behavior makes people think, that these are two steps of the one process, and that at first server gets the estimated plan and then it gets the actual plan, two different types of plans. If that was true, that would mean that optimization should be done twice!
这种行为使人们认为,这是一个流程的两个步骤,首先,服务器获取了估计的计划,然后又获取了实际的计划,即两种不同类型的计划。 如果这是真的,那意味着优化应该做两次!
If we collect plans with extended events query_post_compilation_showplan and query_post_execution_showplan for the second execution – we will see, that post compilation plan (without any runtime information) has the same shape as the post execution plan and no t2 access.
如果我们为第二次执行收集带有扩展事件query_post_compilation_showplan和query_post_execution_showplan的计划–我们将看到,该后编译计划(不包含任何运行时信息)的形状与该后执行计划相同,并且没有t2访问权限。
The difference between the two plans above appears because of a so called Parameter Embedding Optimization. When option recompile is used at the statement level some kind of a deferred compilation is used. Then, when the execution begins, statements in the batch or module are executed one by one until the deferred recompilation statement is achieved. At that moment all the local variables are known and might be embedded into the query as a run-time constants, with this new constants the recompilation occurs.
上面两个计划之间的差异是由于所谓的参数嵌入优化而出现的。 在语句级别使用选项重新编译时,将使用某种延迟的编译。 然后,当开始执行时,批处理或模块中的语句将一一执行,直到获得延迟的重新编译语句为止。 在那一刻,所有局部变量都是已知的,并且可能作为运行时常量嵌入到查询中,使用此新常量将进行重新编译。
You may think of the recompiling query as if @a was replaced by its run-time value 0:
您可能会认为重新编译查询就像@a被其运行时值0代替:
select *, case when 0 = 1 then (select top(1) b from t2) end from t1 option(recompile);
Obviously, condition 0 = 1 could not ever be true, and it is safely removed at the simplification phase. This optimization may be also applied in the where clause, order by clause, join on clause etc.
显然,条件0 = 1永远不可能成立,因此在简化阶段可以安全地将其删除。 此优化还可以应用于where子句,order by子句,join on子句等。
It is interesting to note, that a plan with an option recompile is cached together with the whole batch plan. That is another proof that there is no special Estimated and Actual plans.
有趣的是,带有选项重新编译的计划与整个批处理计划一起缓存。 这是没有特别的估计和实际计划的另一个证明。
Look at the following example. There is a batch containing three statements, the first one is a declare, the second one is a Join without any recompilation, and the third is a statement with an option recompile.
看下面的例子。 有一个批处理,包含三个语句,第一个是声明,第二个是不重新编译的Join,第三个是带有选项重新编译的语句。
Let’s demand estimated plan, then execute it and demand estimated plan again.
让我们需求估算计划,然后执行它并再次需求估算计划。
dbcc freeproccache;
go
--Demand estimted plan: first time
set showplan_xml on
go
declare @a int = 0;
select * from t1 join t2 on t1.a = t2.b; --Statement to be cached
select *, case when @a = 1 then (select top(1) b from t2) end from t1 option(recompile); --Statement to be recompiled
go
set showplan_xml off
go
-- Execute
go
declare @a int = 0;
select * from t1 join t2 on t1.a = t2.b; --Statement to be cached
select *, case when @a = 1 then (select top(1) b from t2) end from t1 option(recompile); --Statement to be recompiled
go
--Demand estimted plan: second time
set showplan_xml on
go
declare @a int = 0;
select * from t1 join t2 on t1.a = t2.b; --Statement to be cached
select *, case when @a = 1 then (select top(1) b from t2) end from t1 option(recompile); --Statement to be recompiled
go
set showplan_xml off
go
(Note, that a batch should be the same every time, that’s why I put the comment Execute in a separate batch, splitting with GO)
(请注意,每个批次的批次应该相同,这就是为什么我将注释Execute放在一个单独的批次中,并用GO拆分的原因)
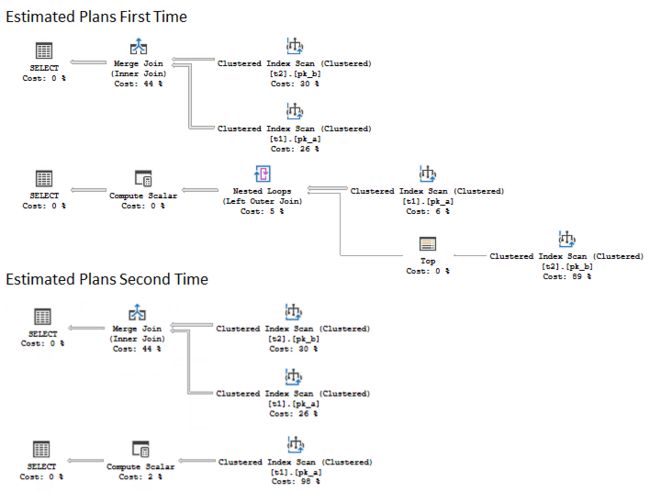
Surprisingly, we may see that the pair of the estimated execution plans, that was demanded after the execution has the different plan for the second query. It is the compiled plan, that was cached after recompilation during the execution. Interesting to note, that if you inspect the property of the SELECT language element (the green icon) in the second plan, you will find the property “RetrievedFromCache” set to “false”, however, if you inspect the plan cache:
出乎意料的是,我们可能会看到在执行之后需要的一对估计的执行计划对第二个查询具有不同的计划。 它是已编译的计划,是在执行期间重新编译后缓存的。 有趣的是,如果您在第二个计划中检查SELECT语言元素的属性(绿色图标),则会发现属性“ RetrievedFromCache”设置为“ false”,但是,如果您检查计划缓存,则:
select
qp.query_plan,
st.[text]
from
sys.dm_exec_cached_plans cp
cross apply sys.dm_exec_query_plan(cp.plan_handle) qp
cross apply sys.dm_exec_sql_text(cp.plan_handle) st
where
st.[text] like '%Statement to be cached%' and
st.[text] not like '%dm_exec_cached_plans%'
Both plans will be returned.
这两个计划都将退还。
I think that is enough to demonstrate that there is no two separate different plans like Estimated and Actual. These terms are a little bit confusing (implying the difference, according to the title), but very widespread. In the new Extended Events mechanism, the plans are called in a more correct way: post compilation, pre execution, post execution. I simply call it a compiled plan. An actual plan is an XML or text representation of a compiled plan with additional run-time info.
我认为这足以证明没有两个单独的不同计划,例如“估计”和“实际”。 这些术语有些令人困惑(根据标题,这意味着区别),但是非常普遍。 在新的扩展事件机制中,将以更正确的方式调用计划:后编译,预执行,后执行。 我只是称其为已编译的计划。 实际计划是带有附加运行时信息的已编译计划的XML或文本表示。
That’s what a Compiled Plan is, but still, it is still not what would make the actual iterations over rows.
那就是编译计划,但仍然不是行实际迭代的原因。
Executable Operators Tree (Iterators Tree)
可执行运算符树(迭代器树)
When a plan is compiled and should be next executed, server turns a Compiled Plan into an Executable Plan (don’t mix it with an Actulal Execution Plan), also known as an Execution Context.
当计划被编译并应在下次执行时,服务器将已编译的计划转换为可执行计划(不要将其与实际执行计划混合),也称为执行上下文。
There might be one compiled plan, but several executable plans. That makes sense as there might be multiple users who want to execute the same query. Also, the query may have variables and each user may provide specific values for them. That should be considered in the execution, and so, the execution context is built.
可能有一个已编译的计划,但有多个可执行计划。 这很有意义,因为可能有多个用户想要执行同一查询。 同样,查询可能具有变量,并且每个用户都可以为其提供特定的值。 在执行中应该考虑这一点,因此,构建了执行上下文。
Also, each execution context might track the actual number of rows or any other execution specific information and combine it with a compiled plan, and so we get back what is called an Actual Plan if we demand.
另外,每个执行上下文可能会跟踪实际的行数或任何其他特定于执行的信息,并将其与已编译的计划结合起来,因此,如果需要,我们可以得到称为实际计划的信息。
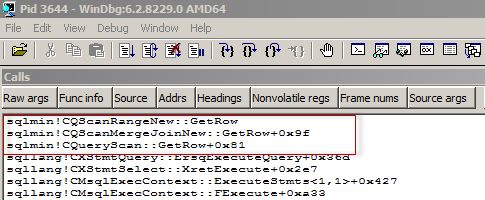
An Executable Plan is represented as the last, purple blocks in the picture. There are no TFs or any other ways to view it directly (or I don’t know them), the only way I know, is to use a debugger with debug symbols.
可执行计划表示为图片中的最后一个紫色块。 没有TF或任何其他直接查看它的方法(或者我不知道它们),我知道的唯一方法是使用带有调试符号的调试器。
I’ll provide a screenshot how it looks like in WinDbg for the illustration.
我将提供一个屏幕截图,以用于WinDbg中的插图。
Back to Cardinality Estimation
返回基数估计
We observed the main optimization process, and learned that the Cardinality Estimation process is used during the very first step and is used next during the second step of a query optimization. If these initial steps produce inaccurate estimates all the next steps and the query execution may be very inefficient due to the inefficient plan. That is why cardinality estimation is so important mechanism in a query optimization process.
我们观察了主要的优化过程,并了解到基数估计过程在查询优化的第一步中被使用,而在查询优化的第二步中被使用。 如果这些初始步骤产生的估算值不准确,则所有后续步骤将由于计划效率低下而导致查询执行效率极低。 这就是为什么基数估计是查询优化过程中如此重要的机制的原因。
The last thing I’d like to mention in that post is that cardinality estimation is done over logical operators only, as we saw. If we think about it – it makes sense. For example, if we join table using Loop Join and get 10 rows, but with Hash Join get 11 rows – obviously, there is something wrong with the join algorithm. It should not work this way.
我在那篇文章中最后要提到的是,基数估计仅在逻辑运算符上完成,如我们所见。 如果我们考虑一下–这是有道理的。 例如,如果我们使用Loop Join联接表并获得10行,而使用Hash Join联接则获得11行–显然,联接算法存在问题。 它不应该这样工作。
Let’s create an index and look at the example.
让我们创建一个索引并查看示例。
create index ix_b on t1(b);
go
set showplan_xml on
go
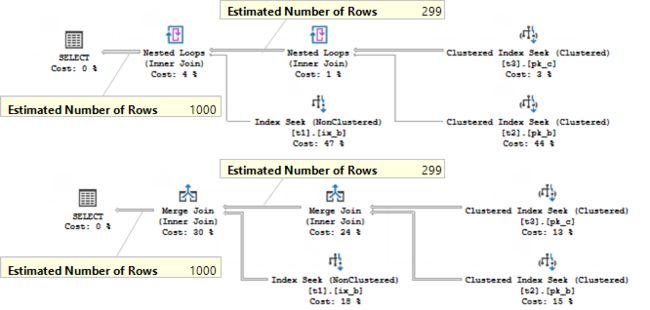
select t1.b, t2.b from t1 join t2 on t2.b = t1.b join t3 on t3.c = t2.b where t1.b < 300 option(loop join)
select t1.b, t2.b from t1 join t2 on t2.b = t1.b join t3 on t3.c = t2.b where t1.b < 300 option(merge join)
go
set showplan_xml off
go
drop index t1.ix_b;
The same query but with different hints for the join algorithm. Every single Join has the same estimates, according to the plans.
相同的查询,但是对连接算法有不同的提示。 根据计划,每个Join都具有相同的估计。
But it is worth to remember that the estimation is dependent of the new logical groups, that may appear during the optimization. If we add some grouping using distinct into this artificial example, we will see, that now estimates of the join types are different.
但是值得记住的是,估计取决于优化过程中可能出现的新逻辑组。 如果我们在此人工示例中使用“ distinct”添加一些分组,我们将看到,现在对连接类型的估计是不同的。
create index ix_b on t1(b);
go
set showplan_xml on
go
select distinct t1.b, t2.b from t1 join t2 on t2.b = t1.b join t3 on t3.c = t2.b where t1.b < 300 option(loop join)
select distinct t1.b, t2.b from t1 join t2 on t2.b = t1.b join t3 on t3.c = t2.b where t1.b < 300 option(merge join)
go
set showplan_xml off
go
drop index t1.ix_b;
You may see that now estimates for the Loops Join and Merge Join are different.
您可能会看到,现在对于循环联接和合并联接的估计是不同的。
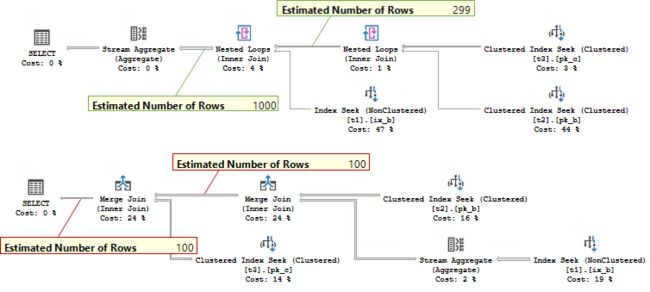
But that is not because the different physical join types are estimated differently, but because the join type drove optimizer to choose another plan shape, and it was considered to be cheaper to perform the aggregation before the Join in case of a Merge Join. That changed cardinality input for the Join and lead to different estimate.
但这不是因为对不同的物理联接类型的估计不同,而是因为联接类型驱使优化器选择其他计划形状,并且在合并联接的情况下,在联接之前执行聚合被认为更便宜。 这改变了Join的基数输入并导致不同的估计。
That’s all for today, in the next post we’ll talk about the cardinality estimation main concepts.
今天就这些了,在下一篇文章中,我们将讨论基数估计的主要概念。
目录 (Table of Contents)
| Cardinality Estimation Role in SQL Server |
| Cardinality Estimation Place in the Optimization Process in SQL Server |
| Cardinality Estimation Concepts in SQL Server |
| Cardinality Estimation Process in SQL Server |
| Cardinality Estimation Framework Version Control in SQL Server |
| Filtered Stats and CE Model Variation in SQL Server |
| Join Containment Assumption and CE Model Variation in SQL Server |
| Overpopulated Primary Key and CE Model Variation in SQL Server |
| Ascending Key and CE Model Variation in SQL Server |
| MTVF and CE Model Variation in SQL Server |
| SQL Server中的基数估计角色 |
| 基数估计在SQL Server优化过程中的位置 |
| SQL Server中的基数估计概念 |
| SQL Server中的基数估计过程 |
| SQL Server中的基数估计框架版本控制 |
| SQL Server中的筛选后的统计信息和CE模型变化 |
| 在SQL Server中加入包含假设和CE模型变化 |
| SQL Server中人口过多的主键和CE模型的变化 |
| SQL Server中的升序密钥和CE模型变化 |
| SQL Server中的MTVF和CE模型变化 |
参考资料 (References)
- Cardinality Estimation (SQL Server) 基数估计(SQL Server)
- SQL Server 2014’s new cardinality estimator (Part 1) SQL Server 2014的新基数估计器(第1部分)
- The New and Improved Cardinality Estimator in SQL Server 2014 SQL Server 2014中的新增和改进的基数估计器
翻译自: https://www.sqlshack.com/cardinality-estimation-place-in-the-optimization-process/
sql优化基数和耗费