Dubbo流程及源码分析(四)
扑街前言:本篇是dubbo的最后一篇文章了,在此对之前dubbo相关的文章做一个总结,第一篇是dubbo的SPI和Java的SPI,第二篇是Spring 集成dubbo和provider 方的启动,接着第三篇就是consumer 方的启动,那么本篇要讲的就是服务调用的全部流程。
InvokerInvocationHandler起始
在上篇文章中我们知道了,consumer 放的启动就是为配置的接口拉取注册中心中的服务信息并生成代理,那么最后包装的代理invoker 就是InvokerInvocationHandler,不管是jdk 还是javassist 去生成代理,最后封装的invoker 都是InvokerInvocationHandler,所以我们要看服务调用的流程话,一定是从这个InvokerInvocationHandler 开始。
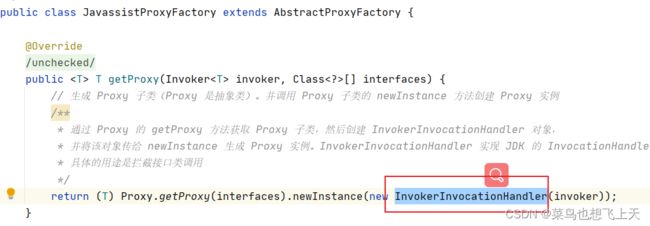
既然只InvokerInvocationHandler 类,那直接搜到具体得代码就行了,InvokerInvocationHandler 就是InvocationHandler 类的实现,那么就可以找到具体的invoke 方法,而这里面也没有什么内容,还是调用invoker 接口的invoke 方法。

还是结合之前的内容,InvokerInvocationHandler 的上一层invoker 封装是什么呢,我们可以找到MockClusterInvoker 的实现。
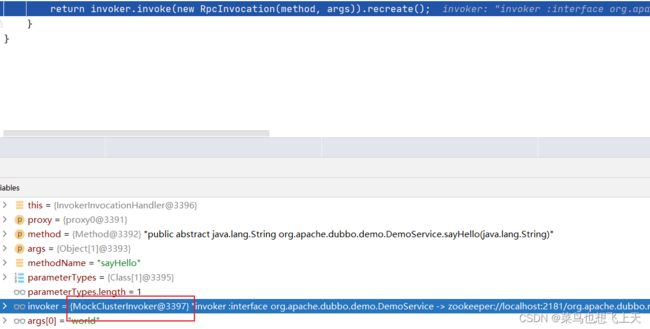
Mock是Cluster层的开始
找到MockClusterInvoker 的具体代码,到了这一层我们就已经到了Cluster 路由层了,在代码中我们是可以找到dubbo 在这一层具体是做了些什么的。
看代码,这里首先就是获取dubbo 的mock 的配置,然后是false 也就是没有配置的话,就是就是下一步;如果是force 的话,那么就是直接执行mock 的逻辑,不发起远程调用;如果都不是,还可以做到服务降级,也就是如果远程调用出错的话,可以做已定义的mock 逻辑。
@Override
/**
* MockClusterInvoker 内部封装了服务降级逻辑
*/
public Result invoke(Invocation invocation) throws RpcException {
Result result = null;
// 获取 mock 配置值
String value = directory.getUrl().getMethodParameter(invocation.getMethodName(), MOCK_KEY, Boolean.FALSE.toString()).trim();
if (value.length() == 0 || value.equalsIgnoreCase("false")) {
//no mock 无 mock 逻辑,直接调用其他 Invoker 对象的 invoke 方法,
// this.invoker= FailoverClusterInvoker extends AbstractClusterInvoker 先执行父类中的 invoke
result = this.invoker.invoke(invocation);
} else if (value.startsWith("force")) {
if (logger.isWarnEnabled()) {
logger.warn("force-mock: " + invocation.getMethodName() + " force-mock enabled , url : " + directory.getUrl());
}
//force:direct mock
// force:xxx 直接执行 mock 逻辑,不发起远程调用
result = doMockInvoke(invocation, null);
} else {
//fail-mock
// fail:xxx 表示消费方对调用服务失败后,再执行 mock 逻辑,不抛出异常
try {
result = this.invoker.invoke(invocation);
} catch (RpcException e) {
if (e.isBiz()) {
throw e;
}
if (logger.isWarnEnabled()) {
logger.warn("fail-mock: " + invocation.getMethodName() + " fail-mock enabled , url : " + directory.getUrl(), e);
}
result = doMockInvoke(invocation, e);
}
}
return result;
}继续还是invoker 的实现调用,而这里就是consumer 启动时封装的具体容错对象,没有配置的情况下就是failover,那么可以继续跟到failoverCluster,因为直接点到invoker 接口是没有找到这个实现类的,所以我们找到对应的父类即可,也就是AbstractClusterInvoker 类,下面看下具体代码。
可以看到的是第一步就是路由,先获取到的invokers,然后在加载具体的负载均衡策略,将策略在传给集群容错的调用,这样下一步就可以直接定位到具体的容错对象,也就是failoverClusterInvoker 类,然后要找到具体的doInvoke 方法。


@Override
public Result invoke(final Invocation invocation) throws RpcException {
checkWhetherDestroyed();
// binding attachments into invocation. 绑定 attachments 到 invocation 中.
Map contextAttachments = RpcContext.getContext().getAttachments();
if (contextAttachments != null && contextAttachments.size() != 0) {
((RpcInvocation) invocation).addAttachments(contextAttachments);
}
// 从 RegistryDirectory 中获取 List 列举,检查Invoker 并进行路由
List> invokers = list(invocation);
// 加载 loadbalance 策略实现 默认加载的是 RandomLoadBalance 实现
LoadBalance loadbalance = initLoadBalance(invokers, invocation);
RpcUtils.attachInvocationIdIfAsync(getUrl(), invocation);
// 调用 doInvoke 进行后续操作 抽象方法由各个子类去实现,默认 FailoverClusterInvoker
return doInvoke(invocation, invokers, loadbalance);
} failoverClusterInvoker 这里代码太多了,我就不一个一个展示了,首先我们要关注的是要通过负载均衡策略去从刚刚上面路由到的invokers 中获取到具体的invoker 对象,然后由具体的invoker.invoke 进行调用返回,这里的invoker 已经是架构图中的cluster 层的最后invoker 对象了,结合架构图这里的invoke 调用时不会直接到DubboInvoker,这里还需要经过一系列的filter 后才能转到DubboInvoker 对象,那么是怎么经过这些filter 的呢?
从架构图中我们可以知道filter 是在protocol 层,而protocol 层也是rpc层,所以我们可以找rpc层的dubbo项目,找到protocol的配置,而在api项目中我们也可以找到相关的配置,在这个配置中我们就可以看到相关的filter 配置了,其实可以看到filter 就是一个wrapper,而在这个ProtocolFilterWrapper 的buildInvokerChain方法中,也就是获取了一系列的filter 从而形成了一个过滤器链,用于包装invoker。

![]()
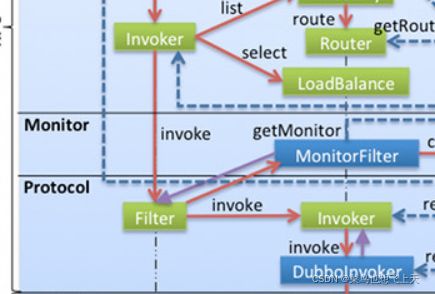
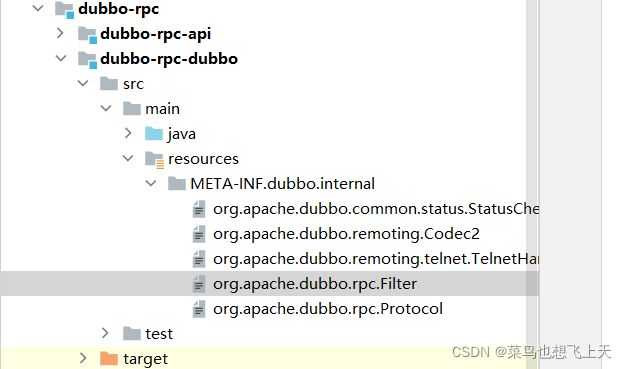


当走过filter 之后,我们就可以得到一个原始的invoker,然后我们就会走到一个叫做AsyncToSyncInvoker 异步转同步的类中,找到对应的invoke 方法,然后到DubboInvoker 的父类AbstractInvoker,然后就是老套路跟到DubboInvoker 的doInvoke 方法,在这里我们基本上就可以看到请求发送的地方了,currentClient 是从连接缓存中获取的,这里是可以做长连接使用的。
这里其实注释也描述了,我们最后会在HeaderExchangeChannel 的request 方法中调用channel.send,这里也是最后走到了NettyChannel的channel.writeAndFlush调用,这个就是真正的netty 服务调用了。到这一步我们已经将exchange 信息交换层的内容走完了,后面就是transport 网络传输层和数据序列化层的内容了。



NettyClient正式开始远程调用
既然我们之前对代理对象封装的就是netty 实现的远程调用,那么我们直接找到NettyClient 类就行,找到doOpen 方法,回想一下我们之前自己编写rpc 框架时,也是使用netty 首先要做的就是一二次编码和解码,然后就是对应的自定义handler,dubbo 也是一样的流程(目前基本上所有的rpc框架都是这个流程),因为我们是consumer 端的调用,那么首先要找的就是对应的编码器,找到NettyClient 中的这段代码,跟进编码器(注意编码器和解码器不要混淆)找到下面这段代码,看到MessageToByteEncoder 对象如果看过我netty 相关的文章这个应该是比较熟悉的,这个是netty 提供的编码器的一种。

private class InternalEncoder extends MessageToByteEncoder {
@Override
protected void encode(ChannelHandlerContext ctx, Object msg, ByteBuf out) throws Exception {
org.apache.dubbo.remoting.buffer.ChannelBuffer buffer = new NettyBackedChannelBuffer(out);
Channel ch = ctx.channel();
NettyChannel channel = NettyChannel.getOrAddChannel(ch, url, handler);
try {
codec.encode(channel, buffer, msg);
} finally {
NettyChannel.removeChannelIfDisconnected(ch);
}
}
}跟进codec.encode 方法,这里会有多个实现,我们要找的是DubboCountCodec,然后跟进是ExchangeCodec 找到对应的请求编码encodeRequest 方法。
到这个地方我们就要讲一个dubbo 基础知识点了,先引入一个dubbo 官网的描述地址:实现细节 | Apache Dubbo,这里可以直观的看到dubbo 的协议头是16个字节,前4个字节中的0和1字节分别存入Magic High、Magic Low、第二号字节(也就是真正的第3个字节)第16个bit 位存是请求还是响应标识,第17个bit 位存入标识是:是否希望响应有返回值,第18个bit 位是标识是否是心态请求,第19到23个bit 位是表示具体的序列化方式,这里的序列化方式有6种,具体的表示可以看文档,最后第3号字节存的就是响应的状态,这个具体的还是看文档,提一个比如:20表示的就是OK;第4到第11号字节(总共就是8个字节)存入的就是请求的唯一键;第12到15号字节存入的就是消息体的长度,这个就是为了解决TCP协议的拆包和沾包问题。
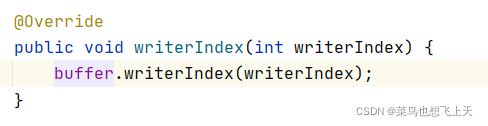
上述就是对于dubbo 定义协议头的方式,我们自己如果需要定义这种协议头的话,就可以参考这个,然后我们继续说代码,我把响应的代码全部粘到下面了,其实就可以看到首先就是封装前16个字节头,然后根据不同的情况继续封装消息体,然后就是封装成不同的对象,然后再次序列化(也就是二次编码),最后用ChannelBuffer 进行写出,这里的writerIndex 方法其实就是调用netty的buffer 对象进行写出的,一个意思。

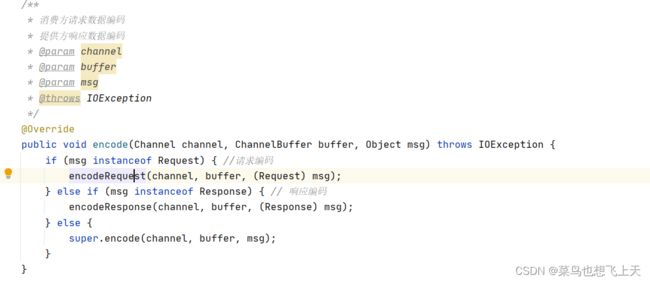

/**
* 请求编码
* @param channel
* @param buffer
* @param req
* @throws IOException
*/
protected void encodeRequest(Channel channel, ChannelBuffer buffer, Request req) throws IOException {
Serialization serialization = getSerialization(channel);
// header. 创建消息头字节数组,长度固定 16 字节,属于定长头+变长体 协议
byte[] header = new byte[HEADER_LENGTH];
// set magic number. 设置2字节魔数
Bytes.short2bytes(MAGIC, header);
// set request and serialization flag. 设置数据包类型(Request/Response)和序列化器编号
header[2] = (byte) (FLAG_REQUEST | serialization.getContentTypeId());
// 设置通信方式(单向/双向)
if (req.isTwoWay()) {
header[2] |= FLAG_TWOWAY;
}
// 设置事件标识
if (req.isEvent()) {
header[2] |= FLAG_EVENT;
}
// set request id. 设置请求id,long类型,8个字节,从第4个字节开始设置
Bytes.long2bytes(req.getId(), header, 4);
// encode request data. 获取 buffer 当前的写位置
int savedWriteIndex = buffer.writerIndex();
// 更新 writerIndex,为消息头预留 16 个字节的空间
buffer.writerIndex(savedWriteIndex + HEADER_LENGTH);
ChannelBufferOutputStream bos = new ChannelBufferOutputStream(buffer);
// 创建序列化器,比如 Hessian2ObjectOutput
ObjectOutput out = serialization.serialize(channel.getUrl(), bos);
if (req.isEvent()) {
// 对事件数据进行序列化操作
encodeEventData(channel, out, req.getData());
} else {
// 对请求数据进行序列化操作 encodeRequestData在子类 DubboCodec 中有实现
encodeRequestData(channel, out, req.getData(), req.getVersion());
}
out.flushBuffer();
if (out instanceof Cleanable) {
((Cleanable) out).cleanup();
}
bos.flush();
bos.close();
// 获取写入的字节数,也就是消息体长度
int len = bos.writtenBytes();
checkPayload(channel, len);
// 将消息体长度写入到消息头中 从第12个字节开始设置,共4字节
Bytes.int2bytes(len, header, 12);
// write 将 buffer 指针移动到 savedWriteIndex,为写消息头做准备
buffer.writerIndex(savedWriteIndex);
buffer.writeBytes(header); // write header. 从 savedWriteIndex 下标处写入消息头
// 设置新的 writerIndex,writerIndex = 原写下标 + 消息头长度 + 消息体长度
buffer.writerIndex(savedWriteIndex + HEADER_LENGTH + len);
}provider方的接收NettyServer的开始
既然已经将消息封装好并写到了channel 中,那么provider 端就是使用netty 来接受了,对了consumer 端还有一个NettyClientHandler 这个就是对于读写的一个封装。我们可以接着看provider 端的接收,直接找打NettyServer 对象的doOpen 方法,还是一样的要做业务处理先解码,我们简单的看下解码器,跟编码器的跟踪方法一直,可以找打ByteToMessageDecoder 的实现,然后可以跟进codec.decode,找到最后的exchangeCodec 实现类,找到对应的解码方式。
具体的解码代码我放在下面了,跟编码的流程是一样的,首选解析前16个字节的消息头,然后就是根据消息头的信息解析对应的消息体,然后将消息体反序列化,然后组装成对应的请求对象。

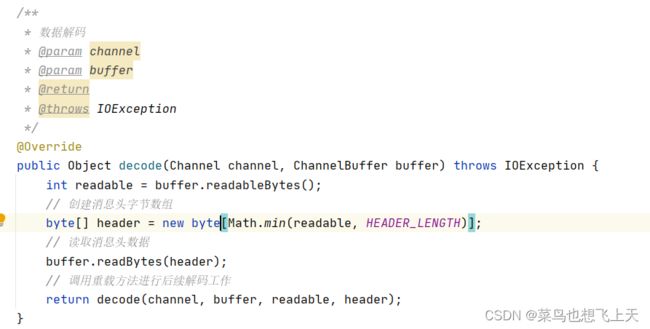
@Override
protected Object decode(Channel channel, ChannelBuffer buffer, int readable, byte[] header) throws IOException {
// check magic number. 检查魔数是否相等
if (readable > 0 && header[0] != MAGIC_HIGH
|| readable > 1 && header[1] != MAGIC_LOW) {
int length = header.length;
if (header.length < readable) {
header = Bytes.copyOf(header, readable);
buffer.readBytes(header, length, readable - length);
}
for (int i = 1; i < header.length - 1; i++) {
if (header[i] == MAGIC_HIGH && header[i + 1] == MAGIC_LOW) {
buffer.readerIndex(buffer.readerIndex() - header.length + i);
header = Bytes.copyOf(header, i);
break;
}
}
// 通过 telnet 命令行发送的数据包不包含消息头,所以这里
// 调用 TelnetCodec 的 decode 方法对数据包进行解码
return super.decode(channel, buffer, readable, header);
}
// check length. 检测可读数据量是否少于消息头长度,若小于则立即返回 DecodeResult.NEED_MORE_INPUT
if (readable < HEADER_LENGTH) {
return DecodeResult.NEED_MORE_INPUT;
}
// get data length. 从消息头中获取消息体长度,从第12个字节处开始的4个字节存储的是消息的长度
int len = Bytes.bytes2int(header, 12);
// 检测消息体长度是否超出限制,超出则抛出异常
checkPayload(channel, len);
int tt = len + HEADER_LENGTH;
// 检测可读的字节数是否小于实际的字节数
if (readable < tt) {
return DecodeResult.NEED_MORE_INPUT;
}
// limit input stream.
ChannelBufferInputStream is = new ChannelBufferInputStream(buffer, len);
try {
// 继续进行解码工作 子类 DubboCodec 重写了 decodeBody 方法
return decodeBody(channel, is, header);
} finally {
if (is.available() > 0) {
try {
if (logger.isWarnEnabled()) {
logger.warn("Skip input stream " + is.available());
}
StreamUtils.skipUnusedStream(is);
} catch (IOException e) {
logger.warn(e.getMessage(), e);
}
}
}
}当解析完成之后,会用ByteToMessageDecoder 提供的out 集合写入到下一层,这里我们就要看对应的NettyServerHandler 了,找到相关的业务处理方法 channelRead方法,然后我们可以跟到HeaderExchangeHandler.received,在这里我们又能发现,当前线程任然是netty的IO线程,但是这里dubbo会将心跳消息进行组装,然后直接返回,至于其余的消息则是根据配置的线程,也就是provider 方的配置,来获取线程分发的方式。(下面图片取自于dubbo官方文档,但是有几点目前不适用于2.7.3的源码,比如心跳在IO线程中已经返回了)
我们之前配置的是message,所以我们要找的Handler 就是MessageOnlyChannelHandler.received,这里我们看它的executor.execute 方法,这里的入参是ChannelEventRunnable 线程,那么有到了老套路环境,是线程就找到它的run 方法,下面我们看下它的代码逻辑。

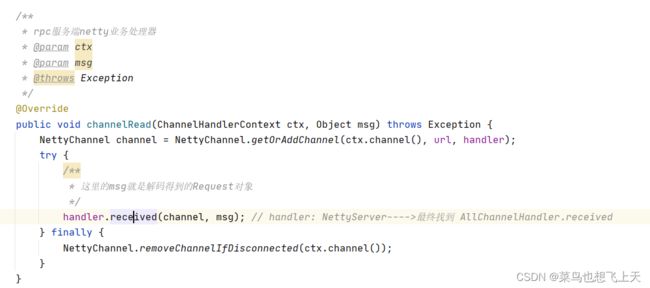
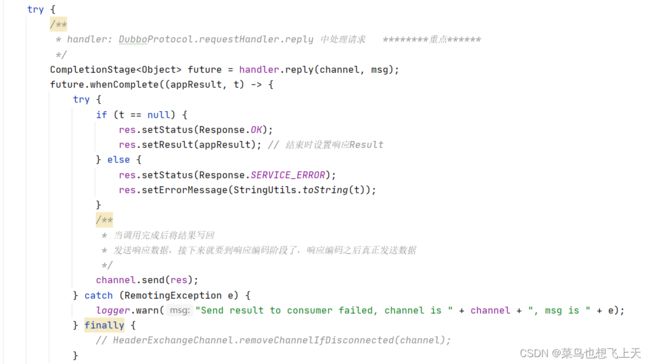
我们这里看下上面所说线程对应的run 方法,其实它所做的也就是一些请求情况的判断,然后调用对应的处理,那么现在就可以走到handler.received 方法里面,这里跟到的是DecodeHanndler,这里就有疑问了,为什么之前已经解码了的,现在又要解码,其实之前的解码只是解码了一部分,请求对象中还有一部分消息没有解码,为的就是防止Netty 中的IO线程出现问题。说会正题,目前再下一步就是HeaderExchangeHandler.received,这里我们可以放心consumer 方和provider 方使用exchange 层传输的对象都是同一个。
其实到这里,我们再结合架构图已经可以发现这里已经形成了一个完成的流程了,exchange 层走完之后,那么就是到了DubboProtocol,然后进过filter 解析为invoker,然后进行真正的远程调整,然后原路返回,这样dubbo 的服务调用过程就结束了。

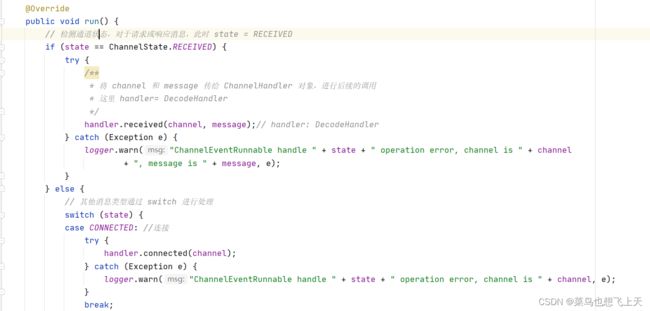
上述就是dubbo 的服务调过程源码解析,其实简单的总结一下就是,provider 方启动时,先启动netty 进行连接绑定,然后连接注册中间,将暴露接口进行服务注册,provider 方启动成功;consumer 方启动时,先将获取注册中心,可以将自己也注册到注册中心上,然后拉去所有暴露接口的注册中心中的服务信息,然后将所有的暴露接口进行封装,其中首先就是封装netty 连接,然后就是容错机制、负载均衡策略、路由策略等等,然后将为装好的invoker 生成代理,consumer 方启动成功;接着就是服务调用,consumer 方进行代理调用,就是一层层解析,然后netty 调用,provider 方监听到连接和读写事件,进行层层解析得到一个具体的invoker,然后就是对invoker 进行对应的业务操作,最后就是走之前启动封装的流程,再将返回对象进行封装,由netty 回写给consumer 方,然后consumer 方又是层层解析,然后给到对应的调用业务,dubbo就此结束。
总结一下最近一段时间的文章,dubbo 算是我自己学习过程中总结的比较完成的系列文章,如果有需要可以跟着我的文章一步一步学习,源码已经放在我的资源里面,有疑问可以留言给我,我看到会尽量回答,愿你我成为技术学习道路上的同行者,当然有大佬看到不对的地方也可以私信我,我会及时改正。