Hive On Spark解析SQL过程剖析
1.Hive执行过程概览
无论Hive Cli还是HiveServer2,一个HQl语句都要经过Driver进行解析和执行,粗略如下图:
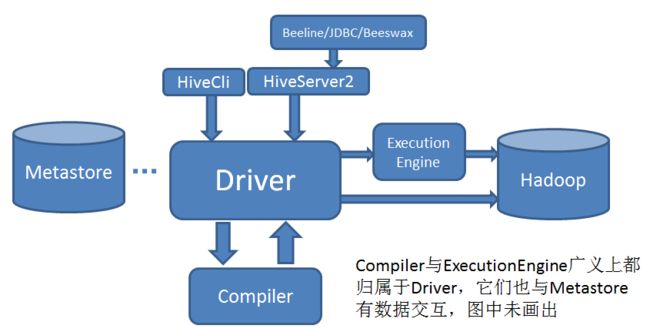
2.Driver处理的流程
HQL解析(生成AST语法树) => 语法分析(得到QueryBlock) => 生成逻辑执行计划(Operator) => 逻辑优化(Logical Optimizer Operator) => 生成物理执行计划(Task Plan) => 物理优化(Task Tree) => 构建执行计划(QueryPlan) => 表以及操作鉴权 => 执行引擎执行
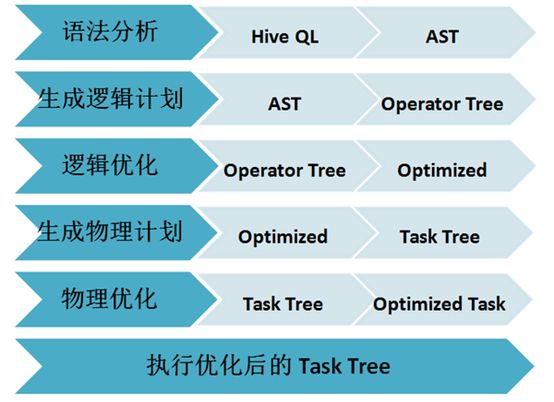
- 语法分析阶段,Hive利用Antlr将用户提交的SQL语句解析成一棵抽象语法树(Abstract Syntax Tree,AST)。
- 生成逻辑计划包括通过Metastore获取相关的元数据,以及对AST进行语义分析。得到的逻辑计划为一棵由Hive操作符组成的树,Hive操作符即Hive对表数据的处理逻辑,比如对表进行扫描的TableScanOperator,对表做Group的GroupByOperator等。
- 逻辑优化即对Operator Tree进行优化,与之后的物理优化的区别主要有两点:一是在操作符级别进行调整;二是这些优化不针对特定的计算引擎。比如谓词下推(Predicate Pushdown)就是一个逻辑优化:尽早的对底层数据进行过滤以减少后续需要处理的数据量,这对于不同的计算引擎都是有优化效果的。
- 生成物理计划即针对不同的引擎,将Operator Tree划分为若干个Task,并按照依赖关系生成一棵Task的树(在生成物理计划之前,各计算引擎还可以针对自身需求,对Operator Tree再进行一轮逻辑优化)。比如,对于MapReduce,一个GROUP BY+ORDER BY的查询会被转化成两个MapReduce的Task,第一个进行Group,第二个进行排序。
- 物理优化则是各计算引擎根据自身的特点,对Task Tree进行优化。比如对于MapReduce,Runtime Skew Join的优化就是在原始的Join Task之后加入一个Conditional Task来处理可能出现倾斜的数据。
- 最后按照依赖关系,依次执行Task Tree中的各个Task,并将结果返回给用户。每个Task按照不同的实现,会把任务提交到不同的计算引擎上执行。
3.Hive On Spark 解析SQL的过程
SELECT NAME,AGE FROM STUDEN WHERE AGE>30;
上边一个简单的sql查询,在分析执行的时候会经历下面所示的几个步骤:
Query=> Parse=> Bind=> Optimize=> Execute
即:语法解析,操作绑定,优化执行策略,交付执行。
3.1 语法解析
语法解析之后,会形成一棵语法树,如下图所示。树中的每个节点是执行的rule,整棵树称之为执行策略。
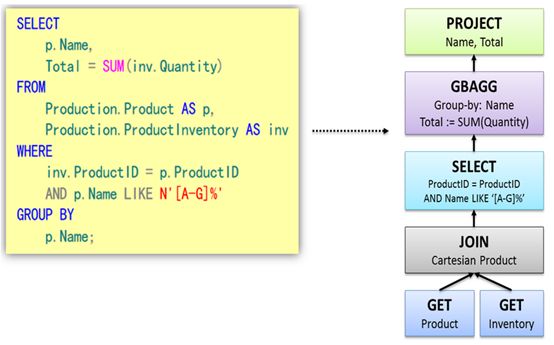
3.2 策略优化
形成上述的执行策略树还只是第一步,因为这个执行策略可以进行优化,所谓的优化就是对树中节点进行合并或是进行顺序上的调整。以大家熟悉的join操作为例,下图给出一个join优化的示例。A JOIN B等同于B JOIN A,但是顺序的调整可能给执行的性能带来极大的影响,下图就是调整前后的对比图。
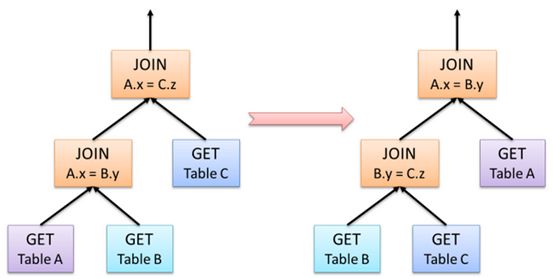
在Hash Join中,首先被访问的表称之为“内部构建表”,第二个表为“探针输入”。创建内部表时,会将数据移动到数据仓库指向的路径;创建外部表,仅记录数据所在的路径。
3.3 HQL
HiveContext是Spark提供的用户接口,HiveContext继承自SqlContext。
既然是继承自SqlContext,那么我们将普通sql与hiveql分析执行步骤做一个对比,可以得到下图。

HiveQL是整个的入口点:
def hiveql(hqlQuery: String): SchemaRDD = {
val result = new SchemaRDD(this, HiveQl.parseSql(hqlQuery))
// We force query optimization to happen right away instead of letting it happen lazily like
// when using the query DSL. This is so DDL commands behave as expected. This is only
// generates the RDD lineage for DML queries, but does not perform any execution.
result.queryExecution.toRdd
result
}上述hiveql的定义与sql的定义几乎一模一样,唯一的不同是sql中使用parseSql的结果作为SchemaRDD的入参而hiveql中使用HiveQl.parseSql作为SchemaRdd的入参。对比:
def sql(sqlText: String): SchemaRDD = {
val result = new SchemaRDD(this, parseSql(sqlText))
result.queryExecution.toRdd
result
}3.4 HiveQL, parser
parseSql的函数定义如代码所示,解析过程中将指令分成两大类:
- nativecommand 非select语句,这类语句的特点是执行时间不会因为条件的不同而有很大的差异,基本上都能在较短的时间内完成。
- 非nativecommand 主要是select语句。
def parseSql(sql: String): LogicalPlan = {
try {
if (sql.toLowerCase.startsWith("set")) {
NativeCommand(sql)
} else if (sql.toLowerCase.startsWith("add jar")) {
AddJar(sql.drop(8))
} else if (sql.toLowerCase.startsWith("add file")) {
AddFile(sql.drop(9))
} else if (sql.startsWith("dfs")) {
DfsCommand(sql)
} else if (sql.startsWith("source")) {
SourceCommand(sql.split(" ").toSeq match { case Seq("source", filePath) => filePath })
} else if (sql.startsWith("!")) {
ShellCommand(sql.drop(1))
} else {
val tree = getAst(sql)
if (nativeCommands contains tree.getText) {
NativeCommand(sql)
} else {
nodeToPlan(tree) match {
case NativePlaceholder => NativeCommand(sql)
case other => other
}
}
}
} catch {
case e: Exception => throw new ParseException(sql, e)
case e: NotImplementedError => sys.error(
s"""
|Unsupported language features in query: $sql
|${dumpTree(getAst(sql))}
""".stripMargin)
}
} 哪些指令是nativecommand呢,答案在HiveQl.scala中的nativeCommands变量。对于非nativeCommand,最重要的解析函数就是nodeToPlan。Spark对HiveQL所做的优化主要体现在Query相关的操作,其它的依然使用Hive的原生执行引擎。
3.5 SQL到Spark作业的转换过程
native command的执行流程
由于native command是一些非耗时的操作,直接使用Hive中原有的exeucte engine来执行即可。这些command的执行示意图如下
![]()
SparkTask的生成和执行
我们通过一个例子来看一下一个简单的两表JOIN查询如何被转换为SparkTask并被执行。下图左半部分展示了这个查询的Operator Tree,以及该Operator Tree如何被转化成SparkTask;右半部分展示了该SparkTask执行时如何得到最终的RDD并通过foreachAsync提交Spark任务。
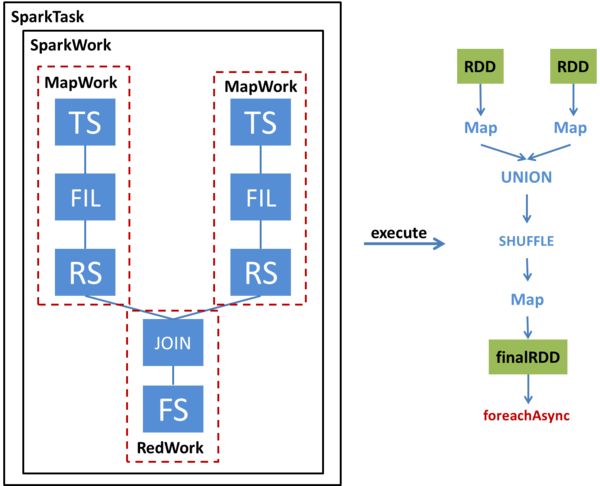
SparkCompiler遍历Operator Tree,将其划分为不同的MapWork和ReduceWork。
MapWork为根节点,总是由TableScanOperator(Hive中对表进行扫描的操作符)开始;后续的Work均为ReduceWork。ReduceSinkOperator(Hive中进行Shuffle输出的操作符)用来标记两个Work之间的界线,出现ReduceSinkOperator表示当前Work到下一个Work之间的数据需要进行Shuffle。因此,当我们发现ReduceSinkOperator时,就会创建一个新的ReduceWork并作为当前Work的子节点。包含了FileSinkOperator(Hive中将结果输出到文件的操作符)的Work为叶子节点。
与MapReduce最大的不同在于,我们并不要求ReduceWork一定是叶子节点,即ReduceWork之后可以链接更多的ReduceWork,并在同一个SparkTask中执行。
总结执行SparkTask步骤:
- 根据MapWork来生成最底层的HadoopRDD,
- 将各个MapWork和ReduceWork包装成Function应用到RDD上。
- 在有依赖的Work之间,需要显式地调用Shuffle转换,具体选用哪种Shuffle则要根据查询的类型来确定。另外,由于这个例子涉及多表查询,因此在Shuffle之前还要对RDD进行Union。
- 经过这一系列转换后,得到最终的RDD,并通过foreachAsync提交到Spark集群上进行计算。
在logicalPlan到physicalPlan的转换过程中,toRdd最关键的元素
override lazy val toRdd: RDD[Row] =
analyzed match {
case NativeCommand(cmd) =>
val output = runSqlHive(cmd)
if (output.size == 0) {
emptyResult
} else {
val asRows = output.map(r => new GenericRow(r.split("\t").asInstanceOf[Array[Any]]))
sparkContext.parallelize(asRows, 1)
}
case _ =>
executedPlan.execute().map(_.copy())
}4. 案例Count
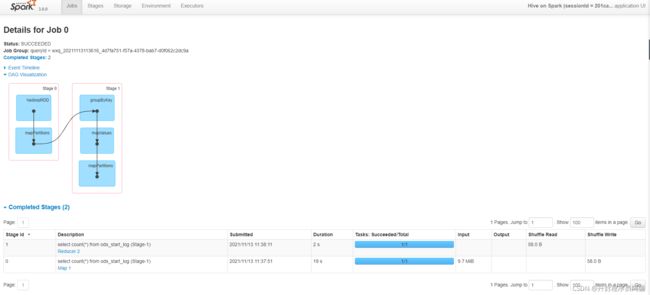
查看执行计划:explain select count(*) from ods_start_log;
Explain
STAGE DEPENDENCIES:
Stage-1 is a root stage
Stage-0 depends on stages: Stage-1
STAGE PLANS:
Stage: Stage-1
Spark //执行引擎
Edges://边
Reducer 2 <- Map 1 (GROUP, 1) //边描述
DagName: wxq_20211113113616_4d7fa751-f57a-4378-bab7-d0f062c2dc9a:1
Vertices: //顶点
Map 1
Map Operator Tree: //map 语法树
TableScan //扫描表操作
alias: ods_start_log
Statistics: Num rows: 308758 Data size: 118565680 Basic stats: COMPLETE Column stats: NONE //统计数字 多少行,数据大小
Select Operator //字段选择操作
Statistics: Num rows: 308758 Data size: 118565680 Basic stats: COMPLETE Column stats: NONE //统计数字 多少行,数据大小
Group By Operator //分组操作
aggregations: count() //聚合算子
mode: hash //hash分组
outputColumnNames: _col0 //输出列名
Statistics: Num rows: 1 Data size: 8 Basic stats: COMPLETE Column stats: NONE //统计数字 多少行,数据大小
Reduce Output Operator //reduce输出操作
sort order:
Statistics: Num rows: 1 Data size: 8 Basic stats: COMPLETE Column stats: NONE //统计数字 多少行,数据大小
value expressions: _col0 (type: bigint) //输出信息描述
Execution mode: vectorized //执行模式:矢量化
Reducer 2
Execution mode: vectorized //执行模式:矢量化
Reduce Operator Tree: //Reduce操作树
Group By Operator //分组操作
aggregations: count(VALUE._col0) //根据列统计
mode: mergepartial //模式:合并部分
outputColumnNames: _col0 //输出列名
Statistics: Num rows: 1 Data size: 8 Basic stats: COMPLETE Column stats: NONE //统计数字 多少行,数据大小
File Output Operator //文件输出算子
compressed: false //不压缩
Statistics: Num rows: 1 Data size: 8 Basic stats: COMPLETE Column stats: NONE//统计数字 多少行,数据大小
table:
input format: org.apache.hadoop.mapred.SequenceFileInputFormat //输入格式
output format: org.apache.hadoop.hive.ql.io.HiveSequenceFileOutputFormat //输出格式
serde: org.apache.hadoop.hive.serde2.lazy.LazySimpleSerDe //序列化
Stage: Stage-0
Fetch Operator //抓取数据
limit: -1
Processor Tree:
ListSink //list输出
查看作业日志:

参考文章:
大数据手册(Hive)--HiveQL_WilenWu-CSDN博客_hiveql
Hive on spark的架构与解析SQL的过程 - 简书