MATLAB | 如何使用MATLAB获取顶刊cell全部绘图(附带近3年全部图像)
众所周知,学习科研绘图、配色最好的办法就是去观摩顶级期刊上的作图,本来想着收集各个顶级期刊绘图提供给大家,但是每年的图像加起来大约3-5G,撑死也就能提供三四年的图像,再多内存可能不太够了,于是我写了一段杷虫代码,可以下载任意册期刊的全部图像,运行就命令行运行例如getCellJPG(185),就可以下载第185册(2022)的全部图像,这段代码也不算长,就放这吧(我杷虫代码功底属实一般,大家见谅):
function getCellJPG(volume)
if nargin < 1
volume = 184;
end
url_archive0 = 'https://www.cell.com/cell/issues';
html_archive = urlread(url_archive0);
A_html_archive = strfind(html_archive,'data-groupid');
Z_html_archive = strfind(html_archive,['>Volume ',num2str(volume)]);
url_archiven = html_archive(A_html_archive(find(A_html_archive<Z_html_archive,1,'last')):Z_html_archive);
url_archiven = url_archiven(15:end-59);
url_archive1 = 'https://www.cell.com/cell/archive?issueGroupId=';
url_archive2 = '&publicationCode=cell';
url_archive = [url_archive1,url_archiven,url_archive2];
html_archive = urlread(url_archive);
A_html_archive = strfind(html_archive,['Volume ',num2str(volume)]);
Z_html_archive = strfind(html_archive,'archive?publicationCode=cell');
Z_html_archive = Z_html_archive(find(Z_html_archive>A_html_archive,1));
html_archive = html_archive(A_html_archive:Z_html_archive);
A_issue = strfind(html_archive,'');
ibegin = 1; jbegin = 1; kbegin = 1;
forderName=['Volume_',num2str(volume)];
if exist(['.\image_',forderName,'\ijkbreak.mat'],'file')
load(['.\image_',forderName,'\ijkbreak.mat']);
end
if ~exist(['.\image_',forderName],'dir')
mkdir(['.\image_',forderName]);
end
disp([ibegin,jbegin,kbegin])
for i = ibegin:length(A_issue)
url_issue = html_archive(A_issue(i):Z_issue(find(Z_issue>A_issue(i),1)));
url_issue = url_issue(10:end-1);
html_issue = urlread(['https://www.cell.com',url_issue]);
A_html_issue = strfind(html_issue,'id="Articles"');
Z_html_issue = strfind(html_issue,'The content on this site');
html_issue = html_issue(A_html_issue:Z_html_issue);
A_article = strfind(html_issue,'class="toc__item__title"');
Z_article = strfind(html_issue,'">');
for j = jbegin:length(A_article)
url_article = html_issue(A_article(j):Z_article(find(Z_article>A_article(j)+30,2)));
url_article = url_article(50:end-1);
html_article = urlread(['https://www.cell.com/cell/fulltext/',url_article]);
A_jpg = strfind(html_article,');
Z_jpg = strfind(html_article,'download-links__download-Hi-res');
for k = kbegin:length(Z_jpg)
ibegin = i ; jbegin = j; kbegin = k;
save(['.\image_',forderName,'\ijkbreak.mat'],'ibegin','jbegin','kbegin')
url_jpg = html_article(A_jpg(find(A_jpg<Z_jpg(k),1,'last')):Z_jpg(k));
url_jpg = ['https://www.cell.com',url_jpg(10:end-10)];
name_jpg = ['.\image_',forderName,'\',url_article,' P',num2str(k)];
websave(name_jpg,url_jpg);
disp(['Downloading Volume-',num2str(volume),...
' Issue-',num2str(i),' Artical-',num2str(j),...
' Pic-',num2str(k),':',url_article])
end
kbegin = 1;
end
jbegin = 1;
end
end
代码设置了可断点下载,就是可以下载了一半中断程序后过段时间接着下。
同时如果有的时候看到一张图非常好想找找源文章读一读,此代码下载的图像名称就标注了图像的来源,比如:
S0092-8674(21)01427-6 P14 这张图片,就是来自编号 S0092-8674(21)01427-6 论文的第14张图:
注意此处连带封面图和示意图一起爬取的,因此第14张图不一定是Figure14哈:
在浏览器输入该论文链接:
- https://www.cell.com/cell/fulltext/S0092-8674(21)01427-6
找到第14张图,是不是对应一致的:
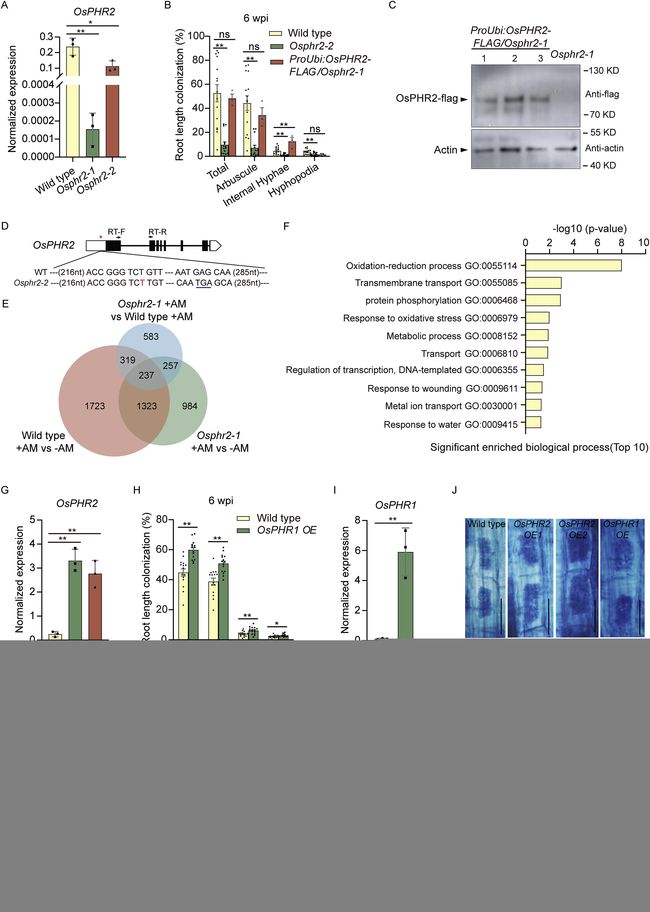
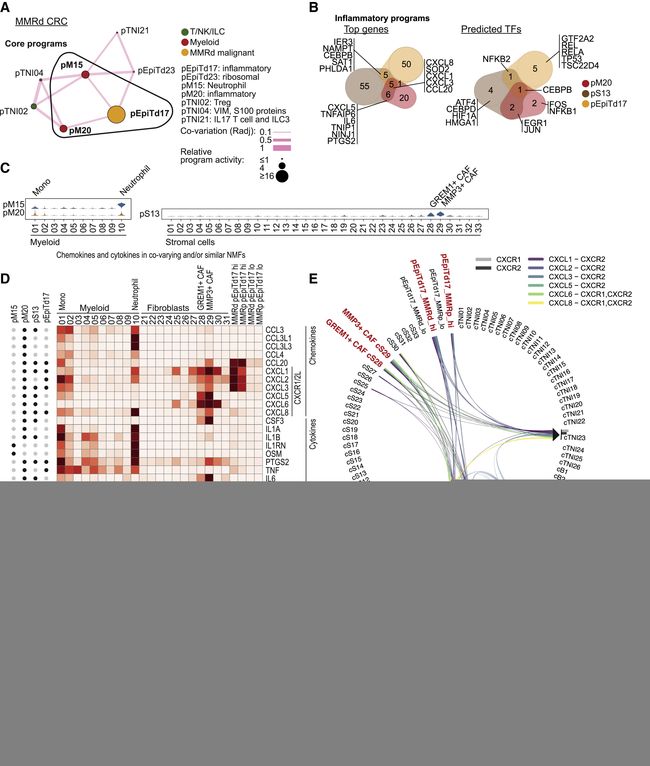
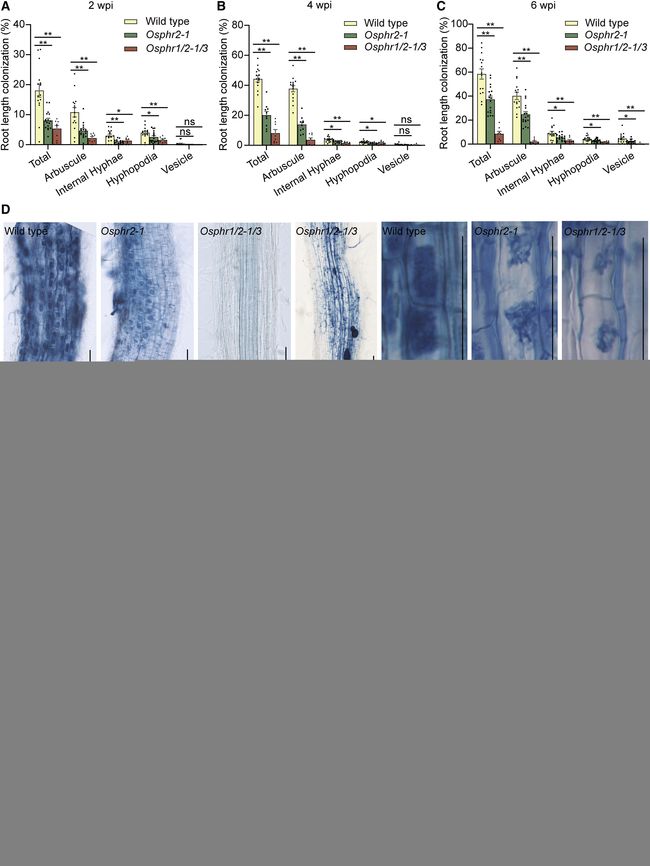
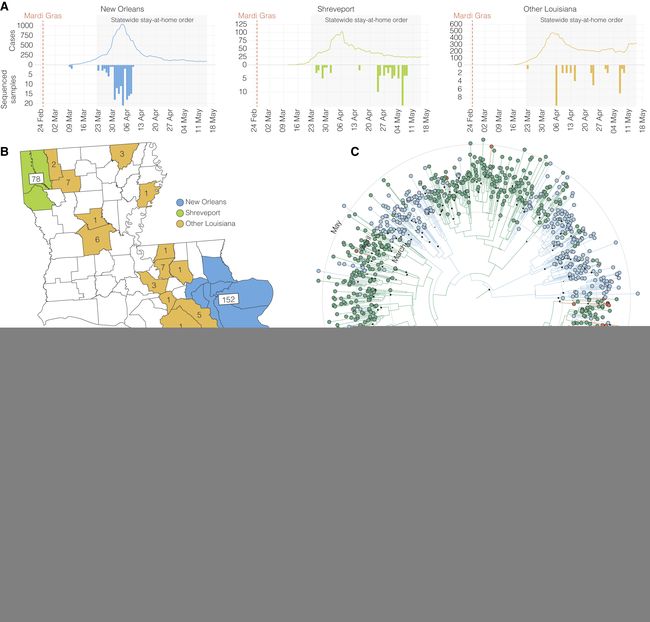
部分图像展示
volume 186 (2023)
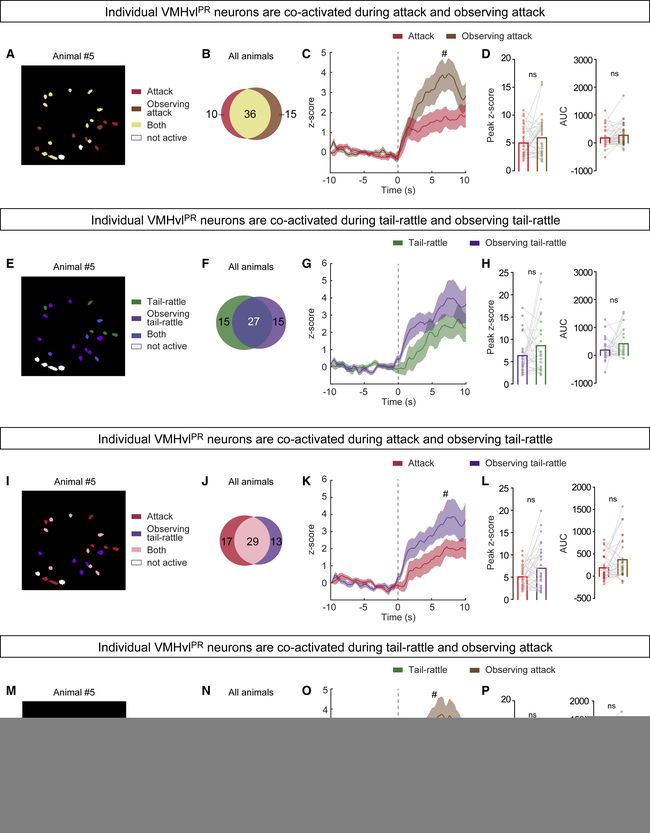
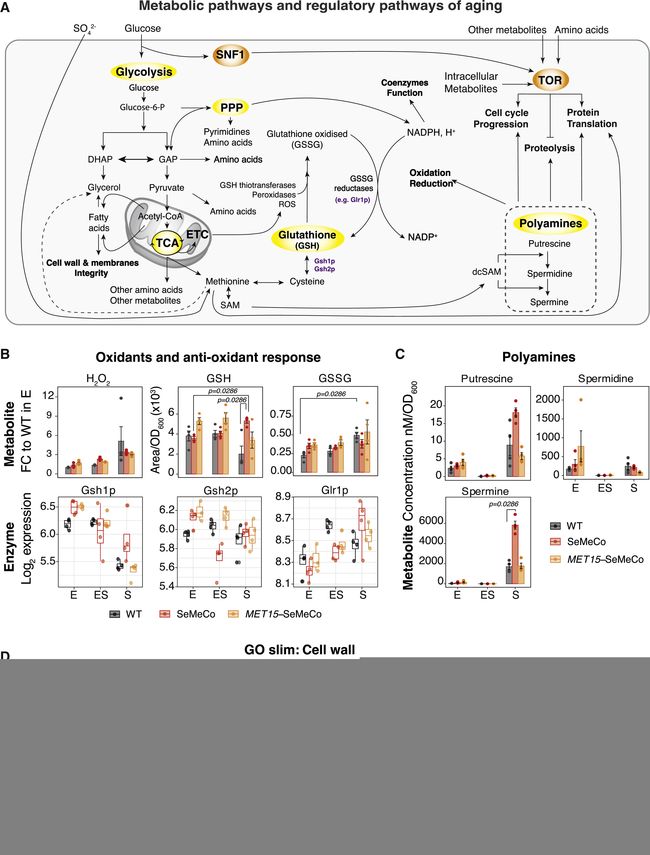
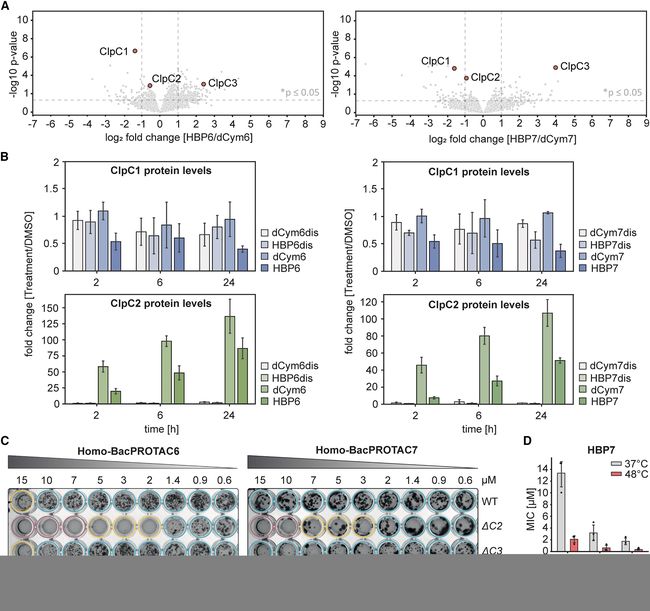
volume 185 (2022)
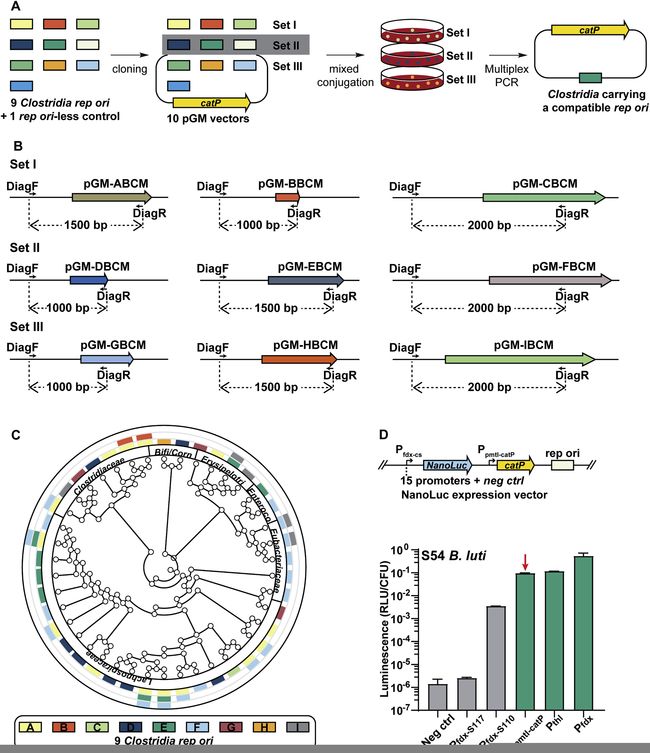




volume 185 (2021)


图像获取
百度网盘
提供近三年来图片百度网盘链接,其中2023年目前为止共1035张,2022年共2578张,2021年共4707张:
volume 186 (2023)
链接:
https://pan.baidu.com/s/1eXPZBWF-wZvjO_rP1M5F4A?pwd=slan
提取码:slan
volume 185 (2022)
链接:
https://pan.baidu.com/s/1OCfNwaA_7Y24Hl-IKMsEpQ?pwd=slan
提取码:slan
volume 184 (2021)
链接:
https://pan.baidu.com/s/1WXcyyKMbUjL13z02yBKrOA?pwd=slan
提取码:slan
gitee仓库
若网盘失效,可去gitee仓库获取最新网盘链接:
https://gitee.com/slandarer/cell-figures