Redis集群详细介绍从0开始-包括集群的Jedis开发
集群
为什么需要集群-高可用性
1、生产环境的实际需求和问题
- 容量不够,redis 如何进行扩容?
- 并发写操作, redis 如何分摊?
- 主从模式,薪火相传模式,主机宕机,会导致ip 地址发生变化,应用程序中配置需要修改对应的主机地址、端口等信息
2、传统解决方案-代理主机来解决
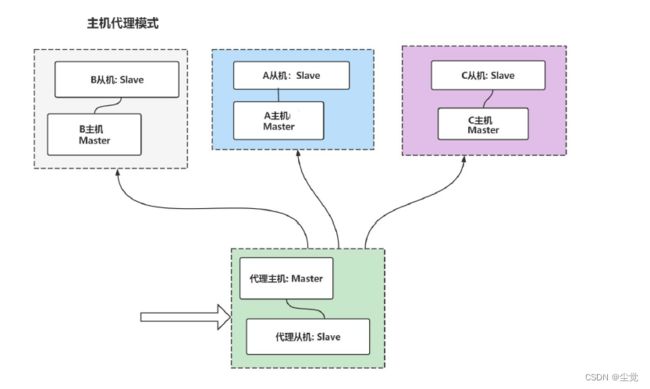
解读上图
- 客户端请求先到代理服务器
- 由代理服务器进行请求转发到对应的业务处理服务器
- 客户端请求先到代理服务器
- 由代理服务器进行请求转发到对应的业务处理服务器
3、redis3.0 提供解决方案-无中心化集群配置
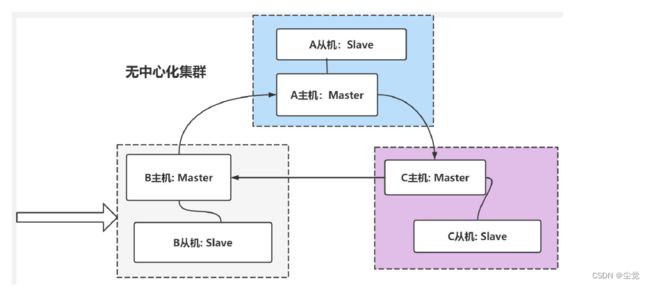
解读上图
- 各个Redis 服务仍然采用主从结构
- 各个Redis 服务是连通的, 任何一台服务器, 都可以作为请求入口
- 各个Redis 服务器因为是连通的, 可以进行请求转发
- 这种方式, 就无中心化集群配置, 可以看到,只需要6 台服务器即可搞定
- 无中心化集群配置, 还会根据key 值, 计算slot , 把数据分散到不同的主机, 从而缓解单个主机的存取压力.[后面会演示和再说明]
- Redis 推荐使用无中心化集群配置
- 在实际生成环境各个Redis 服务器, 应当部署到不同的机器(防止机器宕机, 主从复制失效)
- 后面演示时, 为了方便, 是在一台机器(如果启6 个虚拟Linux, 电脑撑不住),请注意一下.
集群介绍
1、Redis 集群实现了对Redis 的水平扩容,即启动N 个redis 节点,将整个数据库分布存储在这N 个节点中,每个节点存储总数据的1/N。
2、Redis 集群通过分区(partition)来提供一定程度的可用性(availability): 即使集群中有一部分节点失效或者无法进行通讯, 集群也可以继续处理命令请求
Redis 集群搭建
需求说明/图解
搭建步骤演示
将rdb、aof 文件都删除掉
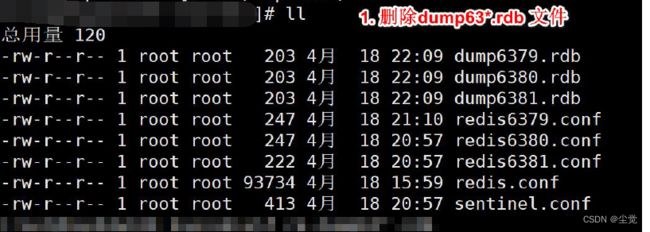
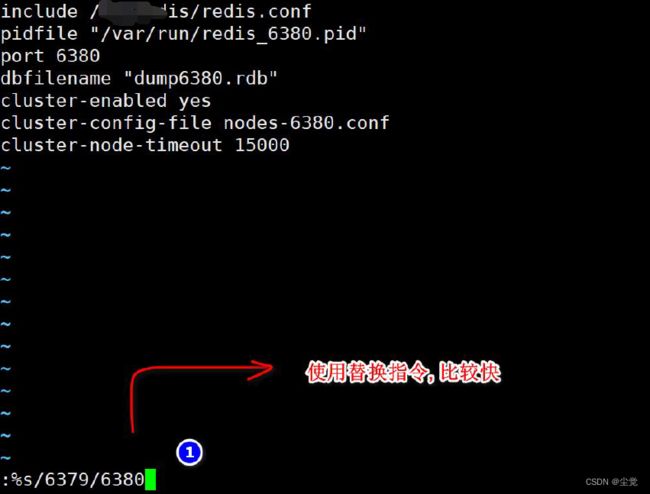
redis cluster 配置修改
cluster-enabled yes 打开集群模式
cluster-config-file nodes-6379.conf 设定节点配置文件名
cluster-node-timeout 15000 设定节点失联时间,超过该时间(毫秒),集群自动进行主从切换
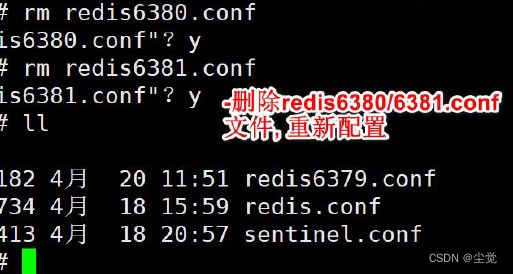
删除不必要的内容
vi /hspredis/redis6379.conf , 删除不必要的内容, 增加cluster 配置, 文件最后内容,如图

注意这里打马赛克的是你自己设置的文件目录 注意前面的 include不要改变 是后面的 可以借助pwd看当前所在的绝对路径前提是在redis.conf位置
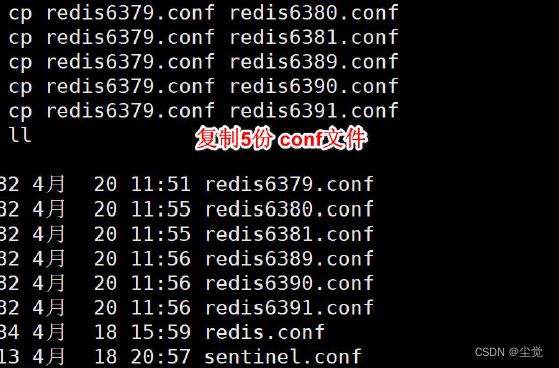
使用查找替换修改另外5 个文件
- 替换指令:%s/6379/6380
- vi redis6380.conf
- 其它几个文件以此操作即可, 操作的时候,一定要小心, 最后建议再检查一下
启动6 个Redis 服务


将六个节点合成一个集群
将六个节点合成一个集群的指令:
redis-cli --cluster create --cluster-replicas 1 192.168.198.130:6379
192.168.198.130:6380 192.168.198.130:6381 192.168.198.130:6389
192.168.198.130:6390 192.168.198.130:6391
注意事项和细节
- 组合之前,请确保所有redis 实例启动后,nodes-xxxx.conf 文件都生成正常
- 此处不要用127.0.0.1, 请用真实IP 地址, 在真实生产环境, IP 都是独立的.
- replicas 1 采用最简单的方式配置集群,一台主机,一台从机,正好三组
- 搭建集群如果没有成功, 把sentinel 进程kill 掉, 再试一下
- 分析主从对应关系




集群方式登录
指令: redis-cli -c -p 6379
指令: cluster nodes 命令查看集群信息, 主从的对应关系, 主要看标注的颜色
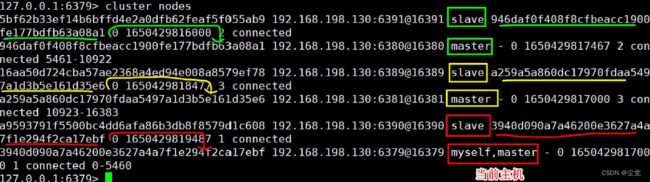
注意事项和细节
1、一个集群至少要有三个主节点
2、选项–cluster-replicas 1 表示我们希望为集群中的每个主节点创建一个从节点。
3、分配原则:尽量保证主服务器和从服务器各自运行在不同的IP 地址(机器), 防止机器故障导致主从机制失效, 高可用性得不到保障
Redis 集群使用
什么是slots
- Redis 集群启动后, 你会看到如下提示

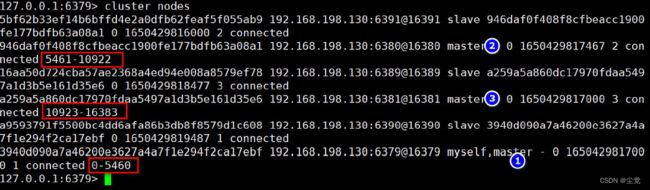
- 一个Redis 集群包含16384 个插槽(hash slot),编号从0-16383, Reids 中的每个键都属于这16384 个插槽的其中一个
- 集群使用公式CRC16(key) % 16384 来计算键key 属于哪个槽, 其中CRC16(key) 语句用于计算键key 的CRC16 校验和
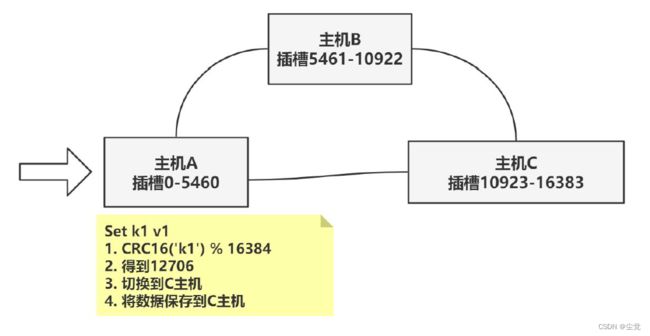
- 集群中的每个节点负责处理一部分插槽。举个例子, 如果一个集群可以有主节点, 其中:
-节点A 负责处理0 号至5460 号插槽。
-节点B 负责处理5461 号至10922 号插槽。
-节点C 负责处理10923 号至16383 号插槽
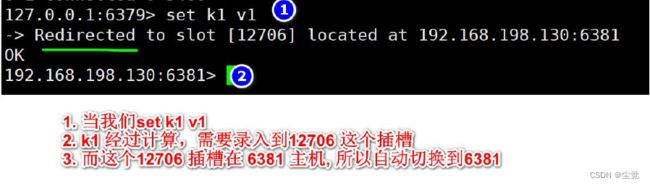
在集群中录入值
-
在redis 每次录入、查询键值,redis 都会计算出该key 应该送往的插槽,如果不是该客户端对应服务器的插槽,redis 会告知应前往的redis 实例地址和端口。
-
redis-cli 客户端提供了–c 参数实现自动重定向。
-
如redis-cli -c –p 6379 登入后,再录入、查询键值对可以自动重定向
-
不在一个slot 下的键值,是不能使用mget,mset 等多键操作

-
可以通过{}来定义组的概念,从而使key 中{}内相同内容的键值对放到一个slot 中去

查询集群中的值
- 指令: CLUSTER KEYSLOT 返回key 对应的slot 值
- 指令: CLUSTER COUNTKEYSINSLOT 返回slot 有多少个key
- 指令: CLUSTER GETKEYSINSLOT 返回count 个slot 槽中的键

Redis 集群故障恢复
如果主节点下线, 从节点会自动升为主节点(注意15 秒超时, 再观察比较准确)

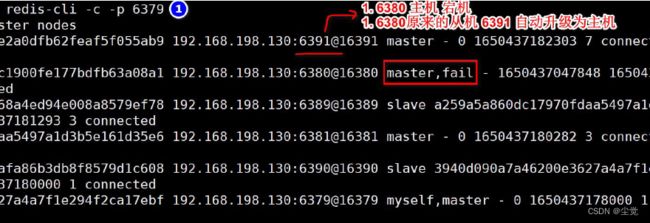
主节点恢复后,主节点回来变成从机


如果所有某一段插槽的主从节点都宕掉,Redis 服务是否还能继续, 要根据不同的配置而言
- 如果某一段插槽的主从都挂掉,而cluster-require-full-coverage 为yes ,那么,整个集群都挂掉
- 如果某一段插槽的主从都挂掉,而cluster-require-full-coverage 为no , 那么, 只是该插槽数据不能使用,也无法存储
- redis.conf 中的参数cluster-require-full-coverage

集群的Jedis 开发
1、即使连接的不是主机,集群会自动切换主机存储。主机写,从机读。
2、无中心化主从集群。无论从哪台主机写的数据,其他主机上都能读到数据
实验
将Redis 相关的端口都打开, 否则会报错


创建edisCluster
src\main\java\com\jedis\JedisCluster_.java
/**
* 操作Redis集群
*/
public class JedisCluster_ {
public static void main(String[] args) {
/**
* 解读
* 1. 这里的set可以加入多个入口
* 2. 因为我们没有做日志配置,输出时,有些提示,但是不影响使用
* 3. 如果我们使用的是集群,需要把相关的端口都打开,否则会报错
*
* 4. JedisCluster的构造器有多个,也可以直接传入HostAndPort 代码如下
* public JedisCluster(HostAndPort node) {
* this(Collections.singleton(node));
* }
*
*/
Set<HostAndPort> set = new HashSet<HostAndPort>();
set.add(new HostAndPort("192.168.198.135",6379));
JedisCluster jedisCluster = new JedisCluster(set);
jedisCluster.set("address","bj~北京");
String address = jedisCluster.get("address");
System.out.println("address-->" + address);
jedisCluster.close();
}
}
完成测试
Redis 集群的优缺点
优点
1、实现扩容
2、分摊压力
3、无中心配置相对简单
缺点
1、多键操作是不被支持的
2、多键的Redis 事务是不被支持的。lua 脚本不被支持
3、由于集群方案出现较晚,很多公司已经采用了其他的集群方案,而其它方案想要迁移至redis cluster,需要整体迁移而不是逐步过渡,复杂度较大