ACL 2023 | 利用思维链(CoT)推理隐式情感,狂涨50%

©PaperWeekly 原创 · 作者 | 费豪
单位 | 新加坡国立大学

题目:
Reasoning Implicit Sentiment with Chain-of-Thought Prompting
作者:
费豪¹,李波波²,刘乾³,邴立东⁴,李霏²,Chua Tat-Seng¹
新加坡国立大学¹,武汉大学²,Sea AI Lab³,阿里巴巴达摩院⁴
会议:
ACL 2023
论文:
https://arxiv.org/abs/2305.11255
代码:
https://github.com/scofield7419/THOR-ISA
本工作极简概括:在隐式情感分析场景中,由于不包含显式的情感相关特征词,现有的情感分类模型在该场景下都严重失效。受启发于人的隐式情感解题模式,本文提出利用思维链(Chain of Thought, CoT)方法来链式推理出隐式情感,在 Zero-shot 设定下提升 50% F1 值。

动机介绍
1.1 任务背景
情感分析(Sentiment Analysis, SA)是自然语言处理领域一个较为火热的研究方向,该任务旨在检测输入文本中对给定目标的情感极性。经过十多年的高速发展,情感分析课题下目前已产生了很多类型的子任务和主题。其中,根据情感特征词是否给定,情感分析又可分为显式情感分析(Explicit SA,ESA)和隐式情感分析(Implicit SA,ISA)。
前者 ESA 是当前主流的分析场景,其中情感相关的表述词在文本中是明确存在的。而与 ESA 不同,ISA 更具挑战性,因为在 ISA 中,输入文本只包含几乎类似于“中性的”事实描述,没有明确的观点态度表达会直接给出。例如,给定一个句子“快去尝尝淄博的烧烤吧!”,句子中不会出现任何显式的情感线索词。
目前几乎所有的情感分析模型的工作原理基本都是面向“特征词”的预测(rationale-oriented prediction),即必须要找准情感特征词(要么人工帮助提取要么机器自动学习)才能准确得到预测。然而对于这种隐式情感场景,由于不包含任何显式关键特征词,现有方法的性能都会快速失效。所以对于关于“淄博的烧烤”这个目标的预测,几乎目前市面上现有的情感分类模型会输出为中性的极性。
实际上对于我们人类而言,即便再困难、再隐含的 ISA,我们都可以轻而易举地确定其所对应的情感极性,原因在于我们总是能够抓住文本背后的真实意图或观点。因此,传统的情感分析方法对于隐式情感的处理往往是无效的,因为它们并没有真正理解其情感是如何引发的。
1.2 现象分析
不妨分析一下我们人类对于 ISA 的解题模式。在这个过程中有两个比较关键的现象:
首先,我们大概率会根据所给定的上下文,进一步发掘更多的信息,以消除更多的不确定性。比如,我们会调用自己的常识知识库来快速确定给定文本中所提到的关键信息到底在谈论什么内容。比如得确定“淄博”是一个地方名,以及“淄博的烧烤”是在谈论淄博这个地方的烧烤这种特色食物。
同时,这其实是一个步步递进式的推理过程。在此之中,我们往往会先确定所谈论的目标的具体方面,比如对于“淄博的烧烤”,其实是想去理解“淄博的烧烤”的“味道”。接着再对于“味道”这个方面,进一步根据蛛丝马迹思考用户的所持有的真正意图和观点,比如会有这么一个思考推理过程:由于用户在强烈推荐别人去尝尝“淄博的烧烤”,那么其“味道”是值得推荐的。最后根据这些所推理出来的丰富的中间上下文信息,便可轻易地且正确地确定最终的情感极性,积极。

▲ 图1 显式情感分析与隐式情感分析示例和区别
1.3 原理归纳
根据上述分析我们可以归纳出以下几点重要方面:
ISA 的决策依赖于一个步步推理的过程,需要一步一步地去揭示更多的上下文、隐含信息。相比之下,现有的(传统的)SA 方法往往采用找关键词并一步到位的预测方式,自然是行不通的。
这个推理过程实际上完美地对应了现有的细粒度方面级别情感分析(Aspect-based Sentiment Analysis, ABSA)的定义,即先确定方面(Aspect),再挖掘意见(Opinion),最终得到情感极性(Polarity)。其中中间的 Aspect 与 Opinion 是隐式的,需要通过推理得到,才能构成完整的情感版图。
这个推理过程可以更确切地拆分为两种推理能力:一个是常识推理能力(即推断“淄博的烧烤”是什么),另一个是多跳推理能力(即推断方面,然后推断观点,再确定最终极性)。

隐式情感三跳推理框架
幸运的是,近来大规模预训练语言模型(Large Language Models, LLMs),诸如 ChatGPT、Vicuna、LLaMA、GPT4 等,取得了巨大的成功,这为我们的问题提供了一个很好的解决方案:
一方面,由于经历过超大规模的预训练,LLMs 被广泛证明学习到了非常丰富的世界知识,在常识理解方面展现出了非凡的能力,因此可以轻松胜任常识性推理。
另一方面,最新的思维链(CoT)理念揭示了 LLMs 的多跳推理的巨大潜力,在这种推理中,合理地提示 LLM 便可进行出色的链式推理。
基于所有这些前驱的成功探索,我们提出了一个三跳推理的思维链提示学习框架(Three-hop Reasoning CoT,THOR)用于解决 ISA 任务。基于一个基座 LLM,我们设计了三种 Prompt 来进行三个推理步骤,分别推断出:1)给定目标的细粒度方面(Aspect),2)对该方面的潜在观点(Opinion),以及 3)最终的极性(Polarity)。通过这种由易到难的渐进推理,可以逐步揭示出完整的情感版图的隐藏元素,以实现更轻松且正确的极性预测,有效地缓解了本任务的预测难度。

▲ 图2 隐式情感三跳推理的思维链提示学习框架(Three-hop Reasoning CoT,THOR)
2.1 思维链提示模板
图 2 给出了一个 THOR 的完整框架示意图。在这里我们事先定义好输入的句子为 X,给定 t 为待分析的目标,极性为 y,并且定义中间的 Aspect 为 a 和潜在的 Opinion 表达为 o。我们构建了一种三跳 Prompt 模板,具体如下:
第一步:我们首先询问 LLM 句子中涉及到关于哪一种方面 a,使用以下模板:

C1 是第一跳提示的上下文。这一步可以表示为 A=argmax p(a|X, t),其中 A 是明确提到方面 a 的输出文本。
第二步:现在基于 X、t 和 a,我们要求 LLM 详细回答关于提到方面 a 的潜在观点 o 是什么:

C2 是第二跳提示的上下文,我们将 C1 和 A 连接在一起。这一步可以写成 O=argmax p(o|X, t, a),其中 O 是包含可能观点表达 o 的答案文本。
第三步:在完整的情感框架(X、t、a 和 o)作为上下文的基础上,我们最终要求LLM 推断出极性 t 的最终答案:

C3 是第三跳提示的上下文。我们将这一步表示为 y=argmax p(y|X, t, a, o)。
2.2 增强推理的自一致性
我们进一步利用自一致性机制来巩固推理的正确性。具体来说,在每个三步推理的过程中,我们设置 LLM 解码器生成多个答案,其中每个答案可能会对方面 a、观点 o 以及极性 y 给出不同的预测。在每一步中,我们保留那些推断得到的 a、o 或 y 具有高投票一致性的答案。我们选择置信度最高的答案作为下一步的上下文。
2.3 通过监督进行推理修正
当存在带有标注的训练集时(即有监督的微调设置),我们还可以对 THOR 进行微调。我们设计了一种推理修正方法。具体地,在每个步骤中,我们通过连接以下内容构建一个提示:1)初始上下文,2)这一步的推理答案文本和 3)最终的问题,然后将其输入 LLM 以预测情感标签,而不是继续进行下一步推理。例如,在第一步的末尾,我们可以组合一个提示:[C1, A,‘对 t 的情感极性是什么?’]。在使用 Gold 标签进行监督时,LLM 将被指导生成更多正确的中间推理,这对于最终的预测是有利的。

实验分析
我们在 SemEval14 Laptop 和 Restaurant 数据集上进行了实验,其中所有实例都已被前驱工作划分为了 ESA 和 ISA。我们使用了 Flan-T5 作为我们的主干 LLM;以及 GPT3 和 ChatGPT 进行测试。我们使用了四个版本的 Flan-T5:250M(基础版)、780M(大型版)、3B(超大型版)和 11B(特大型版),以及四个版本的 GPT3:350M、1.3B、6.7B 和 175B。
● 有监督微调结果
见表 2,在结合 THOR 的情况下,Flan-T5-11B 在 ISA 上表现出显著提升,即在Restaurant 数据集上提升了 7.45%(从 79.73% 提高到 72.28%),在 Laptop 数据集上提升了 5.84%(从 82.43% 提高到 77.59%),平均提升了 6.65% 个点的 F1。

▲ 表2 有监督微调结果
● Zero-shot结果
在 Zero-shot 下的提升更为明显。见表 3,GPT3-175B 在结合力 THOR 后,在 Restaurant 数据集上将 SoTA 结果提升了 51.94%(从 30.02% 提高到81.96%),在 Laptop 数据集上提升了 50.27%(从 25.77% 提高到76.04%),平均提升了 51.10% 个点的 F1。

▲ 表3 Zero-shot下实验结果
● LLM规模影响
随着模型规模的增加,THOR 的有效性呈指数级增强,参见图 3。这与目前的 LLM 的涌现能力的 finding 保持了一致的趋势。
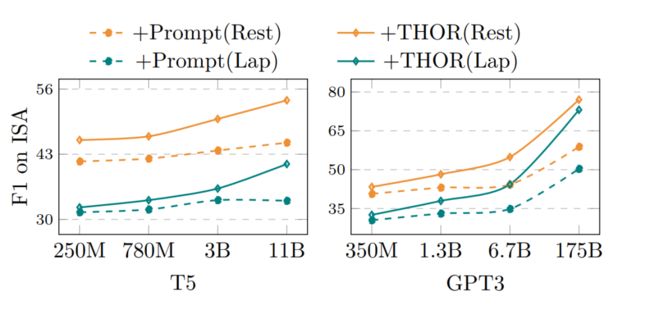
▲ 图3 不同LLM规模下表现
● 在ChatGPT上的表现
在图 4 中,GPT3 和 ChatGPT 利用 THOR 都在 ISA 上取得了显著的改进。同时发现,在 ESA 上的提升不是很明显。

▲ 图4 分别在GPT3和ChatGPT下的表现
● 错误分析
图 5 展示了使用 THOR 时失败案例的错误率,我们总结了三种错误类型。Flan-T5-11B LLM 在 Zero-shot 设置下的错误率为 48.27%,而在有监督微调的情况下下降至 12.79%。无监督的 GPT3(175B)在错误率上与有监督的 T5(11B)保持了一致的低;但是,后者由于推理能力不足而更频繁地失败。这主要在于 LLM 的规模所造成的推理能力差异。
进一步发现,与有监督的 T5(11B)相比,无监督的 GPT3(175B)的大部分失败竟然来自问题数据标注的问题。由于有监督的 T5,尽管测试准确度更高,但其通过对“错误”标签进行监督拟合的,实际上可能学到的是伪相关性(spurious correlations)。
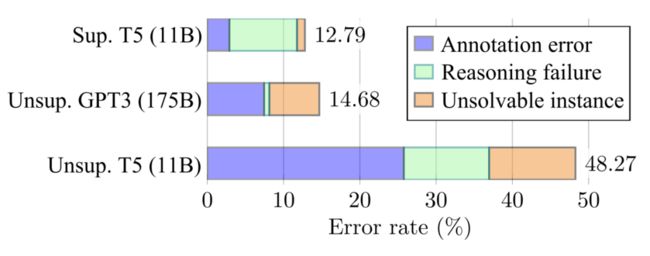
▲ 图5 错误分析
● 在ChatGPT下的个案
我们提供几个真实的测试示例。我们将 THOR 与原始的 Prompt 方法以及 Zero-shot CoT 方法(Prompt + Let’s think step by step),进行比较。所有的 case 都基于 ChatGPT(2022年12月版本)。

▲ 图6 原始的Prompt方法

▲ 图7 Zero-shot CoT方法(Prompt + Let’s think step by step)
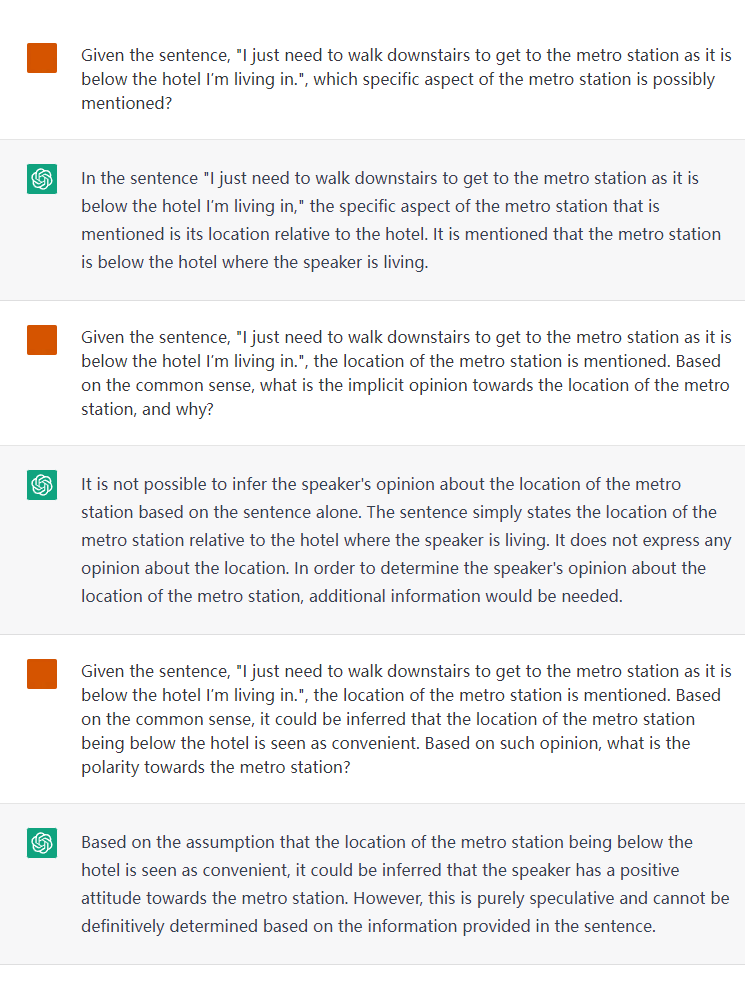
▲ 图8 我们的三跳推理框架(THOR)

结论和未来展望
本文介绍了一种三跳推理学习框架(THOR)用于解决隐式情感(ISA)任务,通过步步递进式、由易到难的渐进推理诱导 LLM 得到丰富的中间上下文信息帮助推断情感极性。所提出的 THOR 框架基于思维链(CoT)提示学习方法,继承了其简单实现的特点,而可实现高性能的任务提升。
今年随着 LLM 的爆裂式发展,目前 NLP 社区已经翻开了新的篇章。LLM 已经为 NLP 各个方面的基准任务提出了新的层面的要求,比如,向更难、更复杂、更接近人级别(Human-level)的语言理解能力的方向发展。其中 CoT 方法得到了较多的关注,其帮助 LLM 实现类人的多跳推理过程。
目前 CoT 大部分工作主要关注于解决数学逻辑方面的离散推理任务,而据我们所知,这是第一次成功将 CoT 思想扩展到情感分析领域这种非数字逻辑推理的任务。未来探索可以将 CoT 的思路扩展到更多的类似的应用上,比如设计并结合更合适的 In-context demonstration 来更好地诱导中间推理过程。
更多阅读




#投 稿 通 道#
让你的文字被更多人看到
如何才能让更多的优质内容以更短路径到达读者群体,缩短读者寻找优质内容的成本呢?答案就是:你不认识的人。
总有一些你不认识的人,知道你想知道的东西。PaperWeekly 或许可以成为一座桥梁,促使不同背景、不同方向的学者和学术灵感相互碰撞,迸发出更多的可能性。
PaperWeekly 鼓励高校实验室或个人,在我们的平台上分享各类优质内容,可以是最新论文解读,也可以是学术热点剖析、科研心得或竞赛经验讲解等。我们的目的只有一个,让知识真正流动起来。
稿件基本要求:
• 文章确系个人原创作品,未曾在公开渠道发表,如为其他平台已发表或待发表的文章,请明确标注
• 稿件建议以 markdown 格式撰写,文中配图以附件形式发送,要求图片清晰,无版权问题
• PaperWeekly 尊重原作者署名权,并将为每篇被采纳的原创首发稿件,提供业内具有竞争力稿酬,具体依据文章阅读量和文章质量阶梯制结算
投稿通道:
• 投稿邮箱:[email protected]
• 来稿请备注即时联系方式(微信),以便我们在稿件选用的第一时间联系作者
• 您也可以直接添加小编微信(pwbot02)快速投稿,备注:姓名-投稿

△长按添加PaperWeekly小编
现在,在「知乎」也能找到我们了
进入知乎首页搜索「PaperWeekly」
点击「关注」订阅我们的专栏吧
·
·
