ClickHouse学习笔记(五):ClickHouse 副本与分片
文章目录
- 1、概述
- 2、数据副本
-
- 2.1、副本的特点
- 2.2、副本的定义形式
- 3、ReplicatedMergeTree 原理解析
-
- 3.1、数据结构
-
- 3.1.1 ZooKeeper 内的节点结构
- 3.1.2 Entry 日志对象的数据结构
- 3.2、副本协同的核心流程
-
- 3.2.1、INSERT 的核心执行流程
- 3.2.2、MERGE 的核心执行流程
- 3.2.3、MUTATION 的核心执行流程
- 3.2.4、ALTER 的核心执行流程
- 4、数据分片
-
- 4.1、基于集群实现分布式 DDL
-
- 4.1.1、数据结构
- 4.1.2、分布式 DDL 的核心执行流程
- 5、Distributed 原理解析
-
- 5.1、定义形式
- 5.2、分片规则
- 5.3、分布式写入的核心流程
- 5.4、分布式查询的核心流程
1、概述
副本和分片类似双胞胎兄弟,提供两种方式区分:
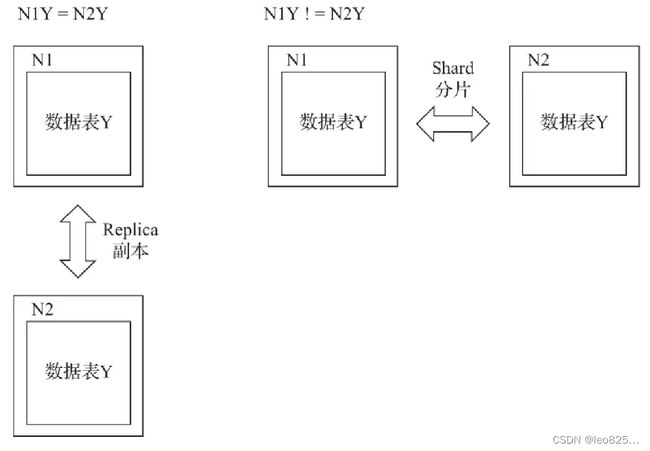
- 第一种:从数据层面区分,假设 ClickHouse 的 N 个节点组成了一个集群,在集群的各个节点上,都有一张结构相同的数据 Y。如果 N1 的 Y 和 N2 的 Y 中的数据完全不同,则 N1 和 N2 互为分片;如果他们的数据完全相同,则他们互为副本。
分片之间的数据是不同的,副本之间的数据是完全相同的。 - 第二种:从功能作用层面区分,使用
副本的主要目的是防止数据丢失,增加数据存储的冗余;而使用分片的主要目的是实现数据的水平切分。
2、数据副本
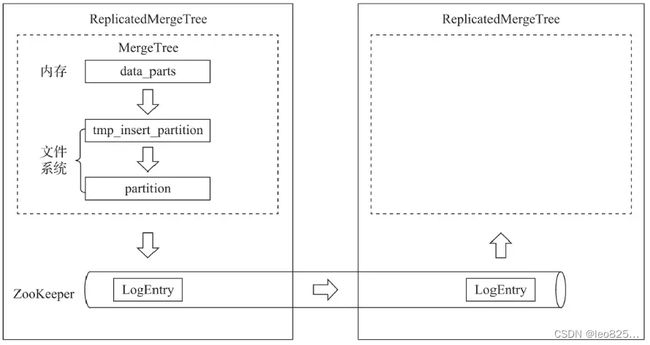
(1)只有使用了 ReplicatedMergeTree 复制表系列引擎,才能应用副本的能力。
(2)ReplicatedMergeTree 增加了 Zookeeper 部分,会进一步在 ZooKeeper 内创建一系列的监听节点,并以此实现实例之间的通信。
(3)ZooKeeper 不会设计表数据传输。
ReplicateMergeTree 与 MergeTree 的逻辑关系示意:
2.1、副本的特点
- 依赖 ZooKeeper:INSERT 和 ALTER 的时候借助 ZooKeeper 实现多个副本之间的同步。但是查询副本的时候,并不需要使用 ZooKeeper。
- 表级别的副本:副本是在表级别定义的,包括副本的数量,以及副本在集群内的分布位置等。
- 多主架构(Multi Master):可以再任意一个副本上执行 INSERT 和 ALTER ,他们效果是相同的。
- Block 数据块:在执行 INSERT 写入数据时,会依据 max_insert_block_size 的大小(默认 1048576 行)将数据切分成若干个 Block 数据块。Block 块是数据写入的基本单元,并且具有写入的原子性和唯一性。
- 原子性:一个 Block 块要么全部写成功,要么全部失败。
- 唯一性:写入 Block 按照数据块顺序、数据行和数据大小等指标,计算 Hash 信息摘要并记录在案,后续若有重复则忽略。预防由于异常导致重复写入的问题。
2.2、副本的定义形式
ReplicatedMergeTree 的定义方式如下:
ENGINE = ReplicatedMergeTree('zk_path', 'replica_name')
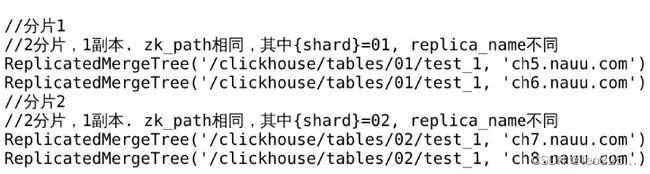
zk_path 用于指定 ZooKeeper 中创建的数据表的路径,一般命名格式为 /clickhouse/tables/{shard}/table_name,{share} 表示分片编号,table_name 表示数据库表的名称。replica_name 是定义在 ZooKeeper 中创建的副本名称,是区分不同副本实例的唯一标识。
- zk_path:同一张表数据的同一个分片的不同副本,应该定义相同的路径
- replica_name:同一张数据表的同一个分片的不同副本,应该定义不同的名称。
3、ReplicatedMergeTree 原理解析
3.1、数据结构
3.1.1 ZooKeeper 内的节点结构
ReplicatedMergeTree 需要依靠 ZooKeeper 的事件监听机制以实现各个副本之间的协同,按照作用的不用,监听节点大致分为如下几类:
(1) 元数据:
- /
metadata: 保存元数据信息,包括主键、分区键、采样表达式等。 - /
columns:保存列字段信息,包括列名称和数据类型。 - /
replicas: 保存副本名称,对应设置参数中的 replica_name。
(2) 判断标识:
- /
leader_election:用于主副本的选举工作,主副本会主导 MERGE 和 MUTATION 操作(ALTER DELETE 和 ALTER UPDATE)。这些任务在主副本完成之后再借助 ZooKeeper 将消息时间分发至其他副本。 - /
blocks:记录 Block 数据块的 Hash 信息摘要,以及对应的 partition_id。通过 Hash 摘要能够判断 Block 数据块是否重复;通过 partition_id 则能够找到需要同步的数据分区。 - /
quorum:记录 quorum 的数量,当至少有 quorum 数量的副本写入成功之后,整个操作才算成功。quorum 的数量由 insert_quorum 参数控制,默认值为 0.
(3) 操作日志:
- /
log:常规操作日志节点(INSERT、MERGE 和 DROP PARTITION),它是整个工作机制中最为 重要的一环,保存了副本需要执行的任务指令。 - /
mutations:MUTATION 操作日志节点,作用与 log 日志蕾西,当执行 ALTER DELETE 和 ALTER UPDATE 时,操作指令会被添加到这个节点。 - /
replicas/(replica_name)/*: 每个副本各自的节点下的一组监听节点,用于指导副本在本地执行具体的任务指令,其中较为 重要的节点如:
(1)/queue:任务队列节点,用于执行具体的操作任务。当副本从/log或/mutations节点监听到操作指令时,会将执行任务添加至该节点下,并基于队列执行。
(2)/log_pointer:log日志指针节点,记录了最后一次执行的log日志下标信息。
(3)/mutation_pointer:mutations日志指针节点,记录了最后一次执行的mutations日志名称。
3.1.2 Entry 日志对象的数据结构
ReplicatedMergeTree 在 ZooKeeper 中有两组非常重要的父节点,那就 /log 和 /mutations。它们的作用是分发操作指令的信息通道,而发送指令的方式,则是为这些父节点添加子节点。/log 和 /mutations 具体实现对象为 LogEntry 和 MutationEntry。
(1) LogEntry
source replica:发送这条 Log 指令的副本来源,对应 replica_name。
type:操作指令类型,主要有 get、merge 和 mutate 三种,分别对应从远程副本下载分区、合并分区和 MUTATION 操作。
block_id:当前分区的 BlockID,对应 /blocks 路径下子节点的名称。
partition_name:当前分区目录的名称。
(2) MutationEntry
source replica:发送这条 MUTATION 指令的副本来源,对应 replica_name。
commands:操作指令,主要有 ALTER DELETE 和 ALTER UPDATE。
mutation_id:MUTATION 操作的版本号。
partition_id:当前分区目录的 ID。
3.2、副本协同的核心流程
副本协同的核心流程主要有 INSERT、MERGE、MUTATION 和 ALTER 四种,分别对应了数据写入、分区合并、数据修改和元数据修改。使用 ReplicatedMergeTree 实现一张拥有 1 分片、1 副本的数据表,来了解相应的工作原理。
3.2.1、INSERT 的核心执行流程
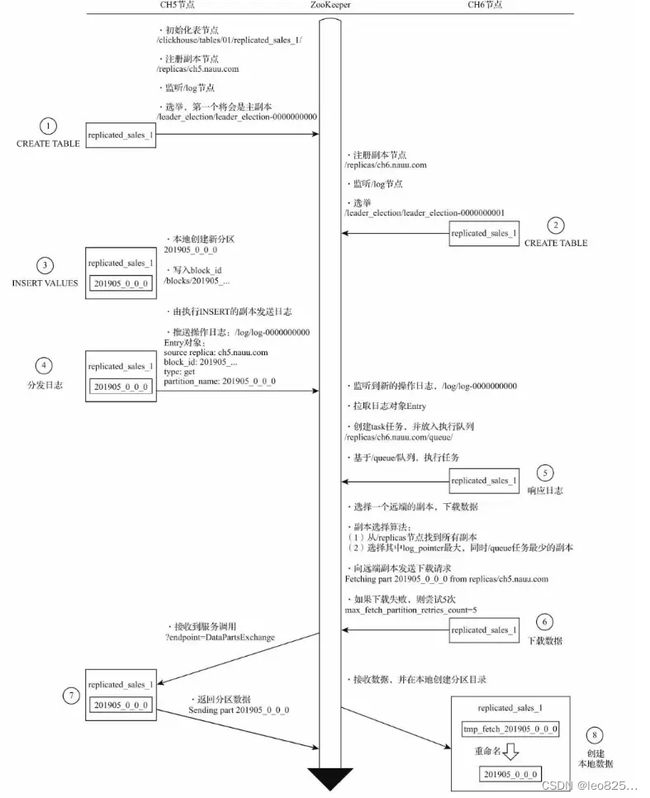
主要的过程分为三步:
(1)由执行了 INSERT 操作的副本向 /log 节点推送操作日志
(2)副本会一直监听 /log 节点变化,拉取 LogEntry,将其转为任务对象放至 /queue 队列
(3)基于 /queue 队列开始执行任务,会选择一个远端副本作为数据的下载来源。选择拥有最大的 log_pointer(执行日志最多),/queue 子节点数量最少(该副本目前的任务执行负担较小)。然后建立起连接开始下载。
3.2.2、MERGE 的核心执行流程
无论 MERGE 操作从哪个副本发起,其合并计划都会由主副本来执行(zk 副本选举产生)。
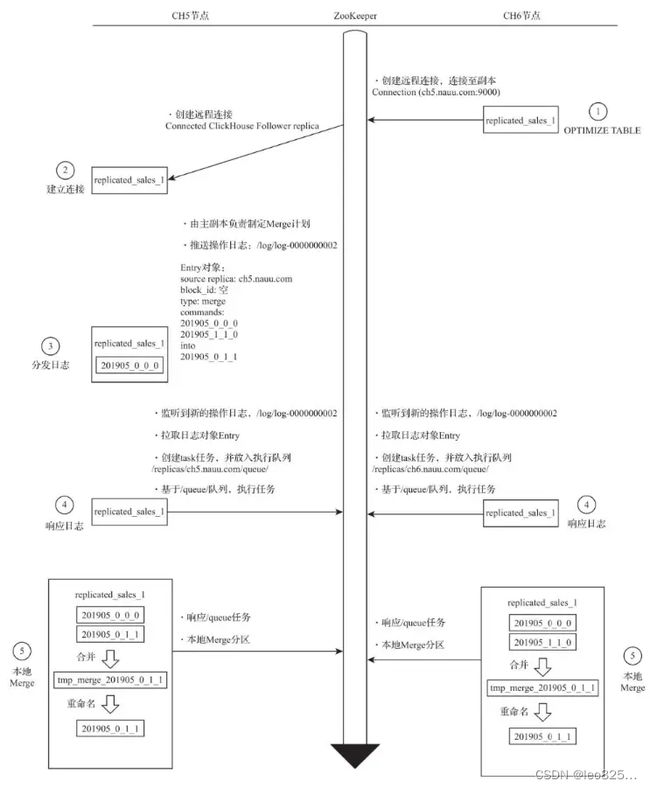
主要步骤如下:
(1)执行 OPTIMIZE 触发 MERGE 合并
(2)创建远程连接进行主副本通信
(3)主副本制定 MERGE 计划并推送 Log 日志
(4)各个副本监听 /log 日志的推送,分别拉取知道到本地,并推送到各自的 /queue 任务队列
(5)各个副本分别在本地执行 MERGE
特别注意:
在 MERGE 的合并过程中,ZooKeeper 也不会进行任何实质性的数据传输,所有的合并操作,最终都是由各个副本在本地完成的。
3.2.3、MUTATION 的核心执行流程
无论 MUTATION 操作从哪个副本发起,其合并计划都会由主副本来执行(zk 副本选举产生)。当进行 ALTER DELETE 或者 ALTER UPDATE 操作的时候会进入 MUTATION 部分的逻辑。
主要步骤如下:
(1)执行 DELETE(UPDATE 效果与此相同) 触发 MUTATION 操作
(2)所有副本实例各自监听 MUTATION 日志
(3)由主副本 实例响应 MUTATION 日志并推送 Log 日志
(4)各个副本监听 /log 日志的推送,分别拉取知道到本地,并推送到各自的 /queue 任务队列
(5)各个副本分别在本地执行 MUTATION
3.2.4、ALTER 的核心执行流程
ALTER 操作进行元数据修改的时候,即会进入 ALTER 部分的逻辑,例如增加、删除表字段等。
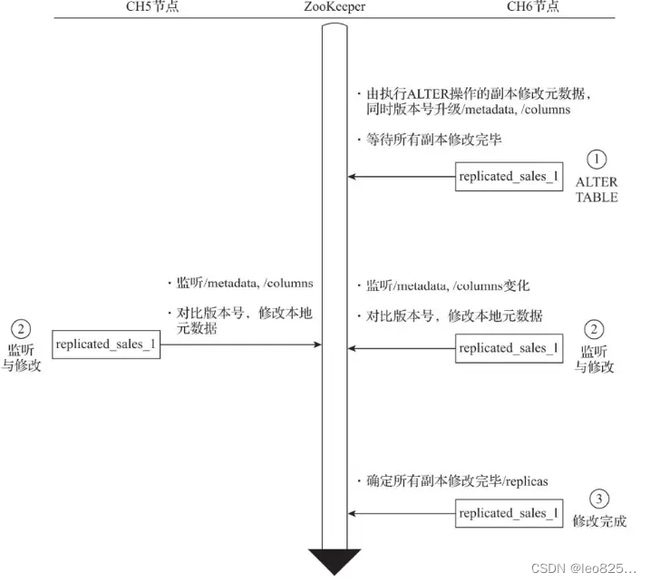
(1)修改共享元数据
(2)监听共享元数据变更并各自执行本地修改
(3)确认所有副本完成修改
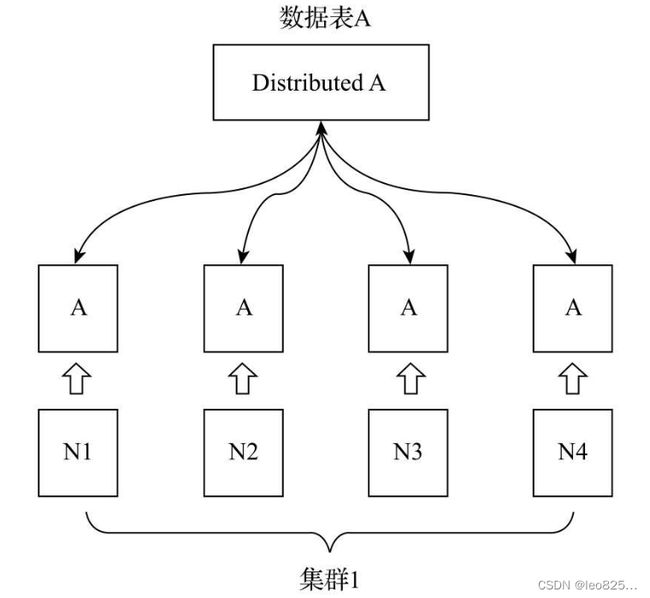
4、数据分片
- ClickHouse 中每个服务节点都称为一个 shard
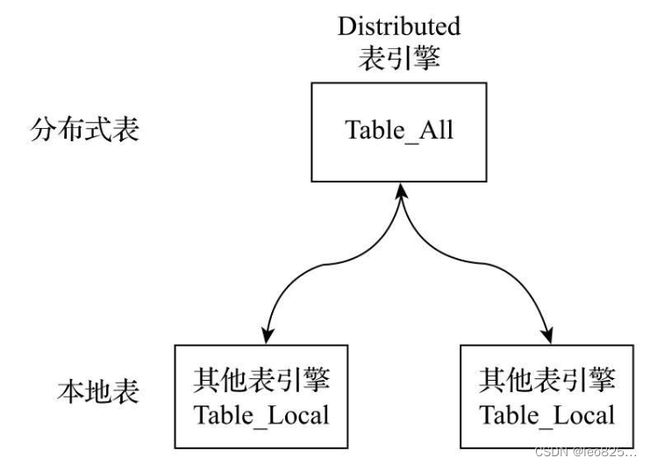
- ClickHouse 数据分片需要结合 Distributed 表引擎一同使用,使得查询、写入能够进行路由。
- Distributed 表引擎本身不存储任何数据,只是作为分布式表的议程透明代理。
Distributed 分布式表引擎与分片的关系示意图:
4.1、基于集群实现分布式 DDL
语法形式如下:
CREATE/DROP/RENAME/ALTER TABLE ON CLUSTER cluster_name
其中,cluster_name 对应了配置文件中的集群名称,ClickHouse 会根据集群的配置信息分别去各个节点执行 DDL 语句。
4.1.1、数据结构
- 默认分布式 DDL 在 ZK 内使用的根路径为
/clickhouse/task_queue/ddl - /query-[seq]/active(用于状态监控等用途) /query-[seq]/finished(用于检查任务完成情况)
- DDLLogEntry 日志对象数据中包含了 query、hosts、initiator
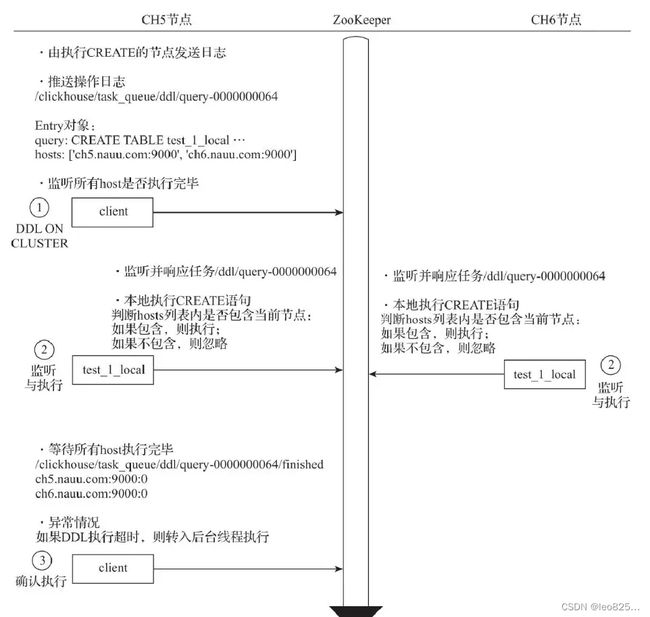
4.1.2、分布式 DDL 的核心执行流程
(1)推送 DDL 日志:谁执行谁负责推送
(2)拉取日志并执行:拉取日志到本地。
(3)确认执行进度:步骤 1 执行后,客户端会阻塞180秒,等待所有 host 执行完毕。
5、Distributed 原理解析
- 由两部分组成,本地表和分布式表,分布式表以all后缀命名。
- 采用读时检查,如果它们表结构不兼容,只有在查询时才抛出错误。
5.1、定义形式
ENGINE = Distributed(cluster, database, table [,shaeding_key])
- cluster 集群名称
- sharding_key 分片键,选填参数
- Distributed表不支持任何MUTATION类型操作
建表语句示例:
CREATE TABLE test_shard_2_all ON CLUSTER sharding_simple ()
ENGINE = Distributed(sharding_simple, defalult, test_shard_2_local, rand())
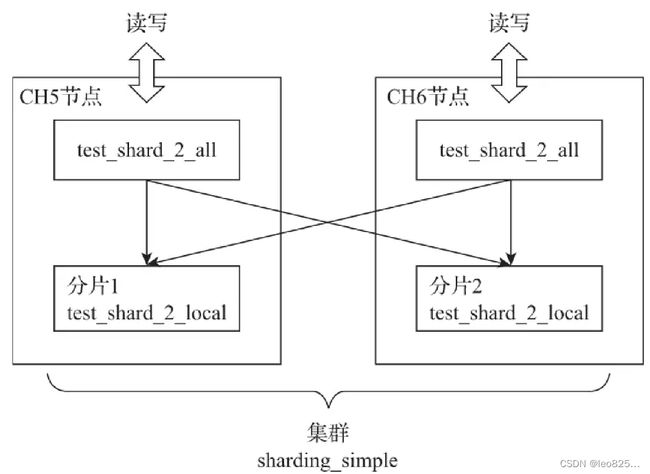
5.2、分片规则
- 分片权重(weight)
集群配置的分片权重,权重越大,写入数据越多 - slot(槽)
slot 数量等于所有分片的权重之和 - 选择函数
slot = shard_value % sum_weight
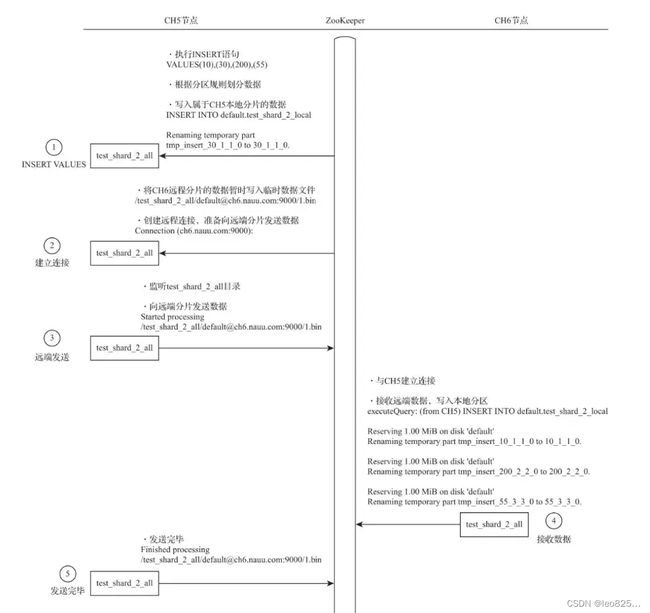
5.3、分布式写入的核心流程
- 在第一个分片节点写入本地分片数据
- 建立远端连接,准备发送远端数据分片
- 发送数据
- 远端分片写入本地
- 第一个分片确认完成写入
副本写入核心流程:
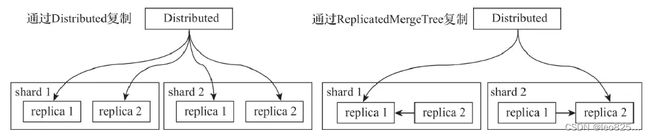
- 一种是继续借助 Distributed 表引擎,由它将数据写入副本
- 另一种则是借助 ReplicatedMergeTree 表引擎实现副本数据的分发
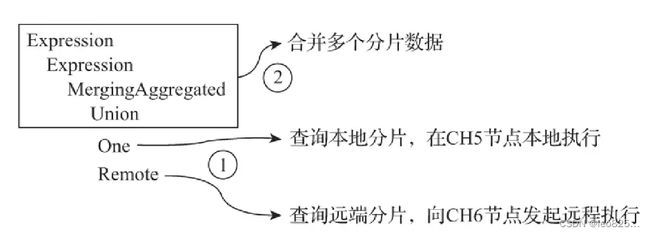
5.4、分布式查询的核心流程
-
多副本路由:randon(默认负载均衡算法)、nearest_hostname(错误最少 replica)、in_order(错误最少 replica 中的按定义逐个选择)、first_or_random(错误最少首选第一个 replica) 四种方式
-
分布式查询是在本地查之后 union 的结果
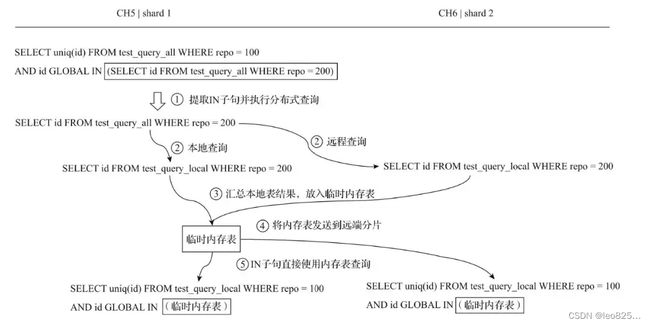
使用Global优化分布式子查询
(1) 使用本地表的问题
SELECT uniq(id) FROM test_query_all WHERE repo = 100 AND id IN (SELECT id FROM test_query_local WHERE repo = 200)
(2)扫的本地表里刚好没有这个数据,有希望在全局里找
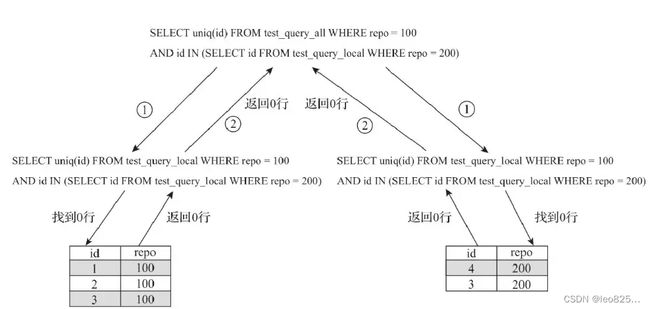
(3)使用分布式表又会有查询放大的问题,每次扫all都是全局广播,就会变成指数增长
SELECT uniq(id) FROM test_query_all WEHRE repo = 100 AND id IN (SELECT id FROM test_query_all WHERE repo = 200)
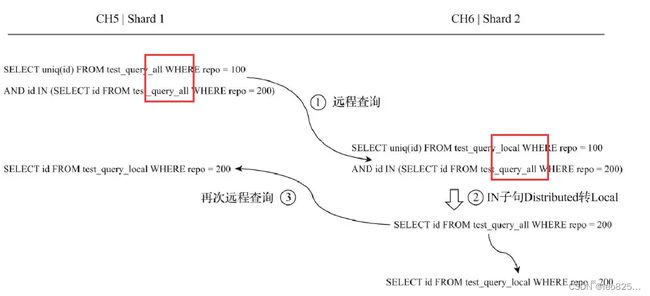
(4)所以有一个 GLOBAL 关键字,可以将中间过程缓存