LINUX运维知识点总结(容器;云计算)
目录
一、Linux基础篇
1、描述Linux系统的启动过程
2、描述Linux下软硬链接的区别
3、如何查看和修改Linux进程优先级
查看进程优先级
修改进程优先级
4、如何将Centos.ISO文件挂载 到/mnt/cdrom
5、查找/opt/tomcat/目录下含有“JDBC”的 jsp类型的文件
6、如何查看Linux服务器运行级别
7、如何查看Linux服务器系统和内核版本
8、某系统管理员需每天做一定的重复工 作,请按照下列要求,编制一个解决方案
9、如何查看一个文件夹inode节点数有多少?
11、如果某文件夹下文件太多无法ls该如 何解决?
12、如何用tcpdump嗅探80端口的访问看看谁最高?
13、如何查看/var/log目录下的文件数?
14、如何查看Linux系统每个ip的连接数?
15、shell下生成32位随机密码
16、统计出apache的access.log中访问量最多的5个ip
17、如果一台办公室内电脑无法上网(打 不开网站),请给出你的排查步骤?
18、如何选择Linux操作系统版本?
19、分析为什么一块磁盘空间足够却不能在上面创建文件?
20、简述Linux系统软件包安装方式及特点
二进制包安装
软件包类型
二、网络篇
1、请描述 TCP/IP协议中主机与主机之间通信的三要素
2、请描述 A、B、C 三类IP地址的默认子网掩码
3、请描述预留给企业的私有网络使用的私有IP有哪三段
4、请简要描述交换机的作用及工作原理
5、请简要描述TCP/IP四次模型中每层的协议
6、请简述tcp协议和udp协议的区别
TCP协议:
UDP协议:
总结:
7、请简单描述tcp协议三次握手和四次断开过程
三次握手 TCP三次握手的过程如下:
四次断开TCP四次断开的过程如下:
8、简述什么是TTL ,它的作用以及原理
9、简述三层交换机作用
10、请简述NAT的作用及优缺点
11、请简述NAT三种实现方式的区别
12、STP是什么协议,有什么作用
13、简述静态路由,动态路由是什么以及特点是
14、增加一条由网关192.168.9.1到达192.168.1.0网络的路
15、网站出现500,502,400,403,404都是什么意思,怎么排查和解决
三、Linux系统服务篇
1、请描述SMTP及POP3分别是什么协议、 作用及端口号
2、请描述http及https分别是什么协议、作用及端口号
3、如何将本地80端口的请求转发到本地8080端口
4、简述FTP的主被动模式
5、请简述http请求过程,并描述http常见的两种请求方法GET和POST的区别
6、请简述SSH免密登录的原理
7、简述企业中常见的文件共享服务及特点
8、简述DNS域名解析过程和原理
9、Linux下如何挂载windows共享目录
10、网站打开不了或者慢如何分析?
四、SHELL编程篇
2、编写脚本清理指定目录的空白普通文件
3、写一个脚本,实现判断192.168.1.0/24 网络里,当前在线的IP有哪些,能ping通则认为在线
4、统计网站访问IP的数量及PV量
6、编写脚本将当前目录所有文件扩展名改为log
7、编写脚本部署LNMP环境
8、写一个自动检测磁盘使用率的脚本,当磁盘使用空间达到90%以上时,需要发送邮件给相关人员
9、写一个脚本监控系统内存和交换分区使用情况
10、写一个倒计时脚本,要求显示离2020年10月1日(国庆节)的凌晨0点,还有多少天,多少时,多少分,多少秒。
五、系统架构篇
1、 linux系统nginx与Php环境,发现PHP-FPM进程高,请说出可能的原因以及如何解决?
2、Nginx反向代理如何实现代理RS节点上 的不同虚拟主机,请说出原理和配置方法或思路
3、如何实现nginx代理的节点访问日志记录的是真实访客的IP,不是代理的IP
4、描述Tomcat的8005、8009、8080三个 端口的含义?
5、描述Tomcat的三种工作模式(Bio、Nio 和Apr)的工作原理
6、请解释Tomcat 中使用的连接器是什么 ?
7、请简述Tomcat调优的大概思路
8、请简单描述nginx与php-fpm的两种连接方式及其优缺点
9、写出你常用的Nginx模块及作用
10、简述Nginx支持的几种负载均衡模式,并指出各模式的应用场景
11、简述Apache 与 Nginx的优缺点
12、简述keepalived的工作原理
13、简单描述keepalive的如何实现高可用
14、简单介绍常见的几种负载均衡方式的比较及工作中如何选择
15、简单描述HTTP与 HTTPS有什么区别
16、简单描述一下你所了解的web应用攻击方式
DDoS(洪水攻击):
SQL注入:
DOS攻击:
OS命令注入攻击:
17、简单介绍lvs的三种负载均衡机制
1、NAT模型
2、DR模型
3、TUN模型
18、简述Redis与Memcached区别及优势?
19、为什么Redis需要把所有数据放到内存中?
20、简述Redis的常见使用场景?
1.会话缓存(Session Cache)
2.队列
3.全页缓存(FPC)
4.排行榜/计数器
5.发布/订阅
21、Redis集群会有写操作丢失吗?为什么?
22、描述一下redis常见的数据结构类型
23、Redis是单线程的,如何提高多核CPU的利用率?
24、简单描述Redis常见性能问题和解决方案?
25、Mongodb 熟悉吗,一般部署几台?
26、CDN是什么?
27、 linux系统nginx与Php环境,发现PHP-FPM进程高,请说出可能的原因以及如何 解决?
28、什么是中间件?什么是jdk?
29、Tomcat和Resin有什么区别,工作中你怎么选择?
30、Squid、Varinsh和Nginx有什么区别,工作中你怎么选择?
六、磁盘管理及存储篇
1、如何检测并修复磁盘/dev/sdb?
2、如何备份当前系统磁盘的分区表?
3、磁盘报错:nospace lex on device,但是df-h查看空间没有满,为什么?
4、web服务器的磁盘空间满了,删除一部分nginx日志后,但是磁盘空间还是满的,为什么?
5、有一块新硬盘/dev/sdf,容量4TB,Linux 系统中一个应用程序需要在/data目录使用此存储的500G的存储空间需要哪些步骤,请描述。
6、简单描述常见的RAID级别及特点
7、存储类型的分类有哪几种?并简单进行描述各自优缺点
8、简单描述DAS、NAS、SAN使用场景及优缺点常
9、什么是分布式存储,它的优点有哪些?
10、简单介绍一下你所了解的Ceph和GlusterFS
七、自动化运维篇
1、什么是灰度发布?
2、你们公司代码是怎么发布和回滚的?
3、用图简单描述jenkins打包部署过程
4、你们公司监控是用什么实现的?
5、简单描述一下zabbix如何实现实时监控,监控了多少客户端 客户端是怎么进行批量安装的?
6、zabbix自定义发现是怎么做的,微信报警如何实现?
7、jenkins你都用了哪些插件?
8、介绍一下ansible的特性及常用模块
9、Ansbile工具的shell、script模块的区 别?
10、描述一下ELK分别代表什么,各有什么特点
11、ELK中的logstash 是怎么收集日志的,在客户端的 logstash 配置文件主要有哪些内容?
12、现在给你三百台服务器,你怎么对他们进行管理?
13、简述一下优化Linux系统的大概思路?
八、数据库管理篇
1、简单描述一下MySQL的基本逻辑架构
2、请列出MySQL常用的数据类型,并写出定义这些数据类型所使用的关键字
4、简述MySQL数据库访问的执行过程
5、写出查找customer表中uid列内大于100的记录并以uid排序,正序输出前10条记录的SQL语句
6、介绍一下备份MySQL数据库的常用工具及特点
一、社区版安装包中的备份工具
二、企业版安装包中的备份工具
三、第三方备份工具XtraBackup和innobackupex(物理备份)
四、mydumper多线程备份工具(逻辑备份,备份SQL语句)
7、简单描述下在做数据库备份时都需要考虑哪些因素?
8、什么是冷/热备份?他们各自有什么优点和缺点?
9、什么是存储引擎?最常用的存储引擎有哪些?
10、介绍一下MySQL的二进制日志作用?
11、为了保证数据库安全性,开启二进制日志后,该文件会越来越大,如何正确清理?
12、简述一下MySQL主从复制的原理
13、描述一下关系型数据库中事务的四大特性
14、如果mysql管理员密码忘了,如何找回?
15、什么是MySQL多实例,如何配置MySQL多实例?
16、如何加强MySQL安全,请给出可行的具体措施?
18、分析一下mysql无法启动可能的原因
19、如果你们公司的网站访问很慢,你会如何排查 ?
20、线上全是 mysql 5.5 的环境,有没有办法搭建5.5到5.7的复制?
九、Linux云计算篇
1、使用云计算有哪些优点?可否列举哪些平台用于大规模云计算?
用于大规模云计算的平台包括:
2、简述云计算的实现方式有哪些?
3、描述一下OpenStack的常见组件有哪些?
4、OpenStack的核心服务有哪些?
5、容器退出后,通过docker ps 命令查看不到,数据会丢失么?
6、如何控制容器占用系统资源(CPU,内存)的份额?
7、如何更改Docker的默认存储设置?
8、Docker公司的三款用于解决多容器分布式软件可移植部署的问题,推出的编排工具有哪些?
9、简单描述Docker-compose编排和管理多容器的过程?
10、简单描述云计算与虚拟化区别?
11、写出hadoop集群常用进程以及进程含义
12、在使用云计算平台前,用户需要考虑哪些必要的方面?
13、云架构有别于传统架构的特点有哪些?
14、简单列出云计算的基本特点?
15、什么是Kubernetes?Kubernetes与Docker有什么关系?
什么是kubernetes?
kubernetes和Docker关系:
16、Kubernetes如何简化容器化部署?
17、你对Kubernetes的负载均衡器有什么了解?
18、您如何看待公司从单一服务转向微服务并部署其服务容器?
19、公司希望通过维持最低成本来提高其效率和技术运营速度,您认为公司将如何实现这一目标?
20、假设公司希望在不同的云基础架构上运行各种工作负载,从裸机到公共云。公司将如何在不同界面的存在下实现这一目标?
十、python编程篇
1、脚本生成随机的20个ID
2、写脚本判断密码强弱
3、写脚本列举当前目录以及所有子目录下的文件,并打印出绝对路径
4、写脚本生成磁盘使用情况的日志文件
5、写脚本统计出每个IP的访问量有多少?(从日志文件中查找)
一、Linux基础篇
1、描述Linux系统的启动过程
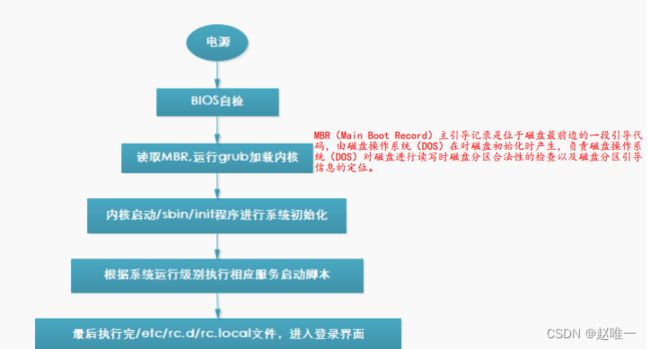
2、描述Linux下软硬链接的区别
1. 硬链接文件与源文件的 inode 节点号相同,而软链接文件的 inode 节点号,与源文件不同。2. 不能对目录创建硬链接,但可以创建软链接。对目录的软链接会经常使用到。3. 删除文件的硬链接文件,对源文件无任何影响;同时删除源文件及其硬链接文件,整个文件才会被真正的删除。4. 软链接文件,如果删除源文件,会导致其软链接失效(红底白字闪烁状)。5. 软链接可以跨文件系统,硬链接不可以跨文件系统。
3、如何查看和修改Linux进程优先级
查看进程优先级
# top或者# ps -exo pid,pri,nice,command
修改进程优先级
通过修改正在运行进程的 nice 值来修改优先级:# renice 优先级 进程 ID或者# top——> 按 “r” 来修改程序运行时来指定优先级:# nice -n 优先级 程序说明:1. 启动进程时,通常会继承父进程的 nice 级别,默认为 0 。2. 优先级的范围: - 20 —— 19 ;数字越低,优先级越高,系统会按照更多的 cpu 时间给该进程
4、如何将Centos.ISO文件挂载 到/mnt/cdrom
mount -o ro /xxx/Centos.ISO /mnt/cdrom开机自动挂载:
echo "mount -o ro /xxx/Centos.ISO /mnt/cdrom" >> /etc/rc.local5、查找/opt/tomcat/目录下含有“JDBC”的 jsp类型的文件
find /opt/tomcat -type f -name "*JDBC*.jpg"6、如何查看Linux服务器运行级别
runlevel或者systemctl get-default ( RHELE7 + 或 Centos7 + )
7、如何查看Linux服务器系统和内核版本
lsb_release -dcat /etc/redhat-releaseuname -r8、某系统管理员需每天做一定的重复工 作,请按照下列要求,编制一个解决方案
解答:编写三个计划任务分别完成以上要求,使用命令 crontab - e 进入编辑模式1 ) 50 16 * * * rm - rf / abc /*2 ) * 08 - 18 / 1 * * * awk '{print $1}' / xyz / x1 >> / backup / bak01.txt3 ) 50 17 * * 1 tar - zcf backup.tar.gz / data
9、如何查看一个文件夹inode节点数有多少?
find /目录 ‐xdev ‐printf '%h\n' | sort | uniq ‐c | sort ‐ k 1 ‐nfind 查找路径 -ctime +3 -name '*.log' -deletefind 查找路径 -ctime +3 -name '*.log' -exec rm -rf {} \;find 查找路径 -ctime +3 -name '*.log' |xargs rm -f11、如果某文件夹下文件太多无法ls该如 何解决?
ls -f 或 ls -aU12、如何用tcpdump嗅探80端口的访问看看谁最高?
tcpdump -i eth0 -tnn dst port 80 -c 10|awk -F. '{print $1"."$2"."$3"."$4}'|sort |uniq -c|sort -nr13、如何查看/var/log目录下的文件数?
ls /var/log/ -1R|grep -|wc -l14、如何查看Linux系统每个ip的连接数?
netstat -n|awk '/^tcp/{print$5}'|awk -F: '{print $1}'|sort |uniq -c|sort -nr15、shell下生成32位随机密码
cat /dev/urandom |head -1|md5sum |head -c 3216、统计出apache的access.log中访问量最多的5个ip
cat access.log | awk '{print $1}' | sort | uniq ‐c | sort -nr | head ‐517、如果一台办公室内电脑无法上网(打 不开网站),请给出你的排查步骤?
1. 首先检查物理网线是否 ok2. 其次确认确认本机 DNS 是否 ok ,可以使用电脑管家相关软件检测3. 确认本机的 IP, 子网掩码,默认网关是否设置合理4. ping 一下网关,如果不通则检查上层网络设备,如交换机,路由器等5. 确定上层链路没问题,同一局域网内其他主机没问题后,可以尝试换跟网线或者换个插口试试
18、如何选择Linux操作系统版本?
一般来讲,桌面用户首选 Ubuntu ;服务器首选 RHEL 或 CentOS ,两者中首选 CentOS 。根据具体要求:1. 安全性要求较高,则选择 Debian 或者 FreeBSD 。2. 需要使用数据库高级服务和电子邮件网络应用的用户可以选择 SUSE 。3. 想要新技术新功能功能可以选择 Feddora , Feddora 是 RHEL 和 CentOS 的一个测试版和预发布版本。4. 根据现有状况,绝大多数互联网公司选择 CentOS 。现在比较常用的是 6 和 7 系列,现在市场占有大概一半左右。另外的原因是 CentOS 更侧重服务器领域,并且无版权约束。
19、分析为什么一块磁盘空间足够却不能在上面创建文件?
1. 首先,确保当前用户有权限在此设备上创建文件。比如,是否设置了磁盘配 额,或者该文件系统只读等。2. 其次,使用 df - ih / dev / sdb (设备名)查看设备 inode 的使用率, 100 % 说明没有空的 inode 号了,可以通过清理磁盘上的空白小文件解决df -ih /dev/sdb3.最后,看看该设备是本地还是网络设备,如果是网络设备还要检查是否网络原 因造成。
20、简述Linux系统软件包安装方式及特点
二进制包安装
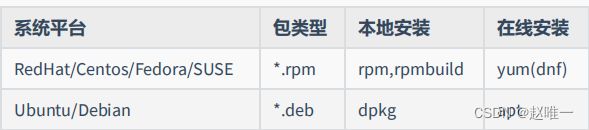
软件包类型

二、网络篇
1、请描述 TCP/IP协议中主机与主机之间通信的三要素
IP 地址( IP address )子网掩码( subnet mask )IP 默认路由( IP router )
2、请描述 A、B、C 三类IP地址的默认子网掩码
A 类 255.0.0.0B 类 255.255.0.0C 类 255.255.255.0
3、请描述预留给企业的私有网络使用的私有IP有哪三段
A 类 10.0.0.1 - 10.255.255.254B 类 172.16.0.1 - 172.16.31.254C 类 192.168.0.1 - 192.168.255.254
4、请简要描述交换机的作用及工作原理
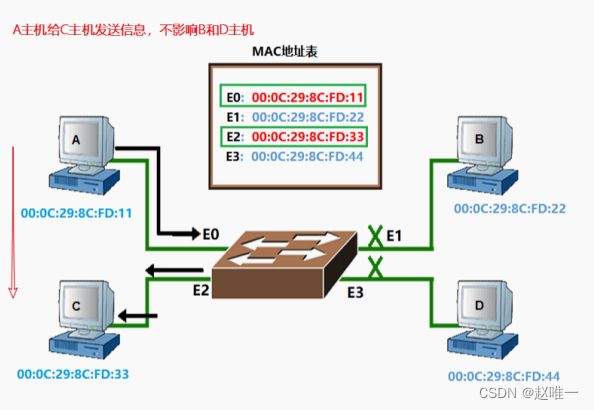
交换机的作用,用来连接多台计算机进行通讯或者组建局域网。交换机的特点及原理:- 交换机的每一个端口所连接的网络都是独立的,也就是独享带宽;- 进行地址学习(源端和目标端的 MAC 地址),维护一张 MAC 地址表- 隔离冲突域。因为每个端口都有一条独占的带宽,当两个端口工作时不影响其它端口的工作。
5、请简要描述TCP/IP四次模型中每层的协议
应用层(用户进程): http 、 ssh 、 ftp 、 dhcp 等等传输层: tcp 、 udp网络层: ICMP 、 IP 、 IGMP链路层: ARP 、 RARP
6、请简述tcp协议和udp协议的区别
TCP协议:
为两台主机提供高可靠性的数据通信。 TCP 是面向连接的通信协议,通过三次握手建立连接,通讯完成时要断开连接,由于 TCP 是面向连接的所以只能用于端到端的通讯。 TCP 提供的是一种可靠的数据流服务,采用 “ 带重传的肯定确认” 技术来实现传输的可靠性。也就是 TCP 数据包中包括序号( seq )和确认( ack ),所以未按照顺序收到的包可以被排序,而损坏的包可以被重传。
UDP协议:
为应用层提供一种非常简单的服务。它是面向无连接的通讯协议, UDP 数据包括目的端口号和源端口号信息,由于通讯不需要连接,所以可以实现广播发送。 UDP 通讯时不需要接收方确认,不保证该数据报能到达另一端,属于不可靠的传输,可能会出现丢包现象。
总结:
7、请简单描述tcp协议三次握手和四次断开过程
三次握手 TCP三次握手的过程如下:
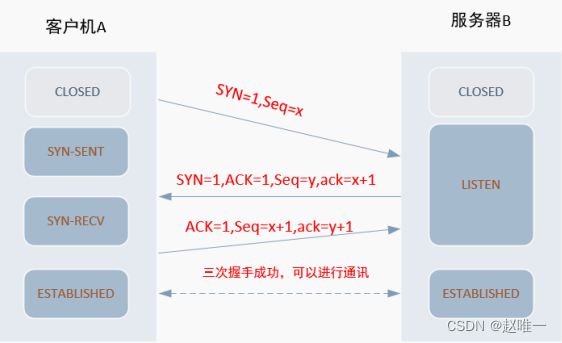
1. 客户机 A 端(主动连接端)发送一个 SYN 包给服务器 B 端(被动连接端);2. 服务器 B 端(被动连接端)收到 SYN 包后,发送一个带 ACK 和 SYN 标志的包给客户机 A 端(主动连接端);3. 客户机 A 端(主动连接端)发送一个带 ACK 标志的包给服务器 B 端(被动连接端),握手动作完成。
四次断开TCP四次断开的过程如下:
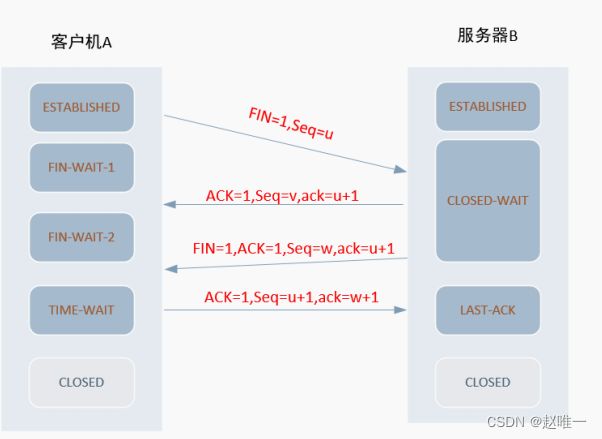
1. 客户机 A 端(主动连接端)发送一个 FIN 包给服务器 B 端(被动连接端)请求断开连接;2. 服务器 B 端(被动连接端)收到 FIN 包后,发送一个 ACK 包给客户机 A 端(主动连接端);3. 服务器 B 端(被动连接端)发送了 ACK 包后,再发送一个 FIN 包给客户机 A 端(主动连接端)确认断开;4. 客户机 A 端(主动连接端)收到 FIN 包后,发送一个 ACK 包,当服务器 B 端(被动连接端)收到 ACK 包后,四次断开动作完成,连接断开。
8、简述什么是TTL ,它的作用以及原理
TTL 指的是数据生命周期作用:避免数据在网络中无限循环转发原理:当网络中的数据包每经过一个路由器 TTL 值减 1 ,当 TTL 值为 0 时,数据包丢弃。
9、简述三层交换机作用
三层交换机是具有网络层功能的交换机,三层交换 = 二层交换 + 三层转发,使用三层交换技术实现 VLAN 间通信。
10、请简述NAT的作用及优缺点
通过将内部网络的私有 IP 地址翻译成全球唯一的公网 IP 地址,使内部网络可以连接到互联网等外部网络上。优点:1. 节省公有合法 IP 地址2. 处理地址重叠3. 增强灵活性4. 安全性缺点:1. 延迟增大2. 配置和维护的复杂性3. 不支持某些应用,可以通过静态 NAT 映射来避免
11、请简述NAT三种实现方式的区别
1. 静态转换的对应关系一对一且不变,并且没有节约公用 IP ,只隐藏了主机的真实地址。2. 动态转换虽然在一定情况下节约了公用 IP, 但当内部网络同时访问 Internet 的主机数大于合法地址池中的 IP 数量时就不适用了。3. 端口多路复用可以使所有内部网络主机共享一个合法的外部 IP 地址,从而最大限度地节约 IP 地址资源。
12、STP是什么协议,有什么作用
参考答案STP :生成树协议作用 : 逻辑上断开环路,防止广播风暴产生。当线路故障,阻塞接口被激活,恢复通信,起备份线路的作用。
13、简述静态路由,动态路由是什么以及特点是
静态路由 :系统管理员设计与构建的路由表规定的路由。适用于网关数量有限的场合,且网络拓朴结构不经常变化的网络。其缺点是不能动态地适用网络状况的变化,当网络状况变化后必须由网络管理员修改路由表。动态路由 :是由路由选择协议而动态构建的,路由协议之间通过交换各自所拥有的路由信息实时更新路由表的内容。动态路由可以自动学习网络的拓朴结构,并更新路由表。其缺点是路由广播更新信息将占据大量的网络带宽。
14、增加一条由网关192.168.9.1到达192.168.1.0网络的路
route add -net 192.168.1.0/24 gw 192.168.9.115、网站出现500,502,400,403,404都是什么意思,怎么排查和解决
500 错误:服务器内部错误,有可能是服务器上程序或者数据库错误,需要打开错误日志,查看日志,分析错误信息。502 错误:网关错误,服务器作为网关或代理,从上游服务器收到无效响应。 Nginx 出现最多,出现 502 要么是 nginx 配置的不对,要么是 php-fpm 资源不够,可以分析php-fpm 的慢执行日志,优化 php-fpm 的执行速度。400 错误:错误请求,服务器不理解请求的语法。这可能是用户发起的请求不合理,需要检查客户端的请求。403 错误:服务器拒绝请求。检查服务器配置,是不是对客户端做了限制。404 错误:未找到请求的资源。检查服务器上是否存在请求的资源,看是否是配置问题。
三、Linux系统服务篇
1、请描述SMTP及POP3分别是什么协议、 作用及端口号
SMTP :简单邮件传输协议,用于发送和接收邮件,端口号 25POP3 :邮局协议版本 3 ,用于客户端接收邮件,端口号 110
2、请描述http及https分别是什么协议、作用及端口号
HTTP :超文本传输协议,用于传输 Internet 浏览器使用的普通文本、超文本、音频和视频等数据,端口号 80HTTPS :安全超文本传输协议,基于 HTTP 开发,提供加密,可以确保消息的私有性和完整性,端口号为 443
3、如何将本地80端口的请求转发到本地8080端口
iptables -t nat -A PREROUTING -p tcp --dport 80 -j REDIRECT --to-port 80804、简述FTP的主被动模式
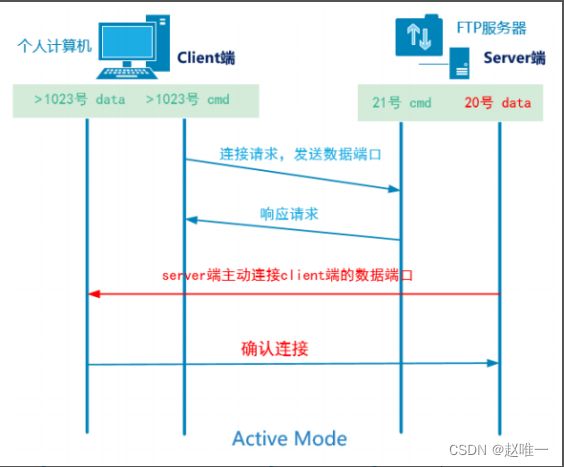
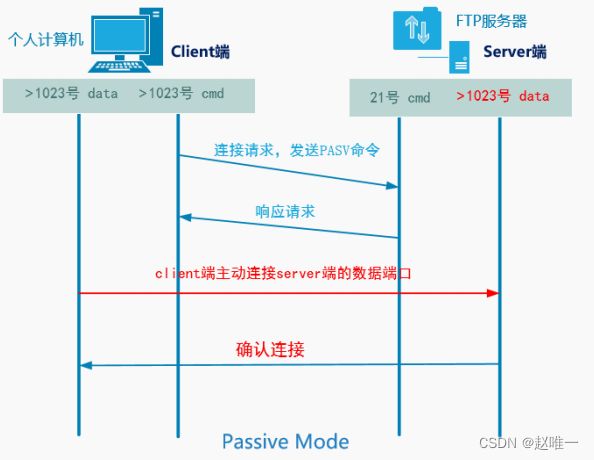
5、请简述http请求过程,并描述http常见的两种请求方法GET和POST的区别

6、请简述SSH免密登录的原理
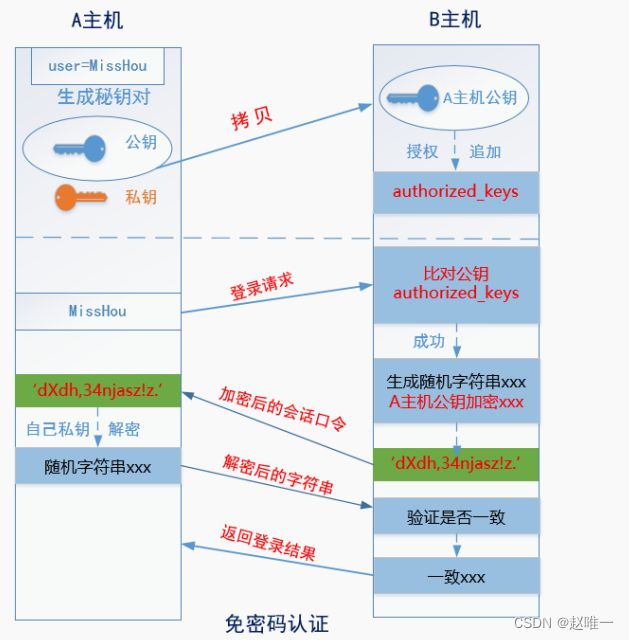
1. 主机 A 上一个用户生成一对秘钥(公钥和私钥)2. 主机 A 上此用户将其公钥远程拷贝到主机 B 上3. 主机 B 上某个用户收到公钥后将其授权追加到自己的 authorized_keys 文件中4. 当主机 A 发送连接请求给主机 B 时,主机 B 收到请求后到自己的 authorized_keys 文件中比对,如果有主机 A 的公钥信息(用户名和主机)则生成一串随机字符串并使用 A 的公钥加密,然后再将加密后的会话口令发给 A 主机5. A 主机收到加密后的会话口令后,使用保存在本地的私钥进行解密,然后将解密后的随机字符串口令再发给 B 主机6. B 主机收到 A 发过来的随机字符串后进行对比,如果一致,则返回登录成功
7、简述企业中常见的文件共享服务及特点
常见的文件共享服务有 FTP 、 samba 、 nfs ,根据不同的需求选择不同的服务。FTP(File Transfer Protocol) 是一种应用非常广泛并且古老的一个互联网文件传输协议。其特点为:1. 主要用于互联网中文件的双向传输(上传 / 下载)、文件共享2. 跨平台, C / S 架构,拥有一个客户端和服务端,使用 TCP 协议作为底层传输协议,提供可靠的数据传输3. FTP 支持匿名用户、本地用户等认证,默认端口 21 号(命令端口); 20 号(数据端口,主动模式下)4. FTP 程序(软件)为 vsftpdNFS ( Network File System )网络文件系统。其特点为:1. 主要用于 linux 系统上实现文件共享的一种协议,其客户端主要是 Linux2. 没有用户认证机制,且数据在网络上传送的时候是明文传送,一般在局域网中使用3. 支持多节点同时挂载及并发写入,一般用于 web 服务器的后端存储SMB ( Server Message Block )协议实现文件共享,也称为 CIFS ( CommonInternet File System )1. 客户端主要是 Windows ;支持多节点同时挂载以及并发写入2. 主要用于 windows 和 Linux 下的文件共享、打印共享3. 实现匿名与本地用户文件共享总结:1. 如果企业内部用于文件的共享可以选择 ftp 或 samba ;为了增加安全性推荐使用 ftp 实现文件共享。2. 如果用于 web 服务器后端存储或其他共享存储使用,且都是 Linux 平台,推荐使用 nfs 实现文件共享。
8、简述DNS域名解析过程和原理
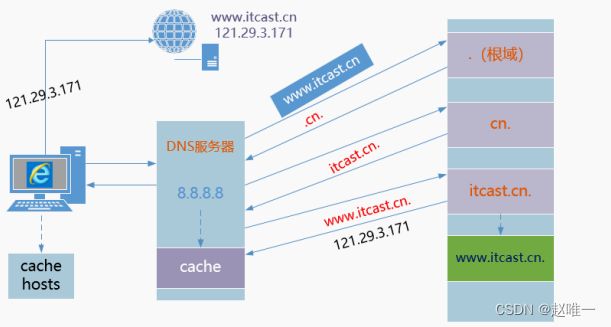
1. 用户要访问 www.itcast.cn ,会先找本机的缓存和 host 文件,然后再找本地设置的 DNS 服务器。2. 本地配置的 DNS 服务器先查询自己缓存,然后看看自己的 A 记录,如果没有则去找根域 (.) 服务器。3. 根服务器反馈一级域名服务器 .cn 结果给客户端配置 DNS 服务器,然后 DNS 服务器就去找一级域名服务器。4. 一级域名服务器说只能提供二级域名服务器 .itcast.cn, 然后 DNS 服务器就去找二级域名服务器。5. 二级域服务器正好有 www.itcast.cn 这个 A 记录,然后发给请求的 DNS 服务器, DNS 服务器缓存之后,再发给客户端
9、Linux下如何挂载windows共享目录
1. windows 下面开启 smb 服务(默认开启) : 控制面板 --- 程序和功能 -- 打开或关闭 Windows 功能2. 在 Linux 上操作1 )登陆到 Linux 系统,创建挂载点: mkdir / bkdata2 )执行挂载 windows 下的共享文件命令# mount.cifs -o user=Administrator,pass=abc@123//10.1.1.12/test /bkdata3 )查看挂载的共享文件: ls / bkdata4)开机自动挂载:
vim /etc/rc.local mount.cifs -o user=Administrator,pass='abc@123' //10.1.1.12/test /bkdata
10、网站打开不了或者慢如何分析?
思路就是从前往后说。首先,排查客户端 ( 网页没有显示看报什么错误,在客户端按 F12 看看有什么错误提示,或者换个浏览器试试,或者清空浏览器缓存试试)。如果没有解决,然后再检查服务端,服务端就是从服务本身,网站资源,通过一些工具测试,看日志等等去一步一步排查。最后,不能正常显示,肯定是哪里有问题,在服务端我们从日志入手,一步一步查看肯定能找到问题的。
四、SHELL编程篇
#!/bin/bash
for i in {1..20}
do
{
if [ $i -le 9 ];then
useradd user0$i && echo "user0$i-`echo $RANDOM|md5sum|cut-c 1-5`"|tee -a user_pass.txt|passwd --stdin user0$i
else
useradd user$i && echo "user$i-`echo $RANDOM|md5sum|cut -c 1-5`"|tee -a user_pass.txt|passwd --stdin user$i
fi
} >/dev/null 2>&1
done2、编写脚本清理指定目录的空白普通文件
#!/bin/bash
#根据需求定义需要清理的目录
read -p "请输入需要清理目录的绝对路径:" path
#查找指定目录里的空白文件并移动到临时目录/tmp中
for i in `find $path -type f`
do
[ ! -s $i ] && mv $i /tmp/
done
#定期清理/tmp目录里的文件
find /tmp -mtime +3 -delete3、写一个脚本,实现判断192.168.1.0/24 网络里,当前在线的IP有哪些,能ping通则认为在线
#!/bin/bash
for ((i=1;i<255;i++))
do
{
ping -c1 192.168.1.$i &>/dev/null
[ $? -eq 0 ] && echo "192.168.1.$i is up" |tee -a
ip_up.txt || echo "192.168.1.$i is down" |tee -a ip_down.txt
}&
done
wait
echo "当前在线IP已保存到ip_up.txt里,请查看"4、统计网站访问IP的数量及PV量
ss -an |grep :80 |awk -F":" '!/LISTEN/{ip_count[$(NF-1)]++};END{for(i in ip_count){print i,ip_count[i]}}' |sort -k2-rn |headgrep '07/Aug/2019' access.log |awk '{ips[$1]++};END{for(i in ips){print i,ips[i]} }' |awk '$2>100' |sort -k2 -rnvim clean_log.sh
#!/bin/bash
#clean log
#定义远程日志服务器IP
remote_log_server=10.1.1.2
#定义web服务器访问日志目录
log_dir=/usr/local/apache2/logs
#定义日志临时存放目录
log_tmp_dir=/tmp/log#定义当前web的IP
host=`ifconfig eth0|sed -n '2p'|awk -F'[ :]+' '{print $4}'`
#判断日志临时存放目录是否存在,不存在则创建它
[ ! -d $log_tmp_dir ] && mkdir -p $log_tmp_dir
#将3天以前的日志文件打包并存放到临时日志目录,以当前web服务器ip命名
cd $log_dir
find ./ -daystart -mtime +3 -exec tar -uf $log_tmp_dir/`echo
$host`_$(date +%F).tar {} \;
#清理当前web服务器3天以前的日志文件
find ./ -daystart -mtime +3 -delete
#将web服务器3天以前的日志文件远程同步到日志服务器
cd $log_tmp_dir
rsync -a ./ $remote_log_server:/$host && find ./ -daystart -mtime +1 -deletecrontab -e
20 04 * * * bash clean_log.sh &>/dev/null6、编写脚本将当前目录所有文件扩展名改为log
#!/bin/bash
for i in `ls ./| grep -P "(.*)(\..*)"`
do
echo $i|mv $i `echo ${i%.**}`.log
done7、编写脚本部署LNMP环境
#!/usr/bin/env bash
# Naime:system_env_init.sh
# Desc:该脚本用于LNMP环境搭建
# Path:/soft/scripts/
# Usage:/soft/scripts/lnmp.sh
main(){
cat </dev/null
[ $? -ne 0 ] && useradd -s /sbin/nologin -M nginx
#解决依赖
echo "安装相应的依赖包"
yum -y install pcre-devel openssl-devel
yum -y install libxml2-devel libjpeg-devel libpng-devel
freetype-devel curl-devel openssl-devel
[ $? -eq 0 ] && echo "依赖包安装完毕"
}
#编译安装nginx
install_nginx()
{
echo "开始安装nginx,请耐心等待..."
init
tar xf /soft/nginx-1.14.2.tar.gz
tar xf /soft/ngx-fancyindex-0.4.3.tar.gz
tar xf /soft/echo-nginx-module-0.61.tar.gz
cd nginx-1.14.2
echo "正在编译安装nginx,请小憩一会..."
{
./configure --prefix=/usr/local/nginx --user=nginx --
group=nginx --with-http_ssl_module --withhttp_stub_status_module --with-http_realip_module --addmodule=/soft/echo-nginx-module-0.61 --add-module=/soft/ngxfancyindex-0.4.3
make && make install
} &>/dev/null
echo "nginx已安装完毕"
echo "配置service方式管理nginx服务..."
cp /soft/service_nginx.sh /etc/init.d/nginx
chmod +x /etc/init.d/nginx
chkconfig --add nginx
service nginx start
[ $? -eq 0 ] && echo "启动脚本配置完毕,nginx服务已经成功启动"
#拷贝nginx提供的contrib/vim目录到用户家目录,使配置文件着色(可选)
cp /soft/nginx-1.14.2/contrib/vim/ ~/.vim
}
#编译安装php
install_php()
{
#解压软件
cd /soft
tar xf php-7.2.12.tar.gz
cd php-7.2.12
#编译安装php
echo "正在编译安装php,请耐心等待..."
{
./configure --prefix=/usr/local/php --with-config-filepath=/usr/local/php/etc --enable-fpm --with-fpm-user=nginx --
with-fpm-group=nginx --with-mysqli=mysqlnd --with-pdomysql=mysqlnd --with-iconv-dir --with-freetype-dir --withjpeg-dir --with-png-dir --with-zlib --with-libxml-dir --
enable-xml --disable-rpath --enable-bcmath --enable-shmop --
enable-sysvsem --enable-inline-optimization --with-curl --
enable-mbregex --enable-mbstring --enable-ftp --with-gd --
with-openssl --with-mhash --enable-pcntl --enable-sockets --
with-xmlrpc --with-libzip --enable-soap --without-pear --withgettext --disable-fileinfo --enable-maintainer-zts && make &&
make install
} &>/dev/null
echo "php已安装完毕,开始后续配置,并且启动php-fpm程序..."
#配置文件初始化
cp php.ini-development /usr/local/php/etc/php.ini
#php-fpm服务配置文件
cp /usr/local/php/etc/php-fpm.conf.default
/usr/local/php/etc/php-fpm.conf
#php-fpm服务子配置文件
cp /usr/local/php/etc/php-fpm.d/www.conf.default
/usr/local/php/etc/php-fpm.d/www.conf
#配置服务及其环境变量
cp /soft/php-7.2.12/sapi/fpm/init.d.php-fpm /etc/init.d/phpfpm
chmod +x /etc/init.d/php-fpm
chkconfig --add php-fpm
service php-fpm start
echo 'PATH=/usr/local/php/bin:$PATH' >> /etc/profile
echo "php已配置完毕,并已成功启动php-fpm"
}
#安装mysql数据库
install_mysql()
{
#创建mysql用户
id mysql &>/dev/null
[ $? -ne 0 ] && useradd -s /sbin/nologin -M mysql
#解决依赖
yum -y install numactl
#解压mysql软件移动到安装目录
echo "正在解压软件包,请稍后..."
cd /soft/
tar xf mysql-5.7.25-linux-glibc2.12-x86_64.tar.gz
mv mysql-5.7.25-linux-glibc2.12-x86_64 /usr/local/mysql
chown -R mysql.mysql /usr/local/mysql
#初始化数据库
echo "正在初始化数据库,请稍后..."
rm -f /etc/my.cnf
cd /usr/local/mysql
bin/mysqld --initialize --user=mysql &> /tmp/init.log
bin/mysql_ssl_rsa_setup &>/dev/null
#创建配置文件
cat >/etc/my.cnf <> /etc/profile
#当前终端设置环境变量
export PATH=/usr/local/mysql/bin:$PATH
#设置root域名的密码
pass=$(tail -1 /tmp/init.log |awk '{print $NF}')
/usr/local/mysql/bin/mysqladmin -uroot password '123' -p$pass
echo "数据库管理员root密码已设置成功为:123"
}
menu()
{
cat < 8、写一个自动检测磁盘使用率的脚本,当磁盘使用空间达到90%以上时,需要发送邮件给相关人员
#!/bin/bash
#Name:check_space.sh
#Desc:check disk space
#Path:/root/Desktop/check_space.sh
#Usage:./check_space.sh or /root/Desktop/check_space.sh
/bin/df -h > df.txt
use=`cat df.txt|awk '{print $5}'|grep -o '[0-9]\+'`
for i in $use
do
[ $i -ge 90 ] && echo notice disk space:`grep $i df.txt`
|mail heima@localhost
done
rm -f df.txt9、写一个脚本监控系统内存和交换分区使用情况
#!/bin/bash
#初始化默认分隔符
OIFS=$IFS
#定义默认分隔符
IFS="\n"
file=`free -m|sed -nr '/Mem|Swap/p'|awk '{print $4,$2}'`
mem=`echo $file|head -1`
swap=`echo $file|tail -1`
echo $mem |awk '{if(($1/$2)*100<=50) print "物理内存空间需要留意,剩余"$1"M";else print "物理内存在正常范围"}'
echo $swap |awk '{if(($1/$2)*100<=50) print "交换空间需要留意,剩余"$1"M";else print "交换空间在正常范围"}'10、写一个倒计时脚本,要求显示离2020年10月1日(国庆节)的凌晨0点,还有多少天,多少时,多少分,多少秒。
#!/bin/bash
goal=`date +%s -d 20201001`
while true
do
now=`date +%s`
if [ $[$goal-$now] -eq 0 ];then
break
fi
day=$[($goal-$now)/86400]
hour=$[($goal-$now)%86400/3600]
minute=$[($goal-$now)%3600/60]
second=$[($goal-$now)%60]
clear
echo "离2018年10月1日还有$day天:$hour时:$minute
分:$second秒"
sleep 1
done
echo "国庆节快乐!!!"五、系统架构篇
1、 linux系统nginx与Php环境,发现PHP-FPM进程高,请说出可能的原因以及如何解决?
1 ) php 的插件程序与现有的 PHP 版本存在不兼容情况,解决方法从 php.ini 中禁止相关插件2 )软件本身存在问题,需要开发协同运维一同处理,查找原因3 ) php 程序存在死循环现象,使用服务器负载过高,解决方法使用 top 命令查看
2、Nginx反向代理如何实现代理RS节点上 的不同虚拟主机,请说出原理和配置方法或思路
客户端向反向代理发送请求,反向代理按一定的规则转发至目标服务器,并将返回的内容返回给客户端,可分为以下两种:配置内部不同服务器转发:upstream app1 {server 192.168.1.10 : 80 weight = 5 ;server 192.168.1.11 : 80 weight = 5 ;}upstream app2 {server 192.168.1.20 : 80 weight = 5 ;server 192.168.1.21 : 80 weight = 5 ;}配置 serverserver{listern 80 ;server_name app.abc.com}配置匹配转发规则:location / app1 / {proxy_pass http :// example.com / app1; proxy_set_header Host $host ;}location / app2 / {proxy_passhttp :// example.com / app2;proxy_set_header Host $host ;}做为负载均衡,配置负载均衡服务器池,也就是调度规则upstream test_servers {server 192.168.1.2 : 80 weight = 5 ;server 192.168.1.4 : 80 weight = 5 ;server 192.168.1.6 : 82 weight = 15 ;}然后配置 server 标签,server {listen 80 ;server_name www.abc.com;proxy_pass http :// test_servers;proxy_set_header Host $host}配置完成后,重新加载 nginx 服务
3、如何实现nginx代理的节点访问日志记录的是真实访客的IP,不是代理的IP
修改 nginx.conf 配置文件:server{listen 80 ;server_name blog.text.com;location / {proxy_pass http :// test_servers;proxy_set_header Host $host ;proxy_set_headerX-Forwarded-For $remote_addr ;}
4、描述Tomcat的8005、8009、8080三个 端口的含义?
8005 —— > 关闭时使用8009 —— > 为 AJP 端口,即容器使用,如 Apache 能通过 AJP 协议访问 Tomcat 的 8009端口8080 —— > 一般应用使用
5、描述Tomcat的三种工作模式(Bio、Nio 和Apr)的工作原理
Bio(Blocking I / O) :默认工作模式,阻塞式 I / O 操作,没有任何优化技术处理,性能比较低。Nio(New I / O or Non ‐ Blocking) :非阻塞式 I / O 操作,有 Bio 有更好的并发处理性能。Apr(Apache Portable Runtime , Apache 可移植运行库 ) :首选工作模式,主要为上层的应用程序提供一个可以跨越多操作系统平台使用的底层支持接口库。tomcat 利用基于 Apr 库 tomcat ‐ native 来实现操作系统级别控制,提供一种优化技术和非阻塞式 I / O 操作,大大提高并发处理能力。但是需要安装 apr 和 tomcat ‐ native 库
6、请解释Tomcat 中使用的连接器是什么 ?
在 Tomcat 中,使用了两种类型的连接器:HTTP 连接器 : 它有许多可以更改的属性,以确定它的工作方式和访问功能,如重定向和代理转发AJP 连接器 : 它与 HTTP 连接器相同的方式工作,但是他们使用的是 HTTP 的 AJP协议。 AJP 连接器通常通过插 件 mod_jk 在 Tomcat 中实现。
7、请简述Tomcat调优的大概思路
1 、增加最大连接数2 、调整工作模式3 、启用 gzip 压缩4 、调整 JVM 内存大小5 、与 Apache 或 Nginx 整合,实现动静分离6 、合理选择垃圾回收算法7 、尽量使用较新 JDK 版本
8、请简单描述nginx与php-fpm的两种连接方式及其优缺点
在 linux 中, nginx 服务器和 php ‐ fpm 可以通过 tcp socket 和 unix socket 两种方式实现。1. unix socket 是一种终端,可以使同一台操作系统上的两个或多个进程进行数据通信。这种方式需要再 nginx 配置文件中填写 php ‐ fpm 的 pid 文件位置,效率要比 tcp socket 高。2. tcp socket 这种通信方式,需要在 nginx 配置文件中填写 php ‐ fpm 运行的 ip 地址和端口号。这种方式的优点是可以跨服务器,当 nginx 和 php ‐ fpm 不在同一台机器上时,只能使用这种方式。
9、写出你常用的Nginx模块及作用
rewrite : 实现重写功能access : 来源控制ssl : 安全加密,实现 httpsngx_http_gzip_module : 网络传输压缩模块ngx_http_proxy_module : 实现代理ngx_http_upstream_module : 实现定义后端服务器列表ngx_cache_purge : 实现缓存清除功能
10、简述Nginx支持的几种负载均衡模式,并指出各模式的应用场景
1. roundrobin 轮询方式,依次将请求分配到各个后台服务器中,默认的负载均 衡方式。适用于后台机器性能一致的情况。 挂掉的机器可以自动从服务列表中剔 除。2. weight 根据权重来分发请求到不同的机器中,适用于后台机器性能不一样的情况。3. ip_hash 根据请求者 ip 的 hash 值将请求发送到后台服务器中,可以保证来自 同一 ip 的请求被打到固定的机器上,可以解决 session 问题。4. url_hash 根据请求的 url 的 hash 值将请求分到不同的机器中,当后台服务器为缓存的时候效率高。5. fair 根据后台响应时间来分发请求,响应时间短的分发的请求多。
11、简述Apache 与 Nginx的优缺点
nginx 相对于 apache 的优点:轻量级,同样起 web 服务,比 apache 占用更少的内存及资源抗并发, nginx 处理请求是异步非阻塞的,而 apache 则是阻塞型的,在高并发下 nginx 能保持 低资源低消耗高性能,高度模块化的设计,编写模块相对简单,社区活跃,各种高性能模块出品迅速。apache 相对于 nginx 的优点:Apache 的 rewrite 功能比 nginx 的 rewrite 强大,模块超多,基本想到的都可以找到,少 bug ,超稳定。 nginx 的 bug 相对较多。
12、简述keepalived的工作原理
在一个虚拟路由器中,只有作为 MASTER 的 VRRP 路由器会一直发送 VRRP 通告信息 ,BACKUP 不会抢占 MASTER ,除非它的优先级更高。当 MASTER 不可用时 (BACKUP 收不到通告信息 ), 多台 BACKUP 中优先级最高的这台会被抢占为 MASTER 。这种抢占是非常快速的 ( < 1 秒 ) ,以保证服务的连续性 , 由于安全性考虑, VRRP 包使用了加密协议进行加密。 BACKUP 不会发送通告信息,只会接收通告信息。
13、简单描述keepalive的如何实现高可用
Keepalived 高可用服务对之间的故障切换转移,是通过 VRRP 协议来实现的。 在 Keepalived 服务正常工作时,主 Master 节点会不断地向备节点发送(多播的方式)心跳消息,用以告诉备 Backup 节点自己还活看,当主 Master 节点发生故障时,就无法发送心跳消息,备节点也就因此无法继续检测到来自主 Master 节点的心跳了,于是调用自身的接管程序,接管主 Master 节点的 IP 资源及服务。而当 Master 节点恢复时,根据配置情况,可以让原来的备(现在的主)继续为 Master ;也可以让原来的备(现在的主)节点释放主节点故障时自身接管的 IP 资源及服务,恢复到原来的备用角色。
14、简单介绍常见的几种负载均衡方式的比较及工作中如何选择
一、 LVS 的特点1 、工作在网络 4 层上,抗负载能力强,作分发之用;2 、配置性比较低;3 、工作稳定,自身具备的双机热备方案;4 、应用范围比较广,可以对所有应用做负载均衡;二、 NGINX 的特点1 、工作在网络的 7 层之上;2 、对网络的依赖比较小;3 、安装和配置比较简单,测试起来比较方便;4 、可以承担高的负载压力且稳定;5 、可以通过端口检测到服务器内部的故障,6 、对请求的异步处理可以帮助节点服务器减轻负载;7 、能支持 http 和 Email ;8 、默认的只有 Round ‐ robin 和 IP ‐ hash 两种负载均衡算法;三、 Haproxy 的特点1 、工作在网络 7 层之上。2 、能够补充 Nginx 的一些缺点比如 Session 的保持, Cookie 的引导等工作3 、支持 url 检测后端的服务器出问题的检测4 、更多的负载均衡策略5 、有更出色的负载均衡速度6 、 HAProxy 可以对 Mysql 进行负载均衡,对后端的 DB 节点进行检测和负载均衡四、工作中如何选择 HAproxy 和 Nginx 由于可以做七层的转发,所以 URL 和目录的转发都可以做在很大并发量的时候我们就要选择 LVS ,像中小型公司的话并发量没那么大选择 HAproxy 或者 Nginx 足已,由于 HAproxy 由是专业的代理服务器配置简单,所以中小型企业推荐使用 HAproxy
15、简单描述HTTP与 HTTPS有什么区别
首先, HTTP 协议传输的数据都是未加密的,也就是明文的,因此使用 HTTP 协议传输隐私信息非常 不安全,为了保证这些隐私数据能加密传输,于是网景公司设计了 SSL ( Secure Sockets Layer )协议用于对 HTTP 协议传输的数据进行加密,从而就诞生 HTTPS 。其次,简单来说, HTTPS 协议是由 SSL + HTTP 协议构建的可进行加密传输、身份认证的网络协议,要比 http 协议安全。最后, HTTPS 和 HTTP 的区别主要如下:1. https 协议需要 ca 申请证书,一般免费证书较少,因而需要一定费用。2. http 是超文本传输协议,信息是明文传输, https 则是具有安全性的 ssl 加密传输协议。3. http 和 https 使用的是完全不同的连接方式,用的端口也不一样,前者是 80 ,后者是 443 。4. http 的连接很简单,是无状态的; HTTPS 协议是由 SSL + HTTP 协议构建的可进行加密传输、身份认证的网络协议,比 http 协议安全。
16、简单描述一下你所了解的web应用攻击方式
DDoS(洪水攻击):
流量攻击主要是针对网络带宽的攻击,即大量攻击包导致网络带宽被阻塞,合法网络包被虚假的攻击包淹没而无法到达主机;资源耗尽攻击,主要是针对服务器主机的攻击,即通过大量攻击包导致主机的内存被耗尽或 CPU 被内核及应用程序占完而造成无法提供网络服务。SQL注入:
指针对 Web 应用使用的数据库,通过运行非法的 SQL 而产生的攻击。该安全隐患有可能引起极大地威胁,有时会直接导致个人信息及机密信息的泄露。DOS攻击:
是一种让运行中的服务呈停止状态的攻击。有时也叫作服务停止或拒绝服务攻击。OS命令注入攻击:
OS 命令注入攻击是指通过 Web 应用,执行非法的操作系统命令达到攻击的目的。
17、简单介绍lvs的三种负载均衡机制
1、NAT模型
NAT 模型是通过网络地址转换来实现的 , 工作方式是 , 首先用户请求到达前端的负载均衡器,然后负载均衡器根据事先定义好的调度算法将用户请求的目标地址 ( 即虚拟 IP 地址 ) 修改为后端的应用服务器,应用程序服务器处理好请求之后将结果返回给用户 , 期间必须要经过负载均衡器 , 负载均衡器将报文的源地址改为用户请求的目标地址 , 再转发给用户 , 从而完成整个负载均衡的过程 .2、DR模型
DR 模型是通过路由技术实现的负载均衡技术 , 这种模型与 NAT 模型不同的地方是 , 负载均衡器通过改写用户请求报文中的 MAC 地址 , 将请求发送到 Real Server, 而 Real Server 直接响应用户 , 这样就大大的减少负载均衡器的压力 ,DR 模型也是用的最多的一种。3、TUN模型
TUN 模型是通过 IP 隧道技术实现的 ,TUN 模型跟 DR 模型有点类似 , 不同的地方是负载均衡器 (Director Server) 跟应用服务器 (Real Server) 通信的机制是通过 IP 隧道技术将用户的请求转发到某个 Real Server, 而 Real Server 也是直接响应用户的 .
18、简述Redis与Memcached区别及优势?
1. memcached 所有的值均是简单的字符串, redis 作为其替代者,不仅仅支持简单的 k / v 类型的数据,同时还提供 list , set , zset , hash 等数据结构的存储。2. redis 的速度比 memcached 快很多,并支持 master-slave( 主 — 从 ) 模式应用。3. redis 支持数据的持久化,可以将内存中的数据保持在磁盘中,重启的时候可以再次加载进行使用。4. Redis 单个 value 存储 string 的最大限制是 512MB , memcached 只能保存 1MB 的数据 .5. redis 是单核, memcached 是多核。
19、为什么Redis需要把所有数据放到内存中?
Redis 为了达到最快的读写速度将数据都读到内存中,并通过异步的方式将数据写入磁盘。所以 redis 具有快速和数据持久化的特征。如果不将数据放在内存中,磁盘 I / O 速度为严重影响 redis 的性能。在内存越来越便宜的今天, redis 将会越来越受欢迎。 如果设置了最大使用的内存,则数据已有记录数达到内存限值后不能继续插入新值。
20、简述Redis的常见使用场景?
1.会话缓存(Session Cache)
最常用的一种使用 Redis 的情景是会话缓存( session cache )。用 Redis 缓存会话比其他存储(如 Memcached )的优势在于: Redis 提供持久化。2.队列
Reids 在内存存储引擎领域的一大优点是提供 list 和 set 操作,这使得 Redis 能作为一个很好的消息队列平台来使用。 Redis 作为队列使用的操作,就类似于本地程序语言(如 Python )对 list 的 push / pop 操作。3.全页缓存(FPC)
除基本的会话 token 之外, Redis 还提供很简便的 FPC 平台。回到一致性问题,即使重启了 Redis 实例,因为有磁盘的持久化,用户也不会看到页面加载速度的下降,这是一个极大改进,类似 PHP 本地 FPC 。4.排行榜/计数器
Redis 在内存中对数字进行递增或递减的操作实现的非常好。集合( Set )和有序集合( Sorted Set )也使得我们在执行这些操作的时候变的非常简单, Redis 只是正好提供了这两种数据结构。5.发布/订阅
最后(但肯定不是最不重要的)是 Redis 的发布 / 订阅功能。发布 / 订阅的使用场景确实非常多。已有人们在社交网络连接中使用,还可作为基于发布 / 订阅的脚本触发器,甚至用 Redis 的发布 / 订阅功能来建立聊天系统!
21、Redis集群会有写操作丢失吗?为什么?
Redis 并不能保证数据的强一致性,这意味这在实际中集群在特定的条件下可能会丢失写操作。
22、描述一下redis常见的数据结构类型
string ——— > 字符串类型,使用场景:做缓存,计数器,共享 sessionhash ——— > 哈希类型,使用场景:用户信息存储list ——— > 列表类型,使用场景:消息队列,微博 TimeLineset ——— > 集合类型,使用场景:好友推荐Sorted Set ——— > 有序集合类型,使用场景:排行榜
23、Redis是单线程的,如何提高多核CPU的利用率?
可以在同一个服务器部署多个 Redis 的实例,并把他们当作不同的服务器来使用,在某些时候,无论如何一个服务器是不够的 , 所以 , 如果你想使用多个 CPU ,你可以考虑一下分片( shard )。
24、简单描述Redis常见性能问题和解决方案?
1. Master 最好不要做任何持久化工作,如 RDB 内存快照和 AOF 日志文件 .2. 如果数据比较重要,某个 Slave 开启 AOF 备份数据,策略设置为每秒同步一次 .3. 为了主从复制的速度和连接的稳定性, Master 和 Slave 最好在同一个局域网内 .4. 尽量避免在压力很大的主库上增加从库 .5. 主从复制不要用图状结构,用单向链表结构更为稳定 , 这样的结构方便解决单 点故障问题,实现 Slave 对 Master 的替换。如果 Master 挂了,可以立刻启用 Slave1 做 Master ,其他不变 .
25、Mongodb 熟悉吗,一般部署几台?
部署过,没有深入研究过,一般 mongodb 部署主从或者 mongodb 分片集群; 建议 3 台或 5 台服务器来部署。 MongoDB 分片的基本思想就是将集合切分成小块。 这些块分散到若干片里面,每个片只负责总数据的一部分。 对于客户端来说,无需知道数据被拆分了,也无需知道服务端哪个分片对应哪些数据。数据在分片之前需要运行一个路由进程,进程名为 mongos 。这个路由器知道所有数据的存放位置,知道数据和片的对应关系。对客户端来说,它仅知道连接了一个普通的 mongod ,在请求数据的过程中,通过路由器上的数据和片的对应关系,路由到目标数据所在的片上,如果请求有了回应,路由器将其收集起来回送给客户端。
26、CDN是什么?
CDN 即内容分发网络,其目的是通过在现有的 Internet 中增加一层新的网络架构,将网站的内容发布到最接近用户的网络边缘,使用户可就近取得所需的内容,提高用户访问网站的速度。通过权威 DNS 服务器来实现最优节点的选择,通过缓存来减少源站的压力。CDN 是构建在现有网络基础之上的智能虚拟网络,依靠部署在各地的边缘服务器,通过中心平台的负载均衡、内容分发、调度等功能模块,使用户就近获取所需内容,降低网络拥塞,提高用户访问响应速度和命中率。 CDN 的关键技术主要有内容存储和分发技术。
27、 linux系统nginx与Php环境,发现PHP-FPM进程高,请说出可能的原因以及如何 解决?
1 ) php 的插件程序与现有的 PHP 版本存在不兼容情况,解决方法从 php.ini 中禁止相关插件2 )软件本身存在问题,需要开发协同运维一同处理,查找原因3 ) php 程序存在死循环现象,使用服务器负载过高,解决方法使用 top 命令查看
28、什么是中间件?什么是jdk?
中间件介绍:中间件是一种独立的系统软件或服务程序,分布式应用软件借助这种软件在不同的技术之间共享资源;中间件位于客户机 / 服务器的操作系统之上,管理计算机资源和网络通讯是连接两个独立应用程序或独立系统的软件。相连接的系统,即使它们具有不同的接口。但通过中间件相互之间仍能交换信息。执行中间件的一个关键途径是信息传递通过中间件,应用程序可以工作于多平台或 OS 环 境。jdk 是 Java 的开发工具包,它是一种用于构建在 Java 平台上发布的应用程序、 applet 和组件的开发环境。
29、Tomcat和Resin有什么区别,工作中你怎么选择?
Tomcat 用户数多,可参考文档多, Resin 用户数少,参考文档少。最主要区别则是 Tomcat 是标准的 java 容器,不过性能方面比 resin 的要差一些,但稳定性和 java 程序的兼容性,应该是比 resin 的要好。工作中选择:现在大公司都是用 resin ,追求性能;而中小型公司都是用Tomcat ,追求稳定和程序的兼容
30、Squid、Varinsh和Nginx有什么区别,工作中你怎么选择?
Squid 、 Varinsh 和 Nginx 都是代理服务器。什么是代理服务器:能当替用户去访问公网,并且能把访问到的数据缓存到服务器本地,等用户下次再访问相同的资源的时候,代理服务器直接从本地回应给用户,当本地没有的时候,我代替你去访问公网,我接收你的请求,我先在我自已的本地缓存找,如果我本地缓存有,我直接从我本地的缓存里回复你如果我在我本地没有找到你要访问的缓存的数据,那么代理服务器就会代替你去访问公网区别:1 ) Nginx 本来是反向代理 / web 服务器,用了插件可以做做这个副业但是本身不支持特性挺多,只能缓存静态文件2 )从这些功能上。 varnish 和 squid 是专业的 cache 服务,而 nginx 这些是第三方模块完成3 ) varnish 本身的技术上优势要高于 squid ,它采用了可视化页面缓存技术在内存的利用上, Varnish 比 Squid 具有优势,性能要比 Squid 高。还有强大的通过 Varnish 管理端口,可以使用正则表达式快速、批量地清除部分缓存它是内存缓存,速度一流,但是内存缓存也限制了其容量,缓存页面和图片一般是挺好的4 ) squid 的优势在于完整的庞大的 cache 技术资料,和很多的应用生产环境工作中选择:要做 cache 服务的话,我们肯定是要选择专业的 cache 服务,优先选择 squid 或者 varnish 。
六、磁盘管理及存储篇
1、如何检测并修复磁盘/dev/sdb?
fsck 用来检查和维护不一致的文件系统。若系统掉电或磁盘发生问题,可利用fsck 命令对文件系统进行检查 .
2、如何备份当前系统磁盘的分区表?
dd if =/ dev / sda of =/ mbr.txt bs = 1 count = 512
3、磁盘报错:nospace lex on device,但是df-h查看空间没有满,为什么?
原因:系统 inode 满了,因为所有的文件的文件名信息都是存放在 inode 里面的,文件内容是存放在 block 里面可以使用 df - ih 来查看 inode 的使用情况
4、web服务器的磁盘空间满了,删除一部分nginx日志后,但是磁盘空间还是满的,为什么?
虽然删除了日志文件,但可能还是被进程调用,因此,需要重启 nginx 服务来释放;或者实际生产环境中使用 >/ logs / access.log 清空文件
5、有一块新硬盘/dev/sdf,容量4TB,Linux 系统中一个应用程序需要在/data目录使用此存储的500G的存储空间需要哪些步骤,请描述。
大概思路是:磁盘分区—— > 格式化 —— > 挂载使用1. 根据需求对磁盘进行分区一般磁盘 >= 2TB ,使用 gdisk 或 parted 工具进行分区;磁盘 < 2TB 使用 fdisk 工具进行分区2. 格式化分区根据需求格式化相应的文件系统类型,如 mkfs.ext4(Centos6 系统 ) 、 mkfs.xfs(Centos7 + 系统 )3. 挂载使用1 ) 创建挂载点 / data2 ) 手动挂载或开机自动挂载手动: mount - o ro / dev / sdf1 / data开机自动挂载: echo "mount -o ro /dev/sdf1 /data" >> / etc / rc.local
6、简单描述常见的RAID级别及特点
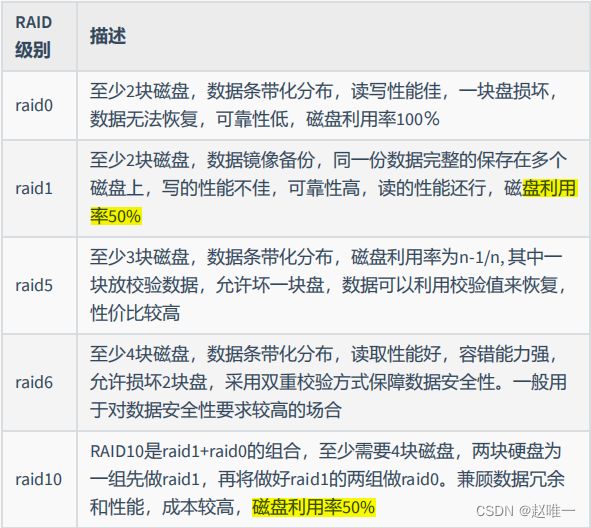
7、存储类型的分类有哪几种?并简单进行描述各自优缺点
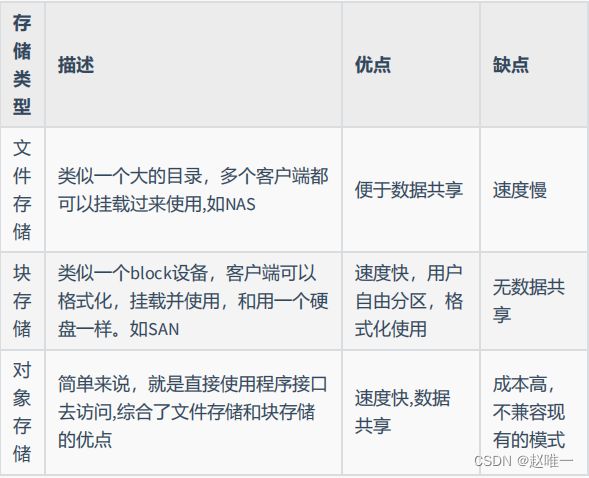
8、简单描述DAS、NAS、SAN使用场景及优缺点常
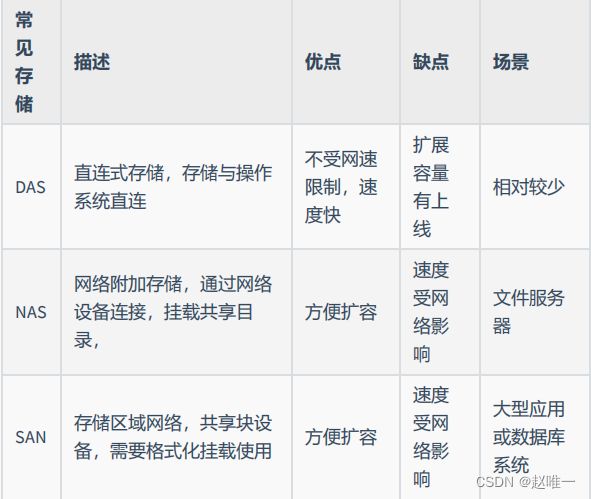
9、什么是分布式存储,它的优点有哪些?
分布式存储可以看作拥有多台存储服务器连接起来的存储导出端(多对一,多对多 ) 。把这多台存储服务器 的存储合起来做成一个整体再通过网络进行远程共享 , 共享的方式有目录 ( 文件存储 ), 块设备 ( 块存储 ), 对象网关或者说 一个程序接口 ( 对象存储 ) 。常见的分布式存储开源软件有 : GlusterFS,Ceph,HDFS,MooseFS,FastDFS 等。分布式存储一般都有以下几个优点 :1. 扩容方便,轻松达到 PB 级别或以上2. 可以实现数据的高可用( HA )和提升读写性能( LB )3. 单个节点故障不会让整个分布式存储挂掉4. 价格相对便宜,大量的廉价设备就可以组成,比光纤 SAN 这种便宜很多。
10、简单介绍一下你所了解的Ceph和GlusterFS
1. CephCeph 是一个能提供的文件存储 , 块存储和对象存储的分布式存储系统集群组件:Ceph OSD :功能是存储数据 , 处理数据的复制、恢复、回填、再均衡 , 并通过检查其他 OSD守护进程的心跳来向 Ceph Monitors 提供一些监控信息Ceph Mo nitor :是一个监视器 , 监视 Ceph 集群状态和维护集群中的各种关系。2. Gluserfs1 ) Glusterfs 是一个开源免费的分布式文件系统,可以实现类似不同 raid 类型的分布式卷提供的卷都为文件存储类型 , 可以实现数据共享 .2 ) glusterf 看作是一个将多台服务器存储空间组合到一起,再划分出不同类型的文件存储卷给导入端使用 .3 ) glasterfs 是无元数据服务器设计,没有单点故障和性能瓶颈,有很好的扩展性,和稳定性,认为存储是软件的事,不能局限于硬件。以原始数据的形式存储,访问数据简单,迁移容易。有的视频公司将他作为片库。缺点:数据一致性问题复杂,文件目录遍历效率低,缺乏全局监控,客户端负载大,占用了大量 cpu 和内存,用户空间效率低,与内核空间要经常交换数据,借用 FUSE ,有性能损耗
七、自动化运维篇
1、什么是灰度发布?
灰度发布是指在黑与白之间,能够平滑过渡的一种发布方式, AB test 就是一种灰度发布方式,让一部用户继续用 A ,一部分用户开始用 B ;如果用户对 B 没有什么反对意见,那么逐步扩大范围,把所有用户都迁移到 B 上面来。灰度发布可以保证整体系统的稳定,在初始灰度的时候就可以发现、调整问题,以保证其影响度。
2、你们公司代码是怎么发布和回滚的?
发布: jenkins 配置好代码路径( SVN 或 GIT ),然后拉代码,打 tag 。需要编译就编译,编译之后推送到发布服务器( jenkins 里面可以调脚本),然后从分发服务器往下分发到业务服务器上。回滚:按照版本号到发布服务器找到对应的版本推送。
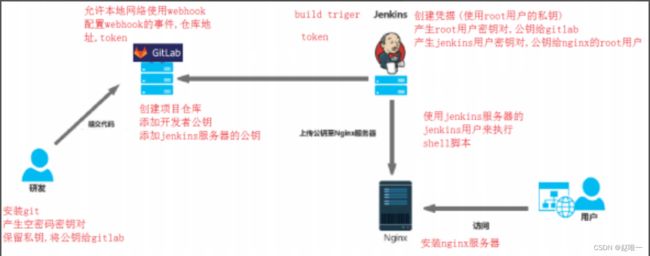
3、用图简单描述jenkins打包部署过程

4、你们公司监控是用什么实现的?
上家公司的业务都跑在阿里云上,我们首选的监控就是用阿里云监控,阿里云监控自带了 ECS 、 RDS 等服务的监控模板,可结合自定义报警规则来触发监控项。之前有一家公司的业务是托管在 IDC ,用的是 zabbix 监控方案, zabbix 图形界面丰富,也自带很多监控模板,特别是多个分区、多个网卡等自动发现并进行监控做得非常不错,不过需要在每台客户机(被监控端)安装 zabbix agent 。
5、简单描述一下zabbix如何实现实时监控,监控了多少客户端 客户端是怎么进行批量安装的?
zabbix 监控流程: agentd 需要安装到被监控的主机上,它负责定期收集各项数据,并发送到 zabbix server 端, zabbix server 将数据存储到数据库中,zabbix web 根据数据在前端进行展现和绘图。我们 zabbix 监控的客户端大概 2000 多台(根据自己简历描述),部署的思路如下:1 、使用命令生成密钥。2 、将公钥发送到所有安装 zabbix 客户端的主机。3 、安装 ansible 软件,(修改配置文件,将 zabbix 客户机添加进组)。4 、创建一个安装 zabbix 客户端的剧本。5 、执行该剧本。6 、验证。
6、zabbix自定义发现是怎么做的,微信报警如何实现?
自动发现:1 、首先需要在模板当中创建一个自动发现的规则,这个地方只需要一个名称和一个键值。2 、过滤器中间要添加你需要的用到的值宏。3 、然后要创建一个监控项原型,也是一个名称和一个键值。4 、然后需要去写一个这样的键值的收集。自动发现实际上就是需要首先去获得需要监控的值,然后将这个值作为一个新的参数传递到另外一个收集数据的 item 里面去。微信报警:1 、首先,需要有一个微信企业号。(一个实名认证的 [ 微信号 ] 一个可以使用的 [ 手机号 ] 一个可以登录的 [ 邮箱号 ]2 、下载并配置微信公众平台私有接口。3 、配置 Zabbix 告警,(增加示警媒介类型,添加用户报警媒介,添加报警动作)
7、jenkins你都用了哪些插件?
ssh remote hosts : 这个可以在远程服务器上面执行脚本。Role Strategy Plugin : 用来精细化管理权限。SCM : 除 CVS 和 Subversion 外需要实现与源代码控制系统支持的插件。Triggers : 事件监听并触发构建的插件。例如, URL 改变触发器将监控一个URL ;当地址内容发生改变,这个触发器就将执行一次作业。Build tools : 实现额外构建工具的插件,如 MSBuild 和 Rake 。如果您想在Hudson 中构建非 Java 的软件时这些就特别有用。Build wrappers : 通常涉及时执行在受控制的构建过程本身之前和之后事件的插件。例如, VMware 插件将在构建之前启动一个客户虚拟机,建立和然后在构建完成后关闭它。这在您可能需要访问 VM 以执行单元测试的情况下是非常有用的。
8、介绍一下ansible的特性及常用模块
no agent ,不需要安装客户端(支持 ssh ), no server 不需要启动服务 ( ansible ),基于模块工作,可以使用任意语言开发模块,基于 ssh 工作 ( 基于密钥认证 ) , YAML 格式,编排任务,支持丰富的数据结构(剧本 playbook ), 使用 python 编写,维护简单常用的模块有: ping 、 user 、 group 、 file 、 shell 、 script 、 copy 、 yum 、 service 等
9、Ansbile工具的shell、script模块的区 别?
script 模块 —— > 在远程主机执行主控端的 shell / python 脚本。shell 模块 —— > 执行远程主机上的 shell / python 脚本。
10、描述一下ELK分别代表什么,各有什么特点
ELK 其实并不是一款软件,而是一整套解决方案,是三个软件产品的首字母缩写Elasticsearch :负责日志检索和储存Logstash :负责日志的收集和分析、处理Kibana :负责日志的可视化Filebeat :日志收集处理工具
11、ELK中的logstash 是怎么收集日志的,在客户端的 logstash 配置文件主要有哪些内容?
logstash 主要根据配置文件的配置来收集日志,其配置文件中 input 、 output 两大块配置及 filter 插件(不是配置必须的); input 中指定日志( type 、 path )等, output 指定日志输出的目标( host 、 port )
12、现在给你三百台服务器,你怎么对他们进行管理?
1 )设定跳板机,使用统一账号登录,便于安全与登录的考量。2 )使用 salt 、 ansiable 、 puppet 进行系统的统一调度与配置的统一管理。3 )建立简单的服务器的系统、配置、应用的 cmdb 信息管理。便于查阅每台服务器上的各种信息记录。
13、简述一下优化Linux系统的大概思路?
1. 不用 root ,添加普通用户,通过 sudo 授权管理2. 更改默认的远程连接 SSH 服务端口及禁止 root 用户远程连接3. 定时自动更新服务器时间4. 尽量配置国内 yum 源5. 调整文件描述符的数量6. 精简开机启动服务( crond rsyslog network sshd )7. 内核参数优化( / etc / sysctl.conf )8. 清空 / etc / issue ,去除系统及内核版本登录前的屏幕显示
八、数据库管理篇
1、简单描述一下MySQL的基本逻辑架构
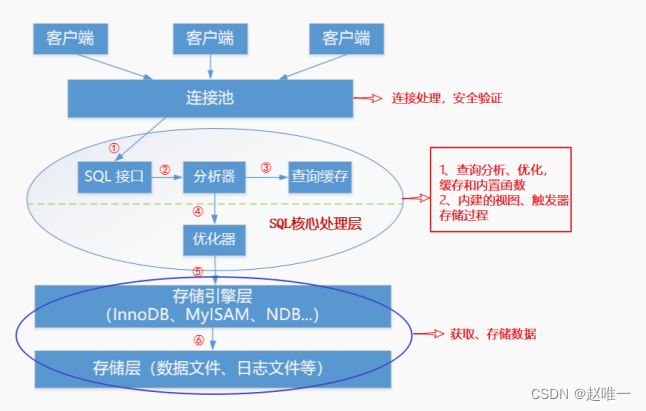
服务层 ( 连接池 ) :经典的 C / S 架构 , 主要是处理连接和安全验证。SQL 核心处理层:处理 MySQL 核心业务。查询分析,优化,缓存和内置函数。内建的视图,存储过程,触发器。存储引擎层:存储引擎负责数据的存储和提取。核心层通过存储引擎的 API 与存储引擎通信 , 来遮蔽不同存储引擎的差异 , 使得差异对上层透明化。存储层:专门用来存储数据文件、日志文件等物理文件。
2、请列出MySQL常用的数据类型,并写出定义这些数据类型所使用的关键字
MySQL 常用的数据类型:数值类型:所用关键字为 int 、 float字符类型:所用关键字为 char 、 varchar日期时间类型:所用关键字为 year 、 time 、 datetime枚举类型:所用关键字为 set 、 enum
优点:索引就像一本书的目录 , 加快查询记录的速度 ;缺点:会降低插入、更新记录的速度默认情况下, MYISAM 引擎的索引信息保存在 “ 表名 .MYI ” 文件中; InnoDB 引擎的数据和索引信息都保存在“ ibdata ” 文件中。
4、简述MySQL数据库访问的执行过程
1 )客户端发出请求。2 )服务器端打开线程响应客户端请求。3 )客户端发起 sql 语句查询数据库。4 )查询缓存:记录用户的 sql 查询语句,如果查询内容相同,直接从查询缓存取出。5 )如果缓存没有进入分析器。6 )分析器:分析用户命令语法是否正确,将用户的命令进行切片,一个词一个词用空格隔开,获得用户要查询的表、内容、用户的权限等。7 )优化器:执行路径的选择,生成执行树。(每个 SQL 语句都有很多执行路径,优化的目的就是在这些执行路径里选择最优的执行路径)。8 )存储引擎:用于管理存储的文件系统,不同的存储引擎有不同的功能和存储方式。
5、写出查找customer表中uid列内大于100的记录并以uid排序,正序输出前10条记录的SQL语句
select * from customer where uid > 100 order by uid asc limit 106、介绍一下备份MySQL数据库的常用工具及特点
一、社区版安装包中的备份工具
1. mysqldump (逻辑备份,只能全量备份)1 )企业版和社区版都包含2 )本质上使用 SQL 语句描述数据库及数据并导出3 )在 MYISAM 引擎上锁表, Innodb 引擎上锁行4 )数据量很大时不推荐使用2. mysqlhotcopy (物理备份工具)1 )企业版和社区版都包含2 ) perl 写的一个脚本,本质上是使用锁表语句后再拷贝数据3 )只支持 MYISAM 数据引擎
二、企业版安装包中的备份工具
mysqlbackup1 )在线备份2 )增量备份3 )部分备份4 )在某个特定时间的一致性状态的备份
三、第三方备份工具XtraBackup和innobackupex(物理备份)
1 ) Xtrabackup 是一个对 InnoDB 做数据备份的工具,支持在线热备份(备份时不影响数据读写),是商业备份工具 InnoDB Hotbackup 的一个很好的替代品。2 ) Xtrabackup 有两个主要的工具: xtrabackup 、 innobackupexa 、 xtrabackup 只能备份 InnoDB 和 XtraDB 两种数据表,不能备份 myisam 类型的表。b 、 innobackupex 是将 Xtrabackup 进行封装的 perl 脚本,所以能同时备份处理 innodb 和 myisam 的存储引擎,但在处理 myisam 时需要加一个读锁。
四、mydumper多线程备份工具(逻辑备份,备份SQL语句)
7、简单描述下在做数据库备份时都需要考虑哪些因素?
1. 首先必须明确需要备份哪些文件,如数据文件, binlog 日志文件、 my.cnf 配置文件等。然后必须制定详细的备份计划或策略,如备份频率、时间点、周期等。2. 备份数据应该放在非数据库本地,并建议有多份副本。3. 必须做好数据恢复的演练(每隔一段时间,对备份的数据在测试环境中进行模拟恢复,保证当出现数据灾难的时候能够及时恢复数据)。4. 根据数据应用的场合、特点选择正确的备份工具。5. 根据数据的一致性和服务的可用性来确定备份方案
8、什么是冷/热备份?他们各自有什么优点和缺点?
冷备份:需要备份的文档先关闭停止使用,再执行备份的方式;优点是简单快速、容易恢复到某个时间点、方便维护;缺点是只能恢复到某个时间点、备份期间数据不便正常使用。热备份:指执行备份时不影响备份文档正常使用的方式;优点是备份速度快、不影响数据使用;缺点是所有操作都会同步,包括删除。
9、什么是存储引擎?最常用的存储引擎有哪些?
1. 存储引擎说白了就是如何管理操作数据(存储数据、如何更新、查询数据等)的一种方法和机制。2. 在 MySql 数据库中提供了多种存储引擎,各个存储引擎的优势各不一样。3. 用户可以根据不同的需求为数据表选择不同的存储引擎,也可以根据自己的需要编写自己的存储引擎。4. 甚至一个库中不同的表使用不同的存储引擎,这些都是允许的。最常用的存储引擎是 MyISAM 和 InnoDB 。
10、介绍一下MySQL的二进制日志作用?
1. 二进制日志记录数据库的所有更改操作( DDL / DML / DCL ),不包含 select 或者 show 这类语句。2. 用于主从复制中, master 主服务器将二进制日志中的更改操作发送给 slave 从服务器,从服务器执行这些更改操作是的和主服务器的更改相同。3. 用于数据的恢复操作。默认二进制日志是关闭的,可以使用 log ‐ bin = xxx 参数开启
11、为了保证数据库安全性,开启二进制日志后,该文件会越来越大,如何正确清理?
show master(slave) status\Gpurge master logs before ’2020‐01‐02 00:00:00’;purge master logs to ’mysql‐bin.000001’;show variables like ‘expire_logs_days’;
set global expire_logs_days = 30;12、简述一下MySQL主从复制的原理
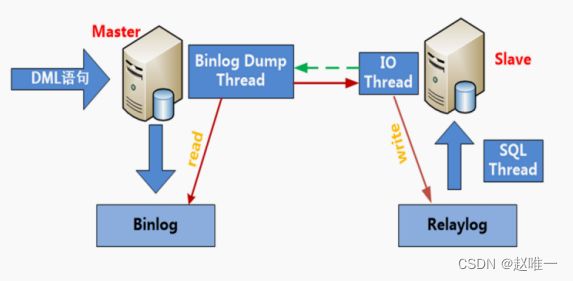
1. slave 端的 IO 线程发送请求给 master 端的 binlog dump 线程2. master 端 binlog dump 线程获取二进制日志信息 ( 文件名和位置信息 ) 发送给slave 端的 IO 线程3. salve 端 IO 线程获取到的内容依次写到 slave 端 relay log 里,并把 master端的 bin-log 文件名和位置记录到 master.info 里4. salve 端的 SQL 线程,检测到 relay log 中内容更新,就会解析 relay log里更新的内容,并执行这些操作,从而达到和 master 数据一致
13、描述一下关系型数据库中事务的四大特性
事务特点( ACID ):原子性 (Atomicity) :事务中的全部操作在数据库中是不可分割的,要么全部完成,要么均不执行。一致性 (Consistency) :指事务必须使数据库从一个一致性状态变换到另一个一致性状态,也就是说一个事务执行之前和执行之后都必须处于一致性状态,不能破坏关系数据的完整性以及业务逻辑上的一致性。隔离性 (Isolation) :一个事务的执行不受其他事务的干扰,事务执行的中间结果对其他事务必须 是透明的。隔离性是当多个用户并发访问数据库时,比如操作同一张表时,数据库为每一个用户开启的事务,不能被其他事务的操作所干扰,多个并发事务之间要相互隔离。持久性 (Durability) :持久性是指一个事务一旦被提交了,那么对数据库中的数据的改变就是永久性的,即便是在数据库系统遇到故障的情况下也不会丢失提交事务的操作。
14、如果mysql管理员密码忘了,如何找回?
mysql> update user set authentication_string ='123456' where user = 'root' and host='localhost';mysql> update user set passowrd = PASSWORD('123456') where user = 'root' and host='localhost';mysql> flush privileges;15、什么是MySQL多实例,如何配置MySQL多实例?
mysql 多实例就是在同一台服务器上启用多个 mysql 服务,它们监听不同的端口,运行多个服务进程,它们相互独立,互不影响的对外提供服务,便于节约服务器资源与后期架构扩展多实例的配置方法有两种:1 、一个实例一个配置文件,不同端口2 、同一配置文件 (my.cnf) 下配置不同实例,基于 mysqld_multi 工具
16、如何加强MySQL安全,请给出可行的具体措施?
1 、删除数据库不使用的默认用户2 、配置相应的权限(包括远程连接)3 、不可在命令行界面下输入数据库的密码4 、定期修改密码与加强密码的复杂度
1. 从库硬件比主库差,导致复制延迟2. 主从复制单线程,如果主库写并发太大,来不及传送到从库就会导致延迟。更高版本的 mysql 可以支持多线程复制3. 慢 SQL 语句过多,可以进行 SQL 优化4. 网络延迟5. master 负载:主库读写压力大,导致复制延迟,可以尝试再架构的前端要加入缓存层6. slave 负载
18、分析一下mysql无法启动可能的原因
1. 权限问题,安装目录其文件拥有者和所属组都不是 mysql 。2. 配置文件编写错误;3. / tmp 临时目录权限问题,导致 mysql 用户无法写。4. 端口被占用,或者 mysql 没有正常关闭导致进程挂死。5. 看错误日志,一般在 data 目录下的 mysql.err ,从日志找原因。
19、如果你们公司的网站访问很慢,你会如何排查 ?
1. 首先,问清楚反应的人哪个服务应用或者页面调取哪个接口慢,叫他把页面或相关的 URL 发给你。2. 接下来就一步一步排除,最直观的分析就是用浏览器按 F12 ,看下是哪一块的内容过慢( DNS 解析、网络加载、大图片、还是某个文件内容等),如果有,就对症下药去解决(图片慢就优化图片、网络慢就查看内网情况等)。3. 其次,看后端服务的日志,其实大多数的问题看相关日志是最有效分析,最好用 tail -f 跟踪一下日志,当然你也要点击测试来访问接口日志才会打出来。4. 最后,排查数据库 , 找到 sql 去 mysql 执行一下,看看时间是否很久,如果很久,就要优化 SQL 问题了, expain 一下 SQL 看看索引情况啥的,针对性优化。 数据量太大的能分表就分表,能分库就分库。如果 SQL 没啥问题,那可能就是写的逻辑代码的问题了,一行行审代码,找到耗时的地方改造,优化逻辑。
20、线上全是 mysql 5.5 的环境,有没有办法搭建5.5到5.7的复制?
可以,但不能开启 gtid 功能。但是非常不建议跨大版本的 MySQL Replication ,更何况是垮了 2 个大版本,最好是先进行升级。
九、Linux云计算篇
1、使用云计算有哪些优点?可否列举哪些平台用于大规模云计算?
使用云计算有下列优点:a )备份数据和存储数据b )强大的服务器功能c ) SaaS (软件即服务)d )信息技术沙盒功能e )提高生产力f )具有成本效益,并节省时间
用于大规模云计算的平台包括:
a ) Apache Hadoopb ) MapReduce
2、简述云计算的实现方式有哪些?
云计算的实现方式有: Private 、 IaaS 、 PaaS 、 SaaSPrivate :传统 / 私有方式优点:所有事情都亲自做,可控缺点:用户成本比较高,要求自身技术水平高典型软件:传统物理机IaaS :基础设施即服务优点:底层硬件到操作系统,都不需要用户操心,可以集中精力做业务项目缺点:服务商提供的东西,不能自己自由定制,不可控典型软件: OpenStack 、 CloudStackPaaS :平台即服务优点:对于只会开发不会运维的人员比较友好,底层到运行环境,都不需要用户操心,可以集中精力做应用项目缺点:服务商提供的东西,不灵活,只适用于特殊的应用项目SaaS :软件、应用即服务优点:所有东西都由服务商提供,用户只需要花钱就行,对于广大企业来说,SaaS 是采用先进技术实施信息化的最好途径。比如说,买企业邮箱,买财务软件云缺点:对客户来说,所有的东西都不可控,安全性不够。
3、描述一下OpenStack的常见组件有哪些?
Cinder :为 VMs 提供持久的块存储能力,支持多种存储方式,工作中 ceph 用的比较多Glance :用于存储和检索磁盘映像文件,支持多种存储方式Heat : openstack 的任务编排工具Horizon : openstack 的 web 可视化界面Keystone ;为 Openstack 中的所有服务提供了认证、授权以及端点编录服务员Nova :管理 VM 的所有操作Netron :为 Openstack 提供网络的功能;插件化设计,支持众多流行的网络Swift :分布式存储,基于 RESTful 的 API 实现非结构化数据对象的存储及检索Trove :提供数据库即服务的功能sahara :在 OpenStack 中提供大数据服务,生产可用Octavia : openstack 中的负载均衡项目,生产可用。IRonic ,物理裸机管理,目前是非常好用。Ceilometer ,用于实现监控和计量服务的实现,缺乏后续发展
4、OpenStack的核心服务有哪些?
compute 、 networking 、 storage 、 dashboard
5、容器退出后,通过docker ps 命令查看不到,数据会丢失么?
容器退出后会处于终止( exited )状态,此时可以通过 docker ps - a 查看,其中数据不会丢失,还可以通过 docker start 来启动,只有删除容器才会清除数据。
6、如何控制容器占用系统资源(CPU,内存)的份额?
在使用 docker create 命令创建容器或使用 docker run 创建并运行容器的时候,可以使用‐ c | – cpu ‐ shares[ = 0 ] 参数来调整同期使用 CPU 的权重,使用‐ m | – memory 参数来调整容器使用内存的大小。
7、如何更改Docker的默认存储设置?
Docker的默认存放位置是/var/lib/docker,如果希望将Docker的本地文件存储到其他分区,可以使用Linux软连接的方式来做。
8、Docker公司的三款用于解决多容器分布式软件可移植部署的问题,推出的编排工具有哪些?
1.D ocker Machine :为本地私有数据中心及公有云平台提供 Docker 引擎,实现从零到 Docker 的一键部署。2.D ocker Compose :是一个编排多容器分布式部署的工具,提供命令集管理容器化应用的完整开发周期,包括服务构建,启动和停止。3.D ocker Swarm :为 Docker 容器提供了原生的集群,它将多个 Docker 引擎的资源汇聚在一起,并提供 Docker 标准的 API ,使 Docker 可以轻松扩展到多台主机。
9、简单描述Docker-compose编排和管理多容器的过程?
1. 使用 Dockerfile 定义应用依赖的镜像2. 使用 docker ‐ compose.yml 定义应用具有的服务3. 通过 docker ‐ compose up 命令创建并运行应用
10、简单描述云计算与虚拟化区别?
虚拟化是一种技术,云计算是资源交付模式,云计算不等于虚拟化。云计算是基于虚拟化技术的一种资源交付使用模式。
11、写出hadoop集群常用进程以及进程含义
1 、 Namenode它是 Hadoop 中的主服务器,管理文件系统名称空间和对集群中存储的文件的访问。2 、 Datanode它负责管理连接到节点的存储(一个集群中可以有多个节点)。每个存储数据的节点运行一个 datanode 守护进程。3 、 secondaryNameNode它不是 namenode 的冗余守护进程,而是提供周期检查点和清理任务。 出于对可扩展性和容错性等考虑,我们一般将 SecondaryNameNode 运行在一台非 NameNode 的机器上。4 、 ResourceManager负责调度 DataNode 上的工作。每个 DataNode 有一个 NodeManager ,它们执行实际工作。5 、 NodeManager负责执行 ResourceManager 分发的任务
12、在使用云计算平台前,用户需要考虑哪些必要的方面?
1. 数据丢失2. 数据存储3. 业务连续性4. 正常运行时间5. 云计算的数据完整性
13、云架构有别于传统架构的特点有哪些?
a )按照需求,云架构满足硬件要求。b )云架构能够按需增减资源。c )云架构能够管理和处理动态工作负载,顺畅无阻。
14、简单列出云计算的基本特点?
a )弹性和可扩展性b )自助式配置和自动取消配置c )标准化界面d )自助计费的使用模式
15、什么是Kubernetes?Kubernetes与Docker有什么关系?
什么是kubernetes?
Kubernetes 是一个开源容器管理工具,负责容器部署,容器扩缩容以及负载平衡。作为 Google 的创意之作,它提供了出色的社区,并与所有云提供商合作。因此,我们可以说 Kubernetes 不是一个容器化平台,而是一个多容器管理解决方案。
kubernetes和Docker关系:
众所周知, Docker 提供容器的生命周期管理, Docker 镜像构建运行时容器。但是,由于这些单独的容器必须通信,因此使用 Kubernetes 。因此,我们说 Docker 构建容器,这些容器通过 Kubernetes 相互通信。因此,可以使用 Kubernetes 手动关联和编排在多个主机上运行的容器。
16、Kubernetes如何简化容器化部署?
由于典型应用程序将具有跨多个主机运行的容器集群,因此所有这些容器都需要相互通信。因此,要做到这一点,你需要一些能够负载平衡,扩展和监控容器的东西。由于 Kubernetes 与云无关并且可以在任何公共 / 私有提供商上运行,因此必须是您简化容器化部署的选择。
17、你对Kubernetes的负载均衡器有什么了解?
负载均衡器是暴露服务的最常见和标准方式之一。根据工作环境使用两种类型的 负载均衡器,即内部负载均衡器或外部负载均衡器。内部负载均衡器自动平衡负载并使用所需配置分配容器,而外部负载均衡器将流量从外部负载引导至后端容器。
18、您如何看待公司从单一服务转向微服务并部署其服务容器?
由于公司的目标是从单一应用程序转向微服务,它们最终可以逐个构建,并行构建,只需在后台切换配置。然后他们可以将这些内置微服务放在 Kubernetes 平台上。因此,他们可以从一次或两次迁移服务开始,并监控它们以确保一切运行稳定。一旦他们觉得一切顺利,他们就可以将其余的应用程序迁移到他们的 Kubernetes 集群中。
19、公司希望通过维持最低成本来提高其效率和技术运营速度,您认为公司将如何实现这一目标?
公司可以通过构建 CI / CD 管道来实现 DevOps 方法,但是这里可能出现的一个问题是配置可能需要一段时间才能启动并运行。因此,在实施 CI / CD 管道之后,公司的下一步应该是在云环境中工作。一旦他们开始处理云环境,他们就可以在集群上安排容器,并可以在 Kubernetes 的帮助下进行协调。这种方法将有助于公司缩短部署时间,并在各种环境中加快速度。
20、假设公司希望在不同的云基础架构上运行各种工作负载,从裸机到公共云。公司将如何在不同界面的存在下实现这一目标?
该公司可以将其基础设施分解为微服务,然后采用 Kubernetes 。这将使公司在不同的云基础架构上运行各种工作负载。
十、python编程篇
1、脚本生成随机的20个ID
#!/usr/bin/python
import datetime
idlist =[]
for _ in range(20):
s1=datetime.datetime.now().timestamp() #返回的是时间戳,但是带微秒
s2=".join([str(random.randint(0,9)) for _ in range(3)])"
s3=".join([chr(random.randint(97,122)) for _ in range(8)])"
idlist.append(str(int(s1))+'_'+s2+'_'+s3)
print(idlist)2、写脚本判断密码强弱
#!/usr/bin/python
s=input("请输入密码: ")
count=0
flag1,flag2,flag3,flag4=True,True,True,True
len=len(s)
if len>= 10 and len<=15:
for i in s:
if i in "0123456789":
if flag1:
count+=1
flag1=False
if i in "ABCDEFGHIJKLMNOPQRSTUVWXYZ":
if flag2:
count+=1
flag2=False
if i in "abcdefghijklmnopqrstuvwxyz":
if flag3:
count+=1
flag3=False
if i in "_":
if flag4:
count+=1
flag4=False
if count==4:
print("it's a right passwd")
else:
print("passwd is wrong")
else:
print("the length is wrong")3、写脚本列举当前目录以及所有子目录下的文件,并打印出绝对路径
#!/usr/bin/env python
import os
for root,dirs,files in os.walk('/tmp'):
for name in files:
print (os.path.join(root,name))
os.walk()4、写脚本生成磁盘使用情况的日志文件
#!/usr/bin/env python
import time
import os
new_time = time.strftime('%Y‐%m‐%d')
disk_status = os.popen('df ‐h').readlines()
str1 = ''.join(disk_status)
f = file(new_time+'.log','w')
f.write('%s' % str1)
f.flush()
f.close()5、写脚本统计出每个IP的访问量有多少?(从日志文件中查找)
#!/usr/bin/python
list = []
f = file('/usr/local/nginx/logs/access.log')
str1 = f.readlines()
f.close()
for i in str1:
ip = i.split()[0]
list.append(ip)
list_num = set(list)
for j in list_num:
num = list.count(j)
print '%s : %s' %(j,num)