linux split join paste uniq tee sort 工作中文本操作常用方法
本文主要是linux文本常见命令,主要内容如下:
split命令将文件按指定行数/size分成小文件,grep -c / awk/wc -l file*统计每个文件行数
join/paste将多个文件按照列合并
tee >>流重定向到文件, /dev/null使用
sort对文件按照指定列排序, uniq按照列获取唯一列大小,每列计数等
cat/tac文件查看,内容重定向到文件
head /tail /less常用功能
split命令将文件按指定行数/size分成小文件,grep -c / awk/wc -l file*统计每个文件行数
工作中有时候需要将一个很大的文件分成一个个小的文件(日志文件很大,直接统计太耗性能,有时可以考虑将其分为小文件在处理),比如一个文件有100K行,我们一个把他分成100个每个只含有1K行的小文件,使用(google -> linux split file into small files by line num)
split -l 1000 large.txt
例如下面我们将一个文件分成小文件每个10行
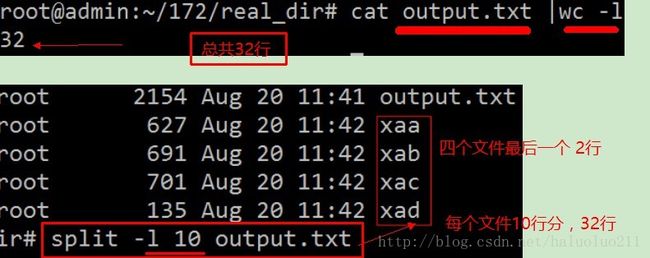
grep -c “” 统计每个文件的大小
root@admin:~/real_dir# for f in xa*;do echo "$f";grep -c "" $f;done
xaa
10
xab
10
xac
10
xad
2当然也可以使用awk将文件名按照参数传递统计(google-> awk count file line/ linux pass parameter to awk ):

当然统计行数首先想到 wc -l (也可统计多个文件,一般统计一个)
# for statistic every file line, just
wc -l xa*
# for example(google -> linux count multiple files line num)
root@ubuntu:/data/services# wc -l out*
10 out1.txt
10 out2.txt
20 total
split 也可以分割 .zip 文件,默认的文件名是 x* ,默认1000行。
当然我们也可以添加前缀例如:
$ split -a5 split.zip
$ ls
split.zip xaaaac xaaaaf xaaaai xaaaal ...
xaaaaa xaaaad xaaaag
# 数字前缀
$ split -d split.zip
$ ls
split.zip x01 x03 x05 x07 x09 ...
x00 x02 x04 x06 x08
join/paste将多个文件按照列合并
paste将文件按照列合并(google->linux merge files by column),例如:
#文件file1, file2内容如下
cat file1
file1 line1
file1 line2
cat file2
file2 line1
file2 line2
# 下面paste将文件file1 2 按照列合并,然后awk输出最后重定向到file3中
paste file{1,2} | awk '{print $1, $2, $3, $4}' > file3
#输出file3
cat file3
file1 line1 file2 line1
file1 line2 file2 line2
# awk 输出所有文件内容
root@ubuntu:/data/services# awk '1' file*
file1 line1
file1 line2
file2 line1
file2 line2
file1 line1 file2 line1
file1 line2 file2 line2join将文件按照列合并,
#文件file1, file2内容如下
cat file1
file1 line1
file1 line2
cat file2
file2 line1
file2 line2
#使用join的时候默认需要第一列相等,由此我们考虑使用cat -n这个每行内容加上了行数,即可,使用 `<` 将输出作为stdin标准输入流
root@ubuntu:/data/services# join <(cat -n file1) <(cat -n file2)
1 file1 line1 file2 line1
2 file1 line2 file2 line2join 按照指定的列合并:
cat wine.txt
Red Beaunes France
White Reisling Germany
Red Riocha Spain
cat reviews.txt
Beaunes Great!
Reisling Terrible!
Riocha Meh
#我们需要把 wine.txt按照第二列,reviews.txt按照第一列:
join -1 2 -2 1 wine.txt reviews.txt
Beaunes Red France Great!
Reisling White Germany Terrible!
Riocha Red Spain Meh
join在合并前需要我们对指定的列是排好序的,如果指定列没有排序则会报错:
cat wine.txt
White Reisling Germany
Red Riocha Spain
Red Beaunes France
cat reviews.txt
Riocha Meh
Beaunes Great!
Reisling Terrible!
join -1 2 -2 1 wine.txt reviews.txt
# 报错如下:
#join: wine.txt:3: is not sorted: Red Beaunes France
#join: reviews.txt:2: is not sorted: Beaunes Great!
# 使用sort按照列排序,然后重定向即可
join -1 2 -2 1 <(sort -k 2 wine.txt) <(sort reviews.txt)
Beaunes Red France Great!
Reisling White Germany Terrible!
Riocha Red Spain Mehjoin默认是按照空格作为分隔符,当然我们也可以指定:
cat wine.txt
Red,Beaunes,France
White Reisling,Germany
Red,Riocha,Spain
cat reviews.txt
Beaunes,Great!
Reisling,Terrible!
Riocha,Meh
# 指定即可
join -t, wine.txt reviews.txt join -o指定列的顺序:
cat names.csv
1,John Smith,London
2,Arthur Dent, Newcastle
3,Sophie Smith,London
cat transactions.csv
£1234,Deposit,John Smith
£4534,Withdrawal,Arthur Dent
£4675,Deposit,Sophie Smith
join -1 2 -2 3 -t , names.csv transactions.csv
John Smith,1,London,£1234,Deposit
Arthur Dent,2, Newcastle,£4534,Withdrawal
Sophie Smith,3,London,£4675,Deposit
join -1 2 -2 3 -t , -o 1.1,1.2,1.3,2.2,2.1 names.csv transactions.csv
1,John Smith,London,Deposit,£1234
2,Arthur Dent, Newcastle,Withdrawal,£4534
3,Sophie Smith,London,Deposit,£4675tee >>流重定向到文件, /dev/null使用
比如我们要将标准输出(stdout)标准错误输出(stderr)输出到终端以及文件中可以使用
command |& tee file.log
追加到日志文件
command |& tee -a output.txt
或者是
./ex1 > outfile 2>&1 或者 ./ex1 &> outfile
下面是caffe图片训练时候的结果输出到日志文件(图片来自个人笔记):

sort对文件按照指定列排序, uniq按照列获取唯一列大小,每列计数等
- uniq对文件的指定的列取unique的时候需要指定列已经是排好序,例如:
$ cat test
aa
aa
bb
bb
$ uniq test.txt
aa
bb
# 如果不排序的话文件内容如下,使用 uniq test.txt输出结果不变
aa
bb
aa
bb- 使用uniq -c 统计每个key对应的行数:
$ uniq -c test.txt
2 aa
2 bb这对于日志统计还是挺有作用的,例如我们要统计日志中:error_info, 以及 warn_info行数(已经排好序)
可以 uniq -c log.txt | grep -e 'error_info' -e 'warn_info'
输出重复的列:
uniq -d filename只按照指定字符统计例如按照前10个字符作为key
uniq -c -w 10 filenamesort排序
-f:忽略大小写,-b:忽略前面的空格,-n使用纯数字排序 -t: 分隔符默认的是 Tab ,-k:区间 -r反向排序

- 指定uniq
cat awk_test.txt
10,15-10-2014,abc
20,12-10-2014,bcd
10,09-10-2014,def
sort -u -t, -k 1 awk_test.txt
10,15-10-2014,abc
20,12-10-2014,bcd我们也可以对文件大小排序显示(-n按照数字排序而不是字符串):
ll | sort -k 5 -n
也可以(-h 按照文件大小):
$ cat test
2M
1G
1K
$ sort -h test
1K
2M
1G
下面是深度学习train.txt(每个类别的样本数量,类型统计,并排序)
其中0,1….代表类别0, 1…..后面的代表数量

cat/tac文件查看,内容重定向到文件
cat的使用一般就是 :
- cat file (输出file所有内容)
- cat file > output.txt(重定向写到文件)
- cat -n file 输出行号
tac 反向输出文件
head /tail /less常用功能
head
* head -2 file输出前两行(head file 默认的前十行)
* head -n 2 file(输出前两行带行号)
tail 一般就是
* tail -f log.txt动态查看日志
* tail file(默认查看后十行)
上面很多命令是实践中常用的总结,部分来源与google搜索,以及
http://www.thegeekstuff.com/category/sed/ 这位大神的bolg
google -> linux command thegeekstuff