Flink服务的HA配置
文章目录
- Standalone 模式HA
- Flink On Yarn 模式HA
默认情况下,每个 Flink 集群只有一个 JobManager,这将导致单点故障(SPOF),如果这个 JobManager 挂了,则不能提交新的任务,并且运行中的程序也会失败。使用JobManager HA,集群可以从 JobManager 故障中恢复,从而避免单点故障。用户可以在Standalone 或 Flink on Yarn 集群模式下配置 Flink 集群 HA(高可用性)。
Flink 的HA需要Zookeeper和HDFS,因此首先要安装启动 zk、hdfs。
Standalone 模式HA
Standalone 模式下,JobManager 的高可用性的基本思想是,任何时候都有一个 AliveJobManager 和多个 Standby JobManager。Standby JobManager 可以在 Alive JobManager挂掉的情况下接管集群成为 Alive JobManager,这样避免了单点故障,一旦某一个 StandbyJobManager 接管集群,程序就可以继续运行。Standby JobManagers 和 Alive JobManager实例之间没有明确区别,每个 JobManager 都可以成为 Alive 或 Standby。配置步骤如下
修改masters配置文件
增加master节点配置如下:
[root@server01 conf]# vi masters
server01:8081
server02:8081
server03:8081
修改 conf/flink-conf.yaml
增加高可用相关配置,配置如下配置项
high-availability: zookeeper
# The path where metadata for master recovery is persisted. While ZooKeeper stores
# the small ground truth for checkpoint and leader election, this location stores
# the larger objects, like persisted dataflow graphs.
#
# Must be a durable file system that is accessible from all nodes
# (like HDFS, S3, Ceph, nfs, ...)
#
high-availability.storageDir: hdfs://server01:9000/flink/ha
# The list of ZooKeeper quorum peers that coordinate the high-availability
# setup. This must be a list of the form:
# "host1:clientPort,host2:clientPort,..." (default clientPort: 2181)
#
high-availability.zookeeper.quorum: server03:2181
将修改的配置文件 复制到其他Flink节点上
root@server01 conf]# scp masters root@server03:/opt/apps/flink/conf
root@server01 conf]# scp masters root@server02:/opt/apps/flink/conf
root@server01 conf]# scp flink-conf.yaml root@server03:/opt/apps/flink/conf
root@server01 conf]# scp flink-conf.yaml root@server02:/opt/apps/flink/conf
启动集群
[root@server01 flink]# bin/start-cluster.sh
Starting HA cluster with 3 masters.
Starting standalonesession daemon on host server01.
Starting standalonesession daemon on host server02.
Starting standalonesession daemon on host server03.
Starting taskexecutor daemon on host server01.
Starting taskexecutor daemon on host server02.
Starting taskexecutor daemon on host server03.
Flink On Yarn 模式HA
正常基于 Yarn 提交 Flink 程序,无论是使用 yarn-session 模式还是 yarn-cluster 模式 , 基 于 yarn 运 行 后 的 application 只 要 kill 掉 对 应 的 Flink 集 群 进 程“YarnSessionClusterEntrypoint”后,基于 Yarn 的 Flink 任务就失败了,不会自动进行重试,所以基于 Yarn 运行 Flink 任务,也有必要搭建 HA,这里同样还是需要借助 zookeeper来完成
修改所有 Hadoop 节点的 yarn-site.xml
将所有 Hadoop 节点的 yarn-site.xml 中的提交应用程序最大尝试次数调大,增加如下配置
<property>
<name>yarn.resourcemanager.am.max-attempts</name>
<value>4</value>
</property>
将修改后的文件复制到其他hadoop节点
[root@server01 hadoop]# scp yarn-site.xml root@server02:/opt/apps/hadoop/etc/hadoop
yarn-site.xml 100% 1146 414.4KB/s 00:00
[root@server01 hadoop]# scp yarn-site.xml root@server03:/opt/apps/hadoop/etc/hadoop
yarn-site.xml 100% 1146 401.7KB/s 00:00
[root@server01 hadoop]#
重启 hdfs 和 zk
修改 flink-conf.yaml
修改内容如下:
high-availability: zookeeper
# The path where metadata for master recovery is persisted. While ZooKeeper stores
# the small ground truth for checkpoint and leader election, this location stores
# the larger objects, like persisted dataflow graphs.
#
# Must be a durable file system that is accessible from all nodes
# (like HDFS, S3, Ceph, nfs, ...)
#
high-availability.storageDir: hdfs://server01:9000/flink/ha
# The list of ZooKeeper quorum peers that coordinate the high-availability
# setup. This must be a list of the form:
# "host1:clientPort,host2:clientPort,..." (default clientPort: 2181)
#
high-availability.zookeeper.quorum: server03:2181
yarn.application-attempts: 10
启动
[root@server01 conf]# ../bin/yarn-session.sh -n 2
2020-08-21 16:29:04,396 INFO org.apache.flink.configuration.GlobalConfiguration - Loading configuration property: jobmanager.rpc.address, server01
2020-08-21 16:29:04,398 INFO org.apache.flink.configuration.GlobalConfiguration - Loading configuration property: jobmanager.rpc.port, 6123
2020-08-21 16:29:04,398 INFO org.apache.flink.configuration.GlobalConfiguration - Loading configuration property: jobmanager.heap.size, 1024m
2020-08-21 16:29:04,398 INFO org.apache.flink.configuration.GlobalConfiguration - Loading configuration property:
2020-08-21 16:29:37,803 INFO org.apache.flink.runtime.rest.RestClient - Rest client endpoint started.
Flink JobManager is now running on server03:43760 with leader id 0d61bb85-a445-4de1-8095-6316288dee5e.
JobManager Web Interface: http://server03:34306
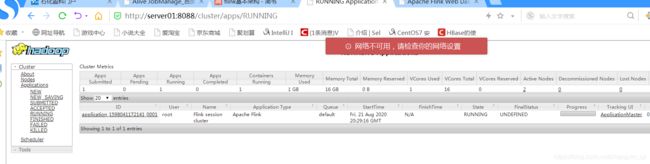
通过yarn 可以看到我们启动的 flink集群
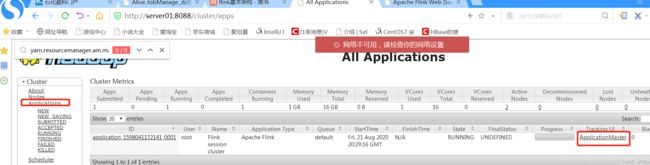
可以看到flink jobmanager 启动在server03上
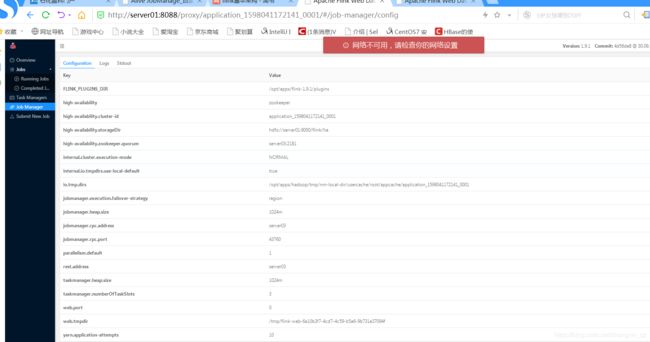
进入对应的节点,kill 掉对应的“YarnSessionClusterEntrypoint”进程。
[root@server03 zookeeper]# jps
7506 DataNode
7767 QuorumPeerMain
8711 TaskManagerRunner
8760 Jps
7625 NodeManager
8761 Jps
8251 StandaloneSessionClusterEntrypoint
[root@server03 zookeeper]# kill -9 8251
[root@server03 zookeeper]# jps
9057 NodeManager
9475 YarnSessionClusterEntrypoint
7767 QuorumPeerMain
8711 TaskManagerRunner
9577 Jps
8958 DataNode
[root@server03 zookeeper]# kill -9 9475
Yarn中观察“applicationxxxx_0001”job 信息 重试后仍然可用