redis单机、主从、哨兵、集群模式
redis单机、主从、哨兵、集群模式
- 一、单机模式
-
- 1、基本介绍
- 2、安装
- 3、SpringBoot集成Redis 单机模式
-
- 1.创建demo
- 2.创建test测试
- 二、主从模式
-
- 1、基本介绍
- 2、搭建
- 3、介绍数据同步:
-
- 1.全量同步
- 2. 增量同步
- 3.优化Redis主从就集群:
- 4.全量同步和增量同步
- 三、哨兵模式(2.8版本开始引入哨兵)
-
- 1、介绍哨兵
- 2、 搭建哨兵集群
- 3、测试主备切换:
- 4、 SpringBoot集成Redis 哨兵模式
-
- 添加配置
- 四、分片集群模式
-
- 1、介绍分片集群模式(3.0之后)
- 2、搭建
- 3、散列插槽概念
- 4、 RedisTemplate访问分片集群
一、单机模式
1、基本介绍
单机模式是最简单的,redis启动后,业务调用即可。
优点:
- 部署简单
- 没有备用节点,成本低
- 单机不需要同步数据,单个机器的性能高
缺点:
- 可靠性低,单节点宕机后,redis就无法继续使用
- 单机的高性能和存储能力,都无法满足双十一这种高性能、高缓存场景。
2、安装
大多数企业都是基于Linux服务器来部署项目,而且Redis官方也没有提供Windows版本的安装包
- 官网下载redis:
https://redis.io/download/
如果说国外的网站太慢,可以在中国友人翻译的redis完整,进行下载,但是并没有最新版本:http://www.redis.cn/ - 解压:
tar -xzf redis-6.2.6.tar.gz - 运行并且编译
make && make install默认的安装路径是在/usr/local/bin目录
redis-cli:是redis提供的命令行客户端
redis-server:是redis的服务端启动脚本
redis-sentinel:是redis的哨兵启动脚本
- 进入
解压的目录下备份一份redis.conf配置文件。并且进行修改配置redis-conf 文件
# 允许访问的地址,默认是127.0.0.1,会导致只能在本地访问。修改为0.0.0.0则可以在任意IP访问,生产环境不要设置为0.0.0.0
bind 0.0.0.0
# 守护进程,修改为yes后即可后台运行
daemonize yes
# 密码,设置后访问Redis必须输入密码
requirepass 123321
# 监听的端口
port 6379
# 工作目录,默认是当前目录,也就是运行redis-server时的命令,日志、持久化等文件会保存在这个目录
dir .
# 数据库数量,设置为1,代表只使用1个库,默认有16个库,编号0~15
databases 1
# 设置redis能够使用的最大内存
maxmemory 512mb
# 日志文件,默认为空,不记录日志,可以指定日志文件名
logfile "redis.log"
- 在
解压的目录下进行启动:redis-server redis.conf
查看redis是否启动成功ps -ef |grep redis - 启动开机自动启动redis:
建一个系统服务文件:vi /etc/systemd/system/redis.service
[Unit]
Description=redis-server
After=network.target
[Service]
Type=forking
#ExecStart= 服务地址 和配置文件
ExecStart=/usr/local/bin/redis-server /usr/local/src/redis-6.2.6/redis.conf
PrivateTmp=true
[Install]
WantedBy=multi-user.target
然后重载系统服务:systemctl daemon-reload
# 启动
systemctl start redis
# 停止
systemctl stop redis
# 重启
systemctl restart redis
# 查看状态
systemctl status redis
3、SpringBoot集成Redis 单机模式
1.创建demo
- 基于spring Initializr来创建一个springBoot项目
我的springBoot版本是:2.2.5.RELEASE
其中我勾选了Spring Data Redis和Lombok - 引入依赖
<dependency>
<groupId>org.springframework.bootgroupId>
<artifactId>spring-boot-starter-data-redisartifactId>
dependency>
<dependency>
<groupId>org.apache.commonsgroupId>
<artifactId>commons-pool2artifactId>
dependency>
- 配置application.yml配置文件
spring:
redis:
# Redis服务器地址
host: 192.168.0.121
# Redis服务器端口
port: 6379
# Redis服务器密码
password: root
# 选择哪个库,默认0库
database: 0
# 连接超时时间
timeout: 10000ms
lettuce:
pool:
max-active: 8 # 最大连接
max-idle: 8 #最大空闲连接
min-idle: 0 # 最小空闲连接
max-wait: 100 # 连接等待时间
2.创建test测试
@SpringBootTest
public class RedisDemoLettuce {
@Autowired
private StringRedisTemplate stringRedisTemplate;
@Test
public void testString(){
ValueOperations<String, String> ops = stringRedisTemplate.opsForValue();
ops.set("name", "zhangsan");
System.out.println(ops.get("name")); //zhangsan
}
@Test
public void testHash(){
HashOperations<String, String, String> opsHash = stringRedisTemplate.opsForHash();
opsHash.put("user:001","name","zhangsan");
opsHash.put("user:001","age","13");
String name = opsHash.get("user:001", "name");
String age = opsHash.get("user:001", "age");
System.out.println(name+age); //zhangsan 13
}
}
二、主从模式
1、基本介绍
主从模式:将一台Redis服务器的数据,复制到其他的Redis服务器。数据的复制是单向的,只能由主节点到从节点。主节点负责读写、从节点只负责读操作。

为什么要开启读写分离?
- 在大多redis应用环境中,读操作比较多,而写操作比较少。
- 单节点Redis的并发能力是有上限的,要进一步提高redis的并发能力,就需要搭建主从集群,实现读写分离。
优点:
- 高可用的基石:如果主节点宕机,从节点可以继续使用 宕机前的备份数据 进行读工作
- 相对单节点,提高了读的能力。分担了主节点的读压力
缺点:
- 数据冗余问题,因为主从节点中的数据,都是相同数据
- 数据也存在存储能力
- 主节点宕机后,需要人工干预,进行主从切换
2、搭建
在一台虚拟机上进行测试,一共三个节点,一主两从。
- 创建了3个文件夹,存放配置信息
mkdir tmp-redis 7001 7002 7003
准备配置文件:
# 允许访问的地址,默认是127.0.0.1,会导致只能在本地访问。修改为0.0.0.0则可以在任意IP访问,生产环境不要设置为0.0.0.0
bind 0.0.0.0
# 守护进程,修改为yes后即可后台运行
daemonize yes
# 密码,设置后访问Redis必须输入密码
requirepass 123321
# 监听的端口
port 6379
# 数据库数量,设置为1,代表只使用1个库,默认有16个库,编号0~15
databases 1
# 设置redis能够使用的最大内存
maxmemory 512mb
- 将redis.conf配置信息,移动到是三个配置文件中
echo 7001 7002 7003 | xargs -t -n 1 cp redis-6.2.4/redis.conf - 修改三个配置文件中的配置:
第一:修改每个实例的端口、工作目录
修改每个文件夹内的配置文件,将端口分别修改为7001、7002、7003,将rdb文件保存位置都修改为自己所在目录(在/tmp目录执行下列命令):
sed -i -e 's/6379/7001/g' -e 's/dir .\//dir \/tmp\/7001\//g' 7001/redis.conf
sed -i -e 's/6379/7002/g' -e 's/dir .\//dir \/tmp\/7002\//g' 7002/redis.conf
sed -i -e 's/6379/7003/g' -e 's/dir .\//dir \/tmp\/7003\//g' 7003/redis.conf
第二:修改每个实例的声明IP
虚拟机本身有多个IP,为了避免将来混乱,我们需要在redis.conf文件中指定每一个实例的绑定ip信息,格式如下:
# redis实例的声明 IP
replica-announce-ip 192.168.150.101
# 一键修改
printf '%s\n' 7001 7002 7003 | xargs -I{} -t sed -i '1a replica-announce-ip 192.168.75.111' {}/redis.conf
- 开启主从关系
有临时和永久两种模式:
-
修改配置文件(永久生效)
- 在redis.conf中添加一行配置:
slaveof
- 在redis.conf中添加一行配置:
-
使用redis-cli客户端连接到redis服务,执行slaveof命令(重启后失效):
slaveof
注意:在5.0以后新增命令replicaof,与salveof效果一致。
- 开启主从服务:
# 第1个
redis-server 7001/redis.conf
# 第2个
redis-server 7002/redis.conf
# 第3个
redis-server 7003/redis.conf
- 测试 主能读写、从只能读
可以发现,只有在7001这个master节点上可以执行写操作,7002和7003这两个slave节点只能执行读操作.
3、介绍数据同步:
1.全量同步
全量同步:主从第一次连接时会执行全量同步,将master节点所有的数据拷贝给slave节点。
简述全量同步的流程?
- slave节点请求增量同步
- master节点判断replid,发现不一致,拒绝增量同步
- master将完整内存数据生成RDB,发送RDB到slave
- slave清空本地数据,加载master的RDB
- master将RDB期间的命令记录在repl_baklog,并持续将log中的命
令发送给slave - slave执行接收到的命令,保持与master之间的同步
2. 增量同步
增量同步的过程:
-
slave请求增量同步
-
master检查replid是否一致?
- 不一致:全量同步
- 一致:去repl_baklog中获取offset后的数据
-
发送offset后的命令
-
执行命令
3.优化Redis主从就集群:
- 在master中配置repl-diskless-sync yes启用无磁盘复制,避免全量同步时的磁盘IO。
- Redis单节点上的内存占用不要太大,减少RDB导致的过多磁盘IO
- 适当提高repl_baklog的大小,发现slave宕机时尽快实现故障恢复,尽可能避免全量同步
- 限制一个master上的slave节点数量,如果实在是太多slave,则可以采用主-从-从链式结构,减少master压力
4.全量同步和增量同步
简述全量同步和增量同步区别?
- 全量同步:master将完整内存数据生成RDB,发送RDB到slave。后续命令则记录在repl_baklog,逐个发送给slave。
- 增量同步:slave提交自己的offset到master,master获取repl_baklog中从offset之后的命令给slave
什么时候执行全量同步?
- slave节点第一次连接master节点时
- slave节点断开时间太久,repl_baklog中的offset已经被覆盖时
什么时候执行增量同步?
- slave节点断开又恢复,并且在repl_baklog中能找到offset时
三、哨兵模式(2.8版本开始引入哨兵)
1、介绍哨兵
哨兵Sentinel也是一个集群,哨兵节点是特殊的redis节点,不存储数据。
访问redis集群的数据都是通过哨兵集群的,哨兵监控整个redis集群。
Redis的Sentinel最小配置是 一主一从。
哨兵基于主从模式,主从有的优点,哨兵全部都有。
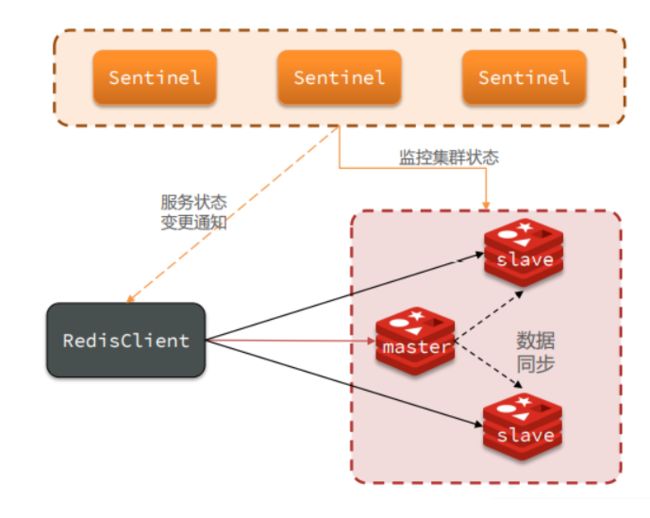
哨兵的作用:
- 监控:Sentinel会不断检查您的master和slave是否按预期工作
- 主备切换:如果master故障,sentinel会将一个slave提升为master。当故障实例恢复后也以新的master为主,旧的master成为slave
- 通知:sentinel充当Reids客户端的服务发现来源,当集群发生故障转移时,会将最新消息推送给Redis的客户端。
哨兵的优点:
- 主从可以自动切换,系统更健壮,可用性更高。
- 监控
- 通知
哨兵的缺点:
- 不能解决海量数据存储问题。不支持数据扩容
- 高并发写操作的问题
2、 搭建哨兵集群
这里我们搭建一个三节点形成的Sentinel集群,来监管之前的Redis主从集群
| 节点 | IP | PORT |
|---|---|---|
| s1 | 192.168.150.101 | 27001 |
| s2 | 192.168.150.101 | 27002 |
| s3 | 192.168.150.101 | 27003 |
- 创建三个文件夹,存放哨兵的配置信息
mkdir s1 s2 s3 - 然后我们在s1目录创建一个sentinel.conf文件,添加下面的内容:
port 27001
sentinel announce-ip 192.168.150.101
sentinel monitor mymaster 192.168.150.101 7001 2
sentinel down-after-milliseconds mymaster 5000
sentinel failover-timeout mymaster 60000
dir "/tmp/s1"
解读:
port 27001:是当前sentinel实例的端口sentinel monitor mymaster 192.168.150.101 7001 2:指定主节点信息mymaster:主节点名称,自定义,任意写192.168.150.101 7001:主节点的ip和端口2:选举master时的quorum值
- 然后将s1/sentinel.conf文件拷贝到s2、s3两个目录中(在/tmp目录执行下列命令):
echo s2 s3 | xargs -t -n 1 cp s1/sentinel.conf - 修改s2、s3两个文件夹内的配置文件,将端口分别修改为27002、27003:
sed -i -e 's/27001/27002/g' -e 's/s1/s2/g' s2/sentinel.conf
sed -i -e 's/27001/27003/g' -e 's/s1/s3/g' s3/sentinel.conf
- 启动
# 第1个
redis-sentinel s1/sentinel.conf
# 第2个
redis-sentinel s2/sentinel.conf
# 第3个
redis-sentinel s3/sentinel.conf
3、测试主备切换:
尝试让master节点7001宕机,查看sentinel日志:
可以看到哨兵日志:
默认30秒后,才会更新日志,才会认为下线了:
- 主观下线7001
- 客观下线,以及有2个了。(3各节点设的2个主观认为下线,则下线)
- 哨兵先进行主节点,哨兵27003当成了领导者。因为去做故障恢复一个主节点去做就行了。
进行选举新的主节点。找到领导者。
策略是:谁先发现的宕机,谁就去选择主节点:27003先发现的,那么7003选择的是7002是主节点。 - slaveof-no noe slave …7002 说明将7002选为主节点
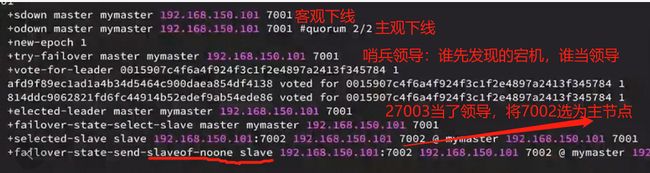
- 进行广播告诉27003说7002是master了,将7001作为从节点。

6. 将7001切换成slave节点

4、 SpringBoot集成Redis 哨兵模式
在Sentinel集群监管下的Redis主从集群,其节点会因为自动故障转移而发生变化,Redis的客户端必须感知这种变化,及时更新连接信息。Spring的RedisTemplate底层利用lettuce实现了节点的感知和自动切换。
添加配置
- 加入依赖:
<dependency>
<groupId>org.springframework.bootgroupId>
<artifactId>spring-boot-starter-data-redisartifactId>
dependency>
- 加入application.yml
spring:
redis:
sentinel:
master: mymaster # 指定master名称
nodes: # 指定redis-sentinel集群信息
- 192.168.150.101:27001
- 192.168.150.101:27002
- 192.168.150.101:27003
- 配置主从读写分离
@Bean
public LettuceClientConfigurationBuilderCustomizer configurationBuilderCustomizer(){
return configBuilder -> configBuilder.readFrom(ReadFrom.REPLICA_PREFERRED);
}
这里的ReadFrom是配置Redis的读取策略,包括下面选择:
- MASTER:从主节点读取
- MASTER_PREFERRED:优先从master节点读取,master不可用才读取replica
- REPLICA:从slave(replica)节点读取
- REPLICA _PREFERRED:优先从slave(replica)节点读取,所有的slave都不可用才读取master
四、分片集群模式
Redis3.0之前的集群模式,用ShardedJedis实现分片是客户端实现分片,客户端自己计算数据的key应该在哪个机器上存储,这个方法的好处是降低了服务器集群的复杂性,客户端自己分片,服务器节点之间是没有联系的,缺点也很明显,就是客户端要实时的知道当前所有节点的信息,因为当增加一个节点时得动态的重新分片啊。
Redis3.0之后的集群模式,用Cluster是用服务端节点实现的数据分片,即客户端随意与集群中的任何节点通信,节点负责计算某个key在哪个机器上,把计算结果反馈给客户端,客户端再去指定的节点存储查询数据,这是一个重定向的过程。
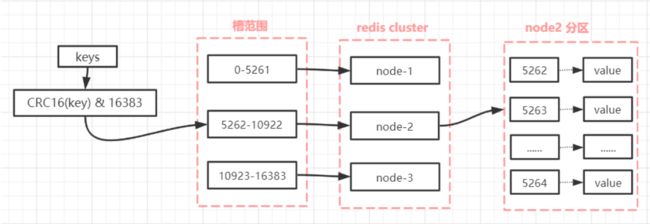
很容易添加或者删除节点,并且无论是添加删除或者修改某一个节点,都不会造成集群不可用的状态。使用哈希槽的好处就在于可以方便的添加 或 移除节点,当添加或移除节点时,只需要移动对应槽和数据移动到对应节点就行。
1、介绍分片集群模式(3.0之后)
- 集群中有多个master,每个master保存不同数据
- 每个master都可以有多个slave节点
- master之间通过ping监测彼此健康状态
- 客户端请求可以访问集群任意节点,最终都会被转发到正确节点


优点:
- redis cluster的性能和高可用性均优于哨兵模式
- 采用多主多从。达到读写高性能
- 存储海量数据
- 主从切换
- 读写分离
缺点:
- 部署繁琐,运维量大,成本高
2、搭建
集群配置:三个master节点、三个slave节点
| IP | PORT | 角色 |
|---|---|---|
| 192.168.150.101 | 7001 | master |
| 192.168.150.101 | 7002 | master |
| 192.168.150.101 | 7003 | master |
| 192.168.150.101 | 8001 | slave |
| 192.168.150.101 | 8002 | slave |
| 192.168.150.101 | 8003 | slave |
- 将每个节点都有自己的redis.conf 配置:举例如下:
port 6379
# 开启集群功能
cluster-enabled yes
# 集群的配置文件名称,不需要我们创建,由redis自己维护
cluster-config-file /tmp/6379/nodes.conf
# 节点心跳失败的超时时间
cluster-node-timeout 5000
# 持久化文件存放目录
dir /tmp/6379
# 绑定地址
bind 0.0.0.0
# 让redis后台运行
daemonize yes
# 注册的实例ip
replica-announce-ip 192.168.150.101
# 保护模式
protected-mode no
# 数据库数量
databases 1
# 日志
logfile /tmp/6379/run.log
- 创建6个新目录,将reids.conf复制到不同目录。
echo 7001 7002 7003 8001 8002 8003 | xargs -t -n 1 cp redis.conf - 修改每个目录下的redis.conf,将其中的6379修改为与所在目录一致:
会将配置文件中的6379 分别改为 7001 7002 7003 8001 8002 8003
# 进入/tmp目录
cd /tmp
# 修改配置文件
printf '%s\n' 7001 7002 7003 8001 8002 8003 | xargs -I{} -t sed -i 's/6379/{}/g' {}/redis.conf
- 一键启动服务:
# 一键启动所有服务
printf '%s\n' 7001 7002 7003 8001 8002 8003 | xargs -I{} -t redis-server {}/redis.conf
通过ps查看状态:
ps -ef | grep redis
如果要关闭所有进程,可以执行命令:
ps -ef | grep redis | awk '{print $2}' | xargs kill
或者(推荐这种方式):
printf '%s\n' 7001 7002 7003 8001 8002 8003 | xargs -I{} -t redis-cli -p {} shutdown
- 创建集群
在Redis5.0之前创建集群比较麻烦,5.0之后集群管理命令都集成到了redis-cli中。
我们使用的是Redis6.2.4版本,集群管理以及集成到了redis-cli中,格式如下:
Redis5.0以后:
redis-cli --cluster create --cluster-replicas 1 192.168.150.101:7001 192.168.150.101:7002 192.168.150.101:7003 192.168.150.101:8001 192.168.150.101:8002 192.168.150.101:8003
命令说明:
redis-cli --cluster或者./redis-trib.rb:代表集群操作命令create:代表是创建集群--replicas 1或者--cluster-replicas 1:指定集群中每个master的副本个数为1,此时节点总数 ÷ (replicas + 1)得到的就是master的数量。因此节点列表中的前n个就是master,其它节点都是slave节点,随机分配到不同master
- 通过命令可以查看集群状态:
redis-cli -p 7001 cluster nodes
- 测试:
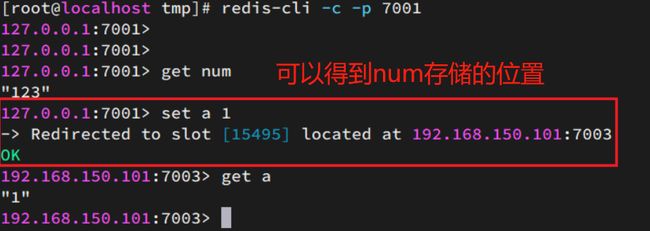
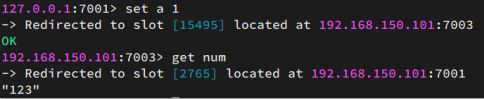
尝试连接7001节点,存储一个数据:
集群操作时,需要给redis-cli加上-c参数才可以:
redis-cli -c -p 7001
# 连接
redis-cli -c -p 7001
# 存储数据
set num 123
# 读取数据
get num
# 再次存储
set a 1
3、散列插槽概念
Redis会把每一个master节点映射到0~16383共16384个插槽(hash slot)上,查看集群信息时就能看到:

数据key不是与节点绑定,而是与插槽绑定。redis会根据key的有效部分计算插槽值,分两种情况:
• key中包含"{}",且“{}”中至少包含1个字符,“{}”中的部分是有效部分
• key中不包含“{}”,整个key都是有效部分
例如:key是num,那么就根据num计算,如果是{itcast}num,则根据itcast计算。计算方式是利用CRC16算法得到一个hash值,然后对16384取余,得到的结果就是slot值。
4、 RedisTemplate访问分片集群
RedisTemplate底层同样基于lettuce实现了分片集群的支持,而使用的步骤与哨兵模式基本一致:
- 引入redis的starter依赖
- 配置分片集群地址
- 配置读写分离
与哨兵模式相比,其中只有分片集群的配置方式略有差异,如下:
spring:
redis:
cluster:
nodes: # 指定分片集群的每一个节点信息
- 192.168.150.101:7001
- 192.168.150.101:7002
- 192.168.150.101:7003
- 192.168.150.101:8001
- 192.168.150.101:8002
- 192.168.150.101:8003