渐进式rehash
Redis之如何解决hash冲突:链式存储、rehash、渐进式rehash
-
- 链式哈希
- rehash
- 渐进式 rehash
我们知道Redis是通过全局hash表来存储key-value键值对的,既然是hash表,那么肯定是会存在hash冲突问题的,而在redis中主要通过链式哈希、渐进式rehash方法来解决这个问题
我们先来了解一下redis中很重要的三个数据结构:
- dict:是Redis中的字典结构,包含两个dictht;
- dictht:表示一个全局Hash表,包含一个或多个dictEntry;
- dictEntry: 表示一个Key-Value节点;
通过下面redis源代码,发现每一个字典中有两个全局hash表(用于rehash),这个我们后面会详细介绍它的作用
/*
* dict 字典
* 大家需要关注的是dictht ht[2]:
* 这里设计存储两个dictht 的指针是用于Redis的rehash,后文中进行详解
*/
typedef struct dict {
dictType *type; /*类型特定函数*/
void *privdata; /*私有数据*/
dictht ht[2]; /*用于存储数据的两个hash表,正常只有一个hash表中有数据,只有在rehash的过程中才会出现两个hash表同时存在数据*/
long rehashidx; /*rehash目前进度,当哈希表进行rehash的时候用到,其他情况下为-1*/
unsigned long iterators; /*迭代器数量*/
} dict;
/*
* 这是我们的哈希表结构。 每个字典都有两个
* 一个哈希表里面有多个哈希表节点(dictEntry),每个节点表示字典的一个键值对
*/
typedef struct dictht {
dictEntry **table; /*哈希表数组指针*/
unsigned long size; /*hashtable 容量 数组大小*/
unsigned long sizemask; /*size -1*/
unsigned long used; /*hashtable中元素个数,正常情况下当used/size=1时将进行扩容操作*/
} dictht;
/*
* 哈希表节点
*/
typedef struct dictEntry {
void *key;
union {
void *val; /*指向Value值的指针,正常是指向一个redisObject*/
uint64_t u64;
int64_t s64;
double d;
} v;
struct dictEntry *next; /*当出现hash冲突时使用链表形式保存hashcode相等但是field 不相等的数据,这里就是指向下一条数据的指针*/
} dictEntry;
下面我开始从链式哈希->rehash->渐进式rehash这个流程来依次解释它们是如何处理hash冲突的,以及一些它们的优缺点
链式哈希
链式hash法也是一种比较常见的处理hash冲突的方法,在很多地方都会利用(例如java中的hashmap)。
链式哈希:同一个哈希桶中的多个元素用一个链表来保存,它们之间依次用指针连接。
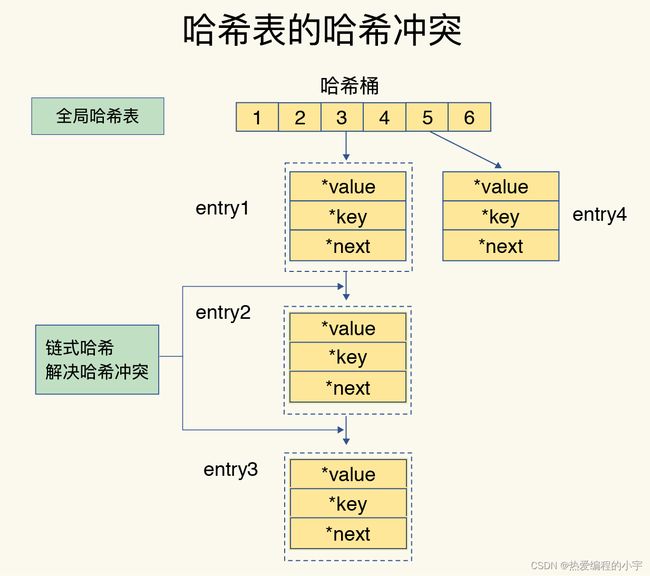
产生的问题:虽然上述解决了hash冲突的问题,但是随着hash冲突可能越来越多,就会导致某些hash冲突链过长,进而导致链上的元素查找耗时长,效率降低。
对于以上这种问题,我们必须要有办法解决。例如在jdk1.8以后的hashmap中,会在同一个桶中的节点数大于8时,将链表来转换为红黑树提升查找效率。
而在redis中也类似,当桶中的节点数超过一定的数量时(已插入的元素数量是桶容量的5倍),就会进行相应的优化。
rehash
为了解决上述链式哈希存在的问题,我们可以尝试使用rehash操作
redis中rehash的核心思想是,增加现有的哈希桶数量,让逐渐增多的 entry 元素能在更多的桶之间分散保存,减少单个桶中的元素数量,从而减少单个桶中的冲突。下面是它的大致流程:
为了使 rehash 操作更高效,Redis 默认使用了两个全局哈希表:哈希表 1 和哈希表 2。一开始,当你刚插入数据时,默认使用哈希表 1,此时的哈希表 2 并没有被分配空间。随着数据逐步增多,Redis 开始执行 rehash,这个过程分为三步:
- 给哈希表 2 分配更大的空间,一般是当前哈希表 1 大小的两倍;
- 把哈希表 1 中的数据重新映射并拷贝到哈希表 2 中(在hash表2下进行重新计算hash值);
- 释放哈希表 1 的空间。
感觉这个和一些JVM的垃圾收集算法中的新生代的survivor0、survivor1的工作流程有一点类似
到此,我们就可以从哈希表 1 切换到哈希表 2,用增大的哈希表 2 保存更多数据,而原来的哈希表 1 留作下一次 rehash 扩容备用。下面是源代码的实现(只截取了重要的部分)
/**
* 如果所有桶中的节点已经搬迁完了,释放ht[0]空间,并将 d->ht[1] 赋值给ht[0]
* 重置ht[1]空间
* 将hash索引 d->rehashidx设置为-1
*/
if (d->ht[0].used == 0) {
zfree(d->ht[0].table);
d->ht[0] = d->ht[1];
_dictReset(&d->ht[1]);
d->rehashidx = -1;
return 0;
}
产生的问题:上述过程中的第二步,可能会涉及大量的数据拷贝,如果一次性把哈希表1的数据拷贝到哈希表2,那么会造成Redis线程阻塞。也就无法服务其它请求,redis也就无法访问数据了。
渐进式 rehash
渐进式,顾名思义,就是不一次性将所有的数据进行转移,而是一步一步的进行转移,直到最后全部完成。避免了一次性大批量的在两个全局hash表之间拷贝数据造成线程阻塞
渐进式 rehash:在上述第二步拷贝数据时,Redis 仍然正常处理客户端请求,每处理一个请求时,从哈希表 1 中的第一个索引位置开始,顺带着将这个索引位置上的所有 entries 拷贝到哈希表 2 中;等处理下一个请求时,再顺带拷贝哈希表 1 中的下一个索引位置的 entries。
渐进式rehash执行时,除了根据键值对的操作来进行数据迁移,Redis本身还会有一个定时任务在执行rehash,如果没有键值对操作时,这个定时任务会周期性地(例如每100ms一次)搬移一些数据到新的哈希表中,这样可以缩短整个rehash的过程。
综上所述:两种rehash的时机:
- 每次redis处理客户端发送的请求时:一次只搬迁1个桶
- redis本身的定时任务:一次执行1毫秒,最少搬迁100个桶
我们可以想想,因为有了定时任务执行rehash,就不会存在rehash完不成的情况。
这两种触发方式的具体实现可以看看这篇源代码分析:redis源码阅读-rehash
如下图所示:通过这种方式就把一次性大量拷贝的开销,分摊到多次处理请求中:
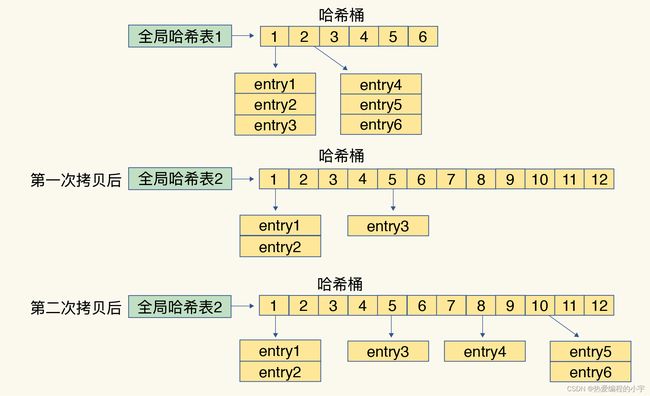
注意:这里仅仅是说了扩容情况下会使用渐进式rehash,其实在缩容时也会用到rehash。(在周期的任务中,会触发缩容判断,如果已用小于1/10,则进行缩容)
思考:一个桶本来已经rehash了再有新增的entry该怎么办?
在进行渐进式 rehash 的过程中, 字典会同时使用 ht[0] 和 ht[1] 两个哈希表, 所以在渐进式 rehash 进行期间, 字典的删除(delete)、查找(find)、更新(update)等操作会在两个哈希表上进行: 比如说, 要在字典里面查找一个键的话, 程序会先在 ht[0] 里面进行查找, 如果没找到的话, 就会继续到 ht[1] 里面进行查找, 诸如此类。 另外, 在渐进式 rehash 执行期间, 新添加到字典的键值对一律会被保存到 ht[1] 里面, 而 ht[0] 则不再进行任何添加操作: 这一措施保证了 ht[0] 包含的键值对数量会只减不增, 并随着 rehash 操作的执行而最终变成空表。
下面是源代码的实现(只截取了重要的一行): 可以很明显的发现如果当前是正在rehash,那么就会选择全局hash表[1]进行操作。那么再有新增的entry都会被放在ht[1]这个hash表中
dictEntry *dictAddRaw(dict *d, void *key, dictEntry **existing){
...
...
//正在rehash的时候,选择哪个槽
ht = dictIsRehashing(d) ? &d->ht[1] : &d->ht[0];
...
...
}
什么时机触发 Rehash 操作?
- 缩容: Redis 定时任务 serverCron 会在每个周期内检查 bucket 的使用情况。当存放 key 的数量和总 bucket 数的比例小于 HASHTABLE_MIN_FILL(10%),触发缩容 Rehash 操作。
- 扩容:在每次调用 dictAddRaw 新增数据时,会检查 bucket 的使用比例。扩容的条件是以下之一:
dict_can_resize = 1 (该参数会在有 COW 操作的子进程运行时更新为 0,防止在子进程操作过程中触发 Rehash,导致内核进行大量的 Page 复制操作)
当前存放的 key 的数量与 bucket 数量的比例超过了 dict_force_resize_ratio(5)
什么时机实际执行 Rehash 函数?
- 定时任务: Redis 定时任务 serverCron 会在每个周期内执行 1ms 渐进式Rehash 操作。
- 附着于其他操作:在 Redis 执行 客户端请求dictAddRaw, dictGenericDelete, dictFind, dictGetSomeKeys 和 dictGetRandomKey 等操作前会执行 Rehash 操作。
参考资料:
极客时间——Redis 核心技术与实战
redis源码阅读-rehash
Redis 源码解读之 Rehash 的调用时机