C/C++内存对齐
文章目录
- 计算机内存的分配
- CPU读取内存
-
- 另一种解释
- 如何分辨存取的是不是内存对齐?
- vs编程理解什么是内存对齐?
- 为什么要进行内存对齐?
- 为什么经过内存对齐后,CPU访问内存的速度大大提升?
- 不同的编译器的对齐方式不同
- 参考链接
计算机内存的分配
这个我现在还没有搞明白,因为有些算法库里面都喜欢用自己定义动态内存分配函数,如fftw_malloc 等,为什么要自己做动态内存分配,而不用C/C++自带的内存分配malloc/calloc/new等呢,有些说是因为“由于不同的编译器内存分配策略
的不同,可能使分配的数组并没有内存对齐,而内存没有对齐,对算法的计算速度影响是显著的”,可是明明malloc/calloc/new分配的动态数组内存是连续的呀,难道连续不等于对齐?是的,内存连续不等于内存对齐。内存对齐可以提高CPU对内存的存取速度,但是连续只是说明一个(数组)结构的所有内容是连续存放的,但不一定是和内存的“自然边界”对齐。下面会阐述这些原因。
CPU读取内存
推荐知乎上 张彦飞 的专栏。
https://zhuanlan.zhihu.com/p/86513504
内存是由chip构成。每个chip内部,是由8个bank组成的。其构造如下图:内存颗粒物理结构

而每一个bank是一个二维平面上的矩阵。(注意,二维矩阵中的一个元素一般存储着8个bit,也就是说包含了8个小电容)。

那么对于我们在应用程序中内存中地址连续的8个字节,例如0x0000-0x0007,是从位于bank上的呢?直观感觉,应该是在第一个bank上吗? 其实不是的,程序员视角看起来连续的地址0x0000-0x0007,实际上位8个bank中的,每一个bank只保存了一个字节。在物理上,他们并不连续。
每当CPU向内存请求数据的时候,内存芯片总是8个bank并行一起工作。每个bank在定位到行地址后,把对应的行copy到row buffer。 再根据列地址把对应的元素中的数据取出来,8个bank把数据拼接一下,一个64位宽的数据就可以返回给CPU了。如下图:

你可能想知道这是为什么,原因是电路工作效率。内存中的8个bank是可以并行工作的。 如果你想读取址0x0000-0x0007,每个bank工作一次,拼起来就是你要的数据,IO效率会比较高。但要存在一个bank里,那这个bank只能自己干活。只能串行进行读取,需要读8次,这样速度会慢很多。
内存在进行IO的时候,一次操作取的就是64个bit。
所以,内存对齐最最底层的原因是内存的IO是以64bit为单位进行的。 对于64位数据宽度的内存,假如cpu也是64位的cpu(现在的计算机基本都是这样的),每次内存IO获取数据都是从同行同列的8个chip中各自读取一个字节拼起来的。从内存的0地址开始,0-63bit的数据可以一次IO读取出来,64-127bit的数据也可以一次读取出来。CPU和内存IO的硬件限制导致没办法一次跨在两个数据宽度中间进行IO。
假如对于一个c的程序员,如果把一个double(64位)地址写到的0x0001开始,而不是0x0000开始,那么数据并没有存在同一行列地址上。因此cpu必须得让内存工作两次才能取到完整的数据。CPU先用行地址取一行,用列地址再砍断砍出来需要的部分,再用CPU取另一行,再用列地址砍出来需要的,最后将两次取出来的合并,效率自然就很低。
扩展1:如果不强制对地址进行操作,仅仅只是简单用c定义一个结构体,编译和链接器会自动替开发者对齐内存的。尽量帮你保证一个变量不跨列寻址。
扩展2:其实在内存硬件层上,还有操作系统层。操作系统还管理了CPU的一级、二级、三级缓存。实际中不一定每次IO都从内存出,如果你的数据局部性足够好,那么很有可能只需要少量的内存IO,大部分都是更为高效的高速缓存IO。但是高速缓存和内存一样,也是要考虑对齐的。
另一种解释
下面的链接关于每次取8个字节的位置和上面张彦飞的说法不同,我也不知道谁的对。。。。兼听则明吧。。。。。???
浅谈CPU内存访问要求对齐的原因
首先简单说一下何为内存对齐。
例如,当cpu需要取4个连续的字节时,若内存起始位置的地址可以被4整除,那么我们称其对齐访问。
反之,则为未对齐访问。比如从地址0xf1取4字节就是非对齐(地址)访问。
简单的看来,对于一个数据总线宽度为32位的cpu,它一次拥有取出四字节数据的能力,理论上cpu应该是可以从任意的内存地址取四个连续字节的,而且是否对齐硬件的设计是相同的(如果内存和CPU都是字节组织的话,那么内存应当可以返回任意地址开始连续的四字节,CPU处理起来也没有任何差异)。
然而,很多cpu并不支持非对齐的内存访问,甚至在访问的时候会发生例外(例如arm架构的某些CPU)!而某些复杂指令集的cpu(比如x86架构),可以完成非对齐的内存访问,然而CPU也不是一次性读出四个字节,而是采取多次读取对齐的内存,然后进行数据拼接,从而实现非对齐数据访问的。如下图:
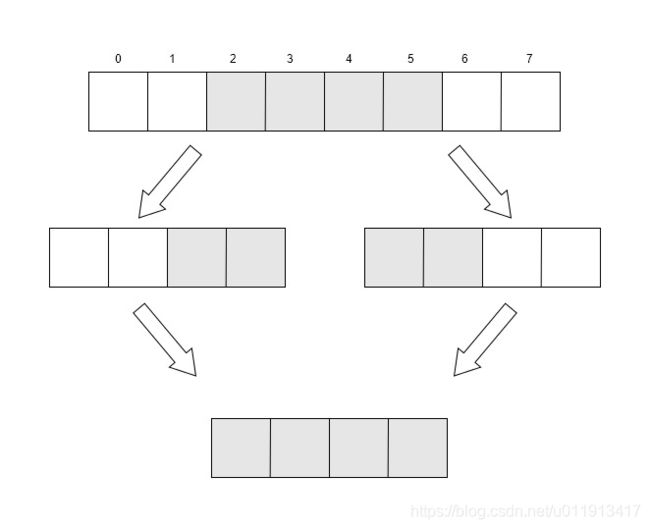
如果我们的数据存于内存的2-5中,在读取时实际上是先读取0-3,再读取4-7字节,再分别将2-3字节和4-5字节合并,最后得到所需的四字节数据。
那么为什么CPU不直接读取2-5,而是要么不提供支持,要么甚至不惜花大力气执行多次访问再拼接访问非对齐的内存呢(如此访问一则增加访问时间,二则增加电路的复杂性)?这背后一定有它的原因!
经过一番互联网搜索,但是在国内只能找到为什么写程序的时候要对齐的解释(因为CPU要么不支持,要么访问效率下降),然后是如何实现对齐。没有一篇文章从硬件原理上去分析为何访问非对齐内存如此麻烦。
最后我在神奇的StackOverflow网站上找到了相关的问题,以及合理的解答(看来并不是只有我一个人有类似的疑问)。
实际上,访问非对齐内存并没有我们想象的那么“简单”,例如,在一个常见的pc上,内存实际上是有多个内存芯片共同组成的(也就是内存条上那些黑色的内存颗粒)
为了提高访存的带宽,通常的做法是将地址分开,放到不同的芯片上,比如,第0-7bit在芯片0上储存,8-15bit在芯片2上组成,以此类推,如下图:
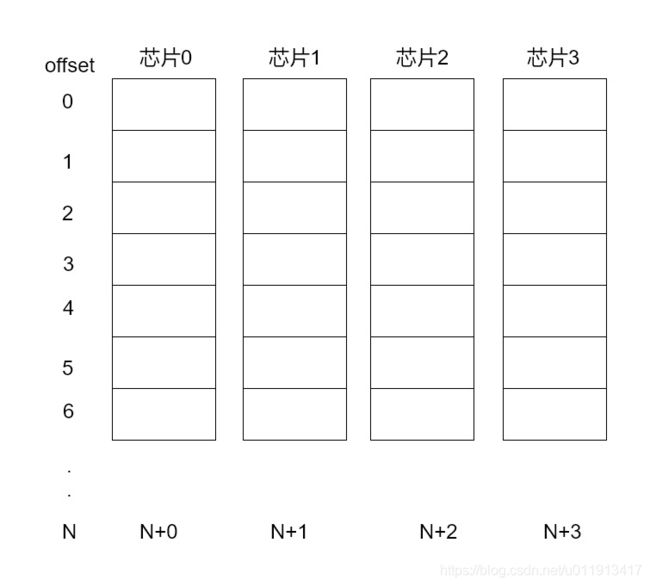
这意味内存实际上并不是完全以byte形式组织的,而是以偏移量(offset)来给出具体地址的。
这样当我们采用对齐的地址访问时,比如从0x00开始访问四字节,显然四个字节储存于4个芯片,而且他们都有同样的偏移量(offset),这时我们就能一次获得所需的数据。
但是当从0x01开始读取4字节呢?此时前三个字节也是按顺序分别储存在1-3芯片中的,而且偏移量都是0,但是第四个字节却储存在偏移量为1的芯片0中。
在访问内存时,CPU需要给出偏移量offset,而发送偏移量的总线宽度大约是40位(64bit环境下),通常这样的总线只有一个。
这意味着在一次内存访问周期内我们只能读取一个结果。
当然,要想一次读取两个offset的内容也不是不能实现,你可以增加用于发送地址的bus数量。对于一个64位的cpu,如果你希望在一个访问周期内读取未对齐的内存,你需要增加到8根总线。这意味着需要增加接近300个io。而通常cpu的管脚数量在700-2000之间,在这基础之上增加300将会是一个很大的改动。换句话说,就是会大大增加硬件的复杂程度。
同时,内存访问信号的频率是非常高的,增加的总线也会造成额外的噪声干扰。
当然,还有一种方法。由于非对齐访问最多也就访问两个不同的offset,而且这两个offset总是连续,我们可以再给内存内部加一根额外的线,这样就可以同时返回offset和offset+1两个偏移量上的数据了。
但是,这样意味着芯片内多了一些额外的加法器(用于给offset加一,得到下一个偏移量),所有的读操作都会在读取前增加一个计算操作。
这一步会降低内存的时钟。于是乎,我们可能为了千分之一概率出现的非对齐访问,增加了99.9%的对齐访问的访问延时。显然这并不是一个明智的选择。
因此,CPU不支持,或者通过两次读取来实现非对齐访问也就有理有据了。
当然,访问非对齐的数据还存在一个问题:cache
通常来说,cache是和offset相关联的,不同的offset被不同的cache line缓存,因此,访问非对齐的数据也意味着多次的cache读取,同样会降低效率。
综上所述,这些也基本上是访问非对齐内存需要多次读取的原因了。
如何分辨存取的是不是内存对齐?
好的,现在存在三个疑问:
1。cpu是如何分辨当前要去访问的数据是不是对齐存储的?
2。在一台电脑中(或者一套程序中),对齐基数是确定不变的吗?
3。结构体对齐和其他数据结构内存对齐的区别是什么?
问题1:据说是系统给每个存储的起始地址都是对齐基数的整数倍,已经被我验证否决掉;
问题2:可以变,和运行操作系统有关,和运行软件有关;
问题3:这个我也不知道啊,所有可以找到的可参考文章都以结构体或者联合体举例说明,难道(动态)数组等其他结构就不对齐了?如果不用对齐,那么很多开源库自己写动态数据的开辟和释放干嘛呢?
看了很多,越看越多,这个萝卜有点儿大,就暂时把这个问题交给时间吧,请时间帮我解答。。。
vs编程理解什么是内存对齐?
参考的内容都是以结构体为例来说明的。
#include
结论:
- 指针大小由平台数位确定;
- 之所以结构体成员出现顺序不同占用内存大小就不同的原因是系统分配内存的时候内存对齐导致的。
#pragma pack(n) 表示设置为n字节对齐。在默认情况下,32位平台就是4,64位平台就是8。
内存对齐的规则:
- 对于结构的各个成员,第一个成员位于偏移为0的位置,以后每个数据成员的偏移量必须是min(#pragma pack(n)指定的数,结构(或联合)最大数据成员长度) 的倍数。
- 在数据成员完成各自对齐之后,结构(或联合)本身也要进行对齐,对齐将按照#pragma pack指定的数值和结构(或联合)最大数据成员长度中,比较小的那个进行。
为什么要进行内存对齐?
1 平台原因
不是所有的硬件平台都能访问任意内存地址上的任意数据,某些硬件平台只能在某些地址处取某些特定类型的数据,否则抛出硬件异常。为了同一个程序可以在多平台运行,需要内存对齐。
2 性能原因
数据结构(尤其是栈)应该尽可能地在自然边界上对齐。原因在于,为了访问未对齐的内存,处理器需要作两次内存访问;而对齐的内存访问仅需要一次访问。
为什么经过内存对齐后,CPU访问内存的速度大大提升?
CPU读取内存不是一次读取单个字节,CPU把内存当作一块一块的,块的大小可以是2,4,8,16个字节。因此CPU在读取内存时是一块一块进行读取的。
假设CPU把内存划分为4字节大小的块,要读取一个4字节大小的int型数据,分二种情况:
1 该int数据从地址0开始
此时,直接将地址0,1,2,3处的四个字节数据读取到即可
2 该int数据从地址1开始
①CPU读取0,1,2,3处的四个字节数据
②CPU读取4,5,6,7处的四个字节数据
③合并地址1,2,3,4处的四个字节数据为一个int数据
看到该int数据如果没有从地址1开始的话会大大降低CPU的性能。
不同的编译器的对齐方式不同
用如下代码分别在VC,和DEV C++编译器上执行。
#includeVC执行结果:
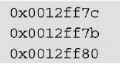
看到a占用 ff7c开始的4字节,b占用ff7b一个字节,c占用ff80开始的4字节
DEV C++执行结果:

a占用ff7c开始的4字节,c占用ff74开始的4字节,ff78开始的到ff7b的4字节被b占用了
可以看到,“不同的编译器对齐方式是不同的”。我认为原作者这句话是错误的!这只能说明定义顺序不是内存分配顺序。好吧,这有牵扯到另一个问题。
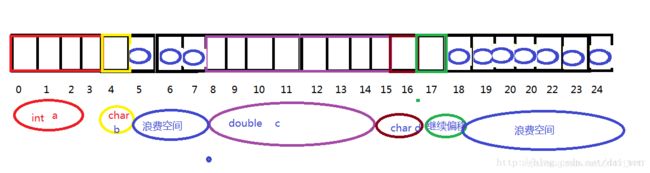
struct A
{
int a;
char b;
double c;
char d;
};
数据类型大小:
在windows系统32位平台上:
int占4个字节
char占1个字节
float占4个字节
double占8个字节
方法:
- a、从零偏移处开始,按字节大小计算,判断此偏移地址是否为该成员变量和对齐参数两者之间的最小值,即min(对齐参数,sizeof()成员);
- b、若是,则从此处开始占用内存,大小为该类型所占字节数值,若不是,则内存向后偏移到最小值整数倍处,再开始占用空间。
- c、按a、b、两步骤算出结构体实际所占内存时,为了方便后面类型的存储,再向后偏移一位,然后判断该地址是否是默认对齐数与该结构体中最大类型所占字节数的最小值 ,即:min(默认对齐参数,类型最大字节数)的整数倍,若是,则当前偏移地址的字节数便是结构体大小,若不是,继续向后偏移,直至为最小值整数倍为止。
参考链接
本篇blog主要是参考以下网页链接,感谢各位作者们的工作。
https://zhuanlan.zhihu.com/p/30007037
https://blog.csdn.net/weixin_40853073/article/details/81451792
https://wenku.baidu.com/view/29b09f0058fafab068dc0219.html
https://www.cnblogs.com/fengxing999/p/10919141.html