【MySQL】-【数据库的设计规范】
文章目录
- 为什么需要数据库设计
- 范式
-
- 范式简介
- 范式都包括哪些
- 键和相关属性的概念
- 第一范式(1st NF)
- 第二范式(2nd NF)
- 第三范式(3rd NF)
- 反范式化
-
- 概述
- 应用举例
- 反范式化的新问题
- 反范式的适用场景
- BCNF(巴斯范式)
- 案例
-
- 案例一
- 案例二
- 第四范式
- 案例
-
- 案例一
- 案例二
- 第五范式、域键范式
- 范式的实战案例
为什么需要数据库设计


范式
范式简介
在关系型数据库中,关于数据表设计的基本原则、规则就称为范式。可以理解为,一张数据表的设计结构需要满足的某种设计标准的级别 。要想设计一个结构合理的关系型数据库,必须满足一定的范式。
范式都包括哪些
目前关系型数据库有六种常见范式,按照范式级别,从低到高分别是:第一范式(1NF)、第二范式(2NF)、第三范式(3NF)、巴斯-科德范式(BCNF)、第四范式(4NF)和第五范式(5NF,又称完美范式)。


键和相关属性的概念

超键:能唯一标识一行数据的属性集,其实只要是主键+任意字段就可以构成一个超键
候选键:真正的能唯一标识一行数据的字段,比如人的身份证号
主键只能有一个,候选键可以有多个
候选键的属性就称为主属性
举例:这里有两个表:
- 球员表(player):球员编号 | 姓名 | 身份证号 | 年龄 | 球队编号
- 球队表(team):球队编号 | 主教练 | 球队所在地
超键:对于球员表来说,超键就是包括球员编号或者身份证号的任意组合,比如(球员编号) (球员编号,姓名)(身份证号,年龄)等。
候选键:就是最小的超键,对于球员表来说,候选键就是(球员编号)或者(身份证号)。
主键:我们自己选定,也就是从候选键中选择一个,比如(球员编号)。
外键:球员表中的球队编号。
主属性、非主属性:在球员表中,主属性是(球员编号)(身份证号),其他的属性(姓名)(年龄)(球队编号)都是非主属性。
第一范式(1st NF)
一、第一范式:主要是确保数据表中每个字段的值必须具有原子性,也就是说数据库表中每个字段的值为不可再次拆分的最小数据单元。
二、我们在设计某个字段的时候,对于字段X来说,不能把字段X拆分成字段X-1和字段X-2。事实上,任何的DBMS都会满足第一范式的要求,不会将字段进行拆分。




第二范式(2nd NF)
一、第二范式要求在满足第一范式的基础上,还要满足==数据表里的每一条数据记录都是可唯一标识的。而且所有非主键字段,都必须完全依赖主键,不能只依赖主键的一部分。==如果知道主键的所有属性的值,就可以检索到任何元组(行)的任何属性的任何值。(要求中的主键,其实可以拓展替换为候选键)
非主键字段完全依赖主键:假如表中字段1、字段2组成了一个唯一主键,其余字段(非主键字段)根据这两个字段的值就能确定唯一值,如果某个非主键字段根据字段1(或字段2)就能确定自己的值,那么这就叫非主键字段依赖主键的一部分,这种情况建议给字段1(或字段2)和该非主键字段建立一张独立的表,然后将该表与原来的表进行关联



在淘宝购物提交订单时,一个订单中可能有多个商品,如果把所有信息都放在同一张表中,并设置订单号、商品编号为唯一主键,那么就违反了第二范式,因为订单创建时间、公司名、顾客姓名等信息可以根据订单号确定,商品数量可以根据商品编号确定,因此我们可以设置成两张表
![]()
第三范式(3rd NF)
一、第三范式是在第二范式的基础上,确保数据表中的每一个非主键字段都和主键字段直接相关,也就是说,要求数据表中的所有非主键字段不能依赖于其他非主键字段。(即,不能存在非主属性A依赖于非主属性B,非主属性B依赖于主键C的情况,即存在“A—B—C”的决定关系)通俗的讲,该规则的意思是所有非主键属性直接不能有依赖关系,必须相互独立
二、这里的主键可以拓展为候选键

列出部门编号后不能再将部门名称、部门简介等与部门相关的信息再加入员工信息表中了,因为部门名称、部门简介等与部门相关的信息都依赖部门编号这个非主键字段,违反了第三范式




每个非主键属性依赖于主键,依赖于整个主键(不能部分依赖),并且除了主键别无他物(与其他非主键相互独立)
反范式化
概述

应用举例




反范式优化实验对比:
- 创建数据库和表:

- 添加数据




- 满足第三范式,查询

- 查询结果

- 进行反范式化的设计

- 反范式化查询

- 反范式化查询结果

反范式化的新问题
- 存储空间变大了。
- 一个表中字段做了修改,另一个表中冗余的字段也需要做同步修改,否则数据不一致
- 若采用存储过程来支持数据的更新、删除等额外操作,如果更新频繁,会非常消耗系统资源
- 在数据量小的情况下,反范式不能体现性能的优势,可能还会让数据库的设计更加 复杂
反范式的适用场景
当冗余信息有价值或者能大幅度提高查询效率的时候,我们才会采取反范式的优化。
一、增加冗余字段的建议

二、历史快照、历史数据的需要
在现实生活中,我们经常需要一些冗余信息,比如订单中的收货人信息,包括姓名、电话和地址等。每次发生的 订单收货信息 都属于 历史快照 ,需要进行保存,但用户可以随时修改自己的信息,这时保存这 些冗余信息是非常有必要的。
反范式优化也常用在 数据仓库 的设计中,因为数据仓库通常 存储历史数据 ,对增删改的实时性要求不 强,对历史数据的分析需求强。这时适当允许数据的冗余度,更方便进行数据分析。

先遵循三范式,再考虑反范式化
BCNF(巴斯范式)

案例
案例一
一、分析下表的范式情况:
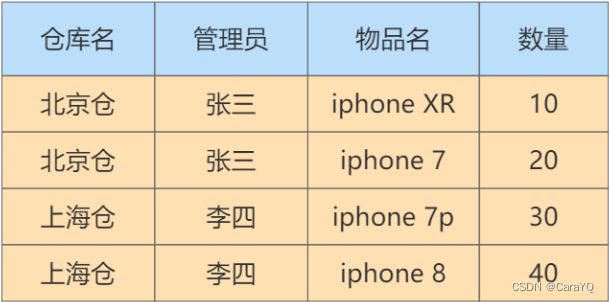
在这个表中,一个仓库只有一个管理员,同时一个管理员也只管理一个仓库。我们先来梳理下这些属性之间的依赖关系。
- 仓库名决定了管理员,管理员也决定了仓库名,同时(仓库名,物品名)的属性集合可以决定数量这个属性。这样,我们就可以找到数据表的候选键。
- 候选键 :是(管理员,物品名)和(仓库名,物品名),然后我们从候选键中选择一个作为 主键 ,比如(仓库名,物品名)。
- 主属性 :包含在任一候选键中的属性,也就是仓库名,管理员和物品名。
- 非主属性 :数量这个属性。
二、是否符合三范式(如何判断一张表的范式呢?我们需要根据范式的等级,从低到高来进行判断。):首先,数据表每个属性都是原子性的,符合 1NF 的要求;其次,数据表中非主属性”数量“都与候选键全部依赖,(仓库名,物品名)决定数量,(管理员,物品名)决定数量。因此,数据表符合 2NF 的要求;最后,数据表中的非主属性,不传递依赖于候选键。因此符合 3NF 的要求
三、存在的问题:既然数据表已经符合了 3NF 的要求,是不是就不存在问题了呢?我们来看下面的情况:
- 增加一个仓库,但是还没有存放任何物品。根据数据表实体完整性的要求,主键不能有空值,因
此会出现 插入异常 ; - 如果仓库更换了管理员,我们就可能会 修改数据表中的多条记录 ;
- 如果仓库里的商品都卖空了,那么此时仓库名称和相应的管理员名称也会随之被删除。
你能看到,即便数据表符合 3NF 的要求,同样可能存在插入,更新和删除数据的异常情况。
四、问题解决
首先我们需要确认造成异常的原因:主属性仓库名对于候选键(管理员,物品名)是部分依赖的关系,这样就有可能导致上面的异常情况。因此引入BCNF,它在 3NF 的基础上消除了主属性对候选键的部分依赖或者传递依赖关系。
如果在关系R中,U为主键,A属性是主键的一个属性,若存在A->Y,Y为主属性,则该关系不属于BCNF。
根据 BCNF 的要求,我们需要把仓库管理关系warehouse_keeper表拆分成下面这样:
仓库表 :(仓库名,管理员)
库存表 :(仓库名,物品名,数量)
这样就不存在主属性对于候选键的部分依赖或传递依赖,上面数据表的设计就符合 BCNF。
案例二
有一个 学生导师表 ,其中包含字段:学生ID,专业,导师,专业GPA,这其中学生ID和专业是联合主键。

这个表的设计满足三范式,但是这里存在另一个依赖关系,“专业”依赖于“导师”,也就是说每个导师只做一个专业方面的导师,只要知道了是哪个导师,我们自然就知道是哪个专业的了。所以这个表的部分主键Major依赖于非主键属性Advisor,那么我们可以进行以下的调整,拆分成2个表:
- 学生导师表:

- 导师表:

第四范式

多值依赖:一个属性可以决定N个属性的值
单值依赖:像函数,一个变量决定另一个变量的值
第四范式在满足第三范式的基础上,去除了非平凡的多值依赖、函数依赖,只保留了平凡的多值依赖
案例
案例一
职工表(职工编号,职工孩子姓名,职工选修课程)。在这个表中,同一个职工可能会有多个职工孩子姓名。同样,同一个职工也可能会有多个职工选修课程,即这里存在着多值事实(存在多个一对多的情况,即非平凡的多值依赖),不符合第四范式。
如果要符合第四范式,只需要将上表分为两个表,使它们只有一个多值事实,例如: 职工表一 (职工编号,职工孩子姓名), 职工表二 (职工编号,职工选修课程),两个表都只有一个多值事实,所以符合第四范式。
案例二
建立课程、教师、教材的模型。我们规定,每门课程有对应的一组教师,每门课程也有对应的一组教材,一门课程使用的教材和教师没有关系。我们建立的关系表如下:课程ID,教师ID,教材ID;这三列作为联合主键。(为了表述方便,我们用Name代替ID,这样更容易看懂)

这个表除了主键,就没有其他字段了,所以肯定满足BC范式,但是却存在 多值依赖 导致的异常。假如我们下学期想采用一本新的英版高数教材,但是还没确定具体哪个老师来教,那么我们就无法在这个表中维护Course高数和Book英版高数教材的的关系。
解决办法是我们把这个多值依赖的表拆解成2个表,分别建立关系。这是我们拆分后的表:

以及

第五范式、域键范式
一、除了第四范式外,我们还有更高级的第五范式(又称完美范式)和域键范式(DKNF)。
二、在满足第四范式(4NF)的基础上,消除不是由候选键所蕴含的连接依赖。如果关系模式R中的每一个连接依赖均由R的候选键所隐含,则称此关系模式符合第五范式。
三、函数依赖是多值依赖的一种特殊的情况,而多值依赖实际上是连接依赖的一种特殊情况。但连接依赖不像函数依赖和多值依赖可以由 语义直接导出 ,而是在 关系连接运算 时才反映出来。存在连接依赖的关系模式仍可能遇到数据冗余及插入、修改、删除异常等问题。
四、第五范式处理的是 无损连接问题 ,这个范式基本 没有实际意义 ,因为无损连接很少出现,而且难以察觉。而域键范式试图定义一个 终极范式 ,该范式考虑所有的依赖和约束类型,但是实用价值也是最小的,只存在理论研究中。