pandas---分箱(离散化处理)、绘图、交叉表和透视表
1. 分箱
分箱操作就是将连续型数据离散化。分箱操作分为等距分箱和等频分箱.
1.1 等宽分箱
pandas.cut(x, bins, right=True, labels=None, retbins=False, precision=3, include_lowest=False,
duplicates='raise', ordered=True)
x:要分箱的一维数组或者 Series。
bins:箱子的边界指示。有三种输入方式:
整数数量的箱子数;
箱子的边缘值数组;
箱子数量与箱子间隔。例如bins=a-q表示 17 个箱子(十六进制字母中 a-q )。
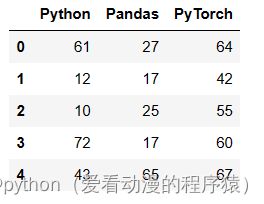
data = np.random.randint(0, 100, size=(5, 3))
df = pd.DataFrame(data=data, columns=['Python', 'Pandas', 'PyTorch'])
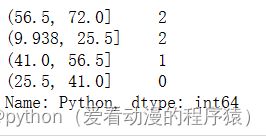
s = pd.cut(df.Python, bins=4)
s.value_counts()
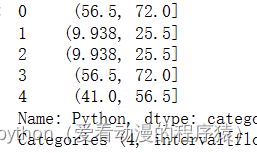
pd.cut(
df.Python, # 分箱数据
bins=[0, 30, 60, 80, 100], # 分箱断点
right=False, # 左闭右开,默认是左开右闭
labels=['D', 'C', 'B', 'A'] # 分箱后分类的标签
)

1.2 等频分箱
pandas.qcut(x, q, labels=None, retbins=False, precision=3, duplicates='raise')
qcut函数根据数据的分位数将数据分成了几个等分(指定 q 的值),并将每个数据点对应到相应的
分组(区间)中,最后用labels中指定的标签表示每个数据点所在的分组。
pd.qcut(
df.Python, # 分箱数据
q=4, # 4等份
labels=['D', 'C', 'B', 'A'] # 分箱后分类的标签
)
2. 绘图
Series和DataFrame都有一个用于生成各类图表的plot方法。
Pandas的绘图是基于Matplotlib, 可以快速实现基本图形的绘制,复杂的图形还是需要用
Matplotlib。
2.1 折线图
s = pd.Series([100, 250, 300, 200, 150, 100])
s.plot()
# sin曲线
x = np.arange(0, 2*np.pi, 0.1)
y = np.sin(x)
s = pd.Series(data=y, index=x)
s.plot() 
DataFrame图表:图例的位置可能会随着数据的不同而不同。
data = np.random.randint(50, 100, size=(5, 6))
index = ['1st', '2nd', '3th', '4th', '5th']
columns = ['Jeff', 'Jack', 'Rose', 'Lucy', 'Lily', 'Bob']
df = pd.DataFrame(data=data, index=index, columns=columns)
# 每一列 一根线
df.plot()
# 每一行 一根线
# df.T.plot() 

2.2 条形图和柱状图
series画图:
s = pd.Series(data=[100, 200, 300, 200])
s.index = ['Lily', 'Lucy', 'Jack', 'Rose']
# s.plot(kind='bar') # 柱状图
s.plot(kind='barh') # 水平:条形图
# kind : str
# The kind of plot to produce:
# - 'line' : line plot (default)
# - 'bar' : vertical bar plot
# - 'barh' : horizontal bar plot
# - 'hist' : histogram
# - 'box' : boxplot
# - 'kde' : Kernel Density Estimation plot
# - 'density' : same as 'kde'
# - 'area' : area plot
# - 'pie' : pie plot
# - 'scatter' : scatter plot
# - 'hexbin' : hexbin plot.
dataframe柱状图:
data = np.random.randint(0, 100, size=(4, 3))
index = list("ABCD")
columns = ['Python', 'C', 'Java']
df = pd.DataFrame(data=data, index=index, columns=columns)
# df.plot(kind='bar')
df.plot(kind='barh')
# df.plot(kind='bar') # 第一种方式
# df.plot.bar() # 第二种方式
# df.plot.bar(stacked=True) # 堆叠
2.3 直方图
rondom生成随机数百分比直方图,调用hist方法:
柱高表示数据的频数,柱宽表示各组数据的组距;
参数bins可以设置直方图方柱的个数上限,越大柱宽越小,数据分组越细致;
设置density参数为True,可以把频数转换为概率。
s = pd.Series([1, 2, 2, 2, 2, 2, 2, 3, 3, 4, 5, 5, 5, 6, 6])
# 直方图
# bins=4 表式4个组
# density: 频数转换为概率
s.plot(kind='hist', bins=5, density=True)kde图:核密度估计,用于弥补直方图由于参数bins设置的不合理导致的精度缺失问题 。
# kde图:核密度估计
s.plot(kind='hist', bins=5, density=True)
s.plot(kind='kde') # 可以结合上面的直方图一起显示,效果更好 
2.4 饼图
df = pd.DataFrame(data=np.random.rand(4, 2),
index=list('ABCD'),
columns=['Python', 'Java']
)
# 画饼图
# df['Python'].plot(kind='pie', autopct='%.1f%%')
# subplots: 子图
df.plot.pie(subplots=True, figsize=(8, 8), autopct='%.1f%%')
2.5 散点图
散点图是观察两个一维数据数列之间的关系的有效方法,DataFrame对象可用。
data = np.random.normal(size=(1000, 2))
df = pd.DataFrame(data=data, columns=list('AB'))
df.head()
# df.plot(kind='scatter', x='A', y='B')
# x='A' : 使用A列作为X轴
# y='B' : 使用B列作为Y轴
df.plot.scatter(x='A', y='B')
2.6 面积图
df = pd.DataFrame(data=np.random.rand(10, 4), columns=list('ABCD'))
# df.plot(kind='area')
df.plot.area(stacked=True) # 堆叠
2.7 箱型图
df = pd.DataFrame(data=np.random.rand(10, 4), columns=list('ABCD'))
# df.plot(kind='box')
df.plot.box()
# 最大值
# 75%
# 50%
# 25%
# 最小值
# 圆点:表式异常值,离群点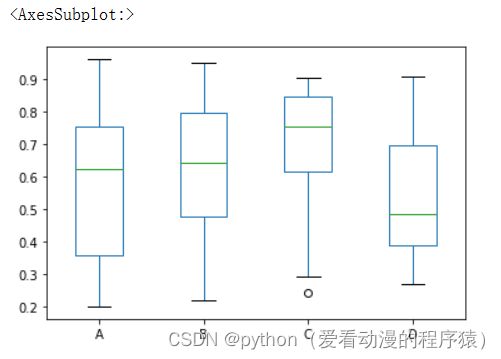
4. 交叉表与透视表
交叉表:交叉表用于计算一列数据对于另外一列数据的分组个数(用于统计分组频率的特殊透视表)
pd.crosstab(value1, value2)
透视表:透视表是将原有DataFrame的列分别作为行索引和列索引,然后对指定列应用聚集函数。
DataFrame.pivot_table([], index=[])
# 寻找星期几跟股票张得的关系
# 1、先把对应的日期找到星期几
date = pd.to_datetime(data.index).weekday
data['week'] = date
# 2、假如把p_change按照大小去分个类0为界限
data['posi_neg'] = np.where(data['p_change'] > 0, 1, 0)
# 通过交叉表找寻两列数据的关系
count = pd.crosstab(data['week'], data['posi_neg'])
# 算数运算,先求和
sum = count.sum(axis=1).astype(np.float32)
# 进行相除操作,得出比例
pro = count.div(sum, axis=0)
pro.plot(kind='bar', stacked=True)
plt.show()
# 通过透视表,将整个过程变成更简单一些
data.pivot_table(['posi_neg'], index='week')