初学者:了解GPT
GPT
- 什么是语言模型
- 自编码(auto-enconde)语言模型
- 自回归(auto-regressive)语言模型
- 基于Transformer的语言模型
- Transformer进化
- GPT2概述
- GPT2详解
- 输入编码
- 多层Decoder
- Decoder中的Self-Attention
- 详解Self-Attention
- GPT2中的Self-Attention
- GPT2全连接神经网络
除了BERT以外,另一个预训练模型GPT也给NLP领域带来了不少轰动,本节也对GPT做一个详细的讲解。
什么是语言模型
本文主要描述和对比2种语言模型:
- 自编码(auto-encoder)语言模型
- 自回归(auto-regressive)语言模型
先看自编码语言模型。 自编码语言模型典型代表就是篇章2.3所描述的BERT。如下图所示,自编码语言模型通过随机Mask输入的部分单词,然后预训练的目标是预测被Mask的单词,不仅可以融入上文信息,还可以自然的融入下文信息。
 自编码语言模型的优缺点:
自编码语言模型的优缺点:
- 优点:自然地融入双向语言模型,同时看到被预测单词的上文和下文。
- 缺点:训练和预测不一致。训练的时候输入引入了[Mask]标记,但是在预测阶段往往没有这个[Mask]标记,导致预训练阶段和Fine-tuning阶段不一致。
接着我们来看看什么是常用的自回归(auto-regressive)语言模型:语言模型根据输入句子的一部分文本来预测下一个词。日常生活中最常见的语言模型就是输入法提示,它可以根据你输入的内容,提示下一个单词。
自回归语言模型的优点和缺点:
- 优点:对于生成类的NLP任务,比如文本摘要,机器翻译等,从左向右的生成内容,天然和自回归语言模型契合。
- 缺点:由于一般是从左到右(当然也可能从右到左),所以只能利用上文或者下文的信息,不能同时利用上文和下文的信息。
GPT-2属于自回归语言模型,相比于手机app上的输入提示,GPT-2更加复杂,功能也更加强大。因为,OpenAI的研究人员从互联网上爬取了40GB的WebText数据集,并用该数据集训练了GPT-2模型。我们可以直接在AllenAI GPT-2 Explorer网站上试用GPT-2模型。 gpt2 output图:自回归GPT-2

基于Transform的语言模型
正如我们在了解Transformer所学习的,原始的Transformer模型是由 Encoder部分和Decoder部分组成的,它们都是由多层transformer堆叠而成的。原始Transformer的seq2seq结构很适合机器翻译,因为机器翻译正是将一个文本序列翻译为另一种语言的文本序列。
但如果要使用Transformer来解决语言模型任务,并不需要完整的Encoder部分和Decoder部分,于是在原始Transformer之后的许多研究工作中,人们尝试只使用Transformer Encoder或者Decoder,并且将它们堆得层数尽可能高,然后使用大量的训练语料和大量的计算资源(数十万美元用于训练这些模型)进行预训练。比如BERT只使用了Encoder部分进行masked language model(自编码)训练,GPT-2便是只使用了Decoder部分进行自回归(auto regressive)语言模型训练。
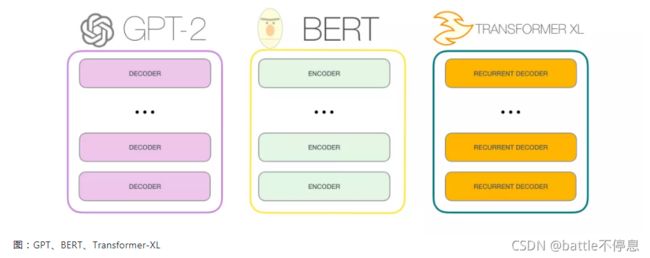
Transform进化
Transformer的Encoder进化成了BERT,Decoder进化成了GPT2。
Decoder部分 与Encoder相比,Decoder部分多了一个Encoder-Decoder self-attention层,使Decoder可以attention到Encoder编码的特定的信息。
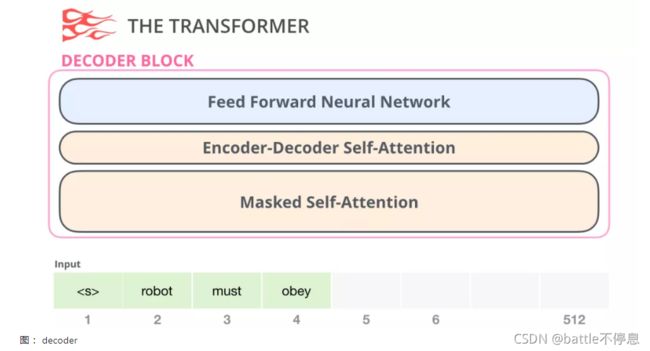
Decoder中的的 Masked Self-Attention会屏蔽未来的token。具体来说,它不像 BERT那样直接将输入的单词随机改为mask,而是通过改变Self-Attention的计算,来屏蔽未来的单词信息。
例如,我们想要计算位置4的attention,我们只允许看到位置4以前和位置4的token。
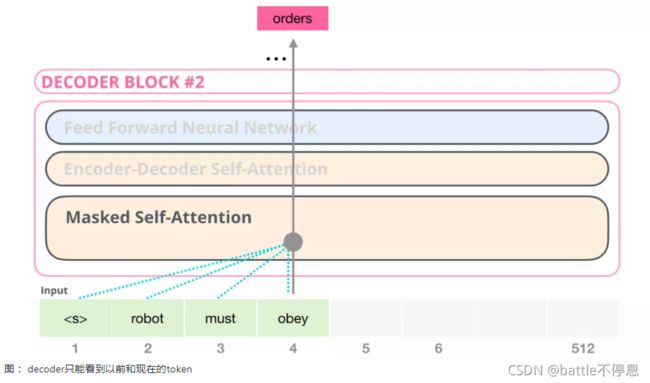
由于GPT2基于Decoder构建,所以BERT和GPT的一个重要区别来了:由于BERT是基于Encoder构建的,BERT使用是Self Attention层,而GPT2基于Decoder构建,GPT-2 使用masked Self Attention。一个正常的 Self Attention允许一个位置关注到它两边的信息,而masked Self Attention只让模型看到左边的信息:
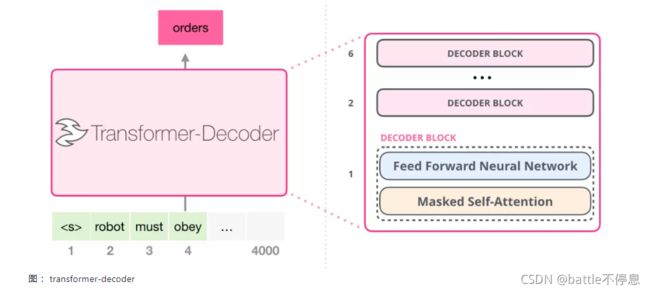
那么GPT2中的Decoder长什么样子呢?由于去掉了Encoder部分,于是Encoder-Decoder self attention也不再需要,新的Transformer-Decoder模型如下图所示:
GPT2
GPT-2能够处理1024 个token。每个token沿着自己的路径经过所有的Decoder层。试用一个训练好的GPT-2模型的最简单方法是让它自己生成文本(这在技术上称为:生成无条件文本)。或者,我们可以给它一个提示,让它谈论某个主题(即生成交互式条件样本)。
在漫无目的情况下,我们可以简单地给它输入一个特殊的初始token,让它开始生成单词。如下图所示:

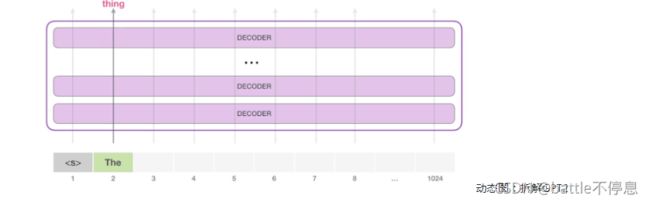
GPT2详解
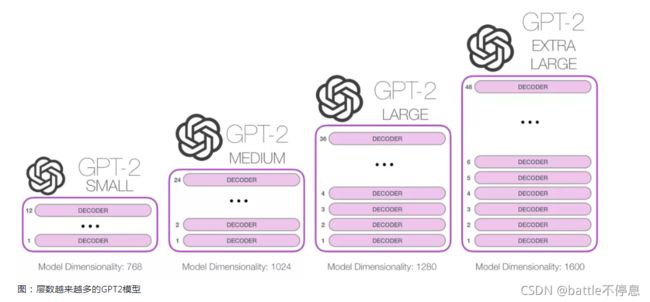
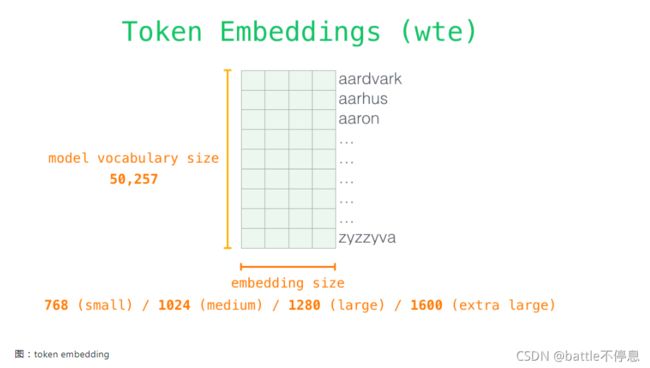
现在我们更深入了解和学习GPT,先看从输入开始。与之前我们讨论的其他 NLP 模型一样,GPT-2 在嵌入矩阵中查找输入的单词的对应的 embedding 向量。如下图所示:每一行都是词的 embedding:这是一个数值向量,可以表示一个词并捕获一些含义。这个向量的大小在不同的 GPT-2 模型中是不同的。最小的模型使用的 embedding 大小是 768。

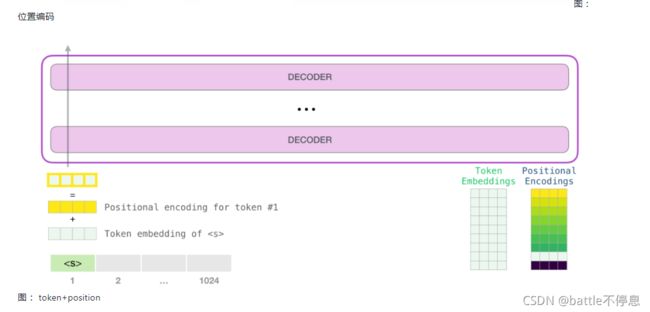
多层Decoder
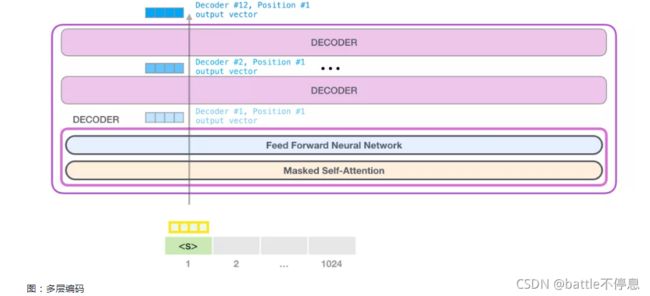
Decoder中包含了Masked Self-Attention,由于Mask的操作可以独立进行,于是我们先独立回顾一下self-attention操作。语言严重依赖于上下文。给个例子:
机器人第2定律:机器人必须服从人给予 它 的命令,当 该命令 与 第一定律 冲突时例外。
- 它 指的是机器人
- 该命令 指的是这个定律的前面部分,也就是 人给予 它 的命令
- 第一定律 指的是机器人第一定律
self-attention所做的事情是:它通过对句子片段中每个词的相关性打分,并将这些词的表示向量根据相关性加权求和,从而让模型能够将词和其他相关词向量的信息融合起来。
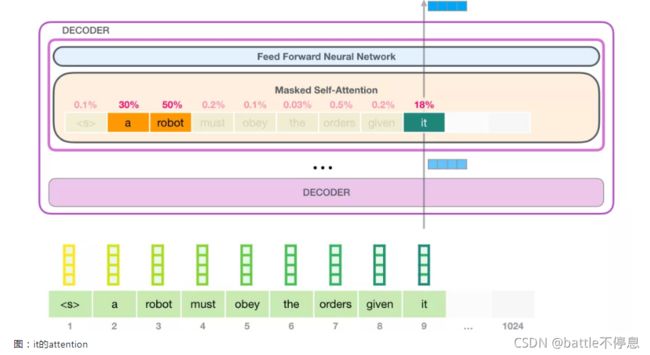
举个例子,如下图所示,最顶层的Decoder中的 Self Attention 层在处理单词 it 的时候关注到 a robot。于是self-attention传递给后续神经网络的it 向量,是3个单词对应的向量和它们各自分数的加权和。
Self-Attention 沿着句子中每个 token 进行处理,主要组成部分包括 3 个向量。
- Query:Query 向量是由当前词的向量表示获得,用于对其他所有单词(使用这些单词的 key 向量)进行评分。
- Key:Key 向量由句子中的所有单词的向量表示获得,可以看作一个标识向量。
- Value:Value 向量在self-attention中与Key向量其实是相同的。

一个粗略的类比是把它看作是在一个文件柜里面搜索,Query 向量是一个便签,上面写着你正在研究的主题,而 Key 向量就像是柜子里的文件夹的标签。当你将便签与标签匹配时,我们取出匹配的那些文件夹的内容,这些内容就是 Value 向量。但是你不仅仅是寻找一个 Value 向量,而是找到一系列Value 向量。
将 Query 向量与每个文件夹的 Key 向量相乘,会为每个文件夹产生一个分数(从技术上来讲:点积后面跟着 softmax)。
我们将每个 Value 向量乘以对应的分数,然后求和,就得到了 Self Attention 的输出。
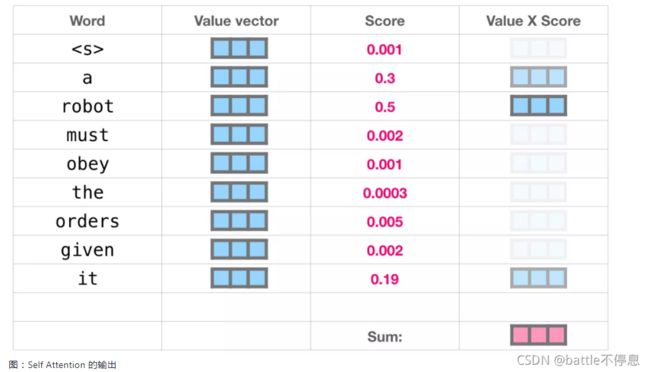
这些加权的 Value 向量会得到一个向量,比如上图,它将 50% 的注意力放到单词 robot 上,将 30% 的注意力放到单词 a,将 19% 的注意力放到单词 it。
而所谓的Masked self attention指的的是:将mask位置对应的的attention score变成一个非常小的数字或者0,让其他单词再self attention的时候(加权求和的时候)不考虑这些单词。
模型的输出
当模型顶部的Decoder层产生输出向量时(这个向量是经过 Self Attention 层和神经网络层得到的),模型会将这个向量乘以一个巨大的嵌入矩阵(vocab size x embedding size)来计算该向量和所有单词embedding向量的相关得分。
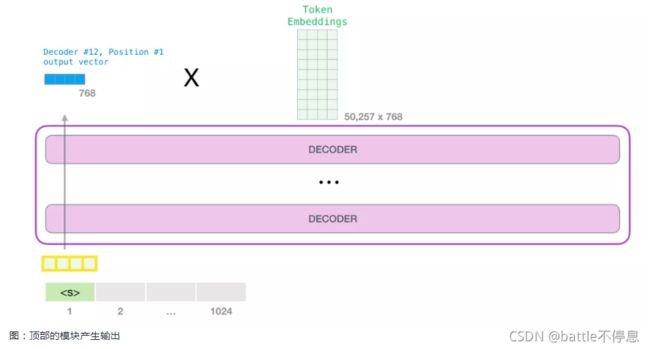
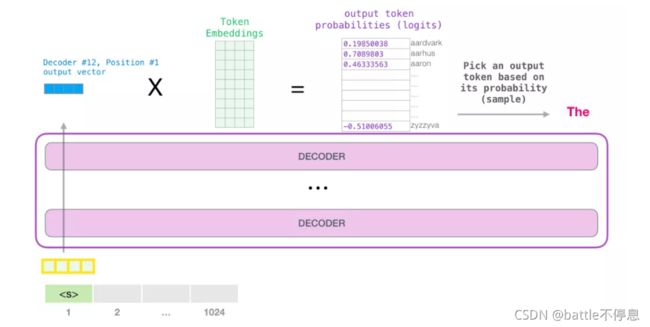
回忆一下,嵌入矩阵中的每一行都对应于模型词汇表中的一个词。这个相乘的结果,被解释为模型词汇表中每个词的分数,经过softmax之后被转换成概率。

我们可以选择最高分数的 token(top_k=1),也可以同时考虑其他词(top k)。假设每个位置输出k个token,假设总共输出n个token,那么基于n个单词的联合概率选择的输出序列会更好。
GPT2中的Self-attention
让我们更详细地了解 GPT-2的masked self attention。
模型预测的时候:每次处理一个 token
但我们用模型进行预测的时候,模型在每次迭代后只添加一个新词,那么对于已经处理过的token来说,沿着之前的路径重新计算 Self Attention 是低效的。那么GPT-2是如何实现高效处理的呢?
先处理第一个token a,如下图所示(现在暂时忽略 )。
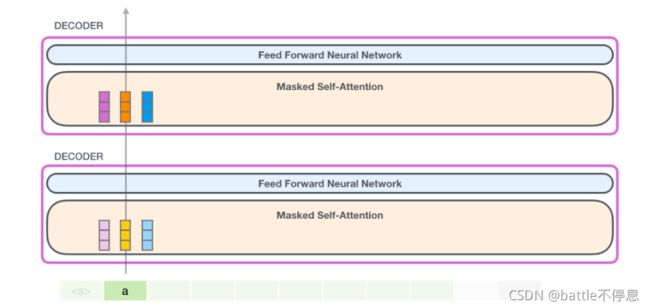
GPT-2 保存 token a 的 Key 向量和 Value 向量。每个 Self Attention 层都持有这个 token 对应的 Key 向量和 Value 向量:
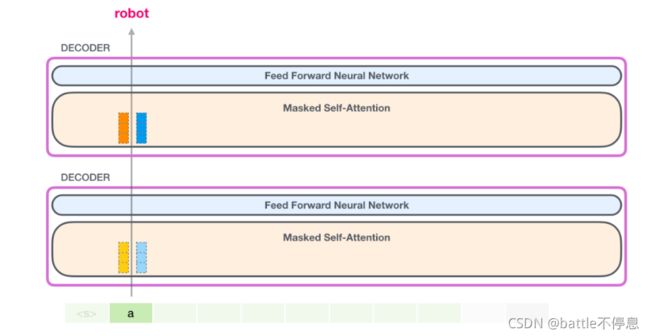
现在在下一个迭代,当模型处理单词 robot,它不需要生成 token a 的 Query、Value 以及 Key 向量。它只需要重新使用第一次迭代中保存的对应向量:
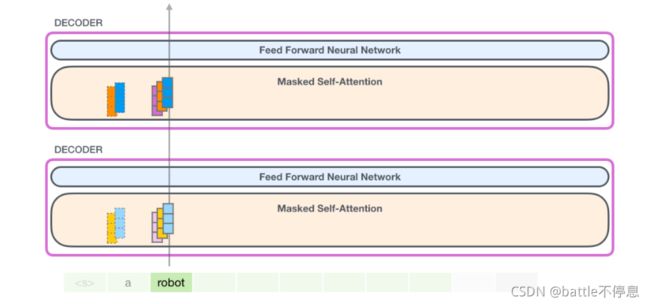
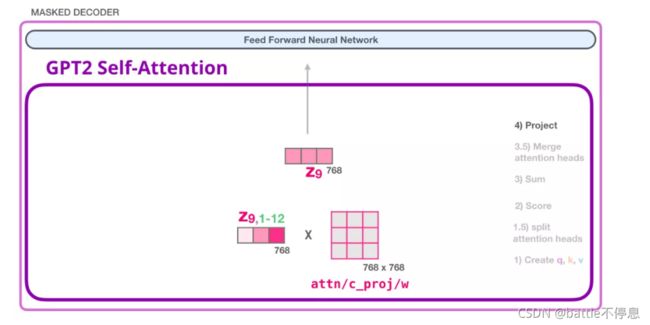
(1) 创建 Query、Key 和 Value 矩阵
让我们假设模型正在处理单词 it。进入Decoder之前,这个 token 对应的输入就是 it 的 embedding 加上第 9 个位置的位置编码:

Transformer 中每个层都有它自己的参数矩阵(在后文中会拆解展示)。embedding向量我们首先遇到的权重矩阵是用于创建 Query、Key、和 Value 向量的。
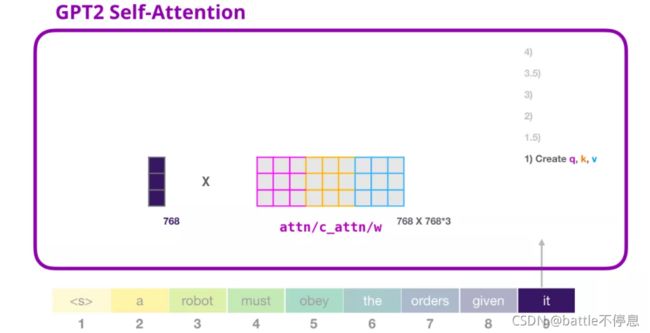
Self-Attention 将它的输入乘以权重矩阵(并添加一个 bias 向量,此处没有画出)
这个相乘会得到一个向量,这个向量是 Query、Key 和 Value 向量的拼接。
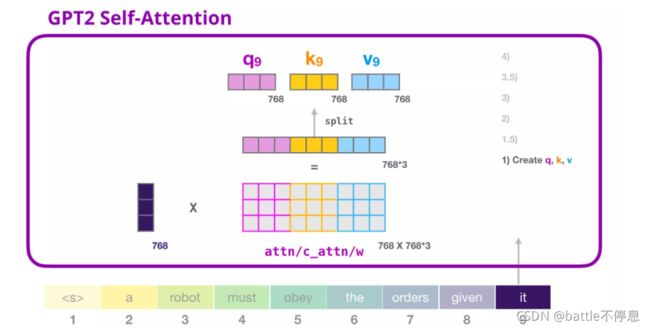
得到Query、Key和Value向量之后,我们将其拆分multi-head,如下图所示。其实本质上就是将一个大向量拆分为多个小向量。

为了更好的理解multi head,我们将其进行如下展示:
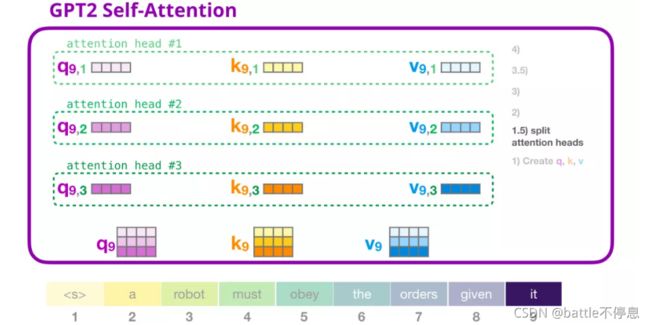
我们现在可以继续进行评分,假设我们只关注一个 attention head(其他的 attention head 也是在进行类似的操作)。
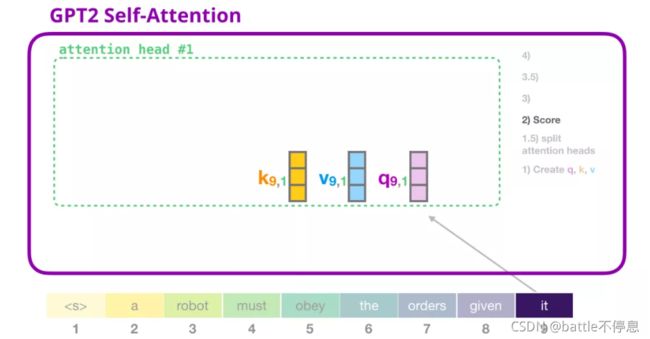
现在,这个 token 可以根据其他所有 token 的 Key 向量进行评分(这些 Key 向量是在前面一个迭代中的第一个 attention head 计算得到的):

正如我们之前所看的那样,我们现在将每个 Value 向量乘以对应的分数,然后加起来求和,得到第一个 attention head 的 Self Attention 结果:
multi head对应得到多个加权和向量,我们将他们都再次拼接起来:
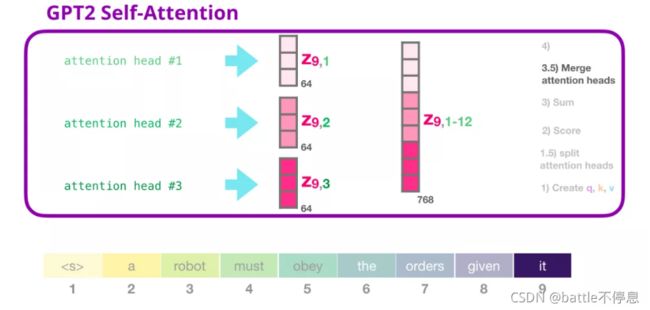
我们将让模型学习如何将拼接好的 Self Attention 结果转换为前馈神经网络能够处理的输入。在这里,我们使用第二个巨大的权重矩阵,将 attention heads 的结果映射到 Self Attention 子层的输出向量:
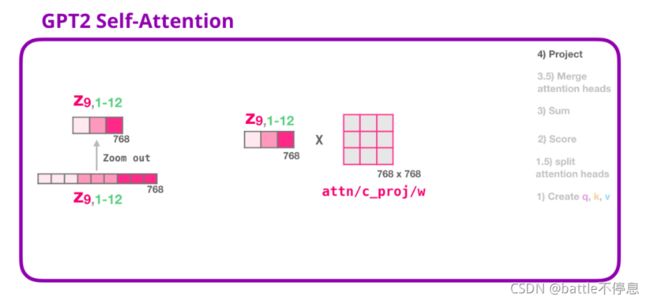
通过以上步骤,我们产生了一个向量,我们可以把这个向量传给下一层: