Oracle19c DataGuard
为记录的更详细点,文章经过二次编辑,有几张图的时间对不上,不过不影响查阅。
CSDN排版不太友好,有些代码的进位都给省略了。
文章早就编辑好了,由于一些原因一直没发出来。
根据自己的环境,一定要仔细比对db_name、db_unique_name、文件路径等等。
文章如有遗漏或错误,欢迎指正。
环境概况
主机一:h1.e.cc
主机二:h2.e.cc
我这里先是在 主机一 上创建了一个 CDB 数据库:DB0
图个方便,把sys密码设置成了0.
初步搭建完成后:
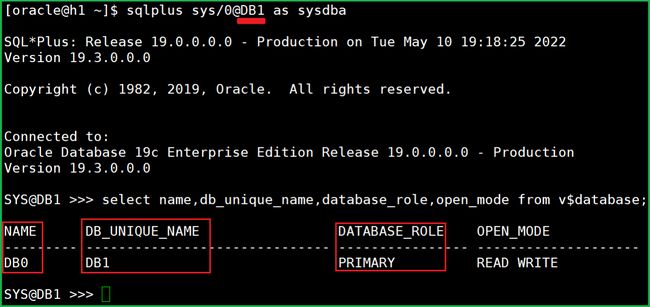
主库:db_name 是 DB0, db_unique_name 是 DB1.
备库:db_name 是 DB0, db_unique_name 是 DB2.
网络
DataGuard 环境得配置静态监听,注意加粗及高亮部分,listener文件中不能有制表符(tab)
主库添加:
SID_LIST_LISTENER=
(SID_LIST= (SID_DESC= (GLOBAL_DBNAME=DB1.e.cc)(SID_NAME=DB0)
(ORACLE_HOME=/u01/app/oracle/product/19.0.0/dbhome_1)))
备库添加:
SID_LIST_LISTENER=
(SID_LIST= (SID_DESC= (GLOBAL_DBNAME=DB2.e.cc)(SID_NAME=DB0)
(ORACLE_HOME=/u01/app/oracle/product/19.0.0/dbhome_1)))
记得检查两边监听,都要处于启动状态。
tnsnames.ora文件中添加:(主备库都要添加)
DB1 = (DESCRIPTION =
(ADDRESS = (PROTOCOL = TCP)(HOST = h1.e.cc)(PORT = 1521))
(CONNECT_DATA = (SERVER = DEDICATED)(SERVICE_NAME = DB1.e.cc)))
DB2 =(DESCRIPTION =
(ADDRESS = (PROTOCOL = TCP)(HOST = h2.e.cc)(PORT = 1521))
(CONNECT_DATA = (SERVER = DEDICATED)(SERVICE_NAME = DB2.e.cc)))
注:$ORACLE_HOME/sqlplus/admin/glogin.sql 里添加了一行: set sqlp "_user '@'_connect_identifier >>> " ~oracle/.bash_profile 里 ORACLE_SID=DB0 所以,当看到:SYS@DB0 >>> 时,说明我是通过 OS 验证方式连接实例的。 像这样: sqlplus / as sysdba 而看到: SYS@DB1>>> 或 SYS@DB2 >>> 时,说明我是通过监听连接实例的。 像这样: sqlplus sys/0@DB1 as sysdba 或 sqlplus sys/0@DB2 as sysdba |
主机一(主库):
要处于归档模式:
查看:archive log list;

如果没有启用归档模式,数据库要 mount 状态执行:
alter database archivelog;standby log
查看redo概况:
select bytes/1024/1024 from v$log
where group# in (select group# from v$logfile);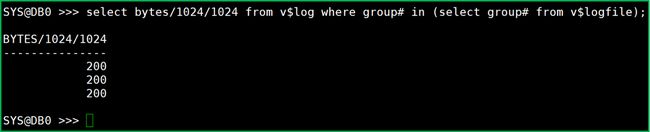
创建(redo member 数+1)个 standbylog。
alter database add standby logfile '/u01/app/oracle/oradata/DB0/standby01.log' size 200M;
alter database add standby logfile '/u01/app/oracle/oradata/DB0/standby02.log' size 200M;
alter database add standby logfile '/u01/app/oracle/oradata/DB0/standby03.log' size 200M;
alter database add standby logfile '/u01/app/oracle/oradata/DB0/standby04.log' size 200M;开启强写日志
alter database force logging;关闭闪回
alter database flashback off;local_listener 要设置为空
alter system set local_listener='';从当前spfile创建一个pfile
create pfile from spfile;关闭数据库
shu immediate;编辑数据库参数文件pfile
注意高亮及加粗部分。
DB0.__data_transfer_cache_size=0 DB0.__db_cache_size=1828716544 DB0.__inmemory_ext_roarea=0 DB0.__inmemory_ext_rwarea=0 DB0.__java_pool_size=0 DB0.__large_pool_size=16777216 DB0.__oracle_base='/u01/app/oracle' DB0.__pga_aggregate_target=838860800 DB0.__sga_target=2516582400 DB0.__shared_io_pool_size=134217728 DB0.__shared_pool_size=520093696 DB0.__streams_pool_size=0 DB0.__unified_pga_pool_size=0 *.audit_file_dest='/u01/app/oracle/admin/DB0/adump' *.audit_trail='db' *.compatible='19.0.0' *.control_files='/u01/app/oracle/oradata/DB0/control01.ctl' *.db_block_size=8192 *.db_domain='e.cc' *.db_name='DB0' *.db_recovery_file_dest='/u01/app/oracle/fast_recovery_area' *.db_recovery_file_dest_size=20g *.diagnostic_dest='/u01/app/oracle' *.dispatchers='(PROTOCOL=TCP) (SERVICE=DB0XDB)' *.enable_pluggable_database=true *.local_listener='' *.log_archive_format='%t_%s_%r.dbf' *.nls_language='AMERICAN' *.nls_territory='AMERICA' *.open_cursors=300 *.pga_aggregate_target=798m *.processes=320 *.remote_login_passwordfile='EXCLUSIVE' *.sga_target=2394m *.undo_tablespace='UNDOTBS1' -- 以下是新加的参数 DB_UNIQUE_NAME=DB1 LOG_ARCHIVE_CONFIG='DG_CONFIG=(DB1,DB2)' LOG_ARCHIVE_DEST_1= 'LOCATION=/u01/app/oracle/fast_recovery_area VALID_FOR=(ALL_LOGFILES,ALL_ROLES) DB_UNIQUE_NAME=DB1' LOG_ARCHIVE_DEST_2= 'SERVICE=DB2 SYNC AFFIRM VALID_FOR=(ONLINE_LOGFILES,PRIMARY_ROLE) DB_UNIQUE_NAME=DB2' FAL_SERVER=DB2 DB_FILE_NAME_CONVERT='/DB2/','/DB1/' LOG_FILE_NAME_CONVERT='/DB2/','/DB1/' STANDBY_FILE_MANAGEMENT=AUTO |
rm或mv之前的 spfile.
rm -f spfileDB0.ora创建spfile,并启动数据库实例
登录 sqlplus, 创建 spfile. 再 startup.
create spfile from pfile;
查看:
可以看到 BD_UNIQUE_NAME 变成 DB1 了,之前是 DB0.
准备配置备库
#未能正常启动就回去看看哪里疏漏了什么细节。
#如果可以正常开启数据库就把 pfile 和密码文件复制到备库上, 准备编辑备库的参数文件
cd $ORACLE_HOME/dbs
scp initDB0.ora h2:/u01/app/oracle/product/19.0.0/dbhome_1/dbs/
scp orapwDB0 h2:/u01/app/oracle/product/19.0.0/dbhome_1/dbs/主机二(备库)
编辑备库参数文件
到主机二$ORACLE_HOME/dbs目录编辑参数文件
//互换DB1和DB2。
sed -i 's/DB1/AAAA/g' initDB0.ora
sed -i 's/DB2/DB1/g' initDB0.ora
sed -i 's/AAAA/DB2/g' initDB0.ora执行上面三条替换命令,DB1 和 DB2 就互换过来了:
DB_UNIQUE_NAME=DB2 LOG_ARCHIVE_CONFIG='DG_CONFIG=(DB2,DB1)' LOG_ARCHIVE_DEST_1= 'LOCATION=/u01/app/oracle/fast_recovery_area VALID_FOR=(ALL_LOGFILES,ALL_ROLES) DB_UNIQUE_NAME=DB2' LOG_ARCHIVE_DEST_2= 'SERVICE=DB1 SYNC AFFIRM VALID_FOR=(ONLINE_LOGFILES,PRIMARY_ROLE) DB_UNIQUE_NAME=DB1' FAL_SERVER=DB1 DB_FILE_NAME_CONVERT='/DB1/','/DB2/' LOG_FILE_NAME_CONVERT='/DB1/','/DB2/' STANDBY_FILE_MANAGEMENT=AUTO |
创建目录
创建好需要的目录:
#根据自己的环境,仔细比对是否正确
mkdir -p /u01/app/oracle/admin/DB0/adump
mkdir -p /u01/app/oracle/oradata/DB0/
mkdir -p /u01/app/oracle/fast_recovery_area开启备库到nomount状态
创建spfile:
create spfile from pfile;开启备库到nomount状态
startup nomount;rman复制

不出意外的话,能看到这么一行: 
如有报错,看看报错信息,回去看看哪里搞错了,删除生成的"问题文件",再尝试能否成功。 |
到sqlplus查看: 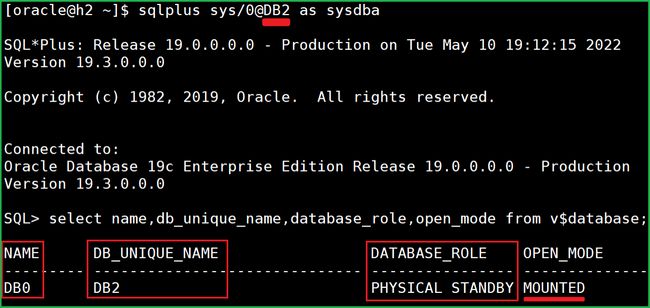
database_role 为 PHYSICAL STANDBY,duplicate 操作完成后就会启动到 mount 状态。 |
开始同步(应用日志)
备库进sqlplus,应用日志 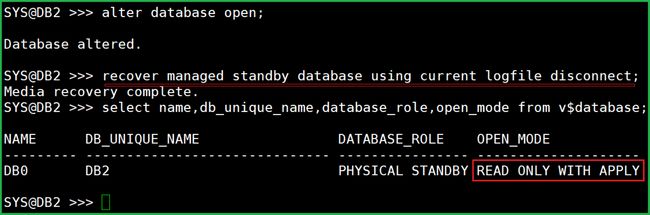
可以看到,open_mode 为 read only with apply. |
取消应用: 
取消应用日志后,就变成 read only 了。 |
完成基本搭建了
基本管理
temp_undo
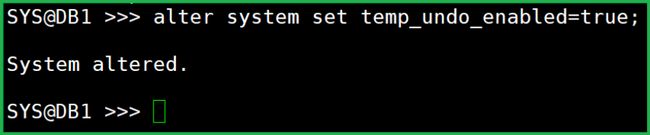
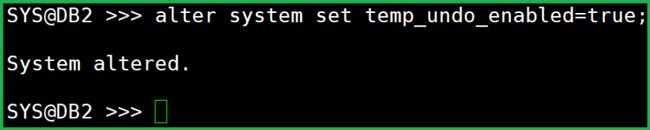
最好开启 temp_undo:
alter system set temp_undo_enabled=true;
dg_broker
alter system set dg_broker_start=true;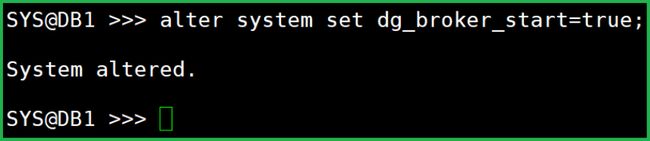

reset log_archive_dest_n
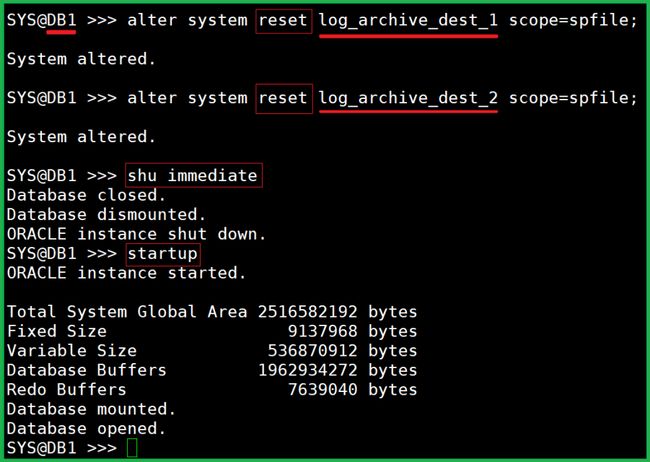
alter system reset log_archive_dest_1 scope=spfile;
alter system reset log_archive_dest_2 scope=spfile;然后重启两个数据库。都开启到 read write 状态。

开启闪回
alter database flashback on;
dgmgrl
到 dgmgrl 里做一些骚操作吧!
dgmgrl sys/0@DB1
注:这里先连到主库。
新建一个配置
新建一个配置,就叫 dgtest 吧。
create configuration dgtest as primary database is 'DB1' connect identifier is 'DB1';
add database 'DB2' as connect identifier is 'DB2';
查看
show configuration; 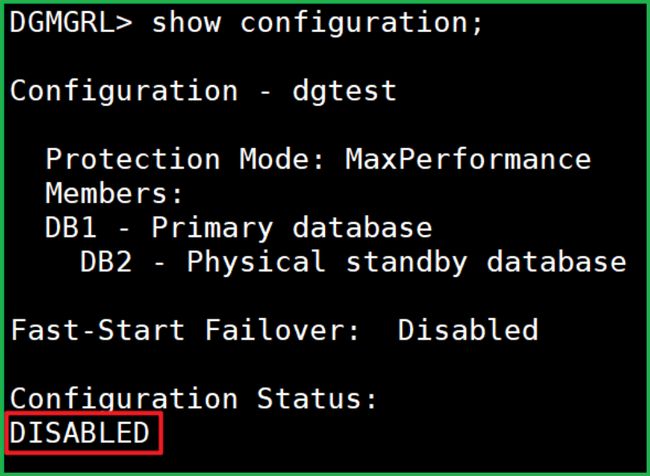
还未开启。
show database verbose 'DB1';
show database verbose 'DB2';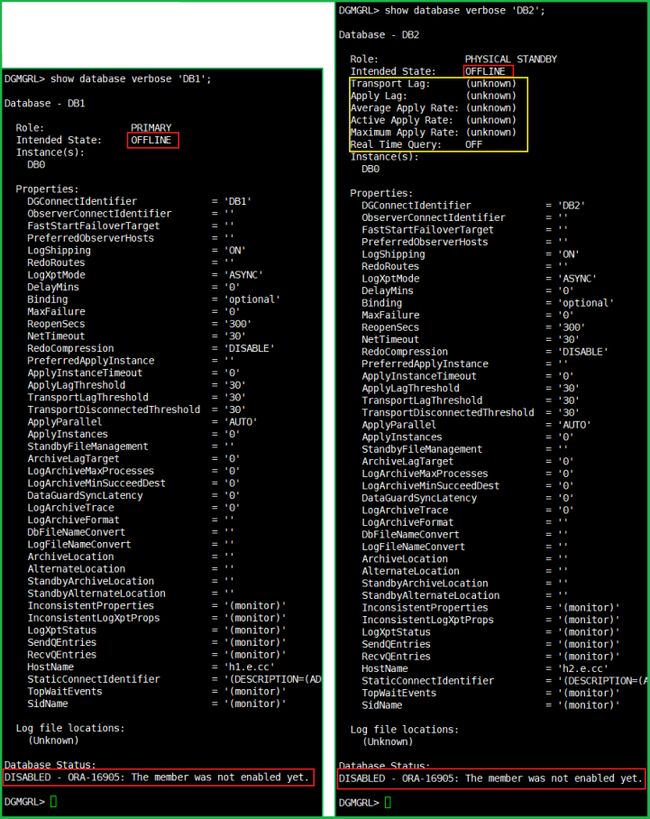
两个都是 disable 状态。
启用
enable configuration;
enable database 'DB1';
enable database 'DB2';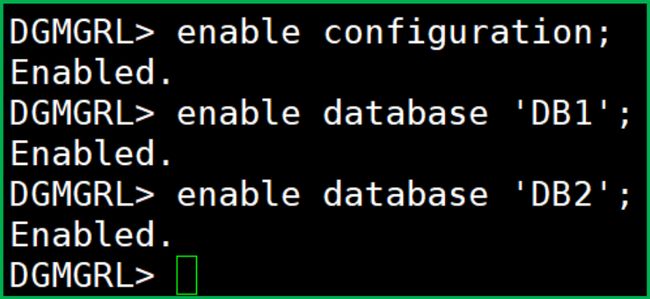
查看
show database verbose 'DB1';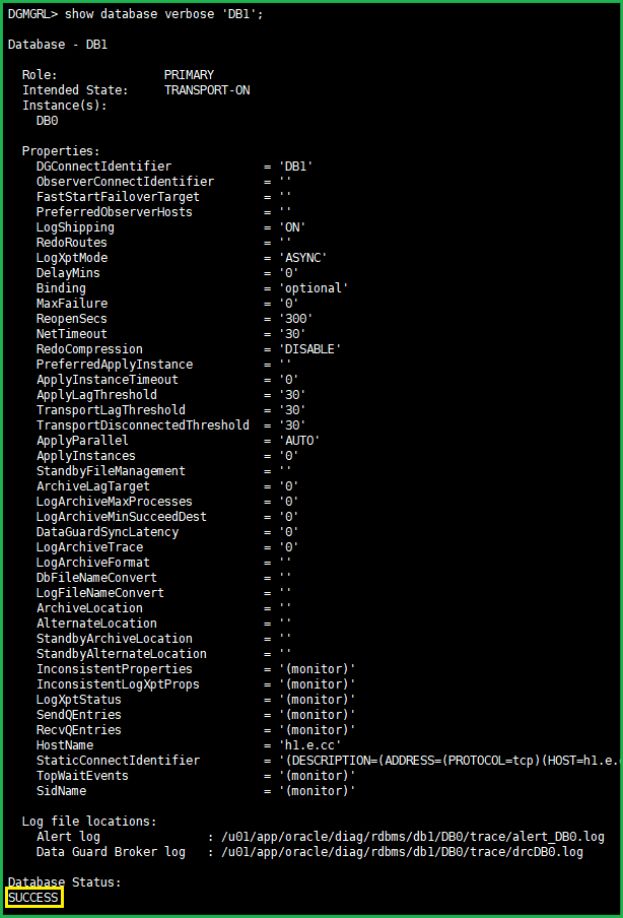
show database verbose 'DB2';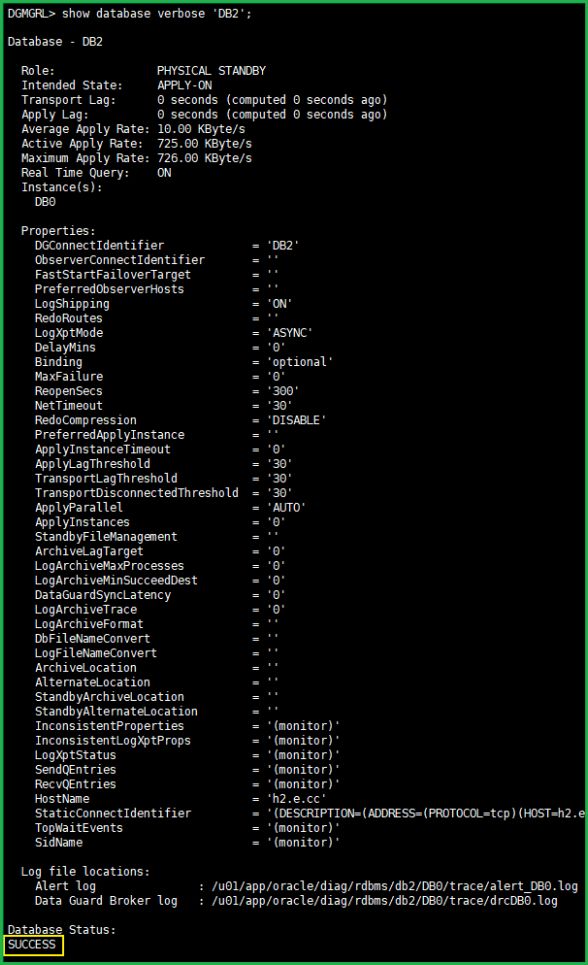
show configuration;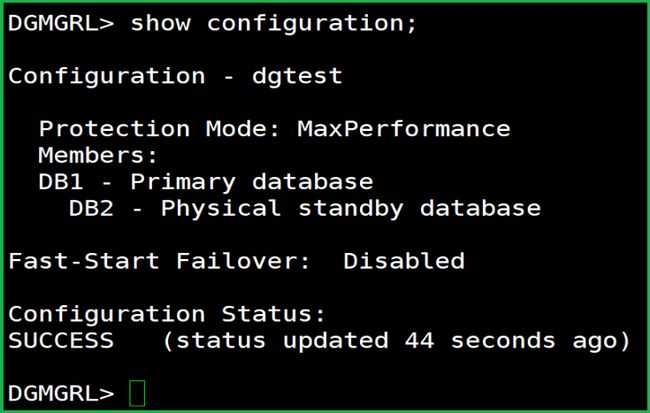
没有报错,也没有警告。 就很舒服。
#注:有些状态内容是一分钟刷新一次的,所以做完更改可能要稍微等一会才能看到变化。做一些改动
edit database 'DB1' set property FastStartFailoverTarget='DB2'; edit database 'DB2' set property FastStartFailoverTarget='DB1'; edit database 'DB1' set property LogXptMode='SYNC'; edit database 'DB2' set property LogXptMode='SYNC'; |
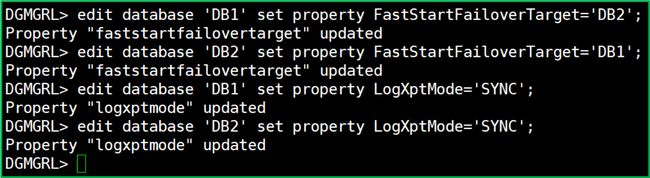
EDIT CONFIGURATION SET PROTECTION MODE MaxAvailability;
enable fast_start failover;
出来个小提示:Zero Data Loss Mode … 很装 X 的感 Jo.
StaticConnectIdentifier
有个 StaticConnectIdentifier 参数,默认是这样的:
这个参数有问题,执行角色互换时换到一半就中止报错,需要改一下。
edit database 'DB1' set property StaticConnectIdentifier='DB1'; edit database 'DB2' set property StaticConnectIdentifier='DB2'; |
参数值要跟 tnsnames 文件里的连接名要匹配。
-- 查看
show configuration; 
observer 进程没开启。 开启之前先看看能不能手动切换:
手动切换角色
switchover to 'DB2';
我在这里是连接到主库执行的切换,如果是在12c数据库上的话会报一个错误,会提示让你连接到备库再执行切换。
而到19c版本,即使连接的是主库,它会自动连接到备库再执行切换(黄框)。
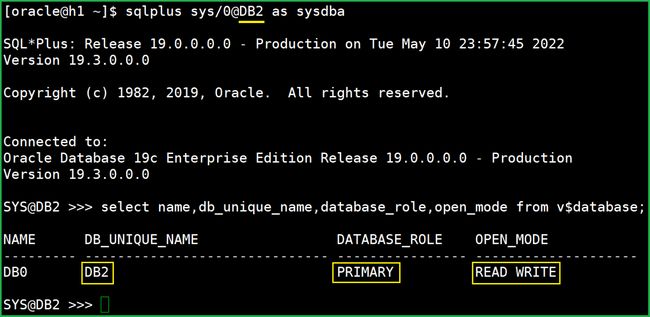
sqlplus查看:
select name,db_unique_name,database_role,open_mode from v$database;之前的备库(DB2),变成主库了,并且已经处于读写状态了:
再看看之前的主库(DB1),变成备库了,并且处于read only with apply,
也就是说已经开始应用日志了,自动的。
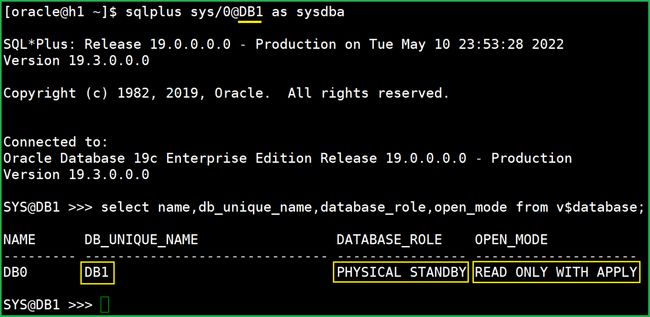
主库:糟了,我成替身了!
手动切换成功了那么自动切换也就没什么大问题了。
自动切换
开启observer
observer “观察”到主库异常时(比如断电)会执行故障转移。
dgmgrl -silent sys/0@DB1 'start observer' &模拟灾难
shutdown abort 命令也会使 observer 做出反应。
不要随便shutdown abort,这条命令相当于把服务器电源给踹了。

观察
这个是 DB1 实例所在主机(h1):
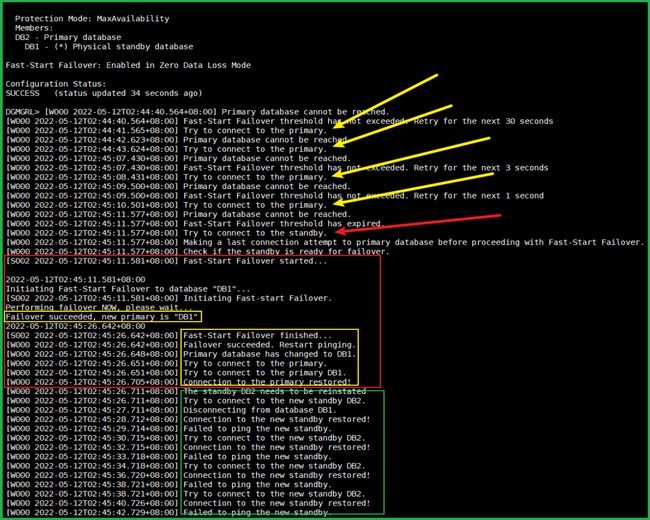
这个是 DB2 实例所在主机(h2):
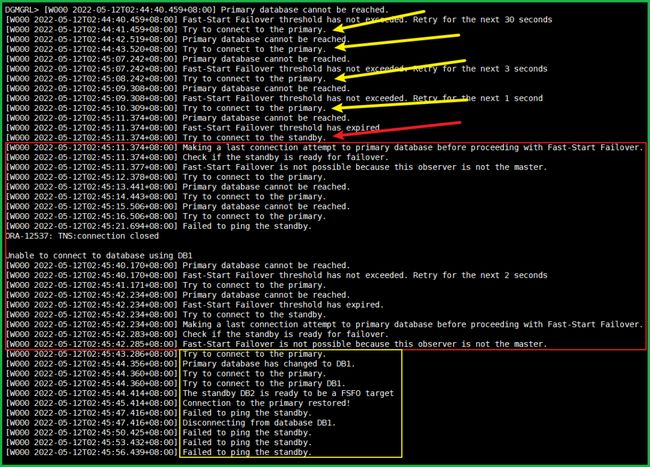
当敲完 shutdown abort 后就立马开始警告了。
30 秒(FastStartFailoverThreshold)后就开始故障转移了,且成功了(红框)。
下面的几行警告是因为之前的主库变备库,但是已经被 shutdown了,提示连不到备库。
手动开启备库
startup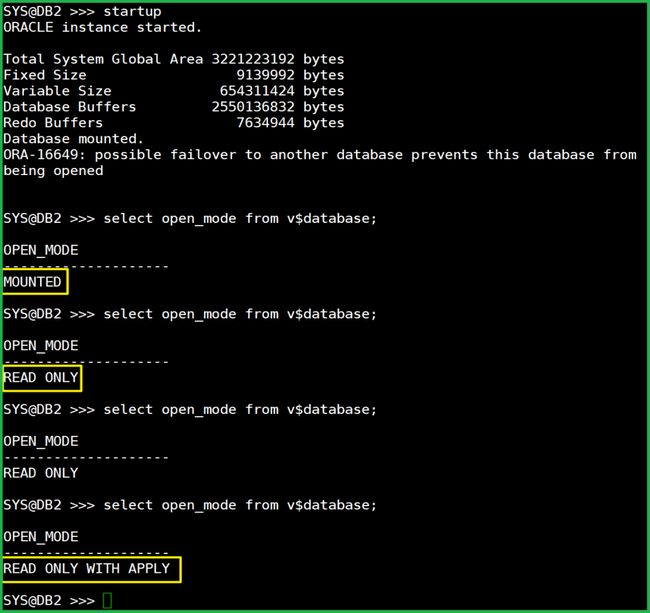
注意:这里我只敲了“startup”,其它啥都没干。
只是查看了几下开启状态,刚开始是 mount,然后是 read only,最后是 read only with apply 了。
已经开始应用了,自动地。
看看 h1 主机:

看看h2主机:
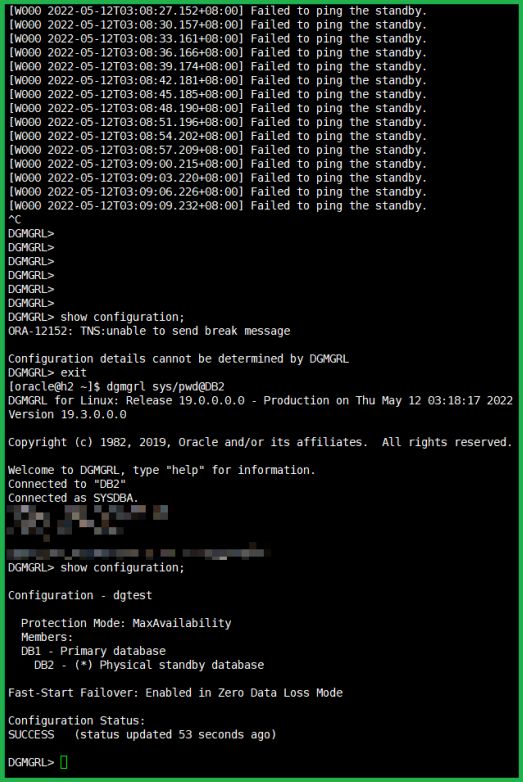
打码部分是命令敲错了。
完事了!↓↓↓
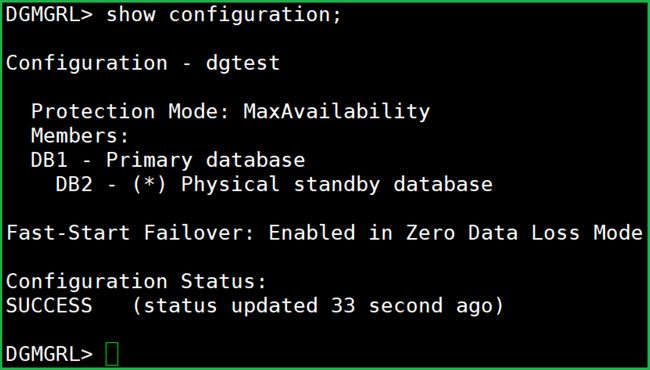
一切正常,仿佛什么都没发生过一样。
嗯↗嗯~ 赛高尼 high 铁鸭子哒~

看看日志
当 shutdown abort 时,DB1(现在的主库)日志:
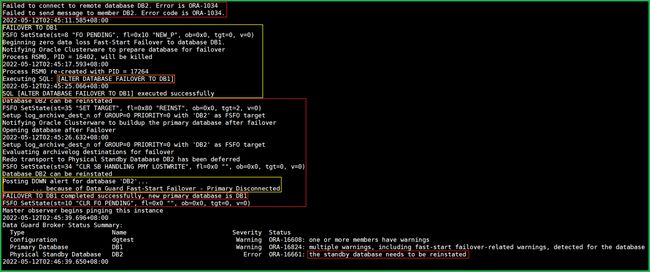
而DB2(当时的主库)的日志没动静了。(毕竟电源被踹了)
开启备库(DB2)后,DB1 日志:
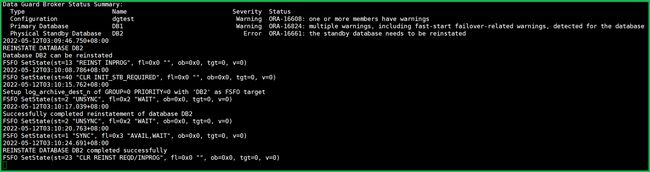
报错没了。
DB2(之前的主库,现在的备库)日志里看到了这样的信息:
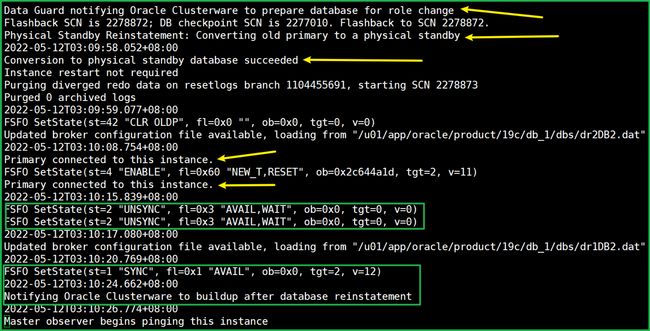
整个过程我只做了:
shutdown abort 和手动启动备库。
而且 shutdown abort 是模拟了一个小灾难,不能算是我的操作。
故障转移都是由 oracle 自动完成的。
包括手动启动备库之后的应用日志,也是自动给我做好了。
也就是说,主库挂了变备库了,你唯一要做的就是 startup 它,其它的事情 oracle 自动给你做好了。
当然,在业务环境当中发生这样的事故,情况要复杂的多得多。
我这只是简单的学习环境,可以说是"理想环境"。
其它
执行 alter system set dg_broker_start=true; 后,
OS 里可以查到一个进程叫 dmon.

执行 dgmgrl -silent sys/0@DB1 'start observer;' & 后,可以这样查看:

observer的关闭:
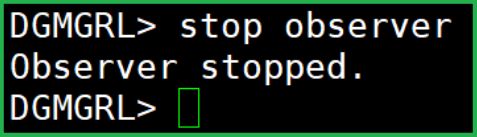
dgmgrl 的帮助非常友好:直接复制粘贴就好了,Oracle一贯的风格。