可以白嫖的语音识别开源项目whisper的搭建详细过程 | 如何在Linux中搭建OpenAI开源的语音识别项目Whisper
原文来自我个人的博客。
1、前提条件
服务器为GPU服务器。点击这里跳转到我使用的GPU服务器。我搭建 whisper 选用的是 NVIDIA A 100显卡,4GB显存。
Python版本要在3.8~3.11之间。
输入下面命令查看使用的Python版本。
python3 -V
2、安装Anaconda
为啥要安装Anaconda?
为了减少不同项目使用的库的版本冲突,我们可以使用Anaconda来创建虚拟Python环境。
下载Anaconda安装脚本
找到对应自己系统的安装器。

下载完成之后我们可以直接运行脚本。
bash 脚本.sh
也可以使用下面的方式运行脚本。
chmod +x 脚本.sh
./脚本.sh
安装完成之后需要重新连接SSH。
验证是否安装成功,可以使用下面的命令。
conda -V
3、安装FFmpeg
apt install ffmpeg
输入ffmpeg回车之后可以看到提示信息,说明安装成功。
4、安装显卡驱动
先输入nvidia-smi查看显卡信息,如果有提示信息,说明已经安装过了显卡驱动。
如果没有安装过显卡驱动,那么这里提供两种安装方式。
4.1、方式一
ubuntu-drivers devices 查看可以安装的显卡驱动
apt install nvidia-driver-530 安装推荐的显卡驱动
nvidia-smi 查看显卡信息

4.2、方式二
去NVIDIA官方驱动下载网站下载相对应的显卡驱动。
点击这里去下载。
具体可以参考这篇文章。
5、安装CUDA
下载CUDA
下载的CUDA版本一定要小于等于nvidia-smi中看到的CUDA版本,不能随意下载。
根据官方的命令安装。
编辑~/.bashrc,在最后添加下面命令。
export PATH=/usr/local/cuda-12.1/bin${PATH:+:${PATH}}
export LD_LIBRARY_PATH=$LD_LIBRARY_PATH:/usr/local/cuda-12.1/lib64
注意:需要把上面cuda-12.1改为你自己安装的CUDA的版本。
重新载入
source ~/.bashrc
sudo ldconfig
检查CUDA是否安装好。
nvcc -V
如果安装过程中没有任何报错,但是输入该命令之后,没有输出版本信息,那么是你的环境变量没有配置或者是没有正确配置。
6、安装cuDNN(可选)
需要主要要想下载cuDNN必须要注册NVIDIA账号,并且一定要勾选同意加入他们的社区,否则是不能下载的。并且这个下载之前是要认证的,所以你不能直接在服务上下载,否则下载的只是一个网页,我们需要在本地电脑上先下载,然后通过rz或者是scp命令上传到服务器中。
cuDNN下载
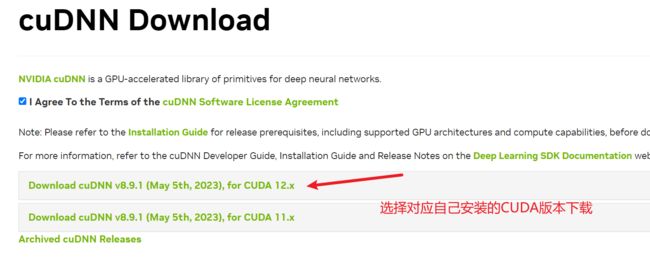
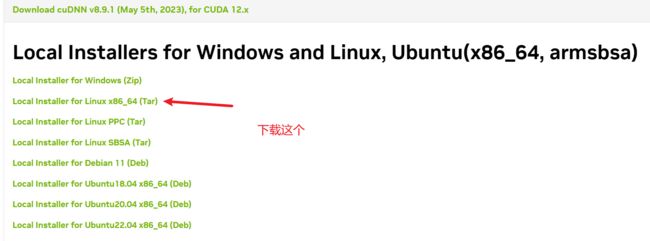
下载完成之后,解压到CUDA目录下。
tar -xvf 文件名
cd 文件夾
sudo cp include/* /usr/local/cuda-12.1/include
sudo cp lib/libcudnn* /usr/local/cuda-12.1/lib64
sudo chmod a+r /usr/local/cuda-12.1/include/cudnn*
sudo chmod a+r /usr/local/cuda-12.1/lib64/libcudnn*
cat /usr/local/cuda/include/cudnn_version.h | grep CUDNN_MAJOR -A 2
7、安装PyTorch
点击这里下载PyTorch
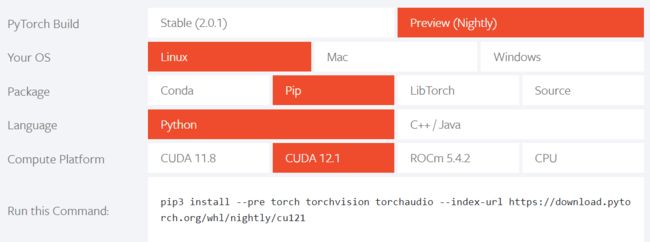
注意:安装的版本一定要和你CUDA版本一致。
安装的时候直接复制官方给出的命令即可。
然后我们可以使用下面的命令来验证是否安装成功。
python
import torch
torch.__version__
torch.cuda.is_available()
其中最后一句是关键,只有返回Ture,才能让Whisper使用显卡进行转录,否则是使用CPU进行转录。如果最后一句返回的是False,那么可能是你安装的PyTorch版本中使用的CUDA版本和你服务器中已经安装的CUDA版本不一致。
8、安装Whisper
安装之前需要使用conda创建一个虚拟环境。
conda create -n whisper python=3.10
激活虚拟环境。
conda activate whisper
退出虚拟环境。
conda deactivate
查看虚拟环境。
conda env list
删除虚拟环境。
conda remove -n whisper --all
先激活虚拟环境,然后输入下面一条命令即可安装。
pip install -U openai-whisper
如果没有任何报错,然后我们输入下面的命令,当看到信息输出时,说明安装成功。
whisper -h
9、Whisper的使用
第一次使用的时候比较慢,需要下载模型,使用的模型越大,转录的速度越慢,转录的准确性越高,Whisper对西班牙语的识别准确性最高,其次时意大利语,然后才是英语,而对于普通话的识别排在中间。
这里简单写一下Whisper的用法。
whisper 你要转录的音视频文件 --model large --language Chinese
更多用法可以使用whisper -h查看。