oracle 索引概念、索引相关、sql查询执行计划
文章目录
-
- 一.索引
-
- 1.1 索引概念
- 1.2 索引分类
- 1.3 位图索引(企业版oracle):
- 1.4 B树索引
-
- (1) 唯一索引
- (2) 组合索引
- (3) 反向键索引
- (4) 函数索引
- 1.5 和分区相关的索引(可将索引存储在不同分区中)
-
- (1) 局部分区索引:
- (2)全局分区索引:
- (3)全局非分区索引:
- 二.索引操作
-
- 2.1 创建标准索引:
- 2.2 查看表中的索引:
- 2.3 查看索引信息:
- 2.4 分析索引是否存在索引碎片:
- 2.5 重建索引:
- 2.6 删除索引:
- 三.执行计划(explain plan)
-
- 3.1 执行计划概念
- 3.2 如何查看执行计划
- 3.3 表访问方式
-
- (1).全表扫描 TABLE ACCESS FULL
- (2). 索引扫描 TABLE ACCESS BY ROWID
-
- index unique scan --索引唯一扫描
- index range scan --索引范围扫描
- index full scan --索引全扫描
- index fast full scan --索引快速全局扫描
- index skip scan --索引跳跃扫描
一.索引
1.1 索引概念
索引作为表相关的可选结构,用于提高sql语句执行性能,减少磁盘IO;索引在逻辑上和物理上都独立于表的数据;使用create index语句创建索引;oracle自动维护索引;
1.2 索引分类
索引分为:B树索引、位图索引
B树索引分为:唯一索引、组合索引、反向键索引、基于函数的索引
1.3 位图索引(企业版oracle):
位图索引适合创建在低基数列(如 性别 仅有 男 女2个属性)上,用一个索引键条目存储指向多行的指针;
位图索引不直接存储rowid,而存储字节列到rowid的映射;
如果索引列被经常更新的话,不适合建立位图索引;
位图索引适合于数据仓库中,不适合OLTP中
1.4 B树索引
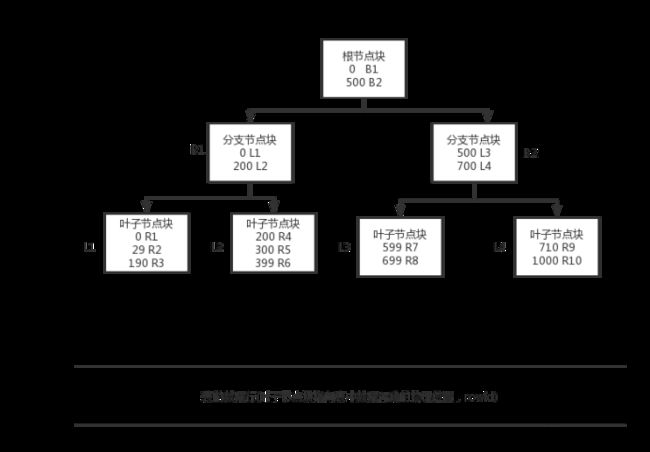
B树索引是一个二叉树,通过根节点块、分支节点块确定叶子节点块,最后叶子节点块包含索引列和指向表中每个匹配行的rowid值
(1) 唯一索引
唯一索引确保在定义索引的列中没有重复值;oracle自动在表的主键上创建唯一索引;
创建表:
create table stu1 (sid number,sname varchar2(20),sage number,male varchar2(2));
在表上创建唯一索引
create unique index s1_index on stu1(SID);
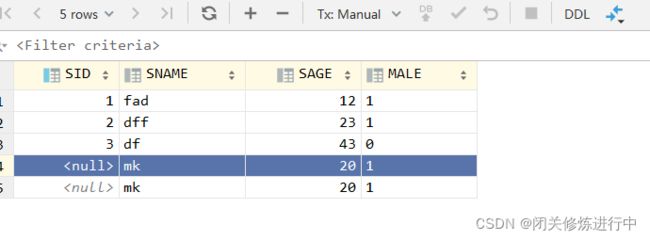
唯一索引可重复插入空值,不违反唯一约束
insert into stu1 values (null,'mk',20,'1');
(2) 组合索引
组合索引是在表中多个列上创建的索引;索引上列的顺序是任意的;如果sql查询中where子句中引用了组合索引的所有列或大多数列,则可以提升检索速度;
(3) 反向键索引
根据实际情况,反转索引列键值的每个字节;通常建立在值是连续增长的列上,使数据均匀地分布在整个索引上;
create index rev_stu1_index on stu1(sid) reverse ;
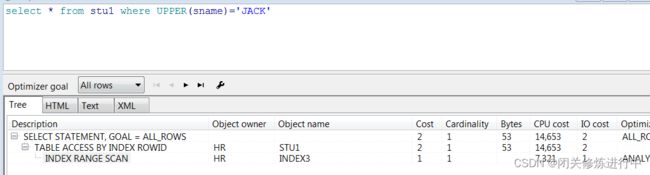
(4) 函数索引
基于一个或多个列上的函数或者表达式创建索引;表达式中不能出现聚合函数;不能在lob类型的列上创建;
创建时必须有QUERY REWRITE权限;
create index index3 on stu1(upper(sname));
1.5 和分区相关的索引(可将索引存储在不同分区中)
和分区相关的索引有三种类型:
(1) 局部分区索引:
在分区表上创建的索引,在每个表分区上创建独立的索引,索引的分区范围和表一致;
create table employee1 (code number,name varchar2(10)) partition by range (code)(
partition p1 values less than (1000),
partition p1 values less than (2000),
partition p1 values less than (maxvalue )
);
create index ind_emp on employee1(code) local ;
select u.INDEX_NAME,u.TABLE_NAME,u.PARTITIONED from USER_INDEXES u;
select * from USER_IND_PARTITIONS;
(2)全局分区索引:
在分区表和非分区表上创建的索引,索引单独指向分区的范围,与表的分区范围或者是否分区无关;
create table employee1 (code number,name varchar2(10)) partition by range (code)(
partition p1 values less than (1000),
partition p1 values less than (2000),
partition p1 values less than (maxvalue )
);
create index ind_emp on employee1(code) global partition by range (code)(partition p1 values less than (1500),
partition p1 values less than (maxvalue )) ;
select u.INDEX_NAME,u.TABLE_NAME,u.PARTITIONED from USER_INDEXES u;
(3)全局非分区索引:
在分区表上创建的全局普通索引,索引没有被分区
create table employee1 (code number,name varchar2(10)) partition by range (code)(
partition p1 values less than (1000),
partition p1 values less than (2000),
partition p1 values less than (maxvalue )
);
create index ind_emp on employee1(code) global ;
二.索引操作
2.1 创建标准索引:
create index emp_ind_1 on emp(last_name);
2.2 查看表中的索引:
select * from user_indexes ui where ui.TABLE_NAME='EMP';

2.3 查看索引信息:
select * from user_ind_columns uic where uic.INDEX_NAME='EMP_IND_1';

2.4 分析索引是否存在索引碎片:
当一个table经常进行DML操作时,它的索引会存在许多block空间的浪费,这是因为index block中的记录只有在全部表示为不可用时, block 才能被加入到freelist中去被重新利用,若存在索引碎片,表查询变慢。
通过 analyze index 分析索引的数据块是否有坏块
然后查看index_stats表中的pct_used列的值,如果pct_used的值过低,说明在索引中存在碎片,需要重建索引
测试:
create table student (sname varchar2(8));
begin
for i in 1..13000000 loop
insert into student values (ltrim(to_char(i,'00000009')));
if mod(i,100)=0 then
commit;
end if;
end loop;
end;
analyze index STU_IND validate structure ;
select s.NAME,s.PCT_USED from INDEX_STATS s where s.NAME='STU_IND';
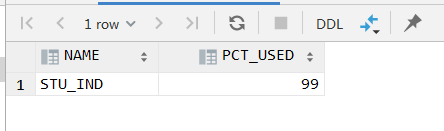
pct_used一般为90%, 默认会保留10%的空闲。
delete student where ROWNUM<3000000;
2.5 重建索引:
alter index <索引名> rebuild [ONLINE] [NOLOGGING] [COMPUTE STATISTICS]
online: 使得在重建索引过程中,用户可对原来的索引进行修改;
nologging: 表示在重建过程中产生最少的重做条目redo entry;
compute statistics : 表示在重建过程中生成了oracle优化器所需要的统计信息,
避免了索引重建之后再进行analyze或者dbms_stats来收集统计信息;
2.6 删除索引:
drop index index3;
三.执行计划(explain plan)
3.1 执行计划概念
一条查询语句在oracle中的执行过程或访问路径的描述。
3.2 如何查看执行计划
explain plan for sql语句;
或者
通过第三方工具,如plsql developer(f5查看执行计划)
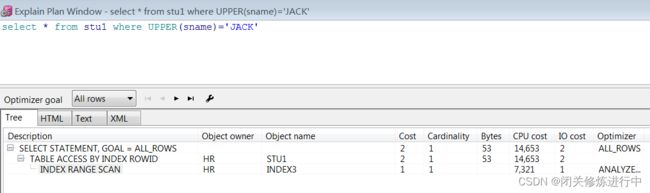
3.3 表访问方式
(1).全表扫描 TABLE ACCESS FULL
oracle顺序读取表中所有的行,并逐条匹配WHERE限定条件。采用多块读的方式进行全表扫描,可以有效提高系统的吞吐量,降低I/O次数。即使创建索引,oracle也会根据CBO的计算结果,决定是否使用索引。
注:
只有全表扫描时才可以使用多块读。该方式下,单个数据块仅访问一次。
对于数据量较大的表,不建议使用全表扫描进行访问。
当访问表中的数据量超过数据总量的5%—10%时,通常oracle会采用全表扫描的方式进行访问。
并行查询可能会导致优化器选择全表扫描的方式。
(2). 索引扫描 TABLE ACCESS BY ROWID
ORACLE在访问目标表数据时,直接通过数据所在的ROWID(与ORACLE中数据块里的行记录一一对应)去定位并访问相关数据。
index unique scan --索引唯一扫描
针对唯一性索引(UNIQUE INDEX)的扫描,它仅仅适用于WHERE条件里是等值查询的目标SQL。因为扫描对象是唯一性索引,所以结果至多只会返回一条记录。
index range scan --索引范围扫描
当扫描的对象是唯一性索引时,此时目标SQL的WHERE条件一定是范围查询(between,<,>等);当扫描对象是非唯一性索引时,对目标SQL的WHERE条件没有限制(可以是等值查询,也可以是范围查询)。索引范围扫描的结果可能会返回多条记录。
index full scan --索引全扫描
索引全扫描的执行结果也是有序的,并且是按照该索引键值列来排序,这也意味着走索引全扫描能够既达到排序的效果,又同时避免了对该索引的索引键值列真正排序操作。简单来说就是通过索引全扫描查出来的数据都是排序好的。
ORACLE能走索引全扫描的前提条件是目标索引至少有一个索引键值列的属性是NOT NULL,如果空还走索引全扫描的话会遗漏目标表中那些索引键值列均为NULL的记录。
index fast full scan --索引快速全局扫描
索引快速全扫描只适用于CBO;
索引快速全扫描可以使用多块读,也可以并行执行。
索引快速全扫描执行结果不一定有序的。
这是因为索引快速扫描时oracle是根据索引行在磁盘上的物理存储顺序来扫描,而不是根据索引行的逻辑顺序来扫描的,所以扫描结果才不一定有序。(对于单个索引叶子块中索引而言,其物理存储顺序与逻辑存储顺序一直,但对于物理存储位置相邻的所有叶子块而言,块与块之间索引行的物理存储顺序不一定在逻辑上有序)
index skip scan --索引跳跃扫描
ORACLE中的索引跳跃式扫描仅仅适用于那些目标索引前导列的DISTINCT值数量较少,后续非前导列的可选择性又非常好的情形,所以索引跳跃式扫描的执行效率一定会随着目标索引前导列的DISTINCT值数量递增而递减。
注:
oracle优化器(Optimizer)
Oracle 数据库中优化器(Optimizer)是SQL分析和执行的优化工具,它负责指定SQL的执行计划,也就是它负责保证SQL执行的效率最高。
比如优化器决定Oracle 以什么样的方式来访问数据,是全表扫描(Full Table Scan),索引范围扫描(Index Range Scan)还是全索引快速扫描(INDEX Fast Full Scan:INDEX_FFS);
对于表关联查询,它负责确定表之间以一种什么方式来关联,比如HASH_JOHN还是NESTED LOOPS 或者MERGE JOIN。
这些因素直接决定SQL的执行效率,所以优化器是SQL 执行的核心,它做出的执行计划好坏,直接决定着SQL的执行效率。
Oracle 的优化器有两种:
RBO(Rule-Based Optimization): 基于规则的优化器
CBO(Cost-Based Optimization): 基于代价的优化器
从Oracle 10g开始,RBO 已经被弃用,使用CBO优化器