【分布式系统】分布式唯一ID生成方案总结
目录
- UUID
-
- 实现
- 数据库生成ID
- segment号段模式
- 美团Leaf-segment号段模式
- Redis生成ID
-
- 实现
- zookeeper生成ID
-
- 实现
- snowflake雪花算法
-
- 实现
- Leaf-snowflake雪花算法
- 百度UidGenerator
- 滴滴TinyID
-
- 双号段缓存
- 多DB支持
- tinyid-client
- 参考
UUID
基本方法之一。
UUID(Universally Unique Identifier),全局唯一标识符。UUID是国际标准化组织(ISO)提出的一个概念,是指在一台机器上生成的数字,它保证对在同一时空中的所有机器都是唯一的。
按照开放软件基金会(OSF)制定的标准计算,UUID基于当前时间、计数器(counter)和硬件标识(通常为无线网卡的MAC地址)等数据计算生成的。每台服务器的MAC地址和网卡地址肯定不一样,所以就算同一时间生成的ID也会有所不同。
实现
Java实现如下:
public static void func1() {
String uuid = UUID.randomUUID().toString();
System.out.println(uuid);
}

运行结果:

优点:
1)性能好,本地生成,不依赖网络
缺点:
1)不单调递增
2)不易存储,UUID太长,16字节128位(通常以36长度的字符串表示)
3)不安全,基于MAC地址生成UUID可能会造成MAC地址泄露,这个漏洞曾被用于寻找梅丽莎病毒的制作者位置。
数据库生成ID
基本方法之一。

在一个单例MySQL中,可以使用auto_increment自增主键ID作为全局分布式服务ID,但是这种方式风险很大。
多机多实例情况下,可以利用给字段设置auto_increment_increment和auto_increment_offset来保证ID自增:
auto_increment_offset,表示从哪个数开始自增,取值范围是1 … 65535。
auto_increment_increment,表示每次自增的量,其默认值是1,取值范围是1 … 65535。
如果多个库则每个库设置的起始数字不一样,步长一样,其中步长可以是库的个数。
比如有三个机器:
DB1 的auto_increment_offset为1,auto_increment_increment为3,生成的是 1,4,7,10。
DB2 的auto_increment_offset为2,auto_increment_increment为3,生成的是2,5,8,11。
DB3的auto_increment_offset为3,auto_increment_increment为3,生成的是3,6,9,12。
优点:
实现简单,ID单调自增,成本小
缺点:
系统不能水平扩展
ID生成的性能瓶颈限制在单台DB的读写性能
segment号段模式
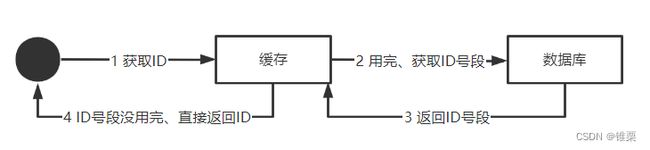
数据库生成的方式,每次获取ID时都需要直接访问数据库,效率较低,如果能够一次获取大量的ID,并将其缓存在本地,那样就可以大大的提升ID获取的效率,这也是号段模式的核心思想。
号段模式每次从数据库中批量的获取一批自增ID给号段服务维护。例如(1,2000]即代表着2000个ID。业务系统只需要到号段服务中申请ID,不需要每次都去请求数据库,所有ID用完之后,才会去申请下一个号段。
号段服务不再强依赖数据库,即使数据库不可用,号段服务也可以继续工作直到申请的ID全部使用完。但是如果此时号段服务重启,就会导致剩余的ID丢失。
为了保证号段服务的高可用,可能需要建立一个集群,在请求方从号段服务获取ID时,就会随机的选取一个节点来获取,而这种并发场景下同样需要考虑到并发安全的问题,可以使用乐观锁来进行并发的控制。
美团Leaf-segment号段模式

Leaf-segment号段模式基于原有的号段模式。将使用数据库的方案,改为利用proxy server批量获取,每次获取一个segment(step决定大小)号段的值。用完之后再去数据库获取新的号段,减轻数据库的压力。
各个业务不同的发号需求用biz_tag字段来区分,每个biz-tag的ID获取相互隔离,互不影响。如果以后有性能需求需要对数据库扩容,不需要上述描述的复杂的扩容操作,只需要对biz_tag分库分表就行。
数据库表设计如下:

其中,biz_tag用于区分业务,max_id表示该biz_tag目前所被分配的ID号段的最大值,step表示每次分配的号段长度。
原来获取ID每次都需要写数据库,现在只需要把step设置得足够大,比如1000。那么只有当1000个号被消耗完了之后才会去重新读写一次数据库。读写数据库的频率从1减小到了1/step。
架构如下:
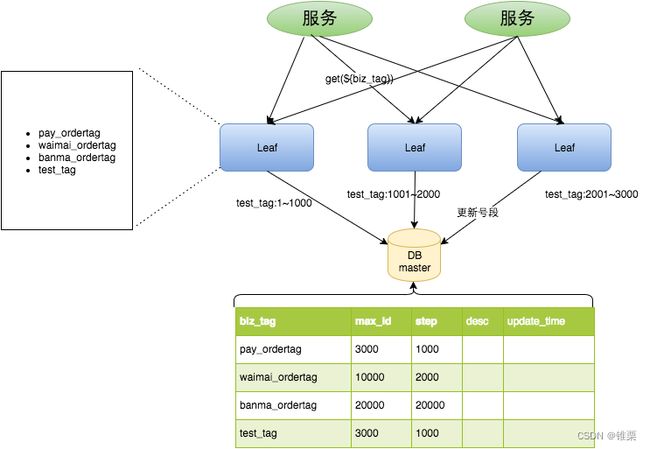
此外该模式还对性能和服务容错做了一些优化,详情可见 https://tech.meituan.com/2017/04/21/mt-leaf.html
Redis生成ID
基本方法之一。
Redis性能由于数据库,并且是单线程的,可以借助Redis的原子操作INCR或INCRBY命令,来获取全局递增的序列号,作为分布式ID。
考虑到Redis的持久化RDB和AOF,可能还会出现一些问题:
RDB定时持久化数据库状态的快照。如果在自增生成分布式ID的过程中,还没来得及持久化,Redis就挂了,再次重启Redis可能会遇到ID重复的问题。
AOF对Redis执行的每条写命令进行持久化来记录数据库状态。Redis挂了重启ID也不会重复,但是INCR性能不高,所以启动时间会较长。
优点:
1)使用内存,性能好
2)ID可以单调递增
缺点:
1)redis 挂了后不可用
2)RDB重启数据丢失会重复ID
3)额外引入Redis增加系统复杂性
实现
我们有代码实现如下:
其中所要用到的依赖:
<parent>
<groupId>org.springframework.bootgroupId>
<artifactId>spring-boot-starter-parentartifactId>
<version>2.3.7.RELEASEversion>
<relativePath/>
parent>
<dependencies>
省略 。。。。。
<dependency>
<groupId>org.springframework.bootgroupId>
<artifactId>spring-boot-starter-data-redisartifactId>
dependency>
<dependency>
<groupId>redis.clientsgroupId>
<artifactId>jedisartifactId>
dependency>
dependencies>
注意,需要求电脑中安装并启动了Redis服务,否则下面代码没法建立连接诶。
RedisIdGeneratorTests.java
import org.junit.Test;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.boot.test.context.SpringBootTest;
import org.springframework.data.redis.connection.RedisStandaloneConfiguration;
import org.springframework.data.redis.connection.jedis.JedisConnectionFactory;
import org.springframework.data.redis.core.RedisTemplate;
import org.springframework.data.redis.serializer.StringRedisSerializer;
import org.springframework.stereotype.Component;
import java.time.LocalDateTime;
import java.time.ZoneOffset;
import java.time.format.DateTimeFormatter;
@SpringBootTest
@Component
public class RedisIdGeneratorTests {
/**
* 开始时间戳
*/
private static final long BEGIN_TIMESTAMP = 1640995200L;
/**
* 序列号的位数
*/
private static final int COUNT_BITS = 32;
@Autowired
private final RedisTemplate<String, Long> template;
public RedisIdGeneratorTests() {
//单机模式
RedisStandaloneConfiguration rsc = new RedisStandaloneConfiguration();
rsc.setPort(6379);
// rsc.setPassword("");
rsc.setHostName("localhost");
//单机模式
JedisConnectionFactory fac = new JedisConnectionFactory(rsc);
this.template = new RedisTemplate<>();
template.setDefaultSerializer(new StringRedisSerializer());
template.setConnectionFactory(fac);
template.afterPropertiesSet();
}
public long nextId(String keyPrefix) throws Exception {
// 1. 生成时间戳
LocalDateTime now = LocalDateTime.now();
long nowSecond = now.toEpochSecond(ZoneOffset.UTC);
long timestamp = nowSecond - BEGIN_TIMESTAMP;
// 2. 生成序列号
// 2.1 获取当前日期,精确到天
String date = now.format(DateTimeFormatter.ofPattern("yyyy:MM:dd"));
// 2.2 获取redis自增长值
long increment = template.opsForValue().increment("id:" + keyPrefix + ":" + date);
// 3. 拼接并返回
return increment << COUNT_BITS | timestamp;
}
@Test
public void getId() throws Exception {
String keyPrefix = "HUMAN_PEACE";
long l1 = nextId(keyPrefix);
System.out.println(l1);
long l2 = nextId(keyPrefix);
System.out.println(l2);
}
}
运行后有:
20:41:57.566 [main] DEBUG org.springframework.data.redis.core.RedisConnectionUtils - Opening RedisConnection
20:41:57.748 [main] DEBUG org.springframework.data.redis.core.RedisConnectionUtils - Closing Redis Connection.
8635455509
20:41:57.750 [main] DEBUG org.springframework.data.redis.core.RedisConnectionUtils - Opening RedisConnection
20:41:57.751 [main] DEBUG org.springframework.data.redis.core.RedisConnectionUtils - Closing Redis Connection.
12930422805
可以看到生成并打印了ID。
zookeeper生成ID
基本方法之一。
zookeeper主要通过其znode数据版本来生成序列号,可以生成32位和64位的数据版本号,客户端可以使用这个版本号来作为唯一的序列号。
一般很少会使用zookeeper来生成唯一ID。主要是由于需要依赖zookeeper,并且是多步调用API,如果在竞争较大的情况下,需要考虑使用分布式锁。因此,这样的性能在高并发的分布式环境下也不太理想。
实现
我们先使用zookeeper 客户端创建结点(安装使用zookeeper可以见【zookeeper】windows版zookeeper安装与启动 可能遇到的各种问题
):

create /test ok
项目代码中引入依赖:
省略。。。。。
<parent>
<groupId>org.springframework.bootgroupId>
<artifactId>spring-boot-starter-parentartifactId>
<version>2.3.7.RELEASEversion>
<relativePath/>
parent>
<dependencies>
<dependency>
<groupId>org.springframework.bootgroupId>
<artifactId>spring-boot-starter-webartifactId>
dependency>
<dependency>
<groupId>org.springframework.bootgroupId>
<artifactId>spring-boot-starter-web-servicesartifactId>
dependency>
省略 。。。。
<dependency>
<groupId>junitgroupId>
<artifactId>junitartifactId>
<scope>testscope>
dependency>
<dependency>
<groupId>org.apache.curatorgroupId>
<artifactId>curator-frameworkartifactId>
<version>4.3.0version>
dependency>
<dependency>
<groupId>org.apache.curatorgroupId>
<artifactId>curator-recipesartifactId>
<version>4.3.0version>
dependency>
<dependency>
<groupId>org.apache.zookeepergroupId>
<artifactId>zookeeperartifactId>
<version>3.4.14version>
<exclusions>
<exclusion>
<groupId>org.slf4jgroupId>
<artifactId>slf4j-log4j12artifactId>
exclusion>
exclusions>
dependency>
dependencies>
注意这里curator和zookeeper的版本不匹配将可能报错。
我们有代码如下:
CuratorDemoApplicationTests.java
import org.apache.curator.RetryPolicy;
import org.apache.curator.framework.CuratorFramework;
import org.apache.curator.framework.CuratorFrameworkFactory;
import org.apache.curator.retry.RetryOneTime;
import org.apache.zookeeper.CreateMode;
import org.junit.Test;
import org.springframework.boot.test.context.SpringBootTest;
import org.springframework.stereotype.Component;
@SpringBootTest
@Component
public class CuratorDemoApplicationTests {
// RetryOneTime:{参数1}毫秒后重连,只重连一次
private final RetryPolicy retryOneTime = new RetryOneTime(3000);
@Test
public void contextLoads() throws Exception {
// 获取客户端
CuratorFramework client = CuratorFrameworkFactory.builder()
// Zookeeper 服务器地址字符串
.connectString("localhost:2181")
// session 会话超时时间
.sessionTimeoutMs(5000)
// 使用哪种重连策略
.retryPolicy(retryOneTime)
// 配置父节点
.namespace("test")
.build();
// 开启会话
client.start();
// 第一次创建 /ok-
String s = client.create().
creatingParentsIfNeeded().
withMode(CreateMode.PERSISTENT_SEQUENTIAL).
forPath("/ok-");
// 输出第一次创建的
System.out.println(s);
// 第二次创建 /ok-
String s1 = client.create().
creatingParentsIfNeeded().
withMode(CreateMode.PERSISTENT_SEQUENTIAL).
forPath("/ok-");
// 输出第二次创建的
System.out.println(s1);
// 第三次创建 /ok-
String s2 = client.create().
creatingParentsIfNeeded().
withMode(CreateMode.PERSISTENT_SEQUENTIAL).
forPath("/ok-");
// 输出第三次创建的
System.out.println(s2);
// 关闭客户端
client.close();
}
}
运行这个测试模块,可以看到输出有:
11:35:57.056 [main-SendThread(localhost:2181)] DEBUG org.apache.zookeeper.ClientCnxn - Reading reply sessionid:0x10028fba3e90006, packet:: clientPath:null serverPath:null finished:false header:: 2,1 replyHeader:: 2,207,0 request:: '/test/ok-,#3139322e3136382e31302e31,v{s{31,s{'world,'anyone}}},2 response:: '/test/ok-0000000000
/ok-0000000000
11:35:57.080 [main-SendThread(localhost:2181)] DEBUG org.apache.zookeeper.ClientCnxn - Reading reply sessionid:0x10028fba3e90006, packet:: clientPath:null serverPath:null finished:false header:: 3,1 replyHeader:: 3,208,0 request:: '/test/ok-,#3139322e3136382e31302e31,v{s{31,s{'world,'anyone}}},2 response:: '/test/ok-0000000001
/ok-0000000001
11:35:57.105 [main-SendThread(localhost:2181)] DEBUG org.apache.zookeeper.ClientCnxn - Reading reply sessionid:0x10028fba3e90006, packet:: clientPath:null serverPath:null finished:false header:: 4,1 replyHeader:: 4,209,0 request:: '/test/ok-,#3139322e3136382e31302e31,v{s{31,s{'world,'anyone}}},2 response:: '/test/ok-0000000002
/ok-0000000002
11:35:57.105 [main] DEBUG org.apache.curator.framework.imps.CuratorFrameworkImpl - Closing
可以看到生成并打印了ID。
snowflake雪花算法
基本方法之一。
雪花算法是Twitter提出的一种生成分布式ID策略,此算法生成的是一个64bit(8字节)的ID,在Java中使用8字节的long来存放。

如上图
第1位:用1bit,其值始终是0,确保ID是正数。
时间戳位:占41bit,精确到毫秒,总共可以容纳约69年的时间。
工作机器id位:占10bit,其中高位5bit是数据中心ID,低位5bit是工作节点ID,最多可以容纳1024个节点。
自增序列号位:占用12bit,每个节点每毫秒从0开始不断累加,最多可以累加到4095,一共可以产生4096个ID,理论上1毫秒内能够产生的最大数量也是这4096。
所以理论上snowflake方案的QPS约为409.6万(4096 * 1000),这种分配方式可以保证在任何一个IDC的任何一台机器在任意毫秒内生成的ID都是不同的。
优点:
1)ID有递增趋势。
2)不依赖数据库 redis 等第三方,灵活方便,性能非常高。
3)可根据自身业务分配bit位,兼具灵活性。
缺点:
1)依赖机器时钟,如果机器时钟回拨,会导致生成重复ID
2)在单机上递增,但是由于涉及到分布式环境,每台机器上的时钟不可能完全同步,有时做不到全局递增(但是一般分布式ID只要求递增趋势,并不严格要求递增)
实现
代码实现如下:
import org.springframework.util.Assert;
public class IdWorker {
/**
* 这两个参数可以读取配置文件
* 这里默认写死
*
* @param workerId 机器标识
* @param datacenterId 数据标识
*/
private static SnowflakeIdWorker worker = new SnowflakeIdWorker(0, 0);
/**
* Twitter的分布式自增ID算法snowflake
*/
public static class SnowflakeIdWorker {
/**
* 第1部分(41位)
* 开始时间截 (2022-04-01)
*/
private final long startTime = 1648742400000L;
/**
* 第2部分(10位)
* 机器id所占的位数
*/
private final long workerIdBits = 5L;
/**
* 数据标识id所占的位数
*/
private final long datacenterIdBits = 5L;
/**
* 第3部分(12位)
* 序列在id中占的位数
*/
private final long sequenceBits = 12L;
/**
* -1L ^ (-1L << 5) = 31
* 支持的最大机器id,结果是31
*/
private final long maxWorkerId = -1L ^ (-1L << workerIdBits);
/**
* -1L ^ (-1L << 5) = 31
* 支持的最大数据标识id,结果是31
*/
private final long maxDatacenterId = -1L ^ (-1L << datacenterIdBits);
/**
* -1L ^ (-1L << 12) = 4095
* 自增长最大值4095,0开始
*/
private final long sequenceMask = -1L ^ (-1L << sequenceBits);
/**
* 时间截向左移22位(5+5+12)
*/
private final long timestampLeftShift = sequenceBits + workerIdBits + datacenterIdBits;
/**
* 数据标识id向左移17位(12+5)
*/
private final long datacenterIdShift = sequenceBits + workerIdBits;
/**
* 机器ID向左移12位
*/
private final long workerIdShift = sequenceBits;
/**
* 工作机器ID(0~31)
*/
private long workerId;
/**
* 数据中心ID(0~31)
*/
private long datacenterId;
/**
* 1毫秒内序号(0~4095)
*/
private long sequence = 0L;
/**
* 上次生成ID的时间截
*/
private long lastTimestamp = -1L;
/**
* 构造函数
*
* @param workerId 工作ID (0~31)
* @param datacenterId 数据中心ID (0~31)
*/
public SnowflakeIdWorker(long workerId, long datacenterId) {
if (workerId > maxWorkerId || workerId < 0) {
throw new IllegalArgumentException(String.format("worker Id can't be greater than %d or less than 0", maxWorkerId));
}
if (datacenterId > maxDatacenterId || datacenterId < 0) {
throw new IllegalArgumentException(String.format("datacenter Id can't be greater than %d or less than 0", maxDatacenterId));
}
this.workerId = workerId;
this.datacenterId = datacenterId;
}
/**
* 获得下一个ID (该方法是线程安全的)
*
* @return SnowflakeId
*/
public synchronized long nextId() {
long timestamp = timeGen();
// 如果当前时间小于上一次ID生成的时间戳,说明系统时钟回退过这个时候应当抛出异常
if (timestamp < lastTimestamp) {
throw new RuntimeException(String.format("Clock moved backwards.Refusing to generate id for %d milliseconds", lastTimestamp - timestamp));
}
// 如果是同一时间生成的,则进行毫秒内序列
if (lastTimestamp == timestamp) {
sequence = (sequence + 1) & sequenceMask;
// 毫秒内序列溢出
//sequence == 0 ,就是1毫秒用完了4096个数
if (sequence == 0) {
// 阻塞到下一个毫秒,获得新的时间戳
timestamp = tilNextMillis(lastTimestamp);
}
}
// 时间戳改变,毫秒内序列重置
else {
sequence = 0L;
}
// 上次生成ID的时间截
lastTimestamp = timestamp;
// 移位并通过或运算拼到一起组成64位的ID
return ((timestamp - startTime) << timestampLeftShift) // 时间戳左移22位
| (datacenterId << datacenterIdShift) //数据标识左移17位
| (workerId << workerIdShift) //机器id标识左移12位
| sequence;
}
/**
* 阻塞到下一个毫秒,直到获得新的时间戳
*
* @param lastTimestamp 上次生成ID的时间截
* @return 当前时间戳
*/
protected long tilNextMillis(long lastTimestamp) {
long timestamp = timeGen();
while (timestamp <= lastTimestamp) {
timestamp = timeGen();
}
return timestamp;
}
/**
* 返回以毫秒为单位的当前时间
*
* @return 当前时间(毫秒)
*/
protected long timeGen() {
return System.currentTimeMillis();
}
}
public static long id() {
Assert.notNull(worker, "SnowflakeIdWorker未配置!");
return worker.nextId();
}
public static void main(String[] args) {
long id = id();
System.out.println(id);
}
}
运行:
158333034955800576
可以看到生成并打印了ID。
Leaf-snowflake雪花算法
Leaf这个名字来自莱布尼茨的一句话:“世界上没有两片相同的树叶。Leaf-snowflake是美团基于snowflake雪花算法进一步优化后的算法,结构如下图:

由于Leaf服务规模大,对于机器ID来说动手配置成本高,因此使用zookeeper持久节点自动配置workerID:
1)启动Leaf-snowflake服务,连接zookeeper,在leaf_forever父节点下检查自己是否已经注册过(是否有该顺序子节点)。
2)如果有注册过直接取回自己的workerID(zk顺序节点生成的int类型ID号),启动服务。
3)如果没有注册过,就在该父节点下面创建一个持久顺序节点,创建成功后取回顺序号当做自己的workerID号,启动服务。

使用zookeeper同时,本机也会缓存一个workerID文件。当zookeeper出现问题,恰好机器出现问题需要重启时,能保证服务能正常启动,做到了对三方组件的弱依赖。
因为这种方案依赖时间,如果机器的时钟发生了回拨,那么就会有可能生成重复的ID号,需要解决时钟回退的问题,如下:

百度UidGenerator
UidGenerator是百度开源的Java实现的基于雪花算法的分布式唯一ID生成器

CachedUidGenerator是一种缓存型的ID生成方式,当剩余ID不足的时候,会异步的方式重新生成一批ID缓存起来,后续请求的时候直接返回现成的ID即可。
CachedUidGenerator采用了双RingBuffer,Uid-RingBuffer用于存储Uid、Flag-RingBuffer用于存储Uid状态(是否可填充、是否可消费)
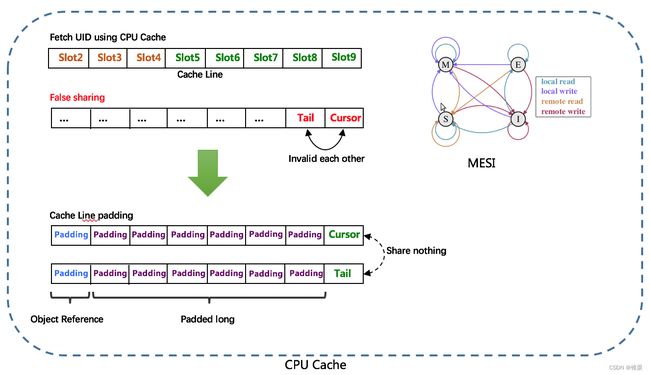
RingBuffer环形数组,数组每个元素成为一个slot。RingBuffer容量,默认为Snowflake算法中sequence最大值,且为2^N。可通过boostPower配置进行扩容,以提高RingBuffer 读写吞吐量。
Tail指针、Cursor指针用于环形数组上读写slot:
Tail指针:表示Producer生产的最大序号(此序号从0开始,持续递增)。Tail不能超过Cursor,即生产者不能覆盖未消费的slot。当Tail已赶上curosr,此时可通过rejectedPutBufferHandler指定PutRejectPolicy
Cursor指针:表示Consumer消费到的最小序号(序号序列与Producer序列相同)。Cursor不能超过Tail,即不能消费未生产的slot。当Cursor已赶上tail,此时可通过rejectedTakeBufferHandler指定TakeRejectPolicy

由于数组元素在内存中是连续分配的,可最大程度利用CPU cache以提升性能。但同时会带来「伪共享」FalseSharing问题,为此在Tail、Cursor指针、Flag-RingBuffer中采用了CacheLine 补齐方式。
RingBuffer填充时机
初始化预填充:RingBuffer初始化时,预先填充满整个RingBuffer.
即时填充:Take消费时,即时检查剩余可用slot量(tail - cursor),如小于设定阈值,则补全空闲slots。阈值可通过paddingFactor来进行配置,请参考Quick Start中CachedUidGenerator配置
周期填充:通过Schedule线程,定时补全空闲slots。可通过scheduleInterval配置,以应用定时填充功能,并指定Schedule时间间隔
滴滴TinyID
Tinyid是滴滴开发的Java实现的一款分布式ID系统,是在美团的Leaf-segment算法基础上升级而来,不仅支持了数据库多主节点模式,还提供了tinyid-client客户端的接入方式,使用起来更加方便。但TinyID只支持号段模式,不支持雪花模式。

其架构如上图,下面简述一下其优化点:
双号段缓存
Tinyid会在首次获取ID时,将可用号段加载到内存中,并在内存中生成ID。如当前号段使用达到一定比例时,系统会异步的去加载下一个可用号段,以此保证内存中始终有可用号段,以便在发号服务宕机后一段时间内还有可用ID。
多DB支持
DB只有一个master时,如果DB不可用,则获取号段不可用。实际上可以支持多个DB,比如2个DB,A和B,获取号段可以随机从其中一台上获取。那么如果A,B都获取到了同一号段,我们怎么保证生成的id不重呢?tinyid是这么做的,让A只生成偶数id,B只生产奇数id,对应的db设计增加了两个字段,如下所示

delta代表id每次的增量,remainder代表余数,例如可以将A,B都delta都设置2,remainder分别设置为0,1则,A的号段只生成偶数号段,B是奇数号段。通过delta和remainder两个字段我们可以根据使用方的需求灵活设计DB个数,同时也可以为使用方提供只生产类似奇数的id序列。
tinyid-client
使用http获取一个id,存在网络开销,是否可以本地生成id?为此TinyID提供了tinyid-client,可以向tinyid-server发送请求来获取可用号段,之后在本地构建双号段、id生成,如此id生成则变成纯本地操作,性能大大提升,因为本地有双号段缓存,则可以容忍tinyid-server一段时间的down掉,可用性也有比较大的提升。
参考
https://tech.meituan.com/2017/04/21/mt-leaf.html
https://blog.csdn.net/qq_34677946/article/details/122295328
https://gitee.com/mirrors/UidGenerator
https://blog.csdn.net/minkeyto/article/details/104944186
https://blog.csdn.net/lianggzone/article/details/107625076