SPARK SQL中 CTE(with表达式)会影响性能么?
背景及问题
本文基于spark 3.1.2
最近在排查spark sql问题的时候,出现了一系列的(CTE)with操作,导致该任务运行不出来,而把对应的(CTE)with 替换成了临时表以后,任务很快的就能运行出来
对应的最简化的sql如下:
with temp1 as (
select
null as user_id
,a.sku_id
from xxx.xxx `a`
where pt between '20211228' and '20220313'
group by
a.sku_id),
temp2 as (
select
a.xxx_code user_id
,a.sku_id
from xxx.xxx_1`a`
left join xxx.xxx_2 `c` on c.pt='20220313' and a.xxx_code=c.xxx_code and c.xxx_id=1
where a.pt='20220313'
and TO_CHAR(upper_time,'yyyymmdd') >= '20220230'
group by
a.xxx_code
,a.sku_id)
select
*
from (
select
a1.sku_id,
a1.user_id
from temp1 `a1`
-- BroadcastNestedLoopJoin
full join temp2 `a5` on a1.user_id=a5.user_id and a1.sku_id=a5.sku_id
);
先说结论,其实是null as user_id 这块代码在作为join条件的时候被优化成布尔表达式false
分析
运行此sql,我们可以得到一下的物理计划:
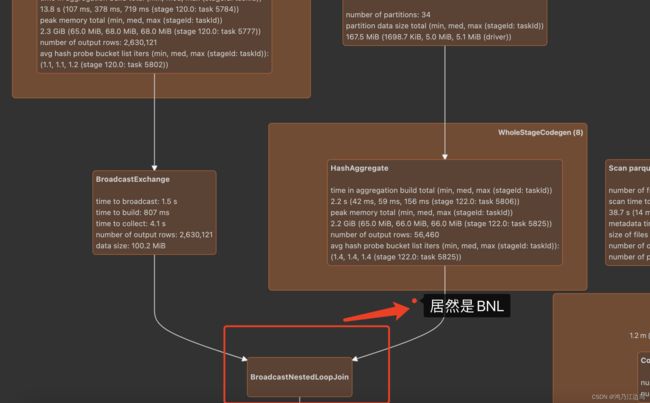
我们看到 temp1和temp2的join的居然是BroadcastNestedLoopJoin,要知道BroadcastNestedLoopJoin的时间复杂度是O(M*N)的,这在数据大的情况下是很难计算出来的。
并且我们查看对应的代码JoinSelection.scala的时候,发现对于有等值条件的join的情况下,而且join的条件是可排序的情况下,最次也是会变成SortMergeJoin,对应的代码如下:
def createJoinWithoutHint() = {
createBroadcastHashJoin(false)
.orElse {
if (!conf.preferSortMergeJoin) {
createShuffleHashJoin(false)
} else {
None
}
}
.orElse(createSortMergeJoin())
.orElse(createCartesianProduct())
.getOrElse {
// This join could be very slow or OOM
val buildSide = getSmallerSide(left, right)
Seq(joins.BroadcastNestedLoopJoinExec(
planLater(left), planLater(right), buildSide, joinType, nonEquiCond))
}
}
这部分的代码比较简单,暂且跳过。
就在百思不得其解的时候,还是最重要的一步,查看对应的逻辑计划日志:
直接重点(我们这里只说join条件部分的变化):
- 解析完后的初始计划 为
Join FullOuter, (('a1.user_id = 'a5.user_id) AND ('a1.sku_id = 'a5.sku_id))
- 经过PromoteStrings规则
Join FullOuter, ((user_id#3 = user_id#13) AND (sku_id#15 = sku_id#98))
||
\/
Join FullOuter, ((null = user_id#13) AND (sku_id#15 = sku_id#98))
- 经过NullPropagation规则
Join FullOuter, ((null = user_id#13) AND (sku_id#15 = sku_id#98))
||
\/
Join FullOuter, (null AND (sku_id#15 = sku_id#98))
- 经过ReplaceNullWithFalseInPredicate规则
Join FullOuter, (null AND (sku_id#15 = sku_id#98))
||
\/
Join FullOuter, (false AND (sku_id#15 = sku_id#98))
- 经过BooleanSimplification规则
Join FullOuter, (false AND (sku_id#15 = sku_id#98))
||
\/
Join FullOuter, false
这样一步一步下来,其实最终的join条件就变成了 布尔表达式 false。
我们再看JoinSelection.scala 中join对应非等值条件case的判断:
case logical.Join(left, right, joinType, condition, hint) =>
val desiredBuildSide = if (joinType.isInstanceOf[InnerLike] || joinType == FullOuter) {
getSmallerSide(left, right)
} else {
// For perf reasons, `BroadcastNestedLoopJoinExec` prefers to broadcast left side if
// it's a right join, and broadcast right side if it's a left join.
// TODO: revisit it. If left side is much smaller than the right side, it may be better
// to broadcast the left side even if it's a left join.
if (canBuildBroadcastLeft(joinType)) BuildLeft else BuildRight
}
...
def createJoinWithoutHint() = {
createBroadcastNLJoin(canBroadcastBySize(left, conf), canBroadcastBySize(right, conf))
.orElse(createCartesianProduct())
.getOrElse {
// This join could be very slow or OOM
Seq(joins.BroadcastNestedLoopJoinExec(
planLater(left), planLater(right), desiredBuildSide, joinType, condition))
}
}
createBroadcastNLJoin(hintToBroadcastLeft(hint), hintToBroadcastRight(hint))
.orElse { if (hintToShuffleReplicateNL(hint)) createCartesianProduct() else None }
.getOrElse(createJoinWithoutHint())
最终还是会调用createJoinWithoutHint生成BroadcastNestedLoopJoinExec。
解决方法及总结
- 改写成临时表
把with改写成临时表,这是有益处的,因为在某些场景下会触发到AQE中的特性,而且改写成临时表后,任务是串行的,能够减少因为资源问题导致的任务运行缓慢问题(笔者曾经有遇到过)
注意:改成临时表的情况下,不能存在null as user_id的语句,否则会报错:Caused by: org.apache.spark.sql.AnalysisException: Cannot create tables with null type. - 把
null as user_id改写成0 as user_id
根据之前的分析,导致变成BroadcastNestedLoopJoinExec的原因是null作为了join条件引发的,我们可以改写就好
其实CTE操作并不是影响性能的主要原因,主要原因还是在于spark对于某种case的处理,这种还会得具体case具体分析处理。
当然也可以参考Why is my CTE so slow?.