[力扣刷题总结](链表篇)
文章目录
- 2. 两数相加
-
- 解法1:链表
- 相似题目:445. 两数相加 II
-
- 解法1:栈+链表
- 206. 反转链表
-
- 解法1:栈实现
- 解法2:双指针-迭代
- 解法3:双指针-递归
- 92. 反转链表 II
-
- 解法1:一次遍历「穿针引线」反转链表(头插法)
- 203. 移除链表元素
-
- 解法1:链表-迭代
- 解法1:链表-递归
- 61. 旋转链表
-
- 解法1:链表
- 相似题目:剑指 Offer 22. 链表中倒数第k个节点
-
- 解法1:链表
- 725. 分隔链表
-
- 解法1:链表
- 相似题目:328. 奇偶链表
-
- 解法1:链表
- 86. 分隔链表
-
- 解法1:虚拟节点+链表指针
- 25. K 个一组翻转链表
-
- 解法1:链表+模拟
- 24. 两两交换链表中的节点
-
- 解法1:链表
- 148. 排序链表
-
- 解法1:链表+归并排序+递归
- 解法2:链表+归并排序+迭代
- 相似题目:147. 对链表进行插入排序
-
- 解法1:链表 +插入排序
- 83. 删除排序链表中的重复元素
-
- 解法1:链表
- 相似题目:82. 删除排序链表中的重复元素 II
-
- 解法1:链表+双指针
- 138. 复制带随机指针的链表
-
- 解法1:哈希表+链表
- 相似题目:133. 克隆图
-
- 解法1:哈希表+BFS
- 解法2:哈希表+DFS
- 160. 相交链表
-
- 双指针
- 21. 合并两个有序链表
-
- 解法1:递归
- 解法2:迭代
- 23. 合并K个升序链表
-
- 解法1:分治
- 解法2:两两合并
- 解法3:最小堆
- 19. 删除链表的倒数第 N 个结点
-
- 解法1:计算链表长度
- 解法2:快慢指针
- 234. 回文链表
-
- 解法1:双指针
- 剑指 Offer 36. 二叉搜索树与双向链表
-
- 解法1:dfs
- HJ51 输出单向链表中倒数第k个结点
-
- 解法1:快慢指针
2. 两数相加
力扣连接
给你两个 非空 的链表,表示两个非负的整数。它们每位数字都是按照 逆序 的方式存储的,并且每个节点只能存储 一位 数字。
请你将两个数相加,并以相同形式返回一个表示和的链表。
你可以假设除了数字 0 之外,这两个数都不会以 0 开头。
示例 1:
_第1张图片](http://img.e-com-net.com/image/info8/47595feb61bd45f7bbd98542a9a964c9.jpg)
输入:l1 = [2,4,3], l2 = [5,6,4]
输出:[7,0,8]
解释:342 + 465 = 807.
示例 2:
输入:l1 = [0], l2 = [0]
输出:[0]
示例 3:
输入:l1 = [9,9,9,9,9,9,9], l2 = [9,9,9,9]
输出:[8,9,9,9,0,0,0,1]
提示:
每个链表中的节点数在范围 [1, 100] 内
0 <= Node.val <= 9
题目数据保证列表表示的数字不含前导零
解法1:链表
代码:
/**
* Definition for singly-linked list.
* struct ListNode {
* int val;
* ListNode *next;
* ListNode() : val(0), next(nullptr) {}
* ListNode(int x) : val(x), next(nullptr) {}
* ListNode(int x, ListNode *next) : val(x), next(next) {}
* };
*/
class Solution {
public:
ListNode* addTwoNumbers(ListNode* l1, ListNode* l2) {
ListNode* res = new ListNode();
ListNode* p = res;
int t = 0;
while(l1!=nullptr || l2!=nullptr || t!=0 ){
if(l1){
t+=l1->val;
l1 = l1->next;
}
if(l2){
t+=l2->val;
l2 = l2->next;
}
p->next = new ListNode(t%10);
p = p->next;
t/=10;
}
return res->next;
}
};
复杂度分析:
时间复杂度:O(max(m,n)),其中 m 和 n 分别为两个链表的长度。我们要遍历两个链表的全部位置,而处理每个位置只需要O(1) 的时间。
空间复杂度:O(1)。注意返回值不计入空间复杂度。
相似题目:445. 两数相加 II
力扣链接
给你两个 非空 链表来代表两个非负整数。数字最高位位于链表开始位置。它们的每个节点只存储一位数字。将这两数相加会返回一个新的链表。
你可以假设除了数字 0 之外,这两个数字都不会以零开头。
示例1:
_第2张图片](http://img.e-com-net.com/image/info8/2ca284acf6a340f688d74d58438437e2.jpg)
输入:l1 = [7,2,4,3], l2 = [5,6,4]
输出:[7,8,0,7]
示例2:
输入:l1 = [2,4,3], l2 = [5,6,4]
输出:[8,0,7]
示例3:
输入:l1 = [0], l2 = [0]
输出:[0]
提示:
链表的长度范围为 [1, 100]
0 <= node.val <= 9
输入数据保证链表代表的数字无前导 0
进阶:如果输入链表不能翻转该如何解决?
解法1:栈+链表
/**
* Definition for singly-linked list.
* struct ListNode {
* int val;
* ListNode *next;
* ListNode() : val(0), next(nullptr) {}
* ListNode(int x) : val(x), next(nullptr) {}
* ListNode(int x, ListNode *next) : val(x), next(next) {}
* };
*/
class Solution {
public:
ListNode* addTwoNumbers(ListNode* l1, ListNode* l2) {
stack<int> st1, st2;
while(l1){
st1.push(l1->val);
l1 = l1->next;
}
while(l2){
st2.push(l2->val);
l2 = l2->next;
}
int add = 0;
ListNode* res = nullptr;
while(!st1.empty() || !st2.empty() || add != 0){
if(!st1.empty()){
add += st1.top();
st1.pop();
}
if(!st2.empty()){
add += st2.top();
st2.pop();
}
ListNode* p = new ListNode(add%10);
p->next = res;
res = p;
add /=10;
}
return res;
}
};
206. 反转链表
给你单链表的头节点 head ,请你反转链表,并返回反转后的链表。
示例 1:
_第3张图片](http://img.e-com-net.com/image/info8/c86fd75fd37b4a7c8b9a238a5968ba74.jpg)
输入:head = [1,2,3,4,5]
输出:[5,4,3,2,1]
示例 2:
_第4张图片](http://img.e-com-net.com/image/info8/0c2ec43e1d794b7ea29faaa2cf59fb5d.jpg)
输入:head = [1,2]
输出:[2,1]
示例 3:
输入:head = []
输出:[]
提示:
链表中节点的数目范围是 [0, 5000]
-5000 <= Node.val <= 5000
进阶:链表可以选用迭代或递归方式完成反转。你能否用两种方法解决这道题?
解法1:栈实现
_第5张图片](http://img.e-com-net.com/image/info8/726055cfb3c247498579dc555909f31e.jpg)
/**
* Definition for singly-linked list.
* struct ListNode {
* int val;
* ListNode *next;
* ListNode() : val(0), next(nullptr) {}
* ListNode(int x) : val(x), next(nullptr) {}
* ListNode(int x, ListNode *next) : val(x), next(next) {}
* };
*/
class Solution {
public:
ListNode* reverseList(ListNode* head) {
stack<ListNode*> ST;
while(head != nullptr){
ST.push(head);
head = head->next;
}
if(ST.empty()) return {};
ListNode* node = ST.top();
ST.pop();
head = node;
while(!ST.empty()){
node->next = ST.top();
ST.pop();
node = node->next;
}
node->next = nullptr;
return head;
}
};
解法2:双指针-迭代
思路:
(1)如果再定义一个新的链表,实现链表元素的反转,其实这是对内存空间的浪费。
其实只需要改变链表的next指针的指向,直接将链表反转 ,而不用重新定义一个新的链表,如图所示:
_第6张图片](http://img.e-com-net.com/image/info8/7e3eb0e17a14436f86131ea75f6988f1.jpg)
之前链表的头节点是元素1, 反转之后头结点就是元素5 ,这里并没有添加或者删除节点,仅仅是改变next指针的方向。
(2)首先定义一个cur指针,指向头结点,再定义一个pre指针,初始化为null。
然后就要开始反转了,首先要把 cur->next 节点用tmp指针保存一下,也就是保存一下这个节点。 为什么要保存一下这个节点呢,因为接下来要改变 cur->next 的指向了,将cur->next 指向pre ,此时已经反转了第一个节点了。
接下来,就是循环走如下代码逻辑了,继续移动pre和cur指针。
最后,cur 指针已经指向了null,循环结束,链表也反转完毕了。 此时我们return pre指针就可以了,pre指针就指向了新的头结点。
代码:
class Solution {
public:
ListNode* reverseList(ListNode* head) {
ListNode* temp; // 保存cur的下一个节点
ListNode* cur = head;
ListNode* pre = NULL;
while(cur) {
temp = cur->next; // 保存一下 cur的下一个节点,因为接下来要改变cur->next
cur->next = pre; // 翻转操作
// 更新pre 和 cur指针
pre = cur;
cur = temp;
}
return pre;
}
};

解法3:双指针-递归
递归法相对抽象一些,但是其实和双指针法是一样的逻辑,同样是当cur为空的时候循环结束,不断将cur指向pre的过程。
关键是初始化的地方,可能有的同学会不理解, 可以看到双指针法中初始化 cur = head,pre = NULL,在递归法中可以从如下代码看出初始化的逻辑也是一样的,只不过写法变了。
具体可以看代码(已经详细注释),双指针法写出来之后,理解如下递归写法就不难了,代码逻辑都是一样的。
class Solution {
public:
ListNode* reverse(ListNode* pre,ListNode* cur){
if(cur == NULL) return pre;
ListNode* temp = cur->next;
cur->next = pre;
// 可以和双指针法的代码进行对比,如下递归的写法,其实就是做了这两步
// pre = cur;
// cur = temp;
return reverse(cur,temp);
}
ListNode* reverseList(ListNode* head) {
// 和双指针法初始化是一样的逻辑
// ListNode* cur = head;
// ListNode* pre = NULL;
return reverse(NULL, head);
}
};

92. 反转链表 II
力扣链接
给你单链表的头指针 head 和两个整数 left 和 right ,其中 left <= right 。请你反转从位置 left 到位置 right 的链表节点,返回 反转后的链表 。
示例 1:
_第7张图片](http://img.e-com-net.com/image/info8/c75029b6a53842a8a231c7f335534bb9.jpg)
输入:head = [1,2,3,4,5], left = 2, right = 4
输出:[1,4,3,2,5]
示例 2:
输入:head = [5], left = 1, right = 1
输出:[5]
提示:
链表中节点数目为 n
1 <= n <= 500
-500 <= Node.val <= 500
1 <= left <= right <= n
进阶: 你可以使用一趟扫描完成反转吗?
解法1:一次遍历「穿针引线」反转链表(头插法)
思路:
整体思想是:在需要反转的区间里,每遍历到一个节点,让这个新节点来到反转部分的起始位置。下面的图展示了整个流程。
_第8张图片](http://img.e-com-net.com/image/info8/ded07510cc9a47bda4406332d2c8177c.jpg)
下面我们具体解释如何实现。使用三个指针变量 pre、curr、next 来记录反转的过程中需要的变量,它们的意义如下:
curr:指向待反转区域的第一个节点 left;
next:永远指向 curr 的下一个节点,循环过程中,curr 变化以后 next 会变化;
pre:永远指向待反转区域的第一个节点 left 的前一个节点,在循环过程中不变。
_第9张图片](http://img.e-com-net.com/image/info8/3538e7ae226242b191cef236ae8a7941.jpg)
_第10张图片](http://img.e-com-net.com/image/info8/b0718da47e0a44968817d5d50439a418.jpg)
代码:
#include#include另外用到了链表题常用技巧:哑节点 dummy。创建 哑节点 作为 链表 的新开头,返回结果是这个节点的下一个位置。目的是:如果要翻转的区间包含了原始链表的第一个位置,那么使用 dummy 就可以维护整个翻转的过程更加通用:要对头结点进行操作时,考虑创建哑节点dummy,使用dummy->next表示真正的头节点。这样可以避免处理头节点为空的边界问题。
复杂度分析:
时间复杂度:O(N),其中 N 是链表总节点数。最多只遍历了链表一次,就完成了反转。
空间复杂度:O(1)。只使用到常数个变量。
203. 移除链表元素
力扣链接
给你一个链表的头节点 head 和一个整数 val ,请你删除链表中所有满足 Node.val == val 的节点,并返回 新的头节点 。
示例 1:
_第11张图片](http://img.e-com-net.com/image/info8/7fd49220414d41f0abef362e6b2718fc.jpg)
输入:head = [1,2,6,3,4,5,6], val = 6
输出:[1,2,3,4,5]
示例 2:
输入:head = [], val = 1
输出:[]
示例 3:
输入:head = [7,7,7,7], val = 7
输出:[]
提示:
列表中的节点数目在范围 [0, 104] 内
1 <= Node.val <= 50
0 <= val <= 50
解法1:链表-迭代
思路:
这里以链表 1 4 2 4 来举例,移除元素4。
_第12张图片](http://img.e-com-net.com/image/info8/43dccd3fbfb74591bf52f67c308db393.jpg)
如果使用C,C++编程语言的话,不要忘了还要从内存中删除这两个移除的节点, 清理节点内存之后如图:
_第13张图片](http://img.e-com-net.com/image/info8/92768bf6c0264e38b8db9ba76ff4451c.jpg)
当然如果使用java ,python的话就不用手动管理内存了。
还要说明一下,就算使用C++来做leetcode,如果移除一个节点之后,没有手动在内存中删除这个节点,leetcode依然也是可以通过的,只不过,内存使用的空间大一些而已,但建议依然要养成手动清理内存的习惯。
这种情况下的移除操作,就是让节点next指针直接指向下下一个节点就可以了,
那么因为单链表的特殊性,只能指向下一个节点,刚刚删除的是链表的中第二个,和第四个节点,那么如果删除的是头结点又该怎么办呢?
这里就涉及如下链表操作的两种方式:
直接使用原来的链表来进行删除操作。
设置一个虚拟头结点在进行删除操作。
可以设置一个虚拟头结点,这样原链表的所有节点就都可以按照统一的方式进行移除了。来看看如何设置一个虚拟头。依然还是在这个链表中,移除元素1。
_第14张图片](http://img.e-com-net.com/image/info8/51f2f80c5a6b4cb3b09ecf00c92a7b0f.jpg)
return 头结点的时候,别忘了 return dummyNode->next;, 这才是新的头结点
代码:
/**
* Definition for singly-linked list.
* struct ListNode {
* int val;
* ListNode *next;
* ListNode() : val(0), next(nullptr) {}
* ListNode(int x) : val(x), next(nullptr) {}
* ListNode(int x, ListNode *next) : val(x), next(next) {}
* };
*/
class Solution {
public:
ListNode* removeElements(ListNode* head, int val) {
ListNode* dummyNode = new ListNode(0);
dummyNode->next = head;
ListNode* cur = head;
ListNode* pre = dummyNode;
while(cur){
if(cur->val == val){
ListNode* next = cur->next;
delete pre->next;
pre->next = next;
cur = next;
}else{
pre = pre->next;
cur = cur->next;
}
}
return dummyNode->next;
}
};
复杂度分析:
时间复杂度:O(n),其中 n是链表的长度。需要遍历链表一次。
空间复杂度:O(1)。
解法1:链表-递归
思路:
链表的定义具有递归的性质,因此链表题目常可以用递归的方法求解。这道题要求删除链表中所有节点值等于特定值的节点,可以用递归实现。
对于给定的链表,首先对除了头节点 head 以外的节点进行删除操作,然后判断 head 的节点值是否等于给定的 val。如果 head 的节点值等于 val,则head 需要被删除,因此删除操作后的头节点为head.next;如果head 的节点值不等于val,则 head 保留,因此删除操作后的头节点还是 head。上述过程是一个递归的过程。
递归的终止条件是 head 为空,此时直接返回 head。当 head 不为空时,递归地进行删除操作,然后判断head 的节点值是否等于 val 并决定是否要删除head。
代码:
/**
* Definition for singly-linked list.
* struct ListNode {
* int val;
* ListNode *next;
* ListNode() : val(0), next(nullptr) {}
* ListNode(int x) : val(x), next(nullptr) {}
* ListNode(int x, ListNode *next) : val(x), next(next) {}
* };
*/
class Solution {
public:
ListNode* removeElements(ListNode* head, int val) {
if(head == NULL) return head;
head->next = removeElements(head->next, val);
return head->val == val ? head->next : head;
}
};
复杂度分析:
时间复杂度:O(n),其中 n 是链表的长度。递归过程中需要遍历链表一次。
空间复杂度:O(n),其中 n 是链表的长度。空间复杂度主要取决于递归调用栈,最多不会超过 n 层。
61. 旋转链表
力扣链接
给你一个链表的头节点 head ,旋转链表,将链表每个节点向右移动 k 个位置。
示例 1:
_第15张图片](http://img.e-com-net.com/image/info8/986541a7eaef4a95881de57dc5e209e5.jpg)
输入:head = [1,2,3,4,5], k = 2
输出:[4,5,1,2,3]
示例 2:
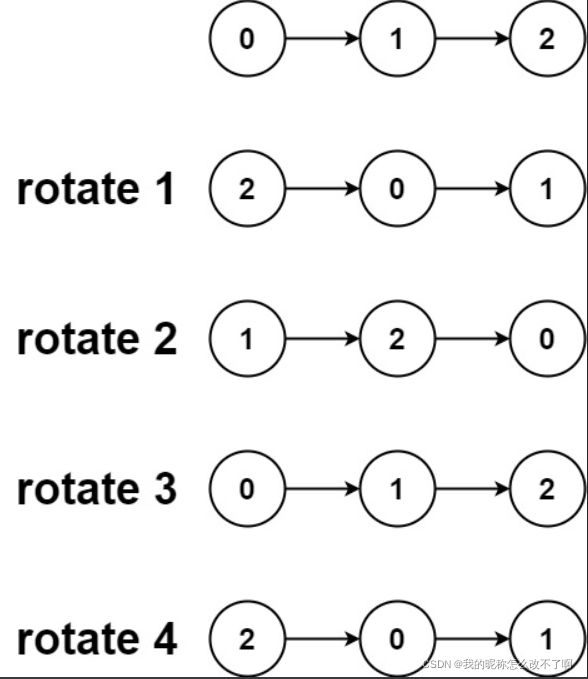
输入:head = [0,1,2], k = 4
输出:[2,0,1]
提示:
链表中节点的数目在范围 [0, 500] 内
-100 <= Node.val <= 100
0 <= k <= 2 * 109
解法1:链表
思路:
_第16张图片](http://img.e-com-net.com/image/info8/f5cb7277868f455aa2eec6f9f317154b.jpg)
_第17张图片](http://img.e-com-net.com/image/info8/c1ed43932af54ae19cdc6c0674194f13.jpg)
_第18张图片](http://img.e-com-net.com/image/info8/4649cf157b39442aa41da2b063e0d59e.jpg)
_第19张图片](http://img.e-com-net.com/image/info8/383ad44f5e0641a98d526bcc6ac5dc8d.jpg)
代码:
/**
* Definition for singly-linked list.
* struct ListNode {
* int val;
* ListNode *next;
* ListNode() : val(0), next(nullptr) {}
* ListNode(int x) : val(x), next(nullptr) {}
* ListNode(int x, ListNode *next) : val(x), next(next) {}
* };
*/
class Solution {
public:
ListNode* rotateRight(ListNode* head, int k) {
if(!head || !k) return head;
int n = 0;
ListNode* tail;
for(ListNode* p = head;p!=nullptr;p=p->next){
tail = p;
n++;
}
k%=n;
ListNode* p = head;
for(int i = 0;i<n-k-1;i++){
p = p->next;
}
tail->next = head;
head = p->next;
p->next = nullptr;
return head;
}
};
相似题目:剑指 Offer 22. 链表中倒数第k个节点
力扣链接
输入一个链表,输出该链表中倒数第k个节点。为了符合大多数人的习惯,本题从1开始计数,即链表的尾节点是倒数第1个节点。
例如,一个链表有 6 个节点,从头节点开始,它们的值依次是 1、2、3、4、5、6。这个链表的倒数第 3 个节点是值为 4 的节点。
示例:
给定一个链表: 1->2->3->4->5, 和 k = 2.
返回链表 4->5.
解法1:链表
/**
* Definition for singly-linked list.
* struct ListNode {
* int val;
* ListNode *next;
* ListNode(int x) : val(x), next(NULL) {}
* };
*/
class Solution {
public:
ListNode* getKthFromEnd(ListNode* head, int k) {
int n = 0;
for(ListNode* p = head;p!=nullptr;p=p->next){
n++;
}
ListNode* p = head;
for(int i = 0;i<n-k;i++){
p = p->next;
}
return p;
}
};
725. 分隔链表
力扣链接
给你一个头结点为 head 的单链表和一个整数 k ,请你设计一个算法将链表分隔为 k 个连续的部分。
每部分的长度应该尽可能的相等:任意两部分的长度差距不能超过 1 。这可能会导致有些部分为 null 。
这 k 个部分应该按照在链表中出现的顺序排列,并且排在前面的部分的长度应该大于或等于排在后面的长度。
返回一个由上述 k 部分组成的数组。
示例 1:
_第20张图片](http://img.e-com-net.com/image/info8/717b49131e46459d87ee7a5ea8c8e3d0.jpg)
输入:head = [1,2,3], k = 5
输出:[[1],[2],[3],[],[]]
解释:
第一个元素 output[0] 为 output[0].val = 1 ,output[0].next = null 。
最后一个元素 output[4] 为 null ,但它作为 ListNode 的字符串表示是 [] 。
示例 2:

输入:head = [1,2,3,4,5,6,7,8,9,10], k = 3
输出:[[1,2,3,4],[5,6,7],[8,9,10]]
解释:
输入被分成了几个连续的部分,并且每部分的长度相差不超过 1 。前面部分的长度大于等于后面部分的长度。
提示:
链表中节点的数目在范围 [0, 1000]
0 <= Node.val <= 1000
1 <= k <= 50
解法1:链表
思路:
1,遍历链表获取长度 length(这个跑不掉 );
2,length 除以 k 得到每段链表的平均长度 aveLength 和 余数 remainder,remainder 的值就是有多少个长度为 (aveLength + 1) 的子链表排在前面。
2.1,举个例子帮助理解一下 11 / 3 = 3 余 2: 一共有3段,每段平均3个节点,但是剩下了2个节点,剩下的2个节点不能丢啊,得全部塞到子链表里面去,怎么塞呢?
2.2,根据题意长的链表排前面,短的链表排后面,所以只有前面的两个子链表一人分担一个多余的节点,如此一来便形成了 4 4 3 的结构。
3,接下来的事儿就比较简单了,按照每个子链表应该的长度[4, 4, 3]去截断给定的链表。
代码:
/**
* Definition for singly-linked list.
* struct ListNode {
* int val;
* ListNode *next;
* ListNode() : val(0), next(nullptr) {}
* ListNode(int x) : val(x), next(nullptr) {}
* ListNode(int x, ListNode *next) : val(x), next(next) {}
* };
*/
class Solution {
public:
vector<ListNode*> splitListToParts(ListNode* head, int k) {
vector<ListNode*> result(k,nullptr);
int length = 0;
for(ListNode* cur = head;cur;cur = cur->next){
length++;
}
int avgLength = length / k;//每个子链表平均元素的个数
int reminder = length % k;//余数
ListNode* cur = head;
ListNode* pre = nullptr;
for(int i = 0;i<k;i++){//数组有k个元素需要遍历k次
result[i] = cur;
int curLength = reminder > 0 ? avgLength + 1 : avgLength;
for(int j = 0;j<curLength && cur;j++){
pre = cur;
cur = cur->next;
}
if(pre) pre->next = nullptr;//一个子链表已经生成,断开连接
if(reminder) reminder--;
}
return result;
}
};
当 pre 到达当前部分的尾结点时,需要拆分pre 和后面一个结点之间的连接关系,在拆分之前需要存储pre 的后一个结点 cur = cur->next;;
复杂度分析:
时间复杂度:O(n),其中 n 是链表的长度。需要遍历链表两次,得到链表的长度和分隔链表。
空间复杂度:O(1)。只使用了常量的额外空间,注意返回值不计入空间复杂度。
相似题目:328. 奇偶链表
给定单链表的头节点 head ,将所有索引为奇数的节点和索引为偶数的节点分别组合在一起,然后返回重新排序的列表。
第一个节点的索引被认为是 奇数 , 第二个节点的索引为 偶数 ,以此类推。
请注意,偶数组和奇数组内部的相对顺序应该与输入时保持一致。
你必须在 O(1) 的额外空间复杂度和 O(n) 的时间复杂度下解决这个问题。
示例 1:
_第21张图片](http://img.e-com-net.com/image/info8/b2cd91100e434dd5b37b502d71847cdb.jpg)
输入: head = [1,2,3,4,5]
输出: [1,3,5,2,4]
示例 2:
_第22张图片](http://img.e-com-net.com/image/info8/c5f5dff3310041cba1f8ea4fa7f8808e.jpg)
输入: head = [2,1,3,5,6,4,7]
输出: [2,3,6,7,1,5,4]
提示:
n == 链表中的节点数
0 <= n <= 104
-106 <= Node.val <= 106
解法1:链表
思路:
创建两个指针分别指向奇偶链表
奇指针每次指向偶指针的next,偶指针每次指向奇指针的next
终止条件是偶数指针为空(一共有奇数个节点),或者偶数指针是最后一个节点(一共有偶数个节点)
_第23张图片](http://img.e-com-net.com/image/info8/bce15a05435b4a73ae28d22673584760.jpg)
代码:
/**
* Definition for singly-linked list.
* struct ListNode {
* int val;
* ListNode *next;
* ListNode() : val(0), next(nullptr) {}
* ListNode(int x) : val(x), next(nullptr) {}
* ListNode(int x, ListNode *next) : val(x), next(next) {}
* };
*/
class Solution {
public:
ListNode* oddEvenList(ListNode* head) {
if(!head) return head;
ListNode* p1_head = head;
ListNode* p2_head = head->next;
ListNode* p1 = p1_head;
ListNode* p2 = p2_head;
while(p2 && p2->next){
p1->next = p1->next->next;
p2->next = p2->next->next;
p1 = p1->next;
p2 = p2->next;
}
p1->next = p2_head;
return head;
}
};
86. 分隔链表
力扣链接
给你一个链表的头节点 head 和一个特定值 x ,请你对链表进行分隔,使得所有 小于 x 的节点都出现在 大于或等于 x 的节点之前。
你应当 保留 两个分区中每个节点的初始相对位置。
示例 1:
_第24张图片](http://img.e-com-net.com/image/info8/f3ab4afc37704650838ba8d3cdb060ea.jpg)
输入:head = [1,4,3,2,5,2], x = 3
输出:[1,2,2,4,3,5]
示例 2:
输入:head = [2,1], x = 2
输出:[1,2]
提示:
链表中节点的数目在范围 [0, 200] 内
-100 <= Node.val <= 100
-200 <= x <= 200
解法1:虚拟节点+链表指针
代码:
/**
* Definition for singly-linked list.
* struct ListNode {
* int val;
* ListNode *next;
* ListNode() : val(0), next(nullptr) {}
* ListNode(int x) : val(x), next(nullptr) {}
* ListNode(int x, ListNode *next) : val(x), next(next) {}
* };
*/
class Solution {
public:
ListNode* partition(ListNode* head, int x) {
ListNode* dummyNode1 = new ListNode(0);
ListNode* dummyNode2 = new ListNode(0);
ListNode* pre1 = dummyNode1;
ListNode* pre2 = dummyNode2;
while(head){
if(head->val < x){
pre1->next = head;
head = head->next;
pre1 = pre1->next;
pre1->next = nullptr;
}else{
pre2->next = head;
head = head->next;
pre2 = pre2->next;
pre2->next = nullptr;
}
}
pre1->next = dummyNode2->next;
return dummyNode1->next;
}
};
25. K 个一组翻转链表
给你一个链表,每 k 个节点一组进行翻转,请你返回翻转后的链表。
k 是一个正整数,它的值小于或等于链表的长度。
如果节点总数不是 k 的整数倍,那么请将最后剩余的节点保持原有顺序。
进阶:
你可以设计一个只使用常数额外空间的算法来解决此问题吗?
你不能只是单纯的改变节点内部的值,而是需要实际进行节点交换。
示例 1:
_第25张图片](http://img.e-com-net.com/image/info8/957f8ec056c44d93b8efad4e2498f986.jpg)
输入:head = [1,2,3,4,5], k = 2
输出:[2,1,4,3,5]
示例 2:
_第26张图片](http://img.e-com-net.com/image/info8/95365e3543ae4655ad2ddc8e4dc08dd3.jpg)
输入:head = [1,2,3,4,5], k = 3
输出:[3,2,1,4,5]
示例 3:
输入:head = [1,2,3,4,5], k = 1
输出:[1,2,3,4,5]
示例 4:
输入:head = [1], k = 1
输出:[1]
提示:
列表中节点的数量在范围 sz 内
1 <= sz <= 5000
0 <= Node.val <= 1000
1 <= k <= sz
解法1:链表+模拟
思路:
_第27张图片](http://img.e-com-net.com/image/info8/4fa8c455e9d8447b81d33a08a2e6d1ee.jpg)
_第28张图片](http://img.e-com-net.com/image/info8/92021f0a76494e25a4fbe6be53347c42.jpg)
_第29张图片](http://img.e-com-net.com/image/info8/df775eea654c41f487ade557504139a5.jpg)
_第30张图片](http://img.e-com-net.com/image/info8/18c92367aca44ad68b103bd1994f1343.jpg)
_第31张图片](http://img.e-com-net.com/image/info8/51b4254ad9744c91bd32469b27179ae2.jpg)
代码:
/**
* Definition for singly-linked list.
* struct ListNode {
* int val;
* ListNode *next;
* ListNode() : val(0), next(nullptr) {}
* ListNode(int x) : val(x), next(nullptr) {}
* ListNode(int x, ListNode *next) : val(x), next(next) {}
* };
*/
class Solution {
public:
pair<ListNode*,ListNode*> myReverse(ListNode* head, ListNode* tail){
ListNode* pre = nullptr;
ListNode* cur = head;
ListNode* tmp;
while(pre != tail){
tmp = cur->next;
cur->next = pre;
pre = cur;
cur = tmp;
}
return {tail,head};
}
ListNode* reverseKGroup(ListNode* head, int k) {
ListNode* dummy = new ListNode(0);
dummy->next = head;
ListNode* pre = dummy;
while(head){
ListNode* tail = head;
for(int i = 0;i<k-1;i++){
tail = tail->next;
if(tail == nullptr) return dummy->next;
}
ListNode* next = tail->next;
tie(head,tail) = myReverse(head,tail);
pre->next = head;
tail->next = next;
pre = tail;
head = next;
}
return dummy->next;
}
};
_第32张图片](http://img.e-com-net.com/image/info8/a90ccafa0f4846319e4b58766e5a6e01.jpg)
24. 两两交换链表中的节点
likou
给你一个链表,两两交换其中相邻的节点,并返回交换后链表的头节点。你必须在不修改节点内部的值的情况下完成本题(即,只能进行节点交换)。
示例 1:
_第33张图片](http://img.e-com-net.com/image/info8/ea53f7e90d574b6897fb9adb48d98483.jpg)
输入:head = [1,2,3,4]
输出:[2,1,4,3]
示例 2:
输入:head = []
输出:[]
示例 3:
输入:head = [1]
输出:[1]
提示:
链表中节点的数目在范围 [0, 100] 内
0 <= Node.val <= 100
解法1:链表
/**
* Definition for singly-linked list.
* struct ListNode {
* int val;
* ListNode *next;
* ListNode() : val(0), next(nullptr) {}
* ListNode(int x) : val(x), next(nullptr) {}
* ListNode(int x, ListNode *next) : val(x), next(next) {}
* };
*/
class Solution {
public:
ListNode* swapPairs(ListNode* head) {
ListNode* dummyNode = new ListNode(0);
dummyNode->next = head;
ListNode* cur = dummyNode;
while(cur->next && cur->next->next){
ListNode* tmp1 = cur->next;
ListNode* tmp = cur->next->next->next;
//swap
cur->next = cur->next->next;
cur->next->next = tmp1;
cur->next->next->next = tmp;
cur = cur->next->next;
}
return dummyNode->next;
}
};
148. 排序链表
给你链表的头结点 head ,请将其按 升序 排列并返回 排序后的链表 。
示例 1:
_第34张图片](http://img.e-com-net.com/image/info8/2781e4c8a14e422398b69d2caab2912b.jpg)
输入:head = [4,2,1,3]
输出:[1,2,3,4]
示例 2:
_第35张图片](http://img.e-com-net.com/image/info8/ddbc69ac309c48d1a950f4b2ae2be619.jpg)
输入:head = [-1,5,3,4,0]
输出:[-1,0,3,4,5]
示例 3:
输入:head = []
输出:[]
提示:
链表中节点的数目在范围 [0, 5 * 104] 内
-105 <= Node.val <= 105
进阶:你可以在 O(n log n) 时间复杂度和常数级空间复杂度下,对链表进行排序吗?
解法1:链表+归并排序+递归
思路:
(1)基本思想
归并排序(MERGE-SORT)是利用归并的思想实现的排序方法,该算法采用经典的分治(divide-and-conquer)策略(分治法将问题分(divide)成一些小的问题然后递归求解,而治(conquer)的阶段则将分的阶段得到的各答案"修补"在一起,即分而治之)。
(2)分而治之

可以看到这种**结构很像一棵完全二叉树,**本文的归并排序我们采用递归去实现(也可采用迭代的方式去实现)。分阶段可以理解为就是递归拆分子序列的过程,递归深度为log2n。
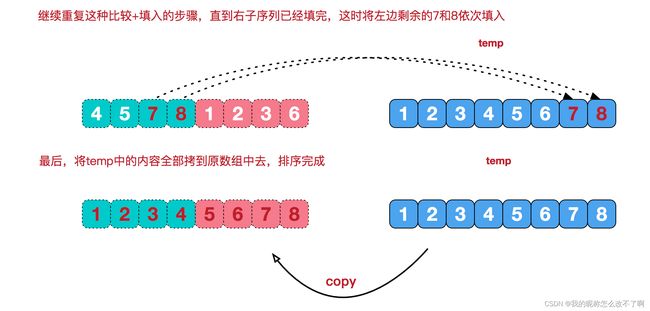
(3) 合并相邻有序子序列
再来看看治阶段,我们需要将两个已经有序的子序列合并成一个有序序列,比如上图中的最后一次合并,要将[4,5,7,8]和[1,2,3,6]两个已经有序的子序列,合并为最终序列[1,2,3,4,5,6,7,8],来看下实现步骤。

(4)归并排序基于分治算法。最容易想到的实现方式是自顶向下的递归实现,考虑到递归调用的栈空间,自顶向下归并排序的空间复杂度是 O(logn)。如果要达到 O(1) 的空间复杂度,则需要使用自底向上的实现方式。
因为链表不支持随机访问,所以用归并排序将其拆分成小段链表,排序后再连接起来效率最高。
该题是三个小题的组合:归并排序 + 双指针找单链表中点 + 合并两个排序链表。
_第36张图片](http://img.e-com-net.com/image/info8/8c8926c8f8c6412aa666dc1254084947.jpg)
寻找链表中点:
_第37张图片](http://img.e-com-net.com/image/info8/0b5720ac6b4b4258926522ec9bc5545c.jpg)
代码:
/**
* Definition for singly-linked list.
* struct ListNode {
* int val;
* ListNode *next;
* ListNode() : val(0), next(nullptr) {}
* ListNode(int x) : val(x), next(nullptr) {}
* ListNode(int x, ListNode *next) : val(x), next(next) {}
* };
*/
class Solution {
public:
ListNode* sortList(ListNode* head) {
//递归
if(head == nullptr || head->next == nullptr) return head;
//中
ListNode* head1 = head;
ListNode* head2 = split(head);//一条链表分成两段分别递归排序
//左右
head1 = sortList(head1);
head2 = sortList(head2);
return merge(head1,head2);//返回合并后结果
}
//双指针找单链表中点模板
ListNode* split(ListNode* head){
ListNode* slow = head;
ListNode* fast = head->next;
while(fast != nullptr && fast->next != nullptr){
slow = slow->next;
fast = fast->next->next;
}
ListNode* mid = slow->next;
slow->next = nullptr; //断尾
return mid;
}
//合并两个排序链表模板
ListNode* merge(ListNode* head1, ListNode* head2){
ListNode* dummyNode = new ListNode(0);
ListNode* p = dummyNode;
while(head1 != nullptr && head2 != nullptr){
if(head1->val < head2->val){
p->next = head1;
p = p->next;
head1 = head1->next;
}else{
p->next = head2;
p = p->next;
head2 = head2->next;
}
}
if(head1 != nullptr) p->next = head1;
if(head2 != nullptr) p->next = head2;
return dummyNode->next;
}
};

解法2:链表+归并排序+迭代
思路:
_第38张图片](http://img.e-com-net.com/image/info8/7930531bf0b445b99b0aed423b1203c2.jpg)
代码:
/**
* Definition for singly-linked list.
* struct ListNode {
* int val;
* ListNode *next;
* ListNode() : val(0), next(nullptr) {}
* ListNode(int x) : val(x), next(nullptr) {}
* ListNode(int x, ListNode *next) : val(x), next(next) {}
* };
*/
class Solution {
public:
ListNode* sortList(ListNode* head) {
int length = getLength(head);
ListNode* dummyNode = new ListNode(-1);
dummyNode->next = head;
for(int i = 1;i<length;i*=2){//依次将链表分成1块,2块,4块...
//每次变换步长,pre指针和cur指针都初始化在链表头
ListNode* pre = dummyNode;
ListNode* cur = dummyNode->next;
while(cur != nullptr){
ListNode* head1 = cur;//第一部分头 (第二次循环之后,cur为剩余部分头,不断往后把链表按照步长step分成一块一块...)
ListNode* head2 = split(head1, i);//第二部分头
cur = split(head2, i);//剩余部分的头
ListNode* merged = merge(head1,head2);//将一二部分排序合并
pre->next = merged;//将前面的部分与排序好的部分连接
while(pre->next != nullptr){//把pre指针移动到排序好的部分的末尾
pre = pre->next;
}
}
}
return dummyNode->next;
}
int getLength(ListNode* head){
//获取链表长度
int length = 0;
while(head != nullptr){
head = head->next;
length++;
}
return length;
}
//断链操作 返回第二部分链表头
ListNode* split(ListNode* head, int k){
if (head == nullptr) return nullptr;
ListNode* cur = head;
for(int i = 1;i<k && cur->next != nullptr;i++){
cur = cur->next;
}
ListNode* head2 = cur->next;
cur->next = nullptr;//断尾
return head2;
}
//合并两个排序链表模板
ListNode* merge(ListNode* head1, ListNode* head2){
ListNode* dummyNode = new ListNode(0);
ListNode* p = dummyNode;
while(head1 != nullptr && head2 != nullptr){
if(head1->val < head2->val){
p->next = head1;
p = p->next;
head1 = head1->next;
}else{
p->next = head2;
p = p->next;
head2 = head2->next;
}
}
if(head1 != nullptr) p->next = head1;
if(head2 != nullptr) p->next = head2;
return dummyNode->next;
}
};
相似题目:147. 对链表进行插入排序
力扣链接
给定单个链表的头 head ,使用 插入排序 对链表进行排序,并返回 排序后链表的头 。
插入排序 算法的步骤:
插入排序是迭代的,每次只移动一个元素,直到所有元素可以形成一个有序的输出列表。
每次迭代中,插入排序只从输入数据中移除一个待排序的元素,找到它在序列中适当的位置,并将其插入。
重复直到所有输入数据插入完为止。
下面是插入排序算法的一个图形示例。部分排序的列表(黑色)最初只包含列表中的第一个元素。每次迭代时,从输入数据中删除一个元素(红色),并就地插入已排序的列表中。
对链表进行插入排序。
示例 1:
_第39张图片](http://img.e-com-net.com/image/info8/0fad51e9d48446efa76b13c7448361f5.jpg)
输入: head = [4,2,1,3]
输出: [1,2,3,4]
示例 2:
_第40张图片](http://img.e-com-net.com/image/info8/e43a76d27ef84bac818d3b356284bb69.jpg)
输入: head = [-1,5,3,4,0]
输出: [-1,0,3,4,5]
提示:
列表中的节点数在 [1, 5000]范围内
-5000 <= Node.val <= 5000
解法1:链表 +插入排序
思路:
_第41张图片](http://img.e-com-net.com/image/info8/6f6ffd6e18bd44448a322daf85c52d73.jpg)
_第42张图片](http://img.e-com-net.com/image/info8/9ddf84f4edad4852ad466902333f40f6.jpg)
_第43张图片](http://img.e-com-net.com/image/info8/7630f2f284884c2f9179e3910c124c17.jpg)
_第44张图片](http://img.e-com-net.com/image/info8/fd1b5a6c4c0b4b5cb9722bc1de04b4fa.jpg)
代码:
/**
* Definition for singly-linked list.
* struct ListNode {
* int val;
* ListNode *next;
* ListNode() : val(0), next(nullptr) {}
* ListNode(int x) : val(x), next(nullptr) {}
* ListNode(int x, ListNode *next) : val(x), next(next) {}
* };
*/
class Solution {
public:
ListNode* insertionSortList(ListNode* head) {
if(head == nullptr || head->next == nullptr) return head;
ListNode* dummyNode = new ListNode(0);
dummyNode->next = head;
ListNode* lastSorted = head;
ListNode* cur = head->next;
while(cur != nullptr){
if(lastSorted->val <= cur->val){
lastSorted = cur;
cur = cur->next;
}else{
ListNode* pre = dummyNode;
while(pre->next->val <= cur->val){
pre = pre->next;
}
lastSorted->next = cur->next;//lastsorted的位置此时没有变
cur->next = pre->next;
pre->next = cur;
}
cur = lastSorted->next;
}
return dummyNode->next;
}
};
_第45张图片](http://img.e-com-net.com/image/info8/74fe59849499420e8b4b165999fde662.jpg)
83. 删除排序链表中的重复元素
给定一个已排序的链表的头 head , 删除所有重复的元素,使每个元素只出现一次 。返回 已排序的链表 。
示例 1:
_第46张图片](http://img.e-com-net.com/image/info8/bad7d655a07141318b24659b73aba0a2.jpg)
输入:head = [1,1,2]
输出:[1,2]
示例 2:
_第47张图片](http://img.e-com-net.com/image/info8/66f3c4da75d14a6b9c7373a526cd5627.jpg)
输入:head = [1,1,2,3,3]
输出:[1,2,3]
提示:
链表中节点数目在范围 [0, 300] 内
-100 <= Node.val <= 100
题目数据保证链表已经按升序 排列
解法1:链表
思路:
_第48张图片](http://img.e-com-net.com/image/info8/8db64fba057e4c5fa574fe0a4de6dad6.jpg)
代码:
/**
* Definition for singly-linked list.
* struct ListNode {
* int val;
* ListNode *next;
* ListNode() : val(0), next(nullptr) {}
* ListNode(int x) : val(x), next(nullptr) {}
* ListNode(int x, ListNode *next) : val(x), next(next) {}
* };
*/
class Solution {
public:
ListNode* deleteDuplicates(ListNode* head) {
ListNode* dummyNode = new ListNode(-101);
dummyNode->next = head;
ListNode* pre = dummyNode;
ListNode* cur = head;
while(cur){
if(pre->val == cur->val){
while(cur && pre->val == cur->val){
cur = cur->next;
}
pre->next = cur;
}else{
pre = cur;
cur = cur->next;
}
}
return dummyNode->next;
}
};
复杂度分析:
时间复杂度:O(n),其中 n 是链表的长度。
空间复杂度:O(1)。
相似题目:82. 删除排序链表中的重复元素 II
力扣链接
给定一个已排序的链表的头 head , 删除原始链表中所有重复数字的节点,只留下不同的数字 。返回 已排序的链表 。
示例 1:
_第49张图片](http://img.e-com-net.com/image/info8/fd9d713add9f439c8fa7b4440a881659.jpg)
输入:head = [1,2,3,3,4,4,5]
输出:[1,2,5]
示例 2:
_第50张图片](http://img.e-com-net.com/image/info8/c31e96a5fb454519af00dc77602be697.jpg)
输入:head = [1,1,1,2,3]
输出:[2,3]
提示:
链表中节点数目在范围 [0, 300] 内
-100 <= Node.val <= 100
题目数据保证链表已经按升序 排列
解法1:链表+双指针
思路:
代码:
/**
* Definition for singly-linked list.
* struct ListNode {
* int val;
* ListNode *next;
* ListNode() : val(0), next(nullptr) {}
* ListNode(int x) : val(x), next(nullptr) {}
* ListNode(int x, ListNode *next) : val(x), next(next) {}
* };
*/
class Solution {
public:
ListNode* deleteDuplicates(ListNode* head) {
if(!head || !head->next) return head;
ListNode* dummyNode = new ListNode(-1);
dummyNode->next = head;
ListNode* cur = head;
ListNode* pre = dummyNode;
while(cur && cur->next){
if(cur->next->val == cur->val){
while(cur->next && cur->next->val == cur->val){
cur = cur->next;
}
pre->next = cur->next;
cur = cur->next;
}
else{
pre = cur;
cur = cur->next;
}
}
return dummyNode->next;
}
};
138. 复制带随机指针的链表
力扣链接
给你一个长度为 n 的链表,每个节点包含一个额外增加的随机指针 random ,该指针可以指向链表中的任何节点或空节点。
构造这个链表的 深拷贝。 深拷贝应该正好由 n 个 全新 节点组成,其中每个新节点的值都设为其对应的原节点的值。新节点的 next 指针和 random 指针也都应指向复制链表中的新节点,并使原链表和复制链表中的这些指针能够表示相同的链表状态。复制链表中的指针都不应指向原链表中的节点 。
例如,如果原链表中有 X 和 Y 两个节点,其中 X.random --> Y 。那么在复制链表中对应的两个节点 x 和 y ,同样有 x.random --> y 。
返回复制链表的头节点。
用一个由 n 个节点组成的链表来表示输入/输出中的链表。每个节点用一个 [val, random_index] 表示:
val:一个表示 Node.val 的整数。
random_index:随机指针指向的节点索引(范围从 0 到 n-1);如果不指向任何节点,则为 null 。
你的代码 只 接受原链表的头节点 head 作为传入参数。
示例 1:
_第51张图片](http://img.e-com-net.com/image/info8/6387c3df10b14ff89122b1662e62d2a2.jpg)
输入:head = [[7,null],[13,0],[11,4],[10,2],[1,0]]
输出:[[7,null],[13,0],[11,4],[10,2],[1,0]]
示例 2:
_第52张图片](http://img.e-com-net.com/image/info8/e66b5eb002314cf69e8e0f26d10dd16c.jpg)
输入:head = [[1,1],[2,1]]
输出:[[1,1],[2,1]]
示例 3:
_第53张图片](http://img.e-com-net.com/image/info8/ca5e0cc974dd4ca988eb21cb82e51cc5.jpg)
输入:head = [[3,null],[3,0],[3,null]]
输出:[[3,null],[3,0],[3,null]]
提示:
0 <= n <= 1000
-104 <= Node.val <= 104
Node.random 为 null 或指向链表中的节点。
解法1:哈希表+链表
思路:
_第54张图片](http://img.e-com-net.com/image/info8/11280df349324f31ac902868f9aca2a3.png)
代码:
/*
// Definition for a Node.
class Node {
public:
int val;
Node* next;
Node* random;
Node(int _val) {
val = _val;
next = NULL;
random = NULL;
}
};
*/
class Solution {
public:
unordered_map<Node*, Node*> isVisited;
Node* copyRandomList(Node* head) {
//DFS
if(head == NULL) return head;
if(!isVisited.count(head)){
Node* newHead = new Node(head->val);
isVisited[head] = newHead;
newHead->next = copyRandomList(head->next);
newHead->random = copyRandomList(head->random);
}
return isVisited[head];
}
};
相似题目:133. 克隆图
力扣链接
给你无向 连通 图中一个节点的引用,请你返回该图的 深拷贝(克隆)。
图中的每个节点都包含它的值 val(int) 和其邻居的列表(list[Node])。
class Node {
public int val;
public List neighbors;
}
测试用例格式:
简单起见,每个节点的值都和它的索引相同。例如,第一个节点值为 1(val = 1),第二个节点值为 2(val = 2),以此类推。该图在测试用例中使用邻接列表表示。
邻接列表 是用于表示有限图的无序列表的集合。每个列表都描述了图中节点的邻居集。
给定节点将始终是图中的第一个节点(值为 1)。你必须将 给定节点的拷贝 作为对克隆图的引用返回。
示例 1:
_第55张图片](http://img.e-com-net.com/image/info8/157a2399fb144ee18bdaebd5e39bb6a1.jpg)
输入:adjList = [[2,4],[1,3],[2,4],[1,3]]
输出:[[2,4],[1,3],[2,4],[1,3]]
解释:
图中有 4 个节点。
节点 1 的值是 1,它有两个邻居:节点 2 和 4 。
节点 2 的值是 2,它有两个邻居:节点 1 和 3 。
节点 3 的值是 3,它有两个邻居:节点 2 和 4 。
节点 4 的值是 4,它有两个邻居:节点 1 和 3 。
示例 2:
_第56张图片](http://img.e-com-net.com/image/info8/e621cc7f243147808a0198e920308c06.jpg)
输入:adjList = [[]]
输出:[[]]
解释:输入包含一个空列表。该图仅仅只有一个值为 1 的节点,它没有任何邻居。
示例 3:
输入:adjList = []
输出:[]
解释:这个图是空的,它不含任何节点。
示例 4:
_第57张图片](http://img.e-com-net.com/image/info8/c3624976c28d496a8f93ebb36c113442.jpg)
输入:adjList = [[2],[1]]
输出:[[2],[1]]
提示:
节点数不超过 100 。
每个节点值 Node.val 都是唯一的,1 <= Node.val <= 100。
无向图是一个简单图,这意味着图中没有重复的边,也没有自环。
由于图是无向的,如果节点 p 是节点 q 的邻居,那么节点 q 也必须是节点 p 的邻居。
图是连通图,你可以从给定节点访问到所有节点。
解法1:哈希表+BFS
思路:
_第58张图片](http://img.e-com-net.com/image/info8/5e820fc3362a4999b6e2fb3dca4c0543.jpg)


代码:
/*
// Definition for a Node.
class Node {
public:
int val;
vector neighbors;
Node() {
val = 0;
neighbors = vector();
}
Node(int _val) {
val = _val;
neighbors = vector();
}
Node(int _val, vector _neighbors) {
val = _val;
neighbors = _neighbors;
}
};
*/
class Solution {
public:
Node* cloneGraph(Node* node) {
//BFS
if(node == nullptr) return node;
unordered_map<Node*, Node*> umap;//旧节点 -> 新节点
queue<Node*> que;
que.push(node);
umap[node] = new Node(node->val);
while(!que.empty()){
Node* cur = que.front();
que.pop();
for(auto& neighbor:cur->neighbors){
if(umap.find(neighbor) == umap.end()){
umap[neighbor] = new Node(neighbor->val);
que.push(neighbor);
}
umap[cur]->neighbors.push_back(umap[neighbor]);
}
}
return umap[node];
}
};
_第59张图片](http://img.e-com-net.com/image/info8/fa74f9d717994c66a41b8030abfc95d4.jpg)
解法2:哈希表+DFS
/*
// Definition for a Node.
class Node {
public:
int val;
vector neighbors;
Node() {
val = 0;
neighbors = vector();
}
Node(int _val) {
val = _val;
neighbors = vector();
}
Node(int _val, vector _neighbors) {
val = _val;
neighbors = _neighbors;
}
};
*/
class Solution {
public:
Node* cloneGraph(Node* node) {
//DFS
unordered_map<Node*,Node*> umap;
return dfs(node,umap);
}
Node* dfs(Node* node, unordered_map<Node*,Node*>& umap){
if(node == nullptr) return node;
if(umap.count(node)) return umap[node];
Node* newNode = new Node(node->val);
umap[node] = newNode;
for(auto x:node->neighbors){
newNode->neighbors.push_back(dfs(x,umap));
}
return newNode;
}
};
_第60张图片](http://img.e-com-net.com/image/info8/5e211df47d8c4ad39313ba876234251f.jpg)
160. 相交链表
给你两个单链表的头节点 headA 和 headB ,请你找出并返回两个单链表相交的起始节点。如果两个链表不存在相交节点,返回 null 。
图示两个链表在节点 c1 开始相交:
_第61张图片](http://img.e-com-net.com/image/info8/80e6a0568ab64386b80cd592f6dc434c.jpg)
题目数据 保证 整个链式结构中不存在环。
注意,函数返回结果后,链表必须 保持其原始结构 。
自定义评测:
评测系统 的输入如下(你设计的程序 不适用 此输入):
intersectVal - 相交的起始节点的值。如果不存在相交节点,这一值为 0
listA - 第一个链表
listB - 第二个链表
skipA - 在 listA 中(从头节点开始)跳到交叉节点的节点数
skipB - 在 listB 中(从头节点开始)跳到交叉节点的节点数
评测系统将根据这些输入创建链式数据结构,并将两个头节点 headA 和 headB 传递给你的程序。如果程序能够正确返回相交节点,那么你的解决方案将被 视作正确答案 。
示例 1:
_第62张图片](http://img.e-com-net.com/image/info8/e75a6ac23b82448da63715e0e2905d99.jpg)
输入:intersectVal = 8, listA = [4,1,8,4,5], listB = [5,6,1,8,4,5], skipA = 2, skipB = 3
输出:Intersected at ‘8’
解释:相交节点的值为 8 (注意,如果两个链表相交则不能为 0)。
从各自的表头开始算起,链表 A 为 [4,1,8,4,5],链表 B 为 [5,6,1,8,4,5]。
在 A 中,相交节点前有 2 个节点;在 B 中,相交节点前有 3 个节点。
示例 2:
_第63张图片](http://img.e-com-net.com/image/info8/b7c6159eb7e1496ab94932a576c4e035.jpg)
输入:intersectVal = 2, listA = [1,9,1,2,4], listB = [3,2,4], skipA = 3, skipB = 1
输出:Intersected at ‘2’
解释:相交节点的值为 2 (注意,如果两个链表相交则不能为 0)。
从各自的表头开始算起,链表 A 为 [1,9,1,2,4],链表 B 为 [3,2,4]。
在 A 中,相交节点前有 3 个节点;在 B 中,相交节点前有 1 个节点。
示例 3:
_第64张图片](http://img.e-com-net.com/image/info8/5012d7fdc6444d209b676a5440f43d86.png)
输入:intersectVal = 0, listA = [2,6,4], listB = [1,5], skipA = 3, skipB = 2
输出:null
解释:从各自的表头开始算起,链表 A 为 [2,6,4],链表 B 为 [1,5]。
由于这两个链表不相交,所以 intersectVal 必须为 0,而 skipA 和 skipB 可以是任意值。
这两个链表不相交,因此返回 null 。
提示:
listA 中节点数目为 m
listB 中节点数目为 n
1 <= m, n <= 3 * 104
1 <= Node.val <= 105
0 <= skipA <= m
0 <= skipB <= n
如果 listA 和 listB 没有交点,intersectVal 为 0
如果 listA 和 listB 有交点,intersectVal == listA[skipA] == listB[skipB]
进阶:你能否设计一个时间复杂度 O(m + n) 、仅用 O(1) 内存的解决方案?
双指针
_第65张图片](http://img.e-com-net.com/image/info8/f7df521bf0ef40209a263755dc41e1e5.jpg)

/**
* Definition for singly-linked list.
* struct ListNode {
* int val;
* ListNode *next;
* ListNode(int x) : val(x), next(NULL) {}
* };
*/
class Solution {
public:
ListNode *getIntersectionNode(ListNode *headA, ListNode *headB) {
if(headA == nullptr || headB == nullptr) return nullptr;
ListNode* p1 = headA, *p2 = headB;
while(p1!=p2){
p1 = (p1 == nullptr) ? headB : p1->next;
p2 = (p2 == nullptr) ? headA : p2->next;
}
return p1;
}
};
21. 合并两个有序链表
力扣链接
将两个升序链表合并为一个新的 升序 链表并返回。新链表是通过拼接给定的两个链表的所有节点组成的。
示例 1:
输入:l1 = [1,2,4], l2 = [1,3,4]
输出:[1,1,2,3,4,4]
示例 2:
输入:l1 = [], l2 = []
输出:[]
示例 3:
输入:l1 = [], l2 = [0]
输出:[0]
提示:
两个链表的节点数目范围是 [0, 50]
-100 <= Node.val <= 100
l1 和 l2 均按 非递减顺序 排列
通过次数1,020,706提交次数1,531,164
解法1:递归
/**
* Definition for singly-linked list.
* struct ListNode {
* int val;
* ListNode *next;
* ListNode() : val(0), next(nullptr) {}
* ListNode(int x) : val(x), next(nullptr) {}
* ListNode(int x, ListNode *next) : val(x), next(next) {}
* };
*/
class Solution {
public:
ListNode* mergeTwoLists(ListNode* list1, ListNode* list2) {
//递归
if(list1 == nullptr) return list2;
else if (list2 == nullptr) return list1;
else if (list1->val < list2->val){
list1->next = mergeTwoLists(list1->next,list2);
return list1;
}else{
list2->next = mergeTwoLists(list1, list2->next);
return list2;
}
}
};
_第66张图片](http://img.e-com-net.com/image/info8/a5c5502c13034f9793fdc512cf7a8eeb.jpg)
解法2:迭代
/**
* Definition for singly-linked list.
* struct ListNode {
* int val;
* ListNode *next;
* ListNode() : val(0), next(nullptr) {}
* ListNode(int x) : val(x), next(nullptr) {}
* ListNode(int x, ListNode *next) : val(x), next(next) {}
* };
*/
class Solution {
public:
ListNode* mergeTwoLists(ListNode* list1, ListNode* list2) {
//迭代
ListNode* head = new ListNode;
ListNode* pre = head;
while(list1 != nullptr && list2 != nullptr){
if(list1->val < list2->val){
pre->next = list1;
list1 = list1->next;
}else{
pre->next = list2;
list2 = list2->next;
}
pre = pre->next;
}
pre->next = (list1 == nullptr ? list2 : list1);
return head->next;
}
};
_第67张图片](http://img.e-com-net.com/image/info8/4f8a76dfce99422895e787449d5f4e22.jpg)
23. 合并K个升序链表
力扣链接
给你一个链表数组,每个链表都已经按升序排列。
请你将所有链表合并到一个升序链表中,返回合并后的链表。
示例 1:
输入:lists = [[1,4,5],[1,3,4],[2,6]]
输出:[1,1,2,3,4,4,5,6]
解释:链表数组如下:
[
1->4->5,
1->3->4,
2->6
]
将它们合并到一个有序链表中得到。
1->1->2->3->4->4->5->6
示例 2:
输入:lists = []
输出:[]
示例 3:
输入:lists = [[]]
输出:[]
提示:
k == lists.length
0 <= k <= 10^4
0 <= lists[i].length <= 500
-10^4 <= lists[i][j] <= 10^4
lists[i] 按 升序 排列
lists[i].length 的总和不超过 10^4
解法1:分治
/**
* Definition for singly-linked list.
* struct ListNode {
* int val;
* ListNode *next;
* ListNode() : val(0), next(nullptr) {}
* ListNode(int x) : val(x), next(nullptr) {}
* ListNode(int x, ListNode *next) : val(x), next(next) {}
* };
*/
class Solution {
public:
ListNode* mergeKLists(vector<ListNode*>& lists) {
if(lists.size() == 0) return nullptr;
return helper(lists,0,lists.size()-1);
}
ListNode* helper(vector<ListNode*>& lists, int start, int end){
if(start == end) return lists[start];
int mid = start + (end-start) / 2;
ListNode* left = helper(lists,start,mid);
ListNode* right = helper(lists,mid+1,end);
return mergeTwoLists(left, right);
}
ListNode* mergeTwoLists(ListNode* a, ListNode* b){//合并
if(a == nullptr) return b;
else if (b == nullptr) return a;
else if (a->val < b->val){
a->next = mergeTwoLists(a->next, b);
return a;
}else{
b->next = mergeTwoLists(a,b->next);
return b;
}
}
};
解法2:两两合并
/**
* Definition for singly-linked list.
* struct ListNode {
* int val;
* ListNode *next;
* ListNode() : val(0), next(nullptr) {}
* ListNode(int x) : val(x), next(nullptr) {}
* ListNode(int x, ListNode *next) : val(x), next(next) {}
* };
*/
class Solution {
public:
ListNode* mergeKLists(vector<ListNode*>& lists) {
if(lists.size() == 0) return nullptr;
//两两合并
ListNode* result = lists[0];
for(int i = 1;i<lists.size();i++){
result = mergeTwoLists(result,lists[i]);
}
return result;
}
ListNode* mergeTwoLists(ListNode* a, ListNode* b){
if(a == nullptr) return b;
else if (b == nullptr) return a;
else if(a->val < b->val){
a->next = mergeTwoLists(a->next,b);
return a;
}else{
b->next = mergeTwoLists(a,b->next);
return b;
}
}
};
解法3:最小堆
/**
* Definition for singly-linked list.
* struct ListNode {
* int val;
* ListNode *next;
* ListNode() : val(0), next(nullptr) {}
* ListNode(int x) : val(x), next(nullptr) {}
* ListNode(int x, ListNode *next) : val(x), next(next) {}
* };
*/
class Solution {
public:
//最小堆+自定义数据类型运算符重载
struct Node{
int val;
ListNode* ptr;
bool operator<(const Node& r)const {
return val > r.val;
}
};
ListNode* mergeKLists(vector<ListNode*>& lists) {
priority_queue<Node> pq;
ListNode* dummy = new ListNode(0);
ListNode* pre = dummy;
for(int i = 0;i<lists.size();i++){
if(lists[i] != nullptr) pq.push({lists[i]->val,lists[i]});
}
while(!pq.empty()){
pre->next = pq.top().ptr;
pq.pop();
pre = pre->next;
if(pre->next) pq.push({pre->next->val,pre->next});
}
pre->next = nullptr;
return dummy->next;
}
};
_第68张图片](http://img.e-com-net.com/image/info8/4be731eb56764113974a598299a26014.jpg)
19. 删除链表的倒数第 N 个结点
力扣链接
给你一个链表,删除链表的倒数第 n 个结点,并且返回链表的头结点。
示例 1:
输入:head = [1,2,3,4,5], n = 2
输出:[1,2,3,5]
示例 2:
输入:head = [1], n = 1
输出:[]
示例 3:
输入:head = [1,2], n = 1
输出:[1]
提示:
链表中结点的数目为 sz
1 <= sz <= 30
0 <= Node.val <= 100
1 <= n <= sz
进阶:你能尝试使用一趟扫描实现吗?
解法1:计算链表长度
/**
* Definition for singly-linked list.
* struct ListNode {
* int val;
* ListNode *next;
* ListNode() : val(0), next(nullptr) {}
* ListNode(int x) : val(x), next(nullptr) {}
* ListNode(int x, ListNode *next) : val(x), next(next) {}
* };
*/
class Solution {
public:
ListNode* removeNthFromEnd(ListNode* head, int n) {
int length = 0;
ListNode* p = head;
while(p){
length++;
p = p->next;
}
if(length == n) return head->next;
p = head;
for(int i = 0;i<length-n-1;i++){
p = p->next;
}
p->next = p->next->next;
return head;
}
};
_第69张图片](http://img.e-com-net.com/image/info8/2ebae5e509e340db8042fc49e2ad58dd.jpg)
解法2:快慢指针
为什么要在head前创建一个新的节点,这样做可以避免讨论头结点被删除的情况,不管原来的head有没有被删除,直接返回dummy.next即可
我们也可以在不预处理出链表的长度,以及使用常数空间的前提下解决本题。
由于我们需要找到倒数第 nn 个节点,因此我们可以使用两个指针first 和 second 同时对链表进行遍历,并且first 比 second 超前 n 个节点。当 first 遍历到链表的末尾时,second 就恰好处于倒数第 nn 个节点。
/**
* Definition for singly-linked list.
* struct ListNode {
* int val;
* ListNode *next;
* ListNode() : val(0), next(nullptr) {}
* ListNode(int x) : val(x), next(nullptr) {}
* ListNode(int x, ListNode *next) : val(x), next(next) {}
* };
*/
class Solution {
public:
ListNode* removeNthFromEnd(ListNode* head, int n) {
//快慢指针
ListNode* dummyNode = new ListNode(0);
dummyNode->next = head;
ListNode* slow = dummyNode;
ListNode* fast = head;
while(n--){
fast = fast->next;
}
while(fast){
slow = slow->next;
fast = fast->next;
}
ListNode* tmp = slow->next;
slow->next = slow->next->next;
delete tmp;
return dummyNode->next;
}
};
234. 回文链表
力扣链接
给你一个单链表的头节点 head ,请你判断该链表是否为回文链表。如果是,返回 true ;否则,返回 false 。
示例 1:

输入:head = [1,2,2,1]
输出:true
示例 2:
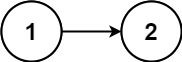
输入:head = [1,2]
输出:false
提示:
链表中节点数目在范围[1, 105] 内
0 <= Node.val <= 9
进阶:你能否用 O(n) 时间复杂度和 O(1) 空间复杂度解决此题?
解法1:双指针
/**
* Definition for singly-linked list.
* struct ListNode {
* int val;
* ListNode *next;
* ListNode() : val(0), next(nullptr) {}
* ListNode(int x) : val(x), next(nullptr) {}
* ListNode(int x, ListNode *next) : val(x), next(next) {}
* };
*/
class Solution {
public:
bool isPalindrome(ListNode* head) {
if(head == nullptr || head->next == nullptr) return true;
ListNode* mid = split(head);
ListNode* firstHead = head;
ListNode* secondHead = reverse(mid);
ListNode* p1 = firstHead, *p2 = secondHead;
while(p1&&p2){
if(p1->val != p2->val) return false;
p1 = p1->next;
p2 = p2->next;
}
return true;
}
ListNode* split(ListNode* head){//返回链表中点
if(head == nullptr) return head;
ListNode* fast = head->next;
ListNode* slow = head;
while(fast && fast->next){
fast = fast->next->next;
slow = slow->next;
}
ListNode* mid = slow->next;
slow->next = nullptr;
return mid;
}
ListNode* reverse(ListNode* head){//反转链表
ListNode* pre = nullptr;
ListNode* cur = head;
while(cur){
ListNode* tmp = cur->next;
cur->next = pre;
pre = cur;
cur = tmp;
}
return pre;
}
};
剑指 Offer 36. 二叉搜索树与双向链表
力扣链接
输入一棵二叉搜索树,将该二叉搜索树转换成一个排序的循环双向链表。要求不能创建任何新的节点,只能调整树中节点指针的指向。
为了让您更好地理解问题,以下面的二叉搜索树为例:
_第71张图片](http://img.e-com-net.com/image/info8/4177112b4d8a4fa88b83d0eb2d1dc4fe.jpg)
我们希望将这个二叉搜索树转化为双向循环链表。链表中的每个节点都有一个前驱和后继指针。对于双向循环链表,第一个节点的前驱是最后一个节点,最后一个节点的后继是第一个节点。
下图展示了上面的二叉搜索树转化成的链表。“head” 表示指向链表中有最小元素的节点。
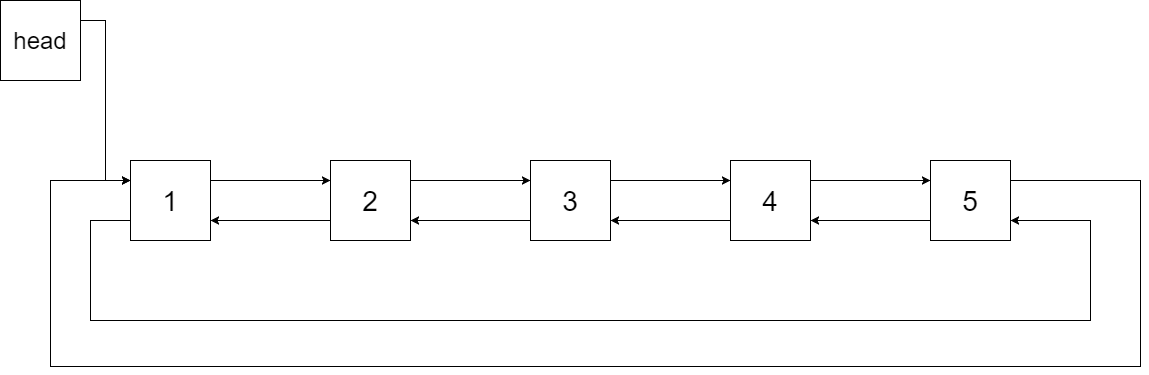
特别地,我们希望可以就地完成转换操作。当转化完成以后,树中节点的左指针需要指向前驱,树中节点的右指针需要指向后继。还需要返回链表中的第一个节点的指针。
注意:本题与主站 426 题相同:https://leetcode-cn.com/problems/convert-binary-search-tree-to-sorted-doubly-linked-list/
注意:此题对比原题有改动。
解法1:dfs
/*
// Definition for a Node.
class Node {
public:
int val;
Node* left;
Node* right;
Node() {}
Node(int _val) {
val = _val;
left = NULL;
right = NULL;
}
Node(int _val, Node* _left, Node* _right) {
val = _val;
left = _left;
right = _right;
}
};
*/
class Solution {
public:
Node* head, *pre;
Node* treeToDoublyList(Node* root) {
if(root == NULL) return NULL;
dfs(root);
head->left = pre;
pre->right = head;
return head;
}
void dfs(Node* cur){
if(cur == NULL) return;
dfs(cur->left);
if(pre == NULL) head = cur;
else{
pre->right = cur;
cur->left = pre;
}
pre = cur;
dfs(cur->right);
}
};
HJ51 输出单向链表中倒数第k个结点
链接
简单 通过率:30.04% 时间限制:1秒 空间限制:32M
知识点
链表
双指针
描述
输入一个单向链表,输出该链表中倒数第k个结点,链表的倒数第1个结点为链表的尾指针。
链表结点定义如下:
struct ListNode
{
int m_nKey;
ListNode* m_pNext;
};
正常返回倒数第k个结点指针,异常返回空指针.
要求:
(1)正序构建链表;
(2)构建后要忘记链表长度。
数据范围:链表长度满足 1 \le n \le 1000 \1≤n≤1000 , k \le n \k≤n ,链表中数据满足 0 \le val \le 10000 \0≤val≤10000
本题有多组样例输入。
输入描述:
输入说明
1 输入链表结点个数
2 输入链表的值
3 输入k的值
输出描述:
输出一个整数
示例1
输入:
8
1 2 3 4 5 6 7 8
4
输出:
5
解法1:快慢指针
#include