华为开源自研AI框架昇思MindSpore应用案例:SSD目标检测
目录
- 一、环境准备
-
- 1.进入ModelArts官网
- 2.使用CodeLab体验Notebook实例
- 二、环境准备
- 三、数据准备与处理
-
- 数据采样
- 数据集创建
- 四、模型构建
- 五、损失函数
- 六、Metrics
- 七、训练过程
- 八、评估
SSD,全称Single Shot MultiBox Detector,是Wei Liu在ECCV 2016上提出的一种目标检测算法。使用Nvidia Titan X在VOC 2007测试集上,SSD对于输入尺寸300x300的网络,达到74.3%mAP以及59FPS;对于512x512的网络,达到了76.9%mAP ,超越当时最强的Faster RCNN(73.2%mAP)。具体可参考论文。 SSD目标检测主流算法分成可以两个类型:
- two-stage方法:RCNN系列
通过算法产生候选框,然后再对这些候选框进行分类和回归。- one-stage方法:yolo和SSD
直接通过主干网络给出类别位置信息,不需要区域生成。
模型结构
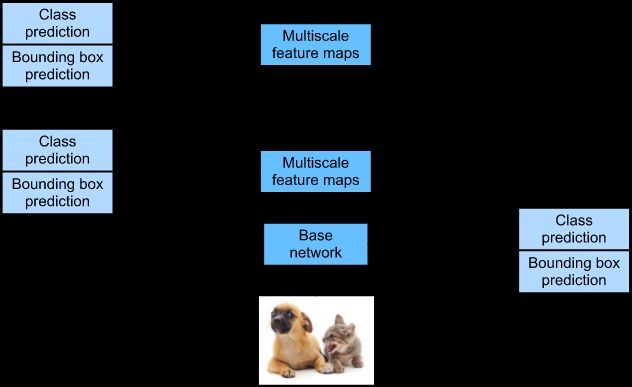
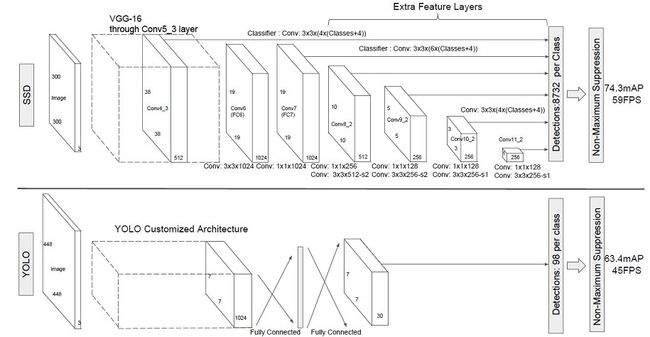
SSD采用VGG16作为基础模型,然后在VGG16的基础上新增了卷积层来获得更多的特征图以用于检测。SSD的网络结构如图所示。上面是SSD模型,下面是Yolo模型,可以明显看到SSD利用了多尺度的特征图做检测。


如果你对MindSpore感兴趣,可以关注昇思MindSpore社区


一、环境准备
1.进入ModelArts官网
云平台帮助用户快速创建和部署模型,管理全周期AI工作流,选择下面的云平台以开始使用昇思MindSpore,获取安装命令,安装MindSpore2.0.0-alpha版本,可以在昇思教程中进入ModelArts官网

选择下方CodeLab立即体验

等待环境搭建完成

2.使用CodeLab体验Notebook实例
下载NoteBook样例代码,SSD目标检测 ,.ipynb为样例代码

选择ModelArts Upload Files上传.ipynb文件

选择Kernel环境

切换至GPU环境,切换成第一个限时免费

进入昇思MindSpore官网,点击上方的安装

获取安装命令

回到Notebook中,在第一块代码前加入命令

conda update -n base -c defaults conda

安装MindSpore 2.0 GPU版本
conda install mindspore=2.0.0a0 -c mindspore -c conda-forge

安装mindvision
pip install mindvision

安装下载download
pip install download

二、环境准备
本案例基于MindSpore实现,开始实验前,请确保本地已经安装了mindspore、download、pycocotools、opencv-python。
三、数据准备与处理
本案例所使用的数据集为coco2017。为了更加方便地保存和加载数据,本案例中在数据读取前首先将coco数据集转换成MindRecord格式。使用MindSpore Record数据格式可以减少磁盘IO、网络IO开销,从而获得更好的使用体验和性能提升。 首先我们需要下载处理好的MindRecord格式的coco数据集。 运行以下代码将数据集下载并解压到指定路径。
from download import download
dataset_url = "https://mindspore-website.obs.cn-north-4.myhuaweicloud.com/notebook/datasets/ssd_datasets.zip"
path = "./"
path = download(dataset_url, path, kind="zip", replace=True)

首先我们为数据处理定义一些输入:
coco_root = "./datasets/"
anno_json = "./datasets/annotations/instances_val2017.json"
train_cls = ['background', 'person', 'bicycle', 'car', 'motorcycle', 'airplane', 'bus',
'train', 'truck', 'boat', 'traffic light', 'fire hydrant',
'stop sign', 'parking meter', 'bench', 'bird', 'cat', 'dog',
'horse', 'sheep', 'cow', 'elephant', 'bear', 'zebra',
'giraffe', 'backpack', 'umbrella', 'handbag', 'tie',
'suitcase', 'frisbee', 'skis', 'snowboard', 'sports ball',
'kite', 'baseball bat', 'baseball glove', 'skateboard',
'surfboard', 'tennis racket', 'bottle', 'wine glass', 'cup',
'fork', 'knife', 'spoon', 'bowl', 'banana', 'apple',
'sandwich', 'orange', 'broccoli', 'carrot', 'hot dog', 'pizza',
'donut', 'cake', 'chair', 'couch', 'potted plant', 'bed',
'dining table', 'toilet', 'tv', 'laptop', 'mouse', 'remote',
'keyboard', 'cell phone', 'microwave', 'oven', 'toaster', 'sink',
'refrigerator', 'book', 'clock', 'vase', 'scissors',
'teddy bear', 'hair drier', 'toothbrush']
train_cls_dict = {}
for i, cls in enumerate(train_cls):
train_cls_dict[cls] = i

数据采样
为了使模型对于各种输入对象大小和形状更加鲁棒,SSD算法每个训练图像通过以下选项之一随机采样:
- 使用整个原始输入图像
- 采样一个区域,使采样区域和原始图片最小的交并比重叠为0.1,0.3,0.5,0.7或0.9
- 随机采样一个区域
每个采样区域的大小为原始图像大小的[0.3,1],长宽比在1/2和2之间。如果真实标签框中心在采样区域内,则保留两者重叠部分作为新图片的真实标注框。在上述采样步骤之后,将每个采样区域大小调整为固定大小,并以0.5的概率水平翻转。
import cv2
import numpy as np
def _rand(a=0., b=1.):
return np.random.rand() * (b - a) + a
def intersect(box_a, box_b):
"""Compute the intersect of two sets of boxes."""
max_yx = np.minimum(box_a[:, 2:4], box_b[2:4])
min_yx = np.maximum(box_a[:, :2], box_b[:2])
inter = np.clip((max_yx - min_yx), a_min=0, a_max=np.inf)
return inter[:, 0] * inter[:, 1]
def jaccard_numpy(box_a, box_b):
"""Compute the jaccard overlap of two sets of boxes."""
inter = intersect(box_a, box_b)
area_a = ((box_a[:, 2] - box_a[:, 0]) *
(box_a[:, 3] - box_a[:, 1]))
area_b = ((box_b[2] - box_b[0]) *
(box_b[3] - box_b[1]))
union = area_a + area_b - inter
return inter / union
def random_sample_crop(image, boxes):
"""Crop images and boxes randomly."""
height, width, _ = image.shape
min_iou = np.random.choice([None, 0.1, 0.3, 0.5, 0.7, 0.9])
if min_iou is None:
return image, boxes
for _ in range(50):
image_t = image
w = _rand(0.3, 1.0) * width
h = _rand(0.3, 1.0) * height
# aspect ratio constraint b/t .5 & 2
if h / w < 0.5 or h / w > 2:
continue
left = _rand() * (width - w)
top = _rand() * (height - h)
rect = np.array([int(top), int(left), int(top + h), int(left + w)])
overlap = jaccard_numpy(boxes, rect)
# dropout some boxes
drop_mask = overlap > 0
if not drop_mask.any():
continue
if overlap[drop_mask].min() < min_iou and overlap[drop_mask].max() > (min_iou + 0.2):
continue
image_t = image_t[rect[0]:rect[2], rect[1]:rect[3], :]
centers = (boxes[:, :2] + boxes[:, 2:4]) / 2.0
m1 = (rect[0] < centers[:, 0]) * (rect[1] < centers[:, 1])
m2 = (rect[2] > centers[:, 0]) * (rect[3] > centers[:, 1])
# mask in that both m1 and m2 are true
mask = m1 * m2 * drop_mask
# have any valid boxes? try again if not
if not mask.any():
continue
# take only matching gt boxes
boxes_t = boxes[mask, :].copy()
boxes_t[:, :2] = np.maximum(boxes_t[:, :2], rect[:2])
boxes_t[:, :2] -= rect[:2]
boxes_t[:, 2:4] = np.minimum(boxes_t[:, 2:4], rect[2:4])
boxes_t[:, 2:4] -= rect[:2]
return image_t, boxes_t
return image, boxes
def ssd_bboxes_encode(boxes):
"""Labels anchors with ground truth inputs."""
def jaccard_with_anchors(bbox):
"""Compute jaccard score a box and the anchors."""
# Intersection bbox and volume.
ymin = np.maximum(y1, bbox[0])
xmin = np.maximum(x1, bbox[1])
ymax = np.minimum(y2, bbox[2])
xmax = np.minimum(x2, bbox[3])
w = np.maximum(xmax - xmin, 0.)
h = np.maximum(ymax - ymin, 0.)
# Volumes.
inter_vol = h * w
union_vol = vol_anchors + (bbox[2] - bbox[0]) * (bbox[3] - bbox[1]) - inter_vol
jaccard = inter_vol / union_vol
return np.squeeze(jaccard)
pre_scores = np.zeros((8732), dtype=np.float32)
t_boxes = np.zeros((8732, 4), dtype=np.float32)
t_label = np.zeros((8732), dtype=np.int64)
for bbox in boxes:
label = int(bbox[4])
scores = jaccard_with_anchors(bbox)
idx = np.argmax(scores)
scores[idx] = 2.0
mask = (scores > matching_threshold)
mask = mask & (scores > pre_scores)
pre_scores = np.maximum(pre_scores, scores * mask)
t_label = mask * label + (1 - mask) * t_label
for i in range(4):
t_boxes[:, i] = mask * bbox[i] + (1 - mask) * t_boxes[:, i]
index = np.nonzero(t_label)
# Transform to tlbr.
bboxes = np.zeros((8732, 4), dtype=np.float32)
bboxes[:, [0, 1]] = (t_boxes[:, [0, 1]] + t_boxes[:, [2, 3]]) / 2
bboxes[:, [2, 3]] = t_boxes[:, [2, 3]] - t_boxes[:, [0, 1]]
# Encode features.
bboxes_t = bboxes[index]
default_boxes_t = default_boxes[index]
bboxes_t[:, :2] = (bboxes_t[:, :2] - default_boxes_t[:, :2]) / (default_boxes_t[:, 2:] * 0.1)
tmp = np.maximum(bboxes_t[:, 2:4] / default_boxes_t[:, 2:4], 0.000001)
bboxes_t[:, 2:4] = np.log(tmp) / 0.2
bboxes[index] = bboxes_t
num_match = np.array([len(np.nonzero(t_label)[0])], dtype=np.int32)
return bboxes, t_label.astype(np.int32), num_match
def preprocess_fn(img_id, image, box, is_training):
"""Preprocess function for dataset."""
cv2.setNumThreads(2)
def _infer_data(image, input_shape):
img_h, img_w, _ = image.shape
input_h, input_w = input_shape
image = cv2.resize(image, (input_w, input_h))
# When the channels of image is 1
if len(image.shape) == 2:
image = np.expand_dims(image, axis=-1)
image = np.concatenate([image, image, image], axis=-1)
return img_id, image, np.array((img_h, img_w), np.float32)
def _data_aug(image, box, is_training, image_size=(300, 300)):
ih, iw, _ = image.shape
h, w = image_size
if not is_training:
return _infer_data(image, image_size)
# Random crop
box = box.astype(np.float32)
image, box = random_sample_crop(image, box)
ih, iw, _ = image.shape
# Resize image
image = cv2.resize(image, (w, h))
# Flip image or not
flip = _rand() < .5
if flip:
image = cv2.flip(image, 1, dst=None)
# When the channels of image is 1
if len(image.shape) == 2:
image = np.expand_dims(image, axis=-1)
image = np.concatenate([image, image, image], axis=-1)
box[:, [0, 2]] = box[:, [0, 2]] / ih
box[:, [1, 3]] = box[:, [1, 3]] / iw
if flip:
box[:, [1, 3]] = 1 - box[:, [3, 1]]
box, label, num_match = ssd_bboxes_encode(box)
return image, box, label, num_match
return _data_aug(image, box, is_training, image_size=[300, 300])
数据集创建
from mindspore import Tensor
from mindspore.dataset import MindDataset
from mindspore.dataset.vision import Decode, HWC2CHW, Normalize, RandomColorAdjust
def create_ssd_dataset(mindrecord_file, batch_size=32, device_num=1, rank=0,
is_training=True, num_parallel_workers=1, use_multiprocessing=True):
"""Create SSD dataset with MindDataset."""
dataset = MindDataset(mindrecord_file, columns_list=["img_id", "image", "annotation"], num_shards=device_num,
shard_id=rank, num_parallel_workers=num_parallel_workers, shuffle=is_training)
decode = Decode()
dataset = dataset.map(operations=decode, input_columns=["image"])
change_swap_op = HWC2CHW()
# Computed from random subset of ImageNet training images
normalize_op = Normalize(mean=[0.485 * 255, 0.456 * 255, 0.406 * 255],
std=[0.229 * 255, 0.224 * 255, 0.225 * 255])
color_adjust_op = RandomColorAdjust(brightness=0.4, contrast=0.4, saturation=0.4)
compose_map_func = (lambda img_id, image, annotation: preprocess_fn(img_id, image, annotation, is_training))
if is_training:
output_columns = ["image", "box", "label", "num_match"]
trans = [color_adjust_op, normalize_op, change_swap_op]
else:
output_columns = ["img_id", "image", "image_shape"]
trans = [normalize_op, change_swap_op]
dataset = dataset.map(operations=compose_map_func, input_columns=["img_id", "image", "annotation"],
output_columns=output_columns, python_multiprocessing=use_multiprocessing,
num_parallel_workers=num_parallel_workers)
dataset = dataset.map(operations=trans, input_columns=["image"], python_multiprocessing=use_multiprocessing,
num_parallel_workers=num_parallel_workers)
dataset = dataset.batch(batch_size, drop_remainder=True)
return dataset
四、模型构建
from mindspore import nn
def _make_layer(channels):
in_channels = channels[0]
layers = []
for out_channels in channels[1:]:
layers.append(nn.Conv2d(in_channels=in_channels, out_channels=out_channels, kernel_size=3))
layers.append(nn.ReLU())
in_channels = out_channels
return nn.SequentialCell(layers)
class Vgg16(nn.Cell):
"""VGG16 module."""
def __init__(self):
super(Vgg16, self).__init__()
self.b1 = _make_layer([3, 64, 64])
self.b2 = _make_layer([64, 128, 128])
self.b3 = _make_layer([128, 256, 256, 256])
self.b4 = _make_layer([256, 512, 512, 512])
self.b5 = _make_layer([512, 512, 512, 512])
self.m1 = nn.MaxPool2d(kernel_size=2, stride=2, pad_mode='SAME')
self.m2 = nn.MaxPool2d(kernel_size=2, stride=2, pad_mode='SAME')
self.m3 = nn.MaxPool2d(kernel_size=2, stride=2, pad_mode='SAME')
self.m4 = nn.MaxPool2d(kernel_size=2, stride=2, pad_mode='SAME')
self.m5 = nn.MaxPool2d(kernel_size=3, stride=1, pad_mode='SAME')
def construct(self, x):
# block1
x = self.b1(x)
x = self.m1(x)
# block2
x = self.b2(x)
x = self.m2(x)
# block3
x = self.b3(x)
x = self.m3(x)
# block4
x = self.b4(x)
block4 = x
x = self.m4(x)
# block5
x = self.b5(x)
x = self.m5(x)
return block4, x
import mindspore as ms
import mindspore.nn as nn
import mindspore.ops as ops
def _last_conv2d(in_channel, out_channel, kernel_size=3, stride=1, pad_mod='same', pad=0):
in_channels = in_channel
out_channels = in_channel
depthwise_conv = nn.Conv2d(in_channels, out_channels, kernel_size, stride, pad_mode='same',
padding=pad, group=in_channels)
conv = nn.Conv2d(in_channel, out_channel, kernel_size=1, stride=1, padding=0, pad_mode='same', has_bias=True)
bn = nn.BatchNorm2d(in_channel, eps=1e-3, momentum=0.97,
gamma_init=1, beta_init=0, moving_mean_init=0, moving_var_init=1)
return nn.SequentialCell([depthwise_conv, bn, nn.ReLU6(), conv])
class FlattenConcat(nn.Cell):
"""FlattenConcat module."""
def __init__(self):
super(FlattenConcat, self).__init__()
self.num_ssd_boxes = 8732
def construct(self, inputs):
output = ()
batch_size = ops.shape(inputs[0])[0]
for x in inputs:
x = ops.transpose(x, (0, 2, 3, 1))
output += (ops.reshape(x, (batch_size, -1)),)
res = ops.concat(output, axis=1)
return ops.reshape(res, (batch_size, self.num_ssd_boxes, -1))
class MultiBox(nn.Cell):
"""
Multibox conv layers. Each multibox layer contains class conf scores and localization predictions.
"""
def __init__(self):
super(MultiBox, self).__init__()
num_classes = 81
out_channels = [512, 1024, 512, 256, 256, 256]
num_default = [4, 6, 6, 6, 4, 4]
loc_layers = []
cls_layers = []
for k, out_channel in enumerate(out_channels):
loc_layers += [_last_conv2d(out_channel, 4 * num_default[k],
kernel_size=3, stride=1, pad_mod='same', pad=0)]
cls_layers += [_last_conv2d(out_channel, num_classes * num_default[k],
kernel_size=3, stride=1, pad_mod='same', pad=0)]
self.multi_loc_layers = nn.CellList(loc_layers)
self.multi_cls_layers = nn.CellList(cls_layers)
self.flatten_concat = FlattenConcat()
def construct(self, inputs):
loc_outputs = ()
cls_outputs = ()
for i in range(len(self.multi_loc_layers)):
loc_outputs += (self.multi_loc_layers[i](inputs[i]),)
cls_outputs += (self.multi_cls_layers[i](inputs[i]),)
return self.flatten_concat(loc_outputs), self.flatten_concat(cls_outputs)
class SSD300Vgg16(nn.Cell):
"""SSD300Vgg16 module."""
def __init__(self):
super(SSD300Vgg16, self).__init__()
# VGG16 backbone: block1~5
self.backbone = Vgg16()
# SSD blocks: block6~7
self.b6_1 = nn.Conv2d(in_channels=512, out_channels=1024, kernel_size=3, padding=6, dilation=6, pad_mode='pad')
self.b6_2 = nn.Dropout(p=0.5)
self.b7_1 = nn.Conv2d(in_channels=1024, out_channels=1024, kernel_size=1)
self.b7_2 = nn.Dropout(p=0.5)
# Extra Feature Layers: block8~11
self.b8_1 = nn.Conv2d(in_channels=1024, out_channels=256, kernel_size=1, padding=1, pad_mode='pad')
self.b8_2 = nn.Conv2d(in_channels=256, out_channels=512, kernel_size=3, stride=2, pad_mode='valid')
self.b9_1 = nn.Conv2d(in_channels=512, out_channels=128, kernel_size=1, padding=1, pad_mode='pad')
self.b9_2 = nn.Conv2d(in_channels=128, out_channels=256, kernel_size=3, stride=2, pad_mode='valid')
self.b10_1 = nn.Conv2d(in_channels=256, out_channels=128, kernel_size=1)
self.b10_2 = nn.Conv2d(in_channels=128, out_channels=256, kernel_size=3, pad_mode='valid')
self.b11_1 = nn.Conv2d(in_channels=256, out_channels=128, kernel_size=1)
self.b11_2 = nn.Conv2d(in_channels=128, out_channels=256, kernel_size=3, pad_mode='valid')
# boxes
self.multi_box = MultiBox()
def construct(self, x):
# VGG16 backbone: block1~5
block4, x = self.backbone(x)
# SSD blocks: block6~7
x = self.b6_1(x) # 1024
x = self.b6_2(x)
x = self.b7_1(x) # 1024
x = self.b7_2(x)
block7 = x
# Extra Feature Layers: block8~11
x = self.b8_1(x) # 256
x = self.b8_2(x) # 512
block8 = x
x = self.b9_1(x) # 128
x = self.b9_2(x) # 256
block9 = x
x = self.b10_1(x) # 128
x = self.b10_2(x) # 256
block10 = x
x = self.b11_1(x) # 128
x = self.b11_2(x) # 256
block11 = x
# boxes
multi_feature = (block4, block7, block8, block9, block10, block11)
pred_loc, pred_label = self.multi_box(multi_feature)
if not self.training:
pred_label = ops.sigmoid(pred_label)
pred_loc = pred_loc.astype(ms.float32)
pred_label = pred_label.astype(ms.float32)
return pred_loc, pred_label
五、损失函数
def class_loss(logits, label):
"""Calculate category losses."""
label = ops.one_hot(label, ops.shape(logits)[-1], Tensor(1.0, ms.float32), Tensor(0.0, ms.float32))
weight = ops.ones_like(logits)
pos_weight = ops.ones_like(logits)
sigmiod_cross_entropy = ops.binary_cross_entropy_with_logits(logits, label, weight.astype(ms.float32), pos_weight.astype(ms.float32))
sigmoid = ops.sigmoid(logits)
label = label.astype(ms.float32)
p_t = label * sigmoid + (1 - label) * (1 - sigmoid)
modulating_factor = ops.pow(1 - p_t, 2.0)
alpha_weight_factor = label * 0.75 + (1 - label) * (1 - 0.75)
focal_loss = modulating_factor * alpha_weight_factor * sigmiod_cross_entropy
return focal_loss

六、Metrics
在SSD中,训练过程是不需要用到非极大值抑制(NMS),但当进行检测时,例如输入一张图片要求输出框的时候,需要用到NMS过滤掉那些重叠度较大的预测框。 非极大值抑制的流程如下:
- 根据置信度得分进行排序
- 选择置信度最高的比边界框添加到最终输出列表中,将其从边界框列表中删除
- 计算所有边界框的面积
- 计算置信度最高的边界框与其它候选框的IoU
- 删除IoU大于阈值的边界框
- 重复上述过程,直至边界框列表为空
import json
from pycocotools.coco import COCO
from pycocotools.cocoeval import COCOeval
def apply_eval(eval_param_dict):
net = eval_param_dict["net"]
net.set_train(False)
ds = eval_param_dict["dataset"]
anno_json = eval_param_dict["anno_json"]
coco_metrics = COCOMetrics(anno_json=anno_json,
classes=train_cls,
num_classes=81,
max_boxes=100,
nms_threshold=0.6,
min_score=0.1)
for data in ds.create_dict_iterator(output_numpy=True, num_epochs=1):
img_id = data['img_id']
img_np = data['image']
image_shape = data['image_shape']
output = net(Tensor(img_np))
for batch_idx in range(img_np.shape[0]):
pred_batch = {
"boxes": output[0].asnumpy()[batch_idx],
"box_scores": output[1].asnumpy()[batch_idx],
"img_id": int(np.squeeze(img_id[batch_idx])),
"image_shape": image_shape[batch_idx]
}
coco_metrics.update(pred_batch)
eval_metrics = coco_metrics.get_metrics()
return eval_metrics
def apply_nms(all_boxes, all_scores, thres, max_boxes):
"""Apply NMS to bboxes."""
y1 = all_boxes[:, 0]
x1 = all_boxes[:, 1]
y2 = all_boxes[:, 2]
x2 = all_boxes[:, 3]
areas = (x2 - x1 + 1) * (y2 - y1 + 1)
order = all_scores.argsort()[::-1]
keep = []
while order.size > 0:
i = order[0]
keep.append(i)
if len(keep) >= max_boxes:
break
xx1 = np.maximum(x1[i], x1[order[1:]])
yy1 = np.maximum(y1[i], y1[order[1:]])
xx2 = np.minimum(x2[i], x2[order[1:]])
yy2 = np.minimum(y2[i], y2[order[1:]])
w = np.maximum(0.0, xx2 - xx1 + 1)
h = np.maximum(0.0, yy2 - yy1 + 1)
inter = w * h
ovr = inter / (areas[i] + areas[order[1:]] - inter)
inds = np.where(ovr <= thres)[0]
order = order[inds + 1]
return keep
class COCOMetrics:
"""Calculate mAP of predicted bboxes."""
def __init__(self, anno_json, classes, num_classes, min_score, nms_threshold, max_boxes):
self.num_classes = num_classes
self.classes = classes
self.min_score = min_score
self.nms_threshold = nms_threshold
self.max_boxes = max_boxes
self.val_cls_dict = {i: cls for i, cls in enumerate(classes)}
self.coco_gt = COCO(anno_json)
cat_ids = self.coco_gt.loadCats(self.coco_gt.getCatIds())
self.class_dict = {cat['name']: cat['id'] for cat in cat_ids}
self.predictions = []
self.img_ids = []
def update(self, batch):
pred_boxes = batch['boxes']
box_scores = batch['box_scores']
img_id = batch['img_id']
h, w = batch['image_shape']
final_boxes = []
final_label = []
final_score = []
self.img_ids.append(img_id)
for c in range(1, self.num_classes):
class_box_scores = box_scores[:, c]
score_mask = class_box_scores > self.min_score
class_box_scores = class_box_scores[score_mask]
class_boxes = pred_boxes[score_mask] * [h, w, h, w]
if score_mask.any():
nms_index = apply_nms(class_boxes, class_box_scores, self.nms_threshold, self.max_boxes)
class_boxes = class_boxes[nms_index]
class_box_scores = class_box_scores[nms_index]
final_boxes += class_boxes.tolist()
final_score += class_box_scores.tolist()
final_label += [self.class_dict[self.val_cls_dict[c]]] * len(class_box_scores)
for loc, label, score in zip(final_boxes, final_label, final_score):
res = {}
res['image_id'] = img_id
res['bbox'] = [loc[1], loc[0], loc[3] - loc[1], loc[2] - loc[0]]
res['score'] = score
res['category_id'] = label
self.predictions.append(res)
def get_metrics(self):
with open('predictions.json', 'w') as f:
json.dump(self.predictions, f)
coco_dt = self.coco_gt.loadRes('predictions.json')
E = COCOeval(self.coco_gt, coco_dt, iouType='bbox')
E.params.imgIds = self.img_ids
E.evaluate()
E.accumulate()
E.summarize()
return E.stats[0]
class SsdInferWithDecoder(nn.Cell):
"""
SSD Infer wrapper to decode the bbox locations."""
def __init__(self, network, default_boxes, ckpt_path):
super(SsdInferWithDecoder, self).__init__()
param_dict = ms.load_checkpoint(ckpt_path)
ms.load_param_into_net(network, param_dict)
self.network = network
self.default_boxes = default_boxes
self.prior_scaling_xy = 0.1
self.prior_scaling_wh = 0.2
def construct(self, x):
pred_loc, pred_label = self.network(x)
default_bbox_xy = self.default_boxes[..., :2]
default_bbox_wh = self.default_boxes[..., 2:]
pred_xy = pred_loc[..., :2] * self.prior_scaling_xy * default_bbox_wh + default_bbox_xy
pred_wh = ops.exp(pred_loc[..., 2:] * self.prior_scaling_wh) * default_bbox_wh
pred_xy_0 = pred_xy - pred_wh / 2.0
pred_xy_1 = pred_xy + pred_wh / 2.0
pred_xy = ops.concat((pred_xy_0, pred_xy_1), -1)
pred_xy = ops.maximum(pred_xy, 0)
pred_xy = ops.minimum(pred_xy, 1)
return pred_xy, pred_label
七、训练过程
import math
import itertools as it
from mindspore.common import set_seed
class GeneratDefaultBoxes():
"""
Generate Default boxes for SSD, follows the order of (W, H, archor_sizes).
`self.default_boxes` has a shape of [archor_sizes, H, W, 4], the last dimension is [y, x, h, w].
`self.default_boxes_tlbr` has a shape as `self.default_boxes`, the last dimension is [y1, x1, y2, x2].
"""
def __init__(self):
fk = 300 / np.array([8, 16, 32, 64, 100, 300])
scale_rate = (0.95 - 0.1) / (len([4, 6, 6, 6, 4, 4]) - 1)
scales = [0.1 + scale_rate * i for i in range(len([4, 6, 6, 6, 4, 4]))] + [1.0]
self.default_boxes = []
for idex, feature_size in enumerate([38, 19, 10, 5, 3, 1]):
sk1 = scales[idex]
sk2 = scales[idex + 1]
sk3 = math.sqrt(sk1 * sk2)
if idex == 0 and not [[2], [2, 3], [2, 3], [2, 3], [2], [2]][idex]:
w, h = sk1 * math.sqrt(2), sk1 / math.sqrt(2)
all_sizes = [(0.1, 0.1), (w, h), (h, w)]
else:
all_sizes = [(sk1, sk1)]
for aspect_ratio in [[2], [2, 3], [2, 3], [2, 3], [2], [2]][idex]:
w, h = sk1 * math.sqrt(aspect_ratio), sk1 / math.sqrt(aspect_ratio)
all_sizes.append((w, h))
all_sizes.append((h, w))
all_sizes.append((sk3, sk3))
assert len(all_sizes) == [4, 6, 6, 6, 4, 4][idex]
for i, j in it.product(range(feature_size), repeat=2):
for w, h in all_sizes:
cx, cy = (j + 0.5) / fk[idex], (i + 0.5) / fk[idex]
self.default_boxes.append([cy, cx, h, w])
def to_tlbr(cy, cx, h, w):
return cy - h / 2, cx - w / 2, cy + h / 2, cx + w / 2
# For IoU calculation
self.default_boxes_tlbr = np.array(tuple(to_tlbr(*i) for i in self.default_boxes), dtype='float32')
self.default_boxes = np.array(self.default_boxes, dtype='float32')
default_boxes_tlbr = GeneratDefaultBoxes().default_boxes_tlbr
default_boxes = GeneratDefaultBoxes().default_boxes
y1, x1, y2, x2 = np.split(default_boxes_tlbr[:, :4], 4, axis=-1)
vol_anchors = (x2 - x1) * (y2 - y1)
matching_threshold = 0.5

from mindspore.common.initializer import initializer, TruncatedNormal
def init_net_param(network, initialize_mode='TruncatedNormal'):
"""Init the parameters in net."""
params = network.trainable_params()
for p in params:
if 'beta' not in p.name and 'gamma' not in p.name and 'bias' not in p.name:
if initialize_mode == 'TruncatedNormal':
p.set_data(initializer(TruncatedNormal(0.02), p.data.shape, p.data.dtype))
else:
p.set_data(initialize_mode, p.data.shape, p.data.dtype)
def get_lr(global_step, lr_init, lr_end, lr_max, warmup_epochs, total_epochs, steps_per_epoch):
""" generate learning rate array"""
lr_each_step = []
total_steps = steps_per_epoch * total_epochs
warmup_steps = steps_per_epoch * warmup_epochs
for i in range(total_steps):
if i < warmup_steps:
lr = lr_init + (lr_max - lr_init) * i / warmup_steps
else:
lr = lr_end + (lr_max - lr_end) * (1. + math.cos(math.pi * (i - warmup_steps) / (total_steps - warmup_steps))) / 2.
if lr < 0.0:
lr = 0.0
lr_each_step.append(lr)
current_step = global_step
lr_each_step = np.array(lr_each_step).astype(np.float32)
learning_rate = lr_each_step[current_step:]
return learning_rate

import time
from mindspore.amp import DynamicLossScaler
set_seed(1)
# load data
mindrecord_dir = "./datasets/MindRecord_COCO"
mindrecord_file = "./datasets/MindRecord_COCO/ssd.mindrecord0"
dataset = create_ssd_dataset(mindrecord_file, batch_size=5, rank=0, use_multiprocessing=True)
dataset_size = dataset.get_dataset_size()
image, get_loc, gt_label, num_matched_boxes = next(dataset.create_tuple_iterator())
# Network definition and initialization
network = SSD300Vgg16()
init_net_param(network)
# Define the learning rate
lr = Tensor(get_lr(global_step=0 * dataset_size,
lr_init=0.001, lr_end=0.001 * 0.05, lr_max=0.05,
warmup_epochs=2, total_epochs=60, steps_per_epoch=dataset_size))
# Define the optimizer
opt = nn.Momentum(filter(lambda x: x.requires_grad, network.get_parameters()), lr,
0.9, 0.00015, float(1024))
# Define the forward procedure
def forward_fn(x, gt_loc, gt_label, num_matched_boxes):
pred_loc, pred_label = network(x)
mask = ops.less(0, gt_label).astype(ms.float32)
num_matched_boxes = ops.sum(num_matched_boxes.astype(ms.float32))
# Positioning loss
mask_loc = ops.tile(ops.expand_dims(mask, -1), (1, 1, 4))
smooth_l1 = nn.SmoothL1Loss()(pred_loc, gt_loc) * mask_loc
loss_loc = ops.sum(ops.sum(smooth_l1, -1), -1)
# Category loss
loss_cls = class_loss(pred_label, gt_label)
loss_cls = ops.sum(loss_cls, (1, 2))
return ops.sum((loss_cls + loss_loc) / num_matched_boxes)
grad_fn = ms.value_and_grad(forward_fn, None, opt.parameters, has_aux=False)
loss_scaler = DynamicLossScaler(1024, 2, 1000)
# Gradient updates
def train_step(x, gt_loc, gt_label, num_matched_boxes):
loss, grads = grad_fn(x, gt_loc, gt_label, num_matched_boxes)
opt(grads)
return loss
print("=================== Starting Training =====================")
for epoch in range(60):
network.set_train(True)
begin_time = time.time()
for step, (image, get_loc, gt_label, num_matched_boxes) in enumerate(dataset.create_tuple_iterator()):
loss = train_step(image, get_loc, gt_label, num_matched_boxes)
end_time = time.time()
times = end_time - begin_time
print(f"Epoch:[{int(epoch + 1)}/{int(60)}], "
f"loss:{loss} , "
f"time:{times}s ")
ms.save_checkpoint(network, "ssd-60_9.ckpt")
print("=================== Training Success =====================")
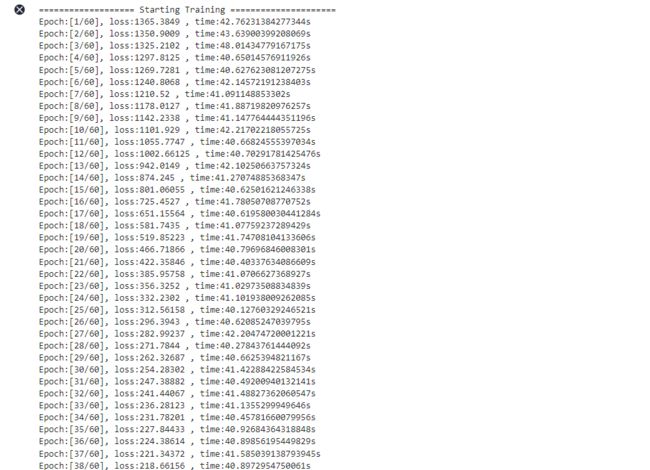
=================== Starting Training =====================
Epoch:[1/60], loss:1365.3849 , time:42.76231384277344s
Epoch:[2/60], loss:1350.9009 , time:43.63900399208069s
Epoch:[3/60], loss:1325.2102 , time:48.01434779167175s
Epoch:[4/60], loss:1297.8125 , time:40.65014576911926s
Epoch:[5/60], loss:1269.7281 , time:40.627623081207275s
Epoch:[6/60], loss:1240.8068 , time:42.14572191238403s
Epoch:[7/60], loss:1210.52 , time:41.091148853302s
Epoch:[8/60], loss:1178.0127 , time:41.88719820976257s
Epoch:[9/60], loss:1142.2338 , time:41.147764444351196s
Epoch:[10/60], loss:1101.929 , time:42.21702218055725s
Epoch:[11/60], loss:1055.7747 , time:40.66824555397034s
Epoch:[12/60], loss:1002.66125 , time:40.70291781425476s
Epoch:[13/60], loss:942.0149 , time:42.10250663757324s
Epoch:[14/60], loss:874.245 , time:41.27074885368347s
Epoch:[15/60], loss:801.06055 , time:40.62501621246338s
Epoch:[16/60], loss:725.4527 , time:41.78050708770752s
Epoch:[17/60], loss:651.15564 , time:40.619580030441284s
Epoch:[18/60], loss:581.7435 , time:41.07759237289429s
Epoch:[19/60], loss:519.85223 , time:41.74708104133606s
Epoch:[20/60], loss:466.71866 , time:40.79696846008301s
Epoch:[21/60], loss:422.35846 , time:40.40337634086609s
Epoch:[22/60], loss:385.95758 , time:41.0706627368927s
Epoch:[23/60], loss:356.3252 , time:41.02973508834839s
Epoch:[24/60], loss:332.2302 , time:41.101938009262085s
Epoch:[25/60], loss:312.56158 , time:40.12760329246521s
Epoch:[26/60], loss:296.3943 , time:40.62085247039795s
Epoch:[27/60], loss:282.99237 , time:42.20474720001221s
Epoch:[28/60], loss:271.7844 , time:40.27843761444092s
Epoch:[29/60], loss:262.32687 , time:40.6625394821167s
Epoch:[30/60], loss:254.28302 , time:41.42288422584534s
Epoch:[31/60], loss:247.38882 , time:40.49200940132141s
Epoch:[32/60], loss:241.44067 , time:41.48827362060547s
Epoch:[33/60], loss:236.28123 , time:41.1355299949646s
Epoch:[34/60], loss:231.78201 , time:40.45781660079956s
Epoch:[35/60], loss:227.84433 , time:40.92684364318848s
Epoch:[36/60], loss:224.38614 , time:40.89856195449829s
Epoch:[37/60], loss:221.34372 , time:41.585039138793945s
Epoch:[38/60], loss:218.66156 , time:40.8972954750061s
Epoch:[39/60], loss:216.29553 , time:42.22093486785889s
Epoch:[40/60], loss:214.20854 , time:40.75188755989075s
Epoch:[41/60], loss:212.36868 , time:41.51768183708191s
Epoch:[42/60], loss:210.74985 , time:40.3460476398468s
Epoch:[43/60], loss:209.32901 , time:40.65240502357483s
Epoch:[44/60], loss:208.08626 , time:41.250218629837036s
Epoch:[45/60], loss:207.00375 , time:40.334686040878296s
Epoch:[46/60], loss:206.06656 , time:40.822086811065674s
Epoch:[47/60], loss:205.2609 , time:40.492422103881836s
Epoch:[48/60], loss:204.57387 , time:41.39555335044861s
Epoch:[49/60], loss:203.9947 , time:40.29546666145325s
Epoch:[50/60], loss:203.51189 , time:39.61115860939026s
Epoch:[51/60], loss:203.11642 , time:41.232492446899414s
Epoch:[52/60], loss:202.79791 , time:40.896180152893066s
Epoch:[53/60], loss:202.54779 , time:40.62282419204712s
Epoch:[54/60], loss:202.35779 , time:40.751235485076904s
Epoch:[55/60], loss:202.2188 , time:41.790447473526s
Epoch:[56/60], loss:202.12277 , time:41.371476888656616s
Epoch:[57/60], loss:202.05978 , time:41.00389575958252s
Epoch:[58/60], loss:202.02513 , time:40.384965658187866s
Epoch:[59/60], loss:202.00772 , time:40.91265916824341s
Epoch:[60/60], loss:201.9999 , time:41.31216502189636s
=================== Training Success =====================
八、评估
mindrecord_file = "./datasets/MindRecord_COCO/ssd_eval.mindrecord0"
def ssd_eval(dataset_path, ckpt_path, anno_json):
"""SSD evaluation."""
batch_size = 1
ds = create_ssd_dataset(dataset_path, batch_size=batch_size,
is_training=False, use_multiprocessing=False)
network = SSD300Vgg16()
print("Load Checkpoint!")
net = SsdInferWithDecoder(network, Tensor(default_boxes), ckpt_path)
net.set_train(False)
total = ds.get_dataset_size() * batch_size
print("\n========================================\n")
print("total images num: ", total)
eval_param_dict = {"net": net, "dataset": ds, "anno_json": anno_json}
mAP = apply_eval(eval_param_dict)
print("\n========================================\n")
print(f"mAP: {mAP}")
def eval_net():
print("Start Eval!")
ssd_eval(mindrecord_file, "./ssd-60_9.ckpt", anno_json)
eval_net()
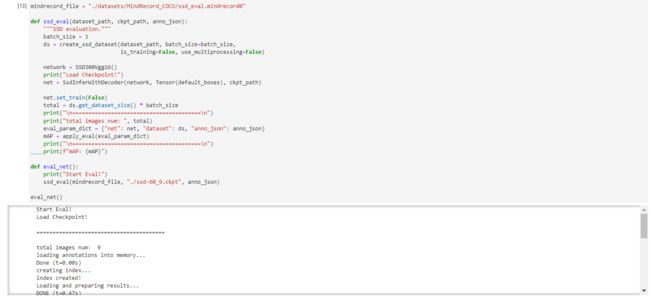
Start Eval!
Load Checkpoint!
========================================
total images num: 9
loading annotations into memory...
Done (t=0.00s)
creating index...
index created!
Loading and preparing results...
DONE (t=0.47s)
creating index...
index created!
Running per image evaluation...
Evaluate annotation type *bbox*
DONE (t=0.97s).
Accumulating evaluation results...
DONE (t=0.20s).
Average Precision (AP) @[ IoU=0.50:0.95 | area= all | maxDets=100 ] = 0.003
Average Precision (AP) @[ IoU=0.50 | area= all | maxDets=100 ] = 0.006
Average Precision (AP) @[ IoU=0.75 | area= all | maxDets=100 ] = 0.000
Average Precision (AP) @[ IoU=0.50:0.95 | area= small | maxDets=100 ] = 0.000
Average Precision (AP) @[ IoU=0.50:0.95 | area=medium | maxDets=100 ] = 0.052
Average Precision (AP) @[ IoU=0.50:0.95 | area= large | maxDets=100 ] = 0.016
Average Recall (AR) @[ IoU=0.50:0.95 | area= all | maxDets= 1 ] = 0.005
Average Recall (AR) @[ IoU=0.50:0.95 | area= all | maxDets= 10 ] = 0.037
Average Recall (AR) @[ IoU=0.50:0.95 | area= all | maxDets=100 ] = 0.071
Average Recall (AR) @[ IoU=0.50:0.95 | area= small | maxDets=100 ] = 0.000
Average Recall (AR) @[ IoU=0.50:0.95 | area=medium | maxDets=100 ] = 0.057
Average Recall (AR) @[ IoU=0.50:0.95 | area= large | maxDets=100 ] = 0.328
========================================
mAP: 0.0025924737758294216