论文阅读| 《An Integrated Pipeline Architecture for Modeling Urban Land Use, Travel Demand, and Traffic 》
整合了土地利用、交通需求模型和交通分配模型
目录
- 摘要
- 1、 介绍
- 1.1 需要一个集成的模型系统
- 1.2 管道体系结构概述
- 2 土地利用模型:urbansim
- 2.1 概述
- 2.2 输入
- 2.3 如何运行
- 可达性的作用
- 模型系统设计和地理水平分析
- 离散选择模型
- 1. 选择模型的计算过程
- 2. 下面是urbansim选择模型中价格调整的过程:
- 3. 备选方案的限制
- 2.4 输出
- 2.5 校准和验证
- 3. 短期交通出行需求模型:ActivitySim
- 3.1 概述
- 3.2 输入
- 3.3 工作原理
- 3.4 输出
- 3.5 校准和验证
- 4. 道路网
- 4.1 概述
- 4.2 网络创建、构建和处理
- 4.3 BPR系数计算和假设
- 4.4 将基于区域的出行需求(OD)链接到道路网络
- 5. 交通分配模型
- 5.1 概述
- 5.2 输入
- 5.3 怎么运行
- 5.4 输出
- 5.5 校准和验证
- 6. 讨论与总结
摘要
ubansim
可作为一个情景分析工具,帮助规划师去对比不同政策决策对长期土地利用预测的影响。
ActivitySim:
是基于活动的交通需求模型,可以生成OD数据。
交通分配:
基于静态的用户平衡分配方法;由交通分配模型产生的拥挤出行时间数据能被反馈会UrbanSim和ActivitySim。
1、 介绍
1.1 需要一个集成的模型系统
项目的总体目标:
开发一个包括土地利用、交通需求、交通分配在内的综合模型,以模拟交通基础设施和土地利用政策的综合和累积影响。
管道的概念:
https://www.cnblogs.com/Nicholas0707/p/10787945.html
1.2 管道体系结构概述
项目集成了三个模型:urbansim、ActivitySim、交通分配模型。

pandana:用于网络分析的python库,可以用于计算出行可达性指标和最短路径;
2 土地利用模型:urbansim
2.1 概述
被设计执行几项任务:
- 根据区域交通规划的需要,预测未来10-40年期间的土地利用信息,作为交通模型的输入。
- 可以预测 道路与交通设施投资以及交通服务水平和出行成本改变对土地利用模型的影响。(评估单个项目或整个交通网络变化的影响)
- 预测土地利用政策变化对土地利用的影响。eg:增加特定地点的FAR(Floor Area Ratio ),或允许在以前仅规划为单个用途的区域内进行混合用途开发。
- 可以预测交通投资引起的土地利用发展模式
- 预测环境政策的影响,eg:湿地保护等
- 可以预测宏观经济结构或土地利用增长率的变化。快速或缓慢的增长。甚至一些部门的衰减,都会导致城市空间结构的变化。
- 可以城市人口结构和组成变化对土地利用的影响,以及对不同社会特征(如年龄、家庭规模和收入)居民聚集的空间格局的可能影响。
- 检查主要开发(包括实际的和假设的)对土地使用和交通的潜在影响。这可以用来探索企业搬迁的影响,或者比较大型开发项目的替代地点。
2.2 输入
- 建筑物数据
- 地块数据
- 家庭数据
- 人口数据(人口总量控制数据)
- 就业数据(就业总量控制数据)
- 土地使用条例数据
- 房地产价格与租金数据(用于租金价格模型)
- 家庭出行数据(用于urbansim的家庭区位选择模型)
除了上面的基础数据,urbansim的另外一个主要输入就是情景输入(scenario :
是对模型系统的输入数据和假设的结合,包括研究地区人口和就业增长的宏观经济假设,假定在特定未来某一年建成的交通系统的配置,以及规范每个地点允许的发展类型的总体计划)
1、 控制总量数据:人口、就业总量控制数据
2、 出行数据:区到区(zone to zone),从交通需求模型中得到
3、土地使用计划:总体规划数据,分配到各个地块。
4、 发展限制数据: 每个地块允许的土地使用类型和密度(一个范围)
2.3 如何运行
可达性的作用
可达性是链接交通和土地利用的概念。
度量可达性:
要度量可达性,首先要选择要使用的基本地理单元,目前使用的大多数交通模型依赖区域(zone)。区域的大小可能不同,但最小的是城市的街区。这个方法的缺点是,必须手动定义区域,区域的范围是任意的,太大则无法模拟微观土地利用措施和可步行性。
模型系统设计和地理水平分析
urbansim已经适用于不同层次的地理环境。在这个项目中使用parcel-level。
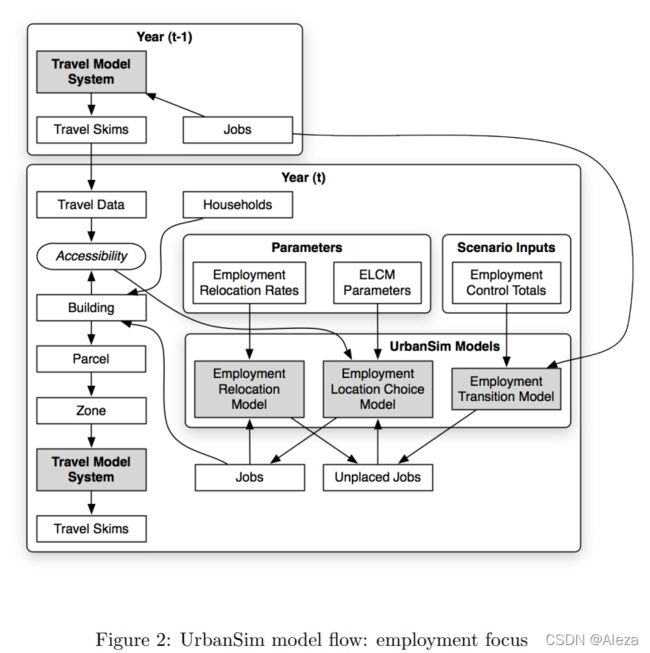


模型以年为单位来预测迁移和位置选择。
离散选择模型
LCM:在urbansim中指的区位选择模型(Location Choice Model)
区位选择模型主要使用离散选择中的多项Logit模型(MNL)
MNL基于随机效用理论(random utility theory)
认为可以改进的部分:用机器学习实现MNL;
之前的叫Choice model ,Choice model 在UrbanSim中以模块化的方式实现,以应对各种各样的选择情况。下图显示了实现的方法:
1. 选择模型的计算过程


2. 下面是urbansim选择模型中价格调整的过程:

开发了一种选择算法,使模型能够模拟短期市场的清算过程。计算区位选择模型的概率步长(?),求每个子市场的概率之和,以计算总需求,并将这个子市场需求估计值与子市场的可供应量进行比较。(意思:进行一次区位选择后,计算市场需求,通过需求与供给的比较,去调整价格)。
对价格进行调整后,并更新区位选择的相关的组件,以反映价格调整后的影响。
这个算法捕获一个关系:在进行区位选择后,需求量增大,会导致价格上涨,这反过来就会抑制需求。
具体的选择过程如下图:

从上图可以看出,调整了价格之后,会反馈到自变量计算这一项(系数不发生改变,就是自变量的值发生了改变,也就是区位选择影响因素的值发生了改变。房价就是区位选择影响因素的最重要的一项。【总结:房价这个自变量的值发生了改变,会影响区位选择】)
3. 备选方案的限制
在有一些情况下,备选方案是不能进行选择的,也就是会受到限制。我们可以预先决定哪些备选方案(选项、alternatives)是受限的。
eg:
家庭预算有限的就无法选择房价比较高的;
无车的家庭,无法选择单独驾车出行模式(拼车是可以的);
那么,在这些选择着进行选择的时候,就要从备选方案中剔除一些备选方案。
2.4 输出
urbansim作为一个微观模拟模型,基本上产生了与输入相同的输出:
- 家庭表
- 微观个体(个人)表
- 就业表(jobs)
- 地块表(parcels)
- 建筑物表(buildings)
这些表都会进行更新:
比如,新的家庭、就业、建筑物的增减(通过模拟实现,并不是真正的增加和减少了)
通过这种微观数据,urbansim能够生成用户想要的统计数据:房地产数据、经济数据、人口统计数据(范围可以是:人口普查区、城市、县或其他规划地理区域);
交通分析区的总结数据(urbansim输出的,交通分析区的统计数据)通常作为交通需求模型的输入。
2.5 校准和验证
urbansim通常纵向校准,从过去的一个观测年开始,运行到下一个观测年,随着时间的推移,将预测数据与观测数据进行比较。并反复调整校准系数,以提高模型与校准年观测目标的拟合度(fit)。
一般来说最好少使用校准常数,因为过度使用及校准常数会束缚模型,使其对政策变化不敏感。
使用Bayesian Melding(贝叶斯融合)来解释不确定性,以校准模型的不确定性,并能在多次运行模型而不固定随机种子的情况下,计算其模拟预测的置信区间。
3. 短期交通出行需求模型:ActivitySim
3.1 概述
ActivitySim是一个Agent_based 模型;(其他的介绍前面有)。
3.2 输入
需要两份主要的输入数据:
- 与地理相关;
- 另外一组与正在模拟的、进行出行选择的、综合的agent的人口有关;
(1)地理数据:
地理数据的区域level:TAZ(交通分析区级别);
由3部分组成:
- 土地利用特征(地块用途use)
- 出行阻抗矩阵(区到区,阻抗:出行时间、距离或成本)
- 用户定义的,各区域估算的总效用指标表。在交通规划中,这些zone-level 的阻抗和效用通常被称为skims和可达性 (也就是阻抗数据+可达性数据)
土地利用数据包括人口和就业特征(zone-level),以及不同土地利用和建筑类型上的措施(即限制土地的用途和建筑物的类别)。在综合模型中,这些数据直接从urbansim的输出数据中读取。(也就是上面提到的,urbansim输出了新的微观数据之后,我们可以对这些微观数据进行统计,得到不同区域的统计数据)
travel skims 通常由交通分配模型生成。ActivitySim通常希望从一个开放矩阵(OMX)中加载数据。后文提到。
可达性,可直接从skims或者交通网络的任何图像表现形式生成(即能通过交通网络和skims计算得到可达性)。
可达性计算方法:
就是汇总poi数据,(这里的poi数据指的是各种设施:医院、学校等)【见可达性度量文章】;度量可达性,可以简单的计算给定的最短距离内(或最短时间内)可到达的设施的数量。 也可以复杂一点,计算公共设施的综合可达性。
(2)综合人口数据
综合人口数据,包括个体及其特征,以及个体所在的家庭和家庭特征。
注意:ActivitySim和urbansim用相同的综合人口数据,但在urbansim中没有用到个体的数据
【也就是我们得微观到个人,因为交通出行需求模型里需要】
3.3 工作原理
ActivitySim和urbansim一样,依赖于:
- DCM(离散选择模型)
- 随机效用最大化模型(McFadden ,1974)
ActivitySim运行由一系列顺序执行的步骤组成。
单个模型可以分成4类:
1. 长期决策:
有三个长期决策模型:
a.就业场所区位选择
b.学校位置选择
c.auto-ownership(??)——模拟现实世界中并非每天都会做的决策,但是这些决策会对现实世界中的决策产生重大影响。
2. 日常活动模式(GDAP)
GDAP为每个家庭成员进行决策,所有的家庭成员都试图最大化日常出行的效用。
GDAP考虑了强制性出行和非强制性出行,选择出行活动(activity)的原则是最大化个人的效用。(活动产生的效用)
最大化过程涉及家庭中所有成员所有可能组合的估计(不同家庭成员会进行不同的选择,那么就会形成不同的组合情况,计算不同组合产生的效益,找出效益最大的组合)。
【这个步骤在ActivitySim模型中运行时间最长】
3. tour-level决策(出行决策)
tours定义了一系列一起完成的trip链,在两次trip之间没有返回家。
强制出行包含往返学校和工作的trip;
在用户的配置文件中定义了非强制出行的方案,因此这些步骤还包括目的地选择模型;
强制出行的方案已经由长期决策模型计算出来。
每个出行(tour)类型都被分成了单独的模型步骤,用于估计模式选择、出发时间、和出行频率(??)
trip指短程的出行。
4. trip-level决策
模式选择必须在个人trip和tour之间进行,因为给定的出行包含不同的trip,以及不同trip对应不同的模式(mode)
下面:tour:出行;trip:行程
下面是对tour 和trip的个人理解:

行程(trip)出发和到达时间也进行了估算,其余的行程(trip)特征是从行程所属的出行(tour)中继承下来的。【即,trip的出发时间和到达时间和所属的tour不同,其余的属性和tour相同】

3.4 输出
输出包括一个单独的HDF5数据文件,其中有一个对应于每个模型步骤的结果表,以及处于最终更新状态的输入文件的版本。然而为了生成交通分配的交通出行需求,我们只关注出行生成步骤的输出(trip generation step)[OD出行需求矩阵]。
这个输出文件中包含 出发点和目的地所在的区(zone)、开始时间、结束时间,以及每个agent在一天中,进行的每次行程(trip)的模式选择。
下面是ActivitySim模型流程


最终得到的区域级的OD出行需求文件最终被用于交通分配。
3.5 校准和验证
与其他模型相比,ActivitySim是通过对个体的决策过程进行建模。
但是,这个模型并不是要在相同的非集计尺度上进行解释。我们不知道哪一个个体会在某一天使用哪一种模式来完成哪一项活动,而是知道整个群体中的个体行为是怎么样的。
用各种数据集来验证我们的结果,包括:BTAZ(出行调查数据集)、就业-家庭动态计划(LEHD)、加利福利亚家庭出行调查(CHTS)。
4. 道路网
4.1 概述
一旦我们生成了这些综合出行需求数据(OD矩阵,区到区的),我们就可以为了交通分配,进行网络建模(道路网建模)。
建成的道路网模型:拓扑网络,网络是由一系列点,以及连接点的边组成的图(需要了解一下图论)。
本节描述了如何获取这些数据。以及如何构建网络的图形模型,处理其拓扑结构,以及计算和输入相关变量。(在实际应用中,可以从open street map上爬取到道路网络)
4.2 网络创建、构建和处理
道路数据,来自于OSM(open street map);
【关于OSM的数据结构,看其他的文档,包括osm获取到的数据的结构等】
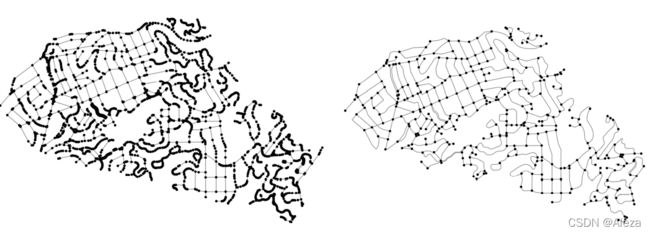
上面是OSMnx进行拓扑简化的效果。
OSM下载道路网数据参考其他博客:
参考教程:https://gitee.com/ni1o1/pygeo-tutorial/blob/master/15-.ipynb
使用OSM下载数据以及处理:
- 区域的道路网络数据
- 下载可驾驶道路网络(OSMnx通过一些元数据标记【 tags】确定哪些路径是可以驾驶的。然后将它们构造成一个图形网络)
- 过滤道路网络,只保留三级道路及以上等级的道路。(需要再了解一下OSM中的道路类型是怎么样的:机动车道、主干道、匝道、未分类道等)
- 过滤掉低等级道路之后,还要移除所有的孤立节点。然后只保留图中最大的弱连通部分。
- 最后,用OSMnx简化图形。
4.3 BPR系数计算和假设
BRP:拥堵函数,定义边(edge)上的出行时间和拥堵之间的关系。一直用BPR函数去模拟在拥堵严重时,通过边所需增加的时间(拥堵额外时间、后面也叫拥堵行程时间);(只要有了简化后的最终处理图【道路网络图】),就可以计算出BPR曲线的系数a0,a1,a2,a3和a4。
下面是BPR函数的式子:
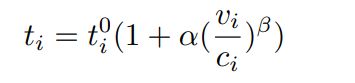
ti: 拥堵时,通过边i的行程时间;
ti0:自由流时,通过边i的行程时间;
vi:单位时间边i上的车辆数;
ci:通行能力(单位时间,边i上的最大车辆数);
α:默认参数为0.15
β:默认参数为4 (在urbansim,中都采用了α和β的默认参数)
对于上面的式子:

a0就是自由流下的行程时间;a1,a2,a3总是0;a4按上面的式子计算。
为了计算这些参数,我们需要关注的有:
- 通行能力
- 在自由流时,通过每条边的时间;
- 还需要边的长度、自由流状态下的速度和车道数信息
用OSM计算变得长度,OSM还包含最大允许车速和车道数等。当信息有缺失时,我们需要进行推断和插补。
下面介绍如何推断和插补:
- 当缺少车道数信息的时候,首先找出边的类型,然后根据这种类型边的车道数的均值,用这个均值来插补。
- 对于缺少最大允许速度的边,通过变类型和车道速,查下表推断出自由流车速:

- 然后,根据自由流速度和边的长度,就可以计算出自由流下,通过边的时间。(即计算出,每条边的自由流行程时间)。

4. 然后,通过边的类型和车道数,查出单位小时每条车道的通行能力;还需要 将(每小时每条车道的通行能力值换算成每秒每边的通行能力)

这样,就可以计算出a0和a4系数值。
4.4 将基于区域的出行需求(OD)链接到道路网络
有OD后,需要进行交通分配,这就需要将OD与道路网链接起来。
ActivitySim得到的OD数据中的起点和终点都是区域(zone),这就需要我们将起点和终点从区域转换为网络节点。
区域——>网络节点:
计算每个区域的质心,确定距离每个区域质心最近的网络节点,以这个最近的网络节点替代区域。
如何确定距离质心最近的网络节点呢?
使用下面的公式:

通过上面的步骤,我们就得到了以下数据:
1. 道路网络
2. 每条边的BPR系数
3. 基于节点的OD数据
下面就可以进行交通分配了。
5. 交通分配模型
5.1 概述
交通分配模型在网络中特定路径上提供车辆,以在OD之间的进行行程。(也就是,将OD矩阵分配到道路网中,道路网中就会出现车辆。)
由此产生的路径分配结果是:在交通网络中,每条边上行驶的车辆总数;然后被用于计算每条边上的行程时间。边上的行驶时间是使用这条边的车辆数量的函数。这些行程时间将会被反馈给Urbansim 和 ActivitySim,被用于计算拥挤状况下的可达性和skims。
5.2 输入
- 网络
- OD出行需求矩阵
- 每条边的BPR系数
网络:
网络基础设施基于一组节点和边,其中连接的边共享一个节点。如果边通过节点连接,则允许车辆从一个边行驶到另一个边。这些边的有序集称为路径。为了让车辆从起点移动到目的地,它必须走特定的路径。起点和终点之间的可能路径由网络拓扑(即边的数量、节点的数量以及这些节点和边之间的连接)定义。在第4节中描述的网络被用作交通分配模型的基础。
BRP系数
之前计算的每条边的BPR系数用于将计算出来的行程时间(伪行程时间)分配给每一条边,作为每条边的负载函数(即边缘上的负载函数)。 这是为了确定,应该把车辆分配到哪些路径。(因为车辆可能会选择需要较少时间的路径)。
5.3 怎么运行
实施的交通分配方法:静态用户平衡分配方法。(wardrop 第一理论)

5.4 输出
- 每个边上的车辆数
- 每个边上的行程时间(用BPR系数计算得出,代表的是每条边的拥挤行程时间)。因为这些行程时间是静态交通分配的结果,则不是精确的行程时间。(之间看的一篇论文中,提到可以直接用高德开放平台API获取行程时间)。
虽然计算出来的行程时间不精确,但是我们也不需要精确的行程时间,因为,边和边之间的比较才是重要的。
5.5 校准和验证
交通分配模型是静态的,则无法很好地模拟实际网络中的交通拥堵,以及反馈。(另看wordrop 第一理论的缺点)。
但是我们可以将每条边上的负载后产生的行程时间与实际数据进行比较,以了解计算行程时间的近似值,以及计算行程时间与实际观测数据的匹配程度。
6. 讨论与总结
###6.1 项目与架构概述
略