基于Flask+Bootstrap+机器学习的世界杯比赛预测系统

♂️ 个人主页:@艾派森的个人主页
✍作者简介:Python学习者
希望大家多多支持,我们一起进步!
如果文章对你有帮助的话,
欢迎评论 点赞 收藏 加关注+

目录
一、项目介绍
1.1项目简介
1.2技术工具
1.3页面概述
二、项目步骤
2.1首页模块
2.2查看历年数据板块
2.3预测板块
2.4app.py
三、项目总结
一、项目介绍
1.1项目简介
本项目使用Flask框架搭建基于机器学习的世界杯比赛预测系统 (简易版)
其中关于Flask知识点可参考文章Flask全套知识点从入门到精通,学完可直接做项目
关于基于机器学习的世界杯比赛预测模型可参考文章基于决策树算法构建世界杯比赛预测模型
整个项目分为以下几个模块:
- 1.首页板块
- 2.展示往届数据板块
- 3.预测球队胜率板块
项目文件框架如下:
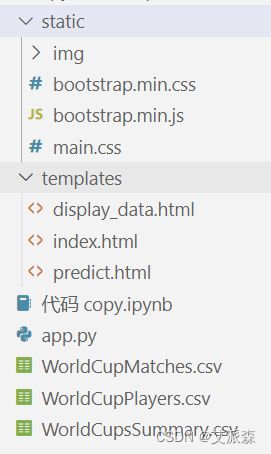
其中manager.py为主程序,password.csv为存储用户账号密码的文件,lianjia是房租价格原始数据集,model.pkl是经过机器学习算法训练出的模型。
1.2技术工具
IDE编辑器:vscode
后端框架:Flask
前端框架:Bootstrap
1.3页面概述
运行app.py程序后,浏览器打开http://127.0.0.1:5000/
映入眼帘的就是首页板块,主要就是项目的名称。
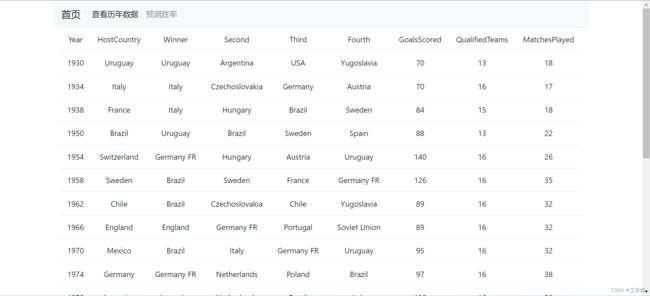
点击导航栏中的查看历年数据页面
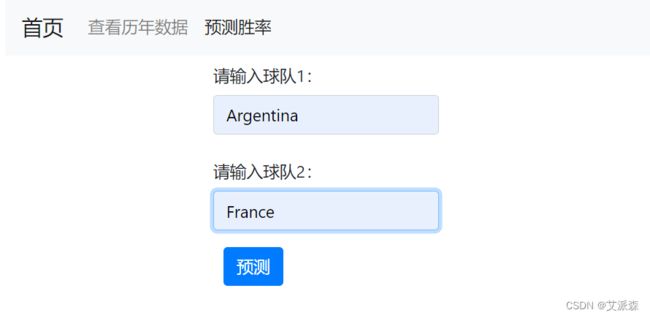
点击导航栏中的预测胜率页面

在预测页面输入两只球队的名称即可进行预测,比如我这里让他预测阿根廷VS法国的胜率
输入名称后点击预测出现以下预测结果
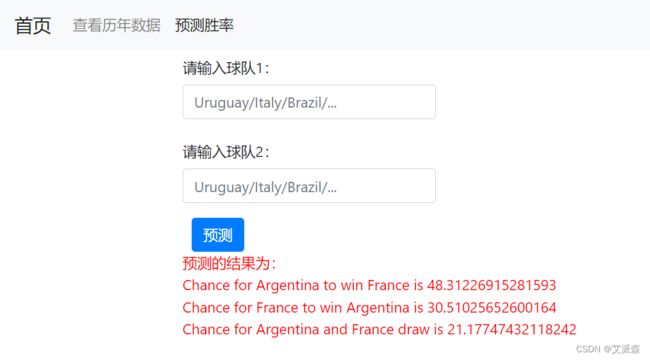
Chance for Argentina to win France is 48.31226915281593
Chance for France to win Argentina is 30.51025652600164
Chance for Argentina and France draw is 21.17747432118242
第一行表示阿根廷赢法国的概率为48.31%
第二行表示法国赢阿根廷的概率为30.51%
第三行表示阿根廷和法国平局的概率为21.18%
二、项目步骤
2.1首页模块
index.html
首页
基于机器学习算法的世界杯比赛预测系统
2.2查看历年数据板块
display_data.html
查看历年数据
Year
HostCountry
Winner
Second
Third
Fourth
GoalsScored
QualifiedTeams
MatchesPlayed
{% for data in datas %}
{{ data.Year }}
{{ data.HostCountry }}
{{ data.Winner }}
{{ data.Second }}
{{ data.Third }}
{{ data.Fourth }}
{{ data.GoalsScored }}
{{ data.QualifiedTeams }}
{{ data.MatchesPlayed }}
{% endfor %}
2.3预测板块
predict.html
预测胜率
{% if error %}
{{ error }}
{% endif %}
{% if prob1 %}
预测的结果为:
Chance for {{ team1 }} to win {{ team2 }} is {{ prob1 }}
Chance for {{ team2 }} to win {{ team1 }} is {{ prob2 }}
Chance for {{ team1 }} and {{ team2 }} draw is {{ prob3 }}
{% endif %}
2.4app.py
from flask import Flask,render_template,views,request
import pandas as pd
import numpy as np
from sklearn.model_selection import train_test_split
from sklearn.utils import shuffle
from sklearn.svm import SVC
import warnings
warnings.filterwarnings('ignore')
app = Flask(__name__)
@app.route('/')
def index():
return render_template('index.html')
@app.route('/display_data')
def display_data():
WorldCupsSummary = pd.read_csv('WorldCupsSummary.csv')
datas = []
for item in WorldCupsSummary.values:
data = {}
data['Year'] = item[0]
data['HostCountry'] = item[1]
data['Winner'] = item[2]
data['Second'] = item[3]
data['Third'] = item[4]
data['Fourth'] = item[5]
data['GoalsScored'] = item[6]
data['QualifiedTeams'] = item[7]
data['MatchesPlayed'] = item[8]
datas.append(data)
return render_template('display_data.html',datas=datas)
class PredictView(views.MethodView):
def __jump(self,prob1=None,prob2=None,prob3=None,error=None,team1=None,team2=None):
return render_template('predict.html',prob1=prob1,prob2=prob2,prob3=prob3,error=error,team1=team1,team2=team2)
def get(self, result=None,error=None):
return self.__jump()
def post(self):
# 导入数据
matches = pd.read_csv('WorldCupMatches.csv')
players = pd.read_csv('WorldCupPlayers.csv')
cups = pd.read_csv('WorldCupsSummary.csv')
# 删除缺失值
matches = matches.dropna()
players = players.dropna()
cups = cups.dropna()
# 用德国取代德国DR和德国FR,用俄罗斯取代苏联
def replace_name(df):
if(df['Home Team Name'] in ['German DR', 'Germany FR']):
df['Home Team Name'] = 'Germany'
elif(df['Home Team Name'] == 'Soviet Union'):
df['Home Team Name'] = 'Russia'
if(df['Away Team Name'] in ['German DR', 'Germany FR']):
df['Away Team Name'] = 'Germany'
elif(df['Away Team Name'] == 'Soviet Union'):
df['Away Team Name'] = 'Russia'
return df
matches = matches.apply(replace_name, axis='columns')
# 创建一个存储足球队的字典
team_name = {}
index = 0
for idx, row in matches.iterrows():
name = row['Home Team Name']
if(name not in team_name.keys()):
team_name[name] = index
index += 1
name = row['Away Team Name']
if(name not in team_name.keys()):
team_name[name] = index
index += 1
# 删除不必要的列
dropped_matches = matches.drop(['Datetime', 'Stadium', 'Referee', 'Assistant 1', 'Assistant 2', 'RoundID',
'Home Team Initials', 'Away Team Initials', 'Half-time Home Goals', 'Half-time Away Goals',
'Attendance', 'City', 'MatchID', 'Stage'], 1)
# 计算每支球队成为世界杯赛冠军的次数
championships = cups['Winner'].map(lambda p: 'Germany' if p=='Germany FR' else p).value_counts()
# 加上“主队冠军”和“客场冠军”:获取世界杯冠军的次数
dropped_matches['Home Team Championship'] = 0
dropped_matches['Away Team Championship'] = 0
def count_championship(df):
if(championships.get(df['Home Team Name']) != None):
df['Home Team Championship'] = championships.get(df['Home Team Name'])
if(championships.get(df['Away Team Name']) != None):
df['Away Team Championship'] = championships.get(df['Away Team Name'])
return df
dropped_matches = dropped_matches.apply(count_championship, axis='columns')
# 定义一个函数用于找出谁赢了:主场胜:1,客场胜:2,平局:0
dropped_matches['Winner'] = '-'
def find_winner(df):
if(int(df['Home Team Goals']) == int(df['Away Team Goals'])):
df['Winner'] = 0
elif(int(df['Home Team Goals']) > int(df['Away Team Goals'])):
df['Winner'] = 1
else:
df['Winner'] = 2
return df
dropped_matches = dropped_matches.apply(find_winner, axis='columns')
# 将team_name字典中的团队名称替换为id
def replace_team_name_by_id(df):
df['Home Team Name'] = team_name[df['Home Team Name']]
df['Away Team Name'] = team_name[df['Away Team Name']]
return df
teamid_matches = dropped_matches.apply(replace_team_name_by_id, axis='columns')
# 删除不必要的列
teamid_matches = teamid_matches.drop(['Year', 'Home Team Goals', 'Away Team Goals'], 1)
X = teamid_matches[['Home Team Name', 'Away Team Name', 'Home Team Championship','Away Team Championship']]
X = np.array(X).astype('float64')
# 附加数据:只需将“主队名称”替换为“客场球队名称”,将“主队冠军”替换为“客场球队冠军”,然后替换结果
_X = X.copy()
_X[:,0] = X[:,1]
_X[:,1] = X[:,0]
_X[:,2] = X[:,3]
_X[:,3] = X[:,2]
y = dropped_matches['Winner']
y = np.array(y).astype('int')
y = np.reshape(y,(1,850))
y = y[0]
_y = y.copy()
for i in range(len(_y)):
if(_y[i]==1):
_y[i] = 2
elif(_y[i] ==2):
_y[i] = 1
X = np.concatenate((X,_X), axis= 0)
y = np.concatenate((y,_y))
# 打乱数据,然后拆分数据集为训练集和测试集
X,y = shuffle(X,y)
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.25)
# 用SVM支持向量机模型进行训练
svm_model = SVC(kernel='rbf', class_weight='balanced', probability=True)
svm_model.fit(X_train, y_train)
# 定义一个预测函数,需要传递两个球队名称,输出两个获胜的概率
def prediction(team1, team2):
id1 = team_name[team1]
id2 = team_name[team2]
championship1 = championships.get(team1) if championships.get(team1) != None else 0
championship2 = championships.get(team2) if championships.get(team2) != None else 0
x = np.array([id1, id2, championship1, championship2]).astype('float64')
x = np.reshape(x, (1,-1))
_y = svm_model.predict_proba(x)[0]
return _y[1]*100,_y[2]*100,_y[0]*100
try:
team1 = request.form['team1']
team2 = request.form['team2']
# 预测比赛
prob1, prob2, prob3 = prediction(team1, team2)
return self.__jump(prob1=prob1,prob2=prob2,prob3=prob3,team1=team1,team2=team2)
except Exception as e:
print(EnvironmentError)
return self.__jump(error='输入数据格式不对,请重新输入!')
app.add_url_rule('/predict/',view_func=PredictView.as_view('my_predict'))
if __name__ == '__main__':
app.run(debug=True)
三、项目总结
本次我们使用了Flask框架结合了基于机器学习的世界杯比赛预测模型,构建了一个简易版基于机器学习的世界杯比赛预测系统,整个项目还有很多地方可以优化,比如页面美化、模块添加等等,这些就留给学习的小伙伴根据自身需求进行创新升级!喜欢本项目的话就三连支持一下啦!
心得与体会:
通过这次Python项目实战,我学到了许多新的知识,这是一个让我把书本上的理论知识运用于实践中的好机会。原先,学的时候感叹学的资料太难懂,此刻想来,有些其实并不难,关键在于理解。
在这次实战中还锻炼了我其他方面的潜力,提高了我的综合素质。首先,它锻炼了我做项目的潜力,提高了独立思考问题、自我动手操作的潜力,在工作的过程中,复习了以前学习过的知识,并掌握了一些应用知识的技巧等
在此次实战中,我还学会了下面几点工作学习心态:
1)继续学习,不断提升理论涵养。在信息时代,学习是不断地汲取新信息,获得事业进步的动力。作为一名青年学子更就应把学习作为持续工作用心性的重要途径。走上工作岗位后,我会用心响应单位号召,结合工作实际,不断学习理论、业务知识和社会知识,用先进的理论武装头脑,用精良的业务知识提升潜力,以广博的社会知识拓展视野。
2)努力实践,自觉进行主角转化。只有将理论付诸于实践才能实现理论自身的价值,也只有将理论付诸于实践才能使理论得以检验。同样,一个人的价值也是透过实践活动来实现的,也只有透过实践才能锻炼人的品质,彰显人的意志。
3)提高工作用心性和主动性。实习,是开端也是结束。展此刻自我面前的是一片任自我驰骋的沃土,也分明感受到了沉甸甸的职责。在今后的工作和生活中,我将继续学习,深入实践,不断提升自我,努力创造业绩,继续创造更多的价值。
这次Python实战不仅仅使我学到了知识,丰富了经验。也帮忙我缩小了实践和理论的差距。在未来的工作中我会把学到的理论知识和实践经验不断的应用到实际工作中,为实现理想而努力。