mysql窗口函数(分析函数)知识笔记
窗口函数
- MySQL从8.0开始支持开窗函数,这个功能在大多商业数据库中早已支持,也叫分析函数。
- 开窗函数与分组聚合比较像,分组聚合是通过制定字段将数据分成多份,每一份执行聚合函数,每份数据返回一条结果。
- 开窗函数也是通过指定字段将数据分成多份,也就是多个窗口,对每个窗口的每一行执行函数,每个窗口返回等行数的结果。
- 窗口函数分为静态窗口和滑动窗口,静态窗口的大小是固定的,滑动窗口的大小可以根据设置进行变化,在当前窗口下生成子窗口。
1、窗口函数的定义
窗口函数作用于一个数据集合。窗口函数的一个概念就是当前行,当前行属于某个窗口就是从整个数据集选取一部分数据进行聚合/排名等操作。
2、窗口函数的语法
语法:函数名([参数]) over(partition by [分组字段] order by [排序字段] asc/desc rows/range between 起始位置 and 结束位置)
函数解读:函数分为两个部分,第一部分是函数名称,开窗函数的数量较少,只有11个窗口函数+聚合函数(所有聚合函数都可以用作开窗函数),根据函数性质,有的要写参数,有的不需要写参数;
第二部分是over语句,over()是必须要写的,里面有三个参数,都是非必须参数,根据需求选写:
1.第一个参数是 partition by +分组字段,将数据根据此字段分成多份,如果不加partition by参数,那会把整个数据当做一个窗口。
2.第二个参数是 order by +排序字段,每个窗口的数据要不要进行排序。
3.第三个参数 rows/range between 起始位置 and 结束位置,这个参数仅针对滑动窗口函数有用,是在当前窗口下分出更小的子窗口。其中起始位置和结束位置可写:current row 边界是当前行,unbounded preceding 边界是分区中的第一行,unbounded following 边界是分区中的最后一行,expr preceding 边界是当前行减去expr的值,expr following 边界是当前行加上expr的值。rows是基于行数,range是基于值的大小,到讲解到滑动窗口函数时再详细介绍。
3、窗口函数中的元素
1) 函数名 window_function_name:
静态窗口函数不能用frame子句;滑动窗口函数指加入order by或frame子句后,函数区域变为到当前行的数据集。
静态窗口函数:
排名函数 rank()、dense_rank()、row_number();
滑动窗口函数:
聚合函数 sum、 avg、percent_rank();
取值函数 first_value()、last_value()、nth_value()、lag()、lead()、ntile()
2) 分区 partition_defintion
窗口按照指定字段进行分区,分区语句为"partition by 指定字段",只有窗口函数功能在分区内执行,并在跨越分区边界时重新初始化。如果没有指定 partition by 语句,且没有后面的frame元素限制,就把所有数据当做一整个区。
3) 排序 order_definition
按照指定字段进行排序,排序语句为"order by 指定字段",窗口函数将按照排序后的排列数据。和partition by 子句配合使用,就是对分区后的数据进行排序;如果单独使用且没有后面的frame元素的限制,就是对整个区的所有数据进行排序。
4) 框架 frame_definition
框架frame是当前分区的一个子集,在分区里面再进一步细分窗口,子句用来定义子集的规则,通常用来作为滑动窗口使用,某些窗口函数属于静态窗口,frame子句就没有作用。
frame_unit有两种,分别是ROWS和RANGE,ROWS是基于行号,RANGE是基于值的范围。
使用BETWEEN frame_start AND frame_end语法来表示行范围,frame_start和frame_end可以支持如下关键字,来确定不同的动态行记录:
CURRENT ROW 边界是当前行,一般和其他范围关键字一起使用
UNBOUNDED PRECEDING 边界是分区中的第一行
UNBOUNDED FOLLOWING 边界是分区中的最后一行
expr PRECEDING 当前行之前的expr(数字或表达式)行
expr FOLLOWING 当前行之后的expr(数字或表达式)行
4、窗口函数的应用
有成绩表sc,字段分别是学生编号s_id,课程编号c_id,成绩score
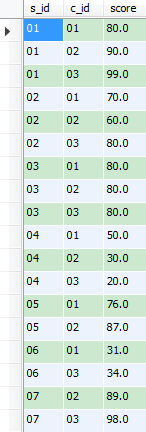
1)排名函数 rank(),dense_rank()、row_number() 静态窗口(不用frame)
– 查询每位学生的成绩总分并排名
思路:先找每位同学的总成绩,然后再排名。
SELECT s_id,SUM(score)总成绩,RANK()over(ORDER BY SUM(score) DESC )排名 FROM sc
GROUP BY s_id;
窗口函数的分区,只对窗口函数有作用,而对sum函数是没有作用,求出来只有一个结果总成绩。
SELECT s_id,SUM(score)总成绩,RANK() over(partition by s_id ORDER BY SUM(score) DESC )排名
FROM sc;
SELECT s_id,SUM(score) over(PARTITION by s_id )总成绩 FROM sc ORDER BY 总成绩 DESC ;
– 查询每个课程的成绩并输出排名列
用关联子查询做的特别复杂,比较一下:
关联子查询
SELECT *,
(SELECT SUM(sc.score<score) FROM sc sc1 WHERE c_id=sc.c_id)+1 排名
FROM sc
ORDER BY c_id,排名;
窗口函数:rank()
SELECT *,RANK()over(PARTITION by c_id order by score desc) 排名 FROM sc;
关联子查询的结果与rank()窗口函数结果一致,我们比较一下三个排名函数:
rank(),dense_rank(),row_number()
SELECT *,RANK() over(PARTITION by c_id order by score desc) 排名 FROM sc;
SELECT *,DENSE_RANK() over(PARTITION by c_id order by score desc) 排名 FROM sc;
SELECT *,ROW_NUMBER() over(PARTITION by c_id order by score desc) 排名 FROM sc;
都是对同一课程不同成绩的学生按成绩多少进行排名,
rank() 按成绩排名时,并列的排名相同但会占据这一行的行位置,如第一个rank表并列第1名后就是第3名。
dense_rank()按成绩排名时,并列的排名相同但不会占据这一行的行位置,如第一个rank表并列第1名后就是第2名。
row_number()只是按成绩排名后又按学号排序,然后把所在行数写出来,而不对并列成绩的同学做处理。
avg()窗口函数
over()什么参数都不加
聚合函数 sum() avg() 滑动窗口,分组后不聚合添加一列
SELECT *,avg(score)over() FROM sc;
over()只加排序的参数
over()不加参数是对整个数据的成绩求平均,窗口数据集是整个数据集。
SELECT *,avg(score)over(order by score) FROM sc;
over()加分区参数再加上排序参数参数
over()只加排序的元素,是按成绩升序排列后对成绩求移动平均,第1个结果就是对第1行求平均等于它本身,第二行等于1行和2行的平均,第三行是对前三行求平均。
SELECT *,SUM(score)over(PARTITION by c_id ORDER BY score) FROM sc;
练一练
– 按平均分数降序排列成绩信息
SELECT *,AVG(score)over(PARTITION by s_id)平均成绩 FROM sc
ORDER BY 平均成绩 DESC;
sum()窗口函数
over()什么参数都不加
over()不加参数是对整个数据的成绩进行求和,窗口数据集是整个数据集。
SELECT *,SUM(score)over() FROM sc;
over()只加排序的参数
over()只加排序的元素,是按成绩升序排列后对成绩进行累加求和。
SELECT *,SUM(score)over(order by score) FROM sc;
over()加分区参数再加上排序参数参数
SELECT *,SUM(score) over(PARTITION by c_id ORDER BY score) FROM sc;
在窗口函数里按课程进行分区和按成绩排序后,得到的是同一个课程按成绩排序后,对学生的成绩进行累计求和。
练一练
– 按总分数降序排列成绩信息
SELECT *,SUM(score)over(PARTITION by s_id)总成绩 FROM sc
ORDER BY 总成绩 DESC;
是通过s_id分区后对每个区域的成绩求和后最后排序。
前后函数:LAG()、LEAD() 静态窗口及frame框架
SELECT *,LAG(score,1,0)over(PARTITION by c_id ORDER BY score DESC) FROM sc;
LAG(score,1,0):score这列当前行往前数1行,如果出现空值则为0
为什么每种课程的第一个值都为0 呢?分区后再往前数1个数字,则不存在为空值,而之前对空值的默认值进行了设定为0。
SELECT *,LEAD(score,2,0)over(PARTITION by c_id ORDER BY score DESC) FROM sc;
LEAD(score,2):score这列当前行,往后数2行,出现空值则为0
为什么每个课程最后两行会为0呢?因为我们分过区了,分区以后再往后数就没有值了所以为空。
头尾函数:FIRST_VALUE()、LAST_VALUE() 滑动窗口
FIRST_VALUE():取所选数据区域的第一个值
SELECT*,FIRST_VALUE(score)over(PARTITION by c_id) FROM sc;
这个结果是按照c_id分区后取每种课程区域的第一个值。
SELECT*,FIRST_VALUE(score)over(PARTITION by c_id rows BETWEEN 2 preceding and 3 following) FROM sc; #所选区域是:按课程分区后,取当前行往前数2行往后数3行
LAST_VALUE() :取所选数据区域的最后一个值
SELECT*,LAST_VALUE(score)over(PARTITION by c_id) FROM sc;
#取每种课程区域的最后一个值
SELECT*,
LAST_VALUE(score)over(PARTITION by c_id rows BETWEEN unbounded preceding and unbounded following)
FROM sc;
#根据c_id分区后,在区域内的第一行到最后一行的最后一个值
SELECT*,
LAST_VALUE(score)over(PARTITION by c_id rows BETWEEN 4 preceding and 2 following) FROM sc;
#所选区域是:按课程分区后,取当前行往前数4行往后数2行
SELECT*,
SUM(score)over(PARTITION by c_id ORDER BY score desc range BETWEEN 10 preceding and 10
following) FROM sc;
#按课程分区后,对 当前值-10到当前值+10 的数值范围进行求和
就第一行举例来说,score是80分,取课程是01的区域,70= 总结一下: frame框架语法: RANGE……BETWEEN……AND…… ROWS……BETWEEN……AND…… CURRENT ROW 边界是当前行,一般和其他范围关键字一起使用 UNBOUNDED PRECEDING 边界是分区中的第一行 UNBOUNDED FOLLOWING 边界是分区中的最后一行 exp PRECEDING 当前行之前的exp(数字或表达式)行 exp FOLLOWING 当前行之后的exp(数字或表达式)行 注意:rows是基于行的处理,而range是基于值,进行加减来确定范围,最终确定窗口区域 分布函数:PERCENT_RANK()、CUM_DIST() 静态窗口 PERCENT_RANK()返回的是(rank-1)/(当前窗口行数-1) 比如说第3行的数据rank=3,当前窗口为课程是01的行总数=6,结果=(3-1)/(6-1)=2/5=0.4 CUM_DIST() :返回的是rank/当前窗口的行数 比如说第3行的数据rank=3,当前窗口为课程是01的行总数=6,结果=3/6=0.5 其他函数:NTH_VALUE() 滑动窗口、NTILE() 静态窗口 NTH_VALUE() 滑动窗口 取分区后,所有区域的第二个值 因为为滑动窗口,用了order by 后取到当前行的第二个值 分组函数NTILE() 静态窗口 NTILE(N):加上要分的组数 即1-2行属于1组,2-3行属于2组,5行3组,6行4组。SELECT *,RANK()over(PARTITION by c_id ORDER BY score DESC)排名,
PERCENT_RANK()over(PARTITION by c_id ORDER BY score DESC)
FROM sc;
SELECT *,RANK()over(PARTITION by c_id ORDER BY score DESC)排名,
CUME_DIST()over(PARTITION by c_id ORDER BY score DESC)
FROM sc;
select *,nth_value(score,2) over(partition by c_id) from sc;
select *,nth_value(score,2) over(partition by c_id ORDER BY score DESC)
from sc;
select *,NTILE(4)over(partition by c_id ) from sc;
#通过c_id分区后,再将这区域分成4组