mysql函数之高级应用(窗口函数)
常用的有数学函数、字符串函数、日期时间函数、条件判断函数、系统信息函数。
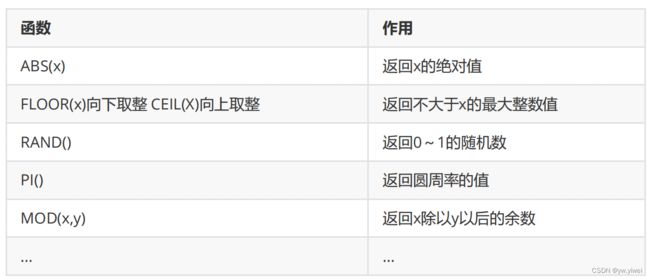
- 数学函数
-- 系统信息函数
select database();
select version();
select user();
-- 数学函数
select abs(-10) as '绝对值'
select abs(price) from products
select floor(5.9) as '向下取整';
select ceil(5.01) as '向上取整'
select round(5.419,2) as '四舍五入' -- 第二个数值是保留几位小数的意思
select rand(); -- 返回0-1之间的随机数
select pi(); -- 返回圆周率
select mod(5,2); -- 求余数,对2取余数
- 字符串函数
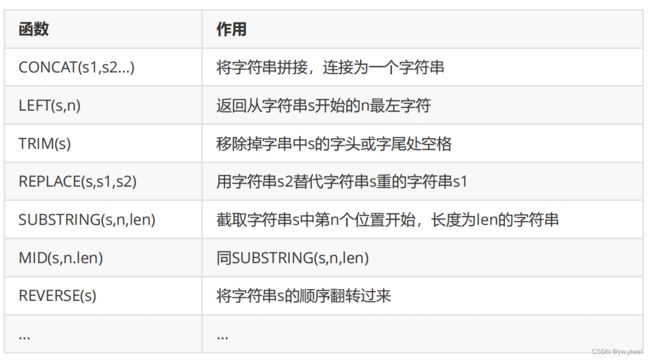
1.CONCAT(s1,s2...)
SELECT CONCAT('la','gou') AS 字符串链接;
concat(table.a,table.b) from table
2.LEFT(s,n)
SELECT LEFT('lagou',2) AS le_sub #从左侧提取2位;
#la
select right('lagou',2) as ri_sub
#ou
select mid('lagou',2,3) as mid_sub
#ago
4.REPLACE(s,s1,s2)
SELECT REPLACE('lagou_jiaoyu','_','.') AS 字符串替换;
#lagou.jiaoyu
5.SUBSTRING(s,n,len) -- 字符串截取
SELECT SUBSTRING('lagou_jiaoyu',7,6) AS SUBSTRING提取子串
,MID('lagou_jiaoyu',7,6) AS MID提取子串;
- 日期和时间函数
 日期:年月日、时间:时分秒
日期:年月日、时间:时分秒
select curate()
select month(curate())
select year(curate())- 条件判断函数
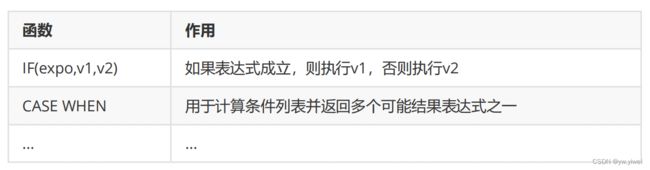
SELECT IF(10>5,10,5) as 最大值; select if(10>2,10,2); select pname,if(price>2000,'奢侈品','普通商品') '商品性质' from products; select pname,if(price>2000,price-1000,price) '优惠后的价格' from products; SELECT CASE WHEN 10>5 THEN 10 ELSE 5 END AS 最大值; case when 条件1 then 结果1 when 条件2 then 结果2 when ... then 结果n (else 结果n+1) end- 系统信息函数
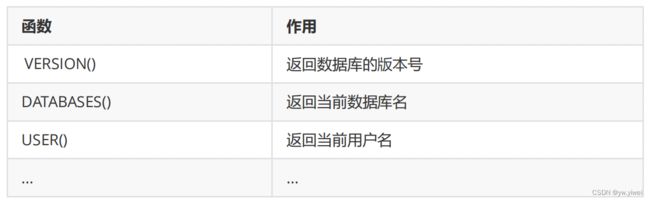
- 系统信息函数
窗口函数
它可以理解为记录集合,窗口函数也就是在满足某种条件的记录集合上执行的特殊函数。对于每条记录都要在此窗口内执行函数,窗口大小都是固定的,这种属于静态窗口(只有partition by,无order by和rows,分组后无上下边界情况);不同的记录对应着不同的窗口,这种动态变化的窗口叫滑动窗口。
语法:函数名([expr]) over 子句
其中,over是关键字,用来指定函数执行的窗口范围,包含三个分析子句:分组(partition by)子
句,排序(order by)子句,窗口(rows)子句。
如果后面括号中什么都不写,则意味着窗口包含满足where条件的所有行,窗口函数基于所有行进行计算;如果不为空,则支持以下语法来设置窗口:
函数名([expr]) over(partition by <要分列的组> order by <要排序的列> rows
知识点总结
sum(...A...) over(partition by ...B... order by ...C... rows between ...D1... and ...D2...)
avg(...A...) over(partition by ...B... order by ...C... rows between ...D1... and ...D2...)
between <数据范围>)
A: 需要被加工的字段名称
B: 分组的字段名称
C: 排序的字段名称
D: 计算的行数范围
rows between 2 preceding and current row # 取当前行和前面两行
rows between unbounded preceding and current row # 包括本行和之前所有的行
rows between current row and unbounded following # 包括本行和之后所有的行
rows between 3 preceding and current row # 包括本行和前面三行
rows between 3 preceding and 1 following # 从前面三行和下面一行,总共五行
# 当order by后面缺少窗口从句条件,窗口规范默认是包括本行和之前所有的行 rows between unbounded preceding and current row.
# 当order by和窗口从句都缺失, 窗口规范默认是 rows between unbounded preceding
and unbounded following
以把窗口函数分为两种:
- 专有窗口函数:
rank()
dense_rank()
row_number()
- 聚合类窗口函数:
普通场景下,聚合函数往往和group by一起使用,但是窗口环境下,聚合函数也可以应用进来,那么此时它们就被称之为聚合类窗口函数,属于窗口函数的一种
sum()
count()
avg()
max()
min()
窗口函数(专有窗口函数+聚合类窗口函数)和普通场景下的聚合函数也很容易混淆,二者区别
如下:
普通场景下的聚合函数是将多条记录聚合为一条(多到一);窗口函数是每条记录都会执行,有几条记录执行完还是几条(多到多)。
分组(partition by):记录按照字段进行分组,窗口函数在不同的分组上分别执行。
排序(order by):按照哪些字段进行排序,窗口函数将按照排序后的记录顺序进行编号,可以和partition子句配合使用,也可以单独使用。如果没有partition子句,数据范围则是整个表的数据行。
窗口(rows):就是进行函数分析时要处理的数据范围,属于当前分区的一个子集,通常用来作为滑动窗口使用。比如要根据每个订单动态计算包括本订单和按时间顺序前后两个订单的移动平均支付金额,则可以设置rows子句来创建滑动窗口(rows)。
- 累计求和:sum() over()
#需求1: 查询出2019年每月的支付总额和当年累积支付总额(也就是当前项+前面所有项的和)
/*思路:2019年用分组得出,每月要用month函数
求取:支付总额用sum
*/
-- step1 过滤出2019年数据
select * from user_trade where year(pay_time)=2019;
-- step2 在1的基础上,按照月份进行group by 分组,统计每个月份的支付总额
SELECT MONTH ( pay_time ), sum( pay_amount ) FROM user_trade WHEREYEAR ( pay_time ) = 2019 GROUP BY MONTH ( pay_time );
-- step3 在2的基础上应用窗口函数实现需求
SELECT
a.MONTH,-- 月份
a.pay_amount,-- 当月总支付金额
SUM( a.pay_amount ) over ( ORDER BY a.MONTH)
-- 就是2019年的数据,所以 不用分组,此时没有使用rows指定窗口数据范围,默认当前行及其之前的所有行
FROM
( SELECT MONTH ( pay_time ) month, SUM( pay_amount ) pay_amount FROM user_trade WHERE YEAR ( pay_time )= '2019' GROUP BY MONTH ( pay_time ) )a;
#一定要先想好窗口函数的表头,然后去找对应的。a表中数据要命名才方便代入窗口函数之中操作。
#需求2:查询出2018-2019年每月的支付总额和当年累积支付总额
/*思路:限定条件2018-2019
每月支付总额sum,当年累积支付总额窗口函数
有两年意味着要按年和月都要分组,计算每月和每年的总和
表头:年、月、月总额
*/
SELECT
YEAR( pay_time ) YEAR,
MONTH ( pay_time ) MONTH,
SUM( pay_amount ) pay_amount
FROM
user_trade
WHERE
YEAR ( pay_time ) IN ( 2018, 2019 )
GROUP BY
YEAR( pay_time ),
MONTH ( pay_time );
#注意group by分组要按年分一次,按月分一次。两个年份在一张表中,之前因为只有一年所以不用分。
SELECT
b.YEAR,
b.MONTH,
b.pay_amount,
sum( b.pay_amount ) over ( PARTITION BY b.YEAR ORDER BY b.MONTH )
from
(
SELECT YEAR
( pay_time ) YEAR,
MONTH ( pay_time ) MONTH,
SUM( pay_amount ) pay_amount
FROM
user_trade
WHERE
YEAR ( pay_time ) IN ( 2018, 2019 )
GROUP BY
YEAR( pay_time ),
MONTH ( pay_time )
)b;
#注意括弧中英文,select year那块的格式- 排序函数
row_number() over(......)
rank() over(......)
dense_rank() over(......)
注意:row_number()、rank() 和dense_rank()紧邻的括号内是不加任何字段名称的。
row_number:它会为查询出来的每一行记录生成一个序号,即使并列也会依次排序且不会重复。
rank&dense_rank:如果使用rank函数来生成序号,over子句中排序字段值相同的序号是一样的,后面字段值不相同的序号将跳过相同的排名号排下一个,也就是相关行之前的排名数加一。
dense_rank函数在生成序号时是连续的,而rank函数生成的序号有可能不连续(1-15并列的会全是1,第16排号就是16。)。
dense_rank函数 出现相同排名时,将不跳过相同排名号,rank值紧接上一次的rank值。
在各个分组内,rank()是跳跃排序,有两个第一名时接下来就是第三名,dense_rank()是连续排
序,有两个第一名时仍然跟着第二名。
#需求5: 2020年1月,购买商品品类数的用户排名
/*也就是根据2020年1月客户购买的品类数多少给用户排名,一个用户可能有买了很多单,所以要对这些品类汇总去重,按照客户名来划分统计品类总数。
限定条件:2020年1月
表头:用户名、品类数(去重的)、排名
思路:先求出各个用户购买的品类数,然后开始排名,count()用到排名窗口函数。
*/
SELECT
user_name,
COUNT( DISTINCT goods_category ) category_count,
row_number() over (ORDER BY COUNT(DISTINCT goods_category)) order1,
rank() over(ORDER BY COUNT(DISTINCT goods_category)) order2,
dense_rank() over(ORDER BY COUNT(DISTINCT goods_category)) order3
FROM
user_trade
WHERE
substring( pay_time, 1, 7 )= '2020-01' GROUP BY user_name
#排序窗口函数中COUNT( DISTINCT goods_category ) 不能用category_count别名代替。
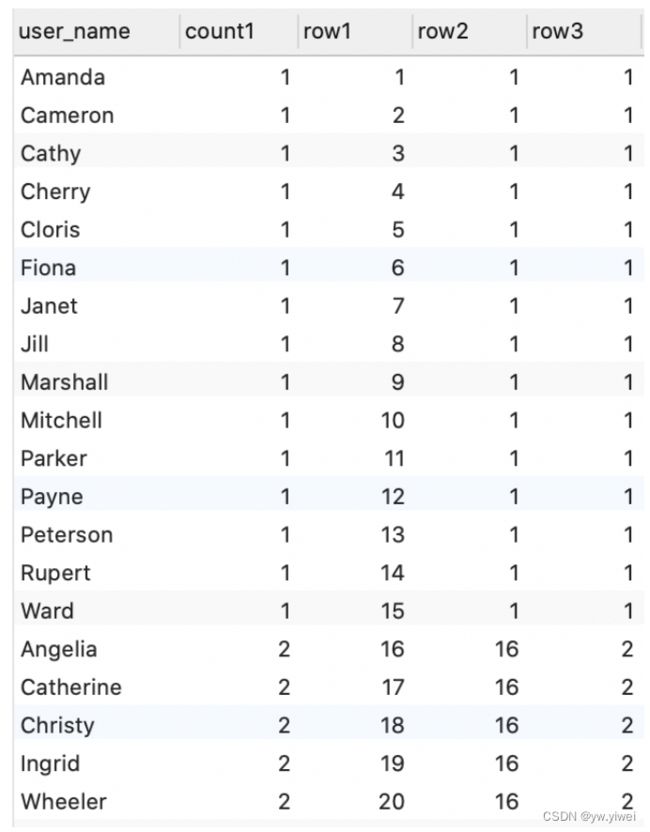 123对应row、rank、dense_rank
123对应row、rank、dense_rank
ntile(n) over(......)
#需求6: 查询出将2020年2月的支付用户,按照支付金额分成5组后的结果
/*限定条件:2020年2月,用户支付金额,可能多笔订单,要按用户分组后再统计各自金额。
表头:用户、支付金额、分成5组后的排序
*/
SELECT
user_name,
SUM( pay_amount ) pay_amount,
ntile( 5 ) over ( ORDER BY SUM( pay_amount ) DESC ) LEVEL
-- 将支付金额[最小,最大]切成5片,看用户处于5片中的哪一水平,desc从大到小降序。
FROM
user_trade
WHERE
substring( pay_time, 1, 7 )= '2020-02'
GROUP BY
user_name;
#需求7: 查询出2020年支付金额排名前30%的所有用户
/*限定条件:2020年
表头:用户、支付金额、切片排名
*/
SELECT a.user_name,a.pay_amount,a.LEVEL from
(SELECT
user_name,
SUM( pay_amount ) pay_amount ,
ntile( 10 ) over ( ORDER BY SUM( pay_amount ) DESC ) LEVEL
FROM
user_trade
WHERE
YEAR ( pay_time )= '2020'
GROUP BY
user_name
)a WHERE a.LEVEL in(1,2,3)
#123序号三个切片就是30%- 偏移分析函数
向上偏移:lag(...) over(......)
向下偏移:lead(...) over(......)
SELECT
user_name,
pay_time,
lead( pay_time, 1, pay_time ) over ( PARTITION BY user_name ORDER BY pay_time ) lead1,
-- 没有传入偏移量就是默认1,后面默认值不传入就是空。
lead( pay_time ) over ( PARTITION BY user_name ORDER BY pay_time ) lead2,
lead( pay_time, 2, pay_time ) over ( PARTITION BY user_name ORDER BY pay_time ) lead3,
lead( pay_time, 2 ) over ( PARTITION BY user_name ORDER BY pay_time ) lead4
FROM
user_trade
WHERE
user_name IN ( 'King', 'West' );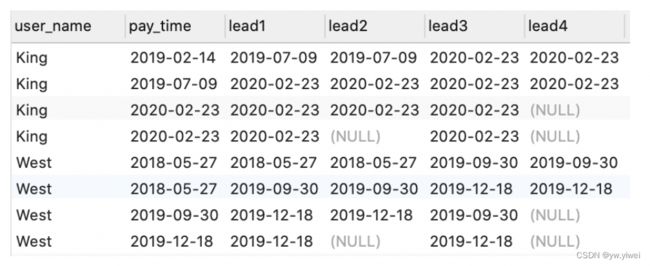
#需求11: 查询出支付时间间隔超过100天的用户数
/*无时间限制,用户数用count要去重,可能一个用户每次都超过一百天再次下单。
子查询表头:用户名、第一次付款时间、后一次付款时间
思路:条件设为求后一次 - 上一次付款天数>100
*/
SELECT COUNT(DISTINCT user_name) FROM
(SELECT
user_name,
pay_time,
lead(pay_time,1) over(PARTITION by user_name ORDER BY pay_time) lead_time
FROM
user_trade
)a WHERE DATEDIFF(lead_time,pay_time) > 100
#DATEDIFF(x2,x1)查询两个日期x2-x1之间的天数#需求11: 查询出每年支付时间间隔最长的用户
/*表头:年份、用户名、时间间隔
限定条件:每年,按年要分组;用户也要分组,某年某人的间隔
支付时间间隔最长:现-上一个支付记录,一个人可能多笔记录且间隔不同
思路:求出某年所有用户时间间隔,然后对时间间隔排序,提取出人,按人头分组即去掉了人头重复。
*/
SELECT b. YEARs,b.user_name,b.interval_days
FROM
(SELECT
a.YEARs,
a.user_name,
DATEDIFF(a.pay_time,a.lag_time) interval_days
rank() over(PARTITION BY a.YEARs ORDER BY DATEDIFF(a.pay_time,a.lag_time )) rank1
FROM
(
SELECT YEAR
( pay_time ) YEARs,
user_name,
pay_time,
LAG( pay_time ) over (
PARTITION BY user_name,
YEAR ( pay_time )
ORDER BY
pay_time
) lag_time
FROM
user_trade
) a
)b
WHERE b.rank1=1;
#DATEDIFF那块总是报错,不知道为啥