One SPRING to Rule Them Both Symmetric AMR Semantic Parsing and Generation without Complex Pipeline
One SPRING to Rule Them Both: Symmetric AMR Semantic Parsing and Generation without a Complex Pipeline

论文:https://ojs.aaai.org/index.php/AAAI/article/view/17489
代码:https://github.com/SapienzaNLP/spring
期刊/会议:AAAI 2021
摘要
在文本到AMR解析中,当前最先进的语义解析器集成了几个不同模块或组件的繁琐管道,并利用图重新分类,即在训练集的基础上开发的一组特定内容的启发式方法。然而,在分布外的情况下,图重新分类的可通用性尚不清楚。相比之下,最先进的AMR-to-Text generation可以被视为parsing的反面,它基于更简单的seq2seq模型。在本文中,我们将Text-to-AMR和AMR-to-text转换为对称转化任务,并表明通过设计仔细的图线性化和扩展预训练的编码器-解码器模型,可以使用完全相同的seq2seq方法,即SPRING(Symmetric PaRsIng aNd Generation),在这两个任务中获得最先进的性能。我们的模型不需要复杂的管道,也不需要基于大量假设的启发式方法。事实上,我们放弃了对图重新分类的需求,这表明这种技术在标准基准之外实际上是有害的。最后,我们在英文AMR 2.0数据集上的表现大大优于先前的技术水平:在Text-to-AMR上,我们获得了3.6个Smatch点的改进,而在AMR-to-Text上,我们比现有技术高出11.2个BLEU点。
1、简介
最近最先进的Text-to-AMR语义解析方法具有非常复杂的前处理和后处理管道,其中集成了几个不同组件的输出。此外,他们采用了基于训练集开发的细粒度、特定内容的启发式方法,因此,这些方法在各个领域和流派中可能非常脆弱。迄今为止,更简单、完整的序列到序列(seq2seq)方法的解析性能一直落后,主要是因为它们的数据效率不如其他方法。
当涉及到AMR-to-Text generation(可以被视为Text-to-AMR parsing的反向任务)时,原始seq2seq方法反而取得了最先进的结果。这种架构不对称性在其他双向转换任务中没有观察到,例如机器翻译,其中使用相同的架构来处理从语言 X X X到语言 Y Y Y的翻译,反之亦然。受此启发,本文的一个关键目标是通过为两者提供相同的架构,实现AMR解析和生成的对称性。此外,我们通过消除对内容修正管道和额外的句法和语义特征的需求,降低了Text-to-AMR架构的复杂性,这些特征通常依赖于外部组件和特定于数据的启发式方法。我们通过有效地线性化AMR图,并通过扩展预训练的seq2seq模型,即BART(Lewis et al, 2020),以处理AMR-to-Text 和Text-to-AMR来实现这一点。事实上,唯一对我们的模型持续有益的外部资源是实体链接的现成系统——这项任务很难用纯seq2seq模型稳健地执行。
我们的贡献总结如下:
- 我们扩展了预训练的Transformer编码器-解码器架构,以生成句子的AMR图的精确线性化,或者反之亦然,生成用于AMR图线性化的句子。
- 与之前的报道(Konstas et al 2017)相反,我们发现在竞争图同构线性化之间的选择确实很重要。我们提出的具有特殊指针标记的基于深度优先搜索(DFS)的线性化优于PENMAN线性化和类似的基于广度优先搜索(BFS)的替代方案,尤其是在AMR-to-Text方面。
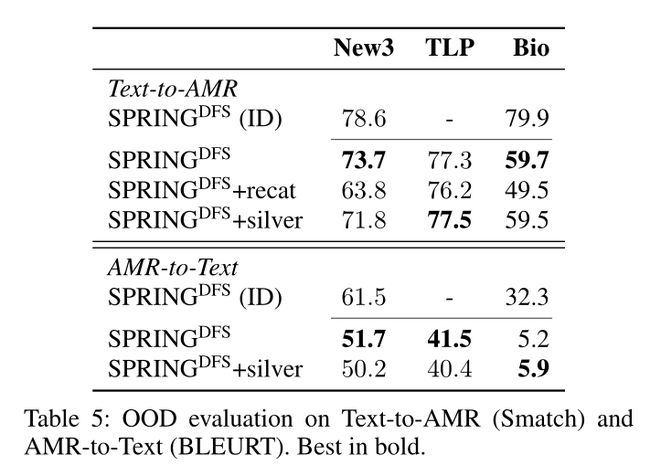
- 我们提出了一种新颖的Out-of-Distribution(OOD)设置来估计Text-to-AMR和AMR-to-Text方法在开放世界数据上推广的能力。
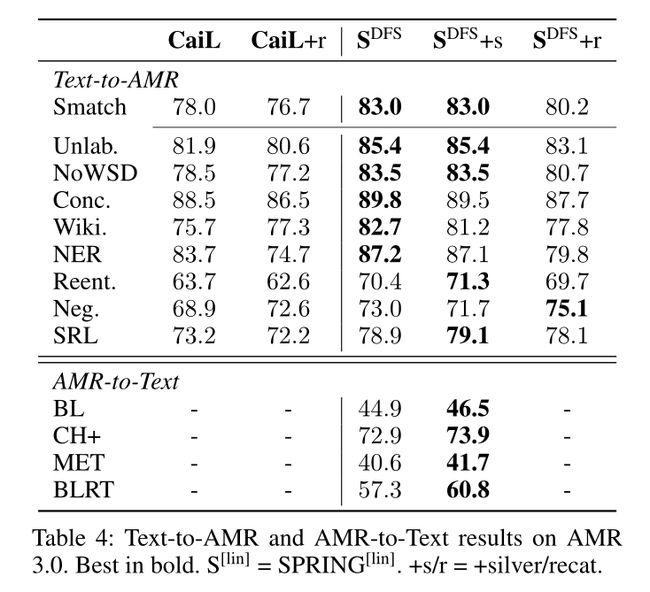
- 我们表明,应该避免对开放世界数据进行图重新分类,因为尽管它在标准基准测试中略微提高了性能,但在OOD设置中无法进行泛化。
- 对于生成任务,我们比AMR 2.0中先前报道的最佳结果高出11.2个BLEU点,对于解析任务,我们高出3.6个Smatch点。
2、相关工作
2.1 Text-to-AMR parsing
pure seq2seq:Seq2seq将模型Text-to-AMR parsing 作为将句子转换为AMR图的线性化。由于其端到端的性质,这种方法对这项任务很有吸引力。然而,由于基于seq2seq的方法需要大量数据,到目前为止,由于标注句子AMR对的数量相对较少,它们在AMR解析方面的性能一直相当不令人满意。为了克服数据稀疏性,已经采用了各种不同的技术:使用未标记的英语文本进行自训练(Konstas et al,2017),使用字符级网络(van Noordn and Bos 2017),以及将概念重新分类作为预处理步骤,以减少开放词汇成分,例如命名实体和日期(Peng et al 2017; van Noord and Bos 2017; Konstas et al 2017)。此外,基于seq2seq的模型通常包含引理、POS或命名实体识别(NER)标签等特征,以及句法和语义结构(Ge et al ,2019)。
为了抵消稀疏性,我们通过利用BART(Lewis et al 2020)——一种最近发布的预训练编码器-解码器——来使用转移学习,通过seq2seq解码器的单次自回归逐步生成线性化图。事实上,BART的基本Transformer编码器-解码器与Ge等人(2019)的类似,但不同之处在于它从头开始训练AMR解析架构。
hybrid approaches:通过使用更复杂的多模块架构的方法,已经获得了Text-to-AMR的最先进的结果。这些方法将seq2seq方法与基于图的算法结合在两阶段(Zhang et al 2019a)或增量一阶段(Zhang et al 2019b; Cai and Lam 2020a)程序。此外,它们集成了类似的处理管道和附加功能,如上述seq2seq方法(Konstas et al 2017),包括细粒度的图重新分类(Zhang et al 2019a,b; Zhou et al 2020; Cai and Lam 2020a),这些都对所实现的性能有很大贡献。
相比之下,我们的模型几乎完全依赖于seq2seq,不需要额外的特征,并且仅为了确保图的有效性而使用了基本的后处理管道。尽管如此,我们的表现明显优于以往的先进方法。此外,我们还表明,广泛的重新分类技术在提高传统领域内基准测试的性能的同时,在OOD设置中是有害的。此外,尽管其他方法已经采用了预训练的编码器,例如BERT(Devlin et al 2019),为了为解析架构提供强大的功能(Zhang et al 2019a,b;Cai and Lam 2020a),我们率先证明了预训练的解码器也有利于AMR解析,尽管预训练只涉及英语,不包括形式表示。
2.2 AMR-to-Text Generation
AMR-to-Text Generation的生成目前有两种主要方法:以图到文本的转换方式显式编码图结构(Song et al 2018; Beck, Haffari, and Cohn 2018; Damonte and Cohen 2019; Zhu et al 2019; Cai and Lam 2020b; Yao, Wang, and Wan 2020),或通过AMR图线性化作为纯seq2seq任务(Konstas et al 2017; Mager et al 2020)。最近基于图的方法依赖于Transformer来编码AMR图(Zhu et al 2019; Cai and Lam 2020b; Wang, Wan, and Yao 2020; Song et al 2020; Yao, Wang, and Wan 2020)。Mager等人(2020)的模型是一个预训练的仅基于Transformer的解码器模型,该模型在AMR图的顺序表示上进行了微调。相反,我们使用编码器-编码器体系结构,该体系结构更适合处理条件生成,并将AMR-to-Text,使其与Text-to-AMR对称,从而消除了对特定任务模型的需求。
2.3 线性化信息损失
以前的Text-to-AMR解析方法(Konstas et al 2017; van Noord and Bos 2017; Peng et al 2017; Ge et al 2019)将seq2seq方法与有损线性化技术结合使用,为了降低复杂性,从图中删除变量等信息。这些信息是启发式恢复的,这使得产生某些有效输出变得更加困难。相反,我们提出了两种线性化技术,它们完全同构于图,并且不会产生任何信息损失。
2.4 BART
BART是一种基于Transformer的编码器-解码器模型,通过去噪自监督任务进行预训练,即重建经过混洗、句子排列、掩蔽和其他类型的破坏修改的英语文本(Lewis et al,2020)。BART在条件生成任务中显示出显著的改进,其中输入和输出序列的词汇表在很大程度上交叉,例如问题回答和摘要。同样,大量的AMR标签是从英语词汇中提取的——尽管AMR的目的是从句子中抽象出来——因此,我们假设BART的去噪预训练也应该适用于AMR到文本和文本到AMR。此外,可以看到BART的预训练任务和AMR-to-Text生成之间的相似性,因为线性化的AMR图可以被视为英语句子的重新排序、部分损坏的版本,模型必须重建该版本。
3、方法
我们使用相同的架构(即SPRING)执行Text-to-AMR Parsing和AMR-to-Text Generation,SPRING利用了BART的迁移学习能力来完成这两项任务。在SPRING中,AMR图是对称处理的:对于Text-to-AMR Parsing,编码器-解码器被训练来预测给定句子的图;对于AMR-to-Text Generation,训练另一个镜面编码器解码器来预测给定图的句子。
为了在seq2seq模型中使用图,我们使用各种不同的线性化技术将它们转换为符号序列(第3.1节)。此外,我们修改了BART词汇表,使其适用于AMR概念、框架和关系(第3.2节)。最后,我们定义了轻量级、非内容修改启发式方法,以应对以下事实,seq2seq可以输出不能解码为图的字符串(第3.3节)。
3.1 图线性化
在这项工作中,我们使用了完全图同构的线性化技术,即,可以将图编码为符号序列,然后将其解码回图,而不会丢失邻接信息。我们建议使用特殊token
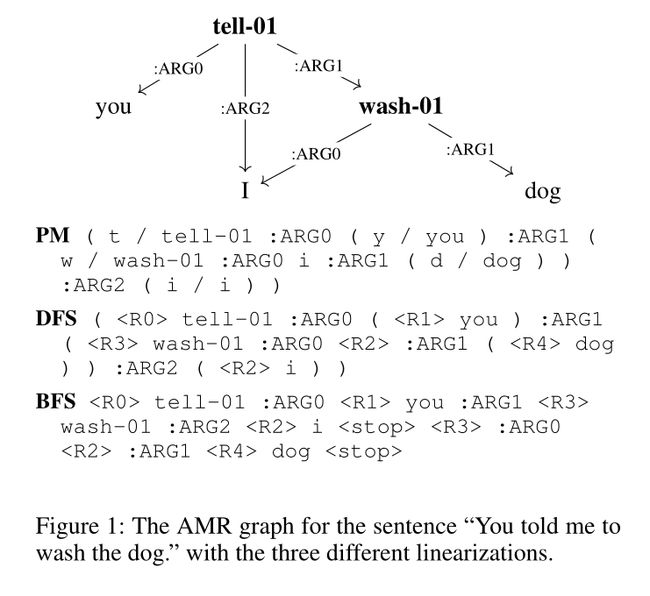
DFS-based:PENMAN所基于的DFS非常有吸引力,因为它与自然语言句法树的线性化方式密切相关:例如,考虑“the dog which ate the bone which my father found is sleeping”这句话,其中名词dog与其头部动词sleeping相距甚远,因为dog的从属词在头动词出现之前就已经完全被“explored”了。因此,我们使用了一种基于DFS的线性化,该线性化具有特殊的标记来指示变量和括号来标记访问深度。此外,我们还处理了冗余斜杠标记(/)。与PENMAN相比,这些功能显著缩短了输出序列的长度,在PENMAN中,变量名通常由子词标记器拆分为多个子标记。这对于使用Transformers进行有效的seq2seq解码非常重要,因为Transformers受到注意力机制的二次复杂性的限制。
BFS-based:BFS遍历的使用是因为它强制执行了一个局部性原则,通过该原则,属于一起的事物在平面表示中彼此接近。此外,Cai和Lam(2019)认为,BFS在认知上是有吸引力的,因为它对应于一个核心语义原则,该原则假设最重要的意义部分在图的上层表示。为此,我们提出了一种基于BFS的线性化,就像我们基于DFS的线性化一样,它使用特殊的token来表示共同引用。我们应用BFS图遍历算法,该算法从图根 r r r开始,访问由边 e e e连接的所有子节点 w w w,将指针标记附加到 r , e r,e r,e,然后如果 w w w是变量则附加指针标记,或者如果 w w w是常数则附加其值。第一次附加指针标记时,我们还会附加其:instance属性。在每个级别的迭代结束时,即在访问子级 w w w之后,我们附加一个特殊的tell-01开始,在其子级上迭代,然后在<stop>之后继续执行wash-01。
Edge ordering:所有上述线性化被解码为相同的图。然而,在PENMAN线性化的gold标注中,可以从每个AMR图中提取边排序。有人建议(Konstas et al,2017),标注者利用这种可能性对源句子中关于论元排序的信息进行编码。我们的初步实验证实,由于AMR-to-Text生成的顺序敏感性,强加不同于PENMAN的边排序对AMR的评估措施有很大的负面影响。为了控制这种情况,我们仔细设计了线性化以保留顺序信息。
3.2 词汇
BART使用子单词词汇,其tokenization经过优化以处理英语,但它不太适合AMR符号。为了解决这个问题,我们通过添加i)训练语料库中至少出现5次的所有关系和框架来扩展BART的标记化词汇;ii)AMR tokens 的组成部分,例如:op;iii)各种图线性化所需的特殊token。此外,我们通过添加一个向量来调整编码器和解码器的嵌入矩阵,以包括新的符号,该向量被初始化为子字成分的平均值。在词汇扩展中添加特定于AMR的符号避免了广泛的子符号分割,从而允许将AMR编码为更紧凑的符号序列,从而减少了解码空间和时间要求。
重新分类。重新分类是一种流行 的缩小词汇大小以处理数据稀疏性的技术。它通过删除感知节点、wiki链接、极性属性和/或匿名命名实体来简化图。为了评估重新分类的贡献,我们对AMR解析文献中常用的方法进行了实验(Zhang et al 2019a,b; Zhou et al 2020; Cai and Lam 2020a)。该方法基于字符串匹配启发式和针对训练数据定制的映射,这也调节了推理时的恢复过程。我们将读者引向张等人(2019a),以了解更多细节。我们注意到,根据常见的实践,我们只在解析中使用重新分类技术,因为可能导致生成的信息损失要高得多。
3.3 后处理
在我们的方法中,我们执行轻度后处理,主要是为了确保解析中生成的图的有效性。为此,我们在PENMAN和DFS中恢复括号奇偶校验,并删除任何在其前面的token不可能连续的令牌。对于BFS,我们在每个后续的:wiki属性的提及,然后运行现成的BLINK实体链接器(Wu et al 2020)并覆盖预测。
4、实验
数据集:
- 分布范围内:AMR2.0(LDC2017T10)、AMR3.0(LDC2020T02)。
- 分布范围外:New3、TLP、Bio
- silver 数据
模型:
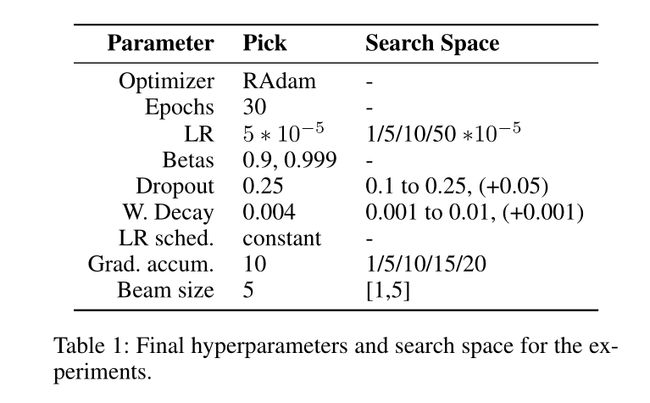
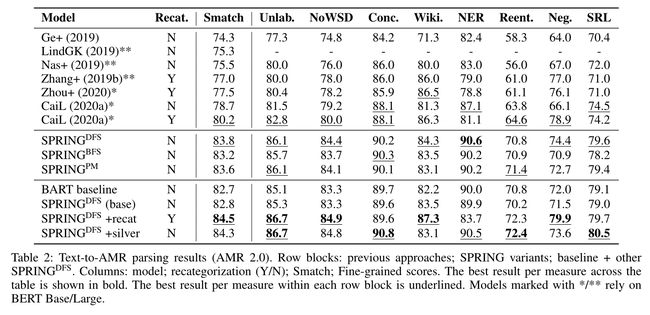
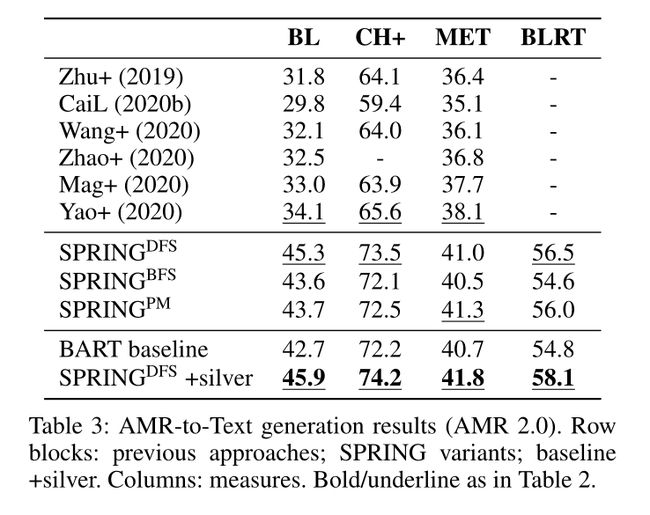
实验结果:
5、总结
在本文中,我们提出了一种简单、对称的方法,用于使用单个seq2seq架构执行最先进的文本到AMR解析和AMR到文本生成。为了实现这一点,我们将英语文本去噪预训练的Transformer编码器-解码器模型扩展到AMR。此外,我们还提出了一种新的基于DFS线性化AMR图,除了比其替代方案更紧凑之外,它不会导致任何信息丢失。最重要的是,我们放弃了竞争方法的大部分要求:繁琐的管道、繁重的启发式(通常根据训练数据定制)以及大多数外部组件。尽管如此降低了复杂性,但我们在解析和生成方面都大大优于先前的技术水平,分别达到83.8 Smatch和45.3 BLEU。我们还提出了一个分布外设置,它可以对不同于训练集的流派和领域进行评估。由于这种设置,我们能够表明,重新分类技术或银数据的集成——提高性能的流行技术——会损害解析和生成的性能。基于较轻的假设,采用像我们这样更简单的方法,可以实现更稳健的泛化。在这里,我们展示了模型在不同数据分布和跨领域上的可推广性,同时将Blloshmi、Tripodi和Navigli(2020)中的跨语言扩展以及形式主义(Navigli 2018)中的扩展留给未来的工作。最后,我们邀请社区使用OOD评估来开发更强大的自动AMR方法。此外,我们相信我们的贡献将为解析和生成的集成开辟更多的方向。
最近工作