第二模块(函数编程(极速版))-第二章-常用模块
系列文章目录
基础常用模块
文章目录
- 系列文章目录
- 前言
- 一、模块介绍与导入
-
- 1.什么是模块
- 2.模块的好处
- 3.模块的分类
- 4.导入方式
- 5.自定义模块
- 6.查找路径
- 二、第三方开源模块的安装使用
- 三、系统调用os模块
- 四、系统调用sys模块
- 五、time&datetime模块
-
- 1.time模块
- 2.datetime模块
- 六、random随机数模块
- 七、序列化pickle&json模块
- 八、hashlib加密
- 九、文件copy模块shutil
- 十、正则表达式re模块
- 十一、软件开发目录设计规范
- 十二、包&跨模块代码调用
- 十三、常用模块学习-logging模块基础
- 总结
前言
提示:这里可以添加本文要记录的大概内容:
例如:随着人工智能的不断发展,机器学习这门技术也越来越重要,很多人都开启了学习机器学习,本文就介绍了机器学习的基础内容。
一、模块介绍与导入
1.什么是模块
2.模块的好处
避免函数名,变量名冲突
a.py
def sayhi():
xxx
b.py
import a
def sayhi():
xxx
a.sayhi()
sayhi()
3.模块的分类
标准模块,内置模块 库 300
第三方模块 18万 pip install
自定义模块,自己写的
4.导入方式
5.自定义模块
6.查找路径
模块查找路径有关系
[‘D:\pyfile\路飞学城就业课程\第二模块-函数编程(极速版)\第二章-常用模块’,
‘D:\pyfile’,
‘D:\PyCharm-professional-2020.2.1\plugins\python\helpers\pycharm_display’, ‘C:\Users\82766\AppData\Local\Programs\Python\Python38\python38.zip’, ‘C:\Users\82766\AppData\Local\Programs\Python\Python38\DLLs’, 标准库
‘C:\Users\82766\AppData\Local\Programs\Python\Python38\lib’, ‘C:\Users\82766\AppData\Local\Programs\Python\Python38’, ‘C:\Users\82766\AppData\Local\Programs\Python\Python38\lib\site-packages’, 第三方模块
‘D:\PyCharm-professional-2020.2.1\plugins\python\helpers\pycharm_matplotlib_backend’]
二、第三方开源模块的安装使用
pip install -i http://pypi.douban.com/simple/ alex_sayhi --trusted-host pypi.douban.com #alex_sayhi是模块名
三、系统调用os模块
代码如下:
import os
得到当前工作目录,即当前Python脚本工作的目录路径: os.getcwd()
>>> os.getcwd()
'C:\\Users\\82766'
返回指定目录下的所有文件和目录名:os.listdir()
>>> os.listdir( 'Desktop')
['Adobe After Effects 2020.lnk', 'Adobe Audition 2020.lnk', 'Adobe Photoshop 2020.lnk', 'Adobe Premiere Pro 2020.lnk', 'desktop.ini', 'Google Chrome.lnk', 'WPS Office.lnk', '微信.lnk', '有道云笔记.lnk', '百度网盘.lnk', '金山打字通.lnk']
函数用来删除一个文件:os.remove()
删除多个目录:os.removedirs(r“c:\python”)
返回一个路径的目录名和文件名:os.path.split() os.path.split('/home/swaroop/byte/code/poem.txt') 结果:('/home/swaroop/byte/code', 'poem.txt')
检验给出的路径是否是一个文件:os.path.isfile()
检验给出的路径是否是一个目录:os.path.isdir()
判断是否是绝对路径:os.path.isabs()
检验给出的路径是否真地存在:os.path.exists()
获取路径名:os.path.dirname()
>>> os.path.dirname("D:\pyfile\路飞学城就业课程\第二模块-函数编程(极速版)\第二章-常用模块\ssh_remote_cmd.py")
'D:\\pyfile\\路飞学城就业课程\\第二模块-函数编程(极速版)\\第二章-常用模块'
获得绝对路径: os.path.abspath()
获取文件名:os.path.basename()
打印当前脚本所在路径,包含文件名
print(__file__)
四、系统调用sys模块
代码如下(示例):
>>> import sys
>>> sys.platform 打印操作系统
'win32'
>>> sys.getdefaultencoding() 获取解释器默认编码
'utf-8'
>>> sys.getfilesystemencoding() 获取内存数据存到文件里的默认编码
'utf-8'
五、time&datetime模块
unix 1970 B C
ibm AIX unix
hp hp unix
oracle sun soloris
linux
windows
mac = unix
1.time模块
>>> import time
time.localtime([secs]):将一个时间戳转换为当前时区的struct_time
time.localtime()
>time.struct_time(tm_year=2020, tm_mon=10, tm_mday=19, tm_hour=15, tm_min=52, tm_sec=23, tm_wday=0, tm_yday=293, tm_isdst=0)
time.gmtime([secs]):gmtime()方法是将一个时间戳转换为UTC时区(0时区)的struct_time
time.gmtime()
>time.struct_time(tm_year=2020, tm_mon=10, tm_mday=19, tm_hour=7, tm_min=54, tm_sec=9, tm_wday=0, tm_yday=293, tm_isdst=0)
time.time():返回当前时间的时间戳
>1603094049.6242926
time.mktime(t):将一个struct_time转化为时间戳
t1 = time.gmtime()
print(t1)
time.struct_time(tm_year=2020, tm_mon=10, tm_mday=19, tm_hour=12, tm_min=51, tm_sec=39, tm_wday=0, tm_yday=293, tm_isdst=0)
print(time.mktime(t1))
1603083099.0
time.sleep(secs):线程推迟指定的时间运行,单位为秒
time.sleep(3)
time.asctime([t]):把一个表示时间的元组或者struct_time表示为这种形式:’Sun Oct 1 12:04:38 2019’。如果没有参数,将会将time.localtime()作为参数传入
time.asctime()
Mon Oct 19 15:57:06 2020
time.ctime([secs]):把一个时间戳(按秒计算的浮点数)转化为time.asctime()的形式。如果参数未给或者为None的时候,将会默认time.time()为参数。它的作用相当于time.asctime(time.localtime(secs))
time.ctime()
Mon Oct 19 15:59:06 2020
time.strftime(format[, t]):把一个代表时间的元组或者struct_time(如由time.localtime()和time.gmtime()返回)转化为格式化的时间字符串。如果t未指定,将传入time.localtime()
>>> time.strftime("%Y-%m-%d %H:%M %p %j %z",time.localtime())
'2020-10-19 20:57 PM 293 +0800'
time.strptime(string[, format]):把一个格式化时间字符串转化为struct_time。实际上它和strftime()是逆操作。
time.strptime("2020/04/01 19:30","%Y/%m/%d %H:%M")
time.struct_time(tm_year=2020, tm_mon=4, tm_mday=1, tm_hour=19, tm_min=30, tm_sec=0, tm_wday=2, tm_yday=92, tm_isdst=-1)
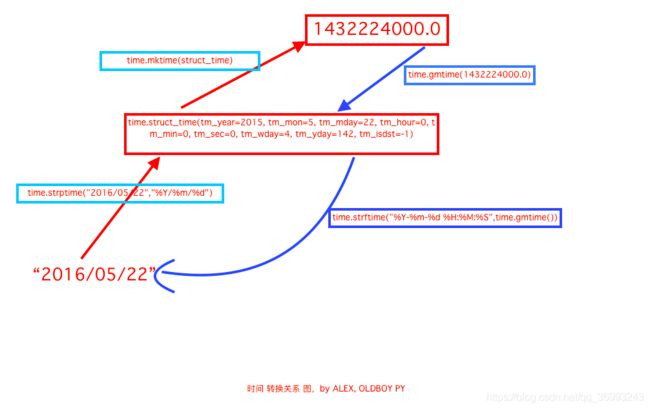
2.datetime模块
1.datetime.datetime.now() 返回当前的datetime日期类型/显示当前时间
datetime.datetime.now()
>datetime.datetime(2020, 10, 19, 16, 20, 53, 427247)
2.>>> datetime.date.timetuple(datetime.date.today()) 转换成元组格式
time.struct_time(tm_year=2020, tm_mon=10, tm_mday=28, tm_hour=0, tm_min=0, tm_sec=0, tm_wday=2, tm_yday=302, tm_isdst=-1)
3.datetime.date.fromtimestamp(322222) 把一个时间戳转为datetime日期类型
>>> datetime.datetime.fromtimestamp(123333)
datetime.datetime(1970, 1, 2, 18, 15, 33)
4.datetime.timedelta:表示时间间隔,即两个时间点之间的长度
>>> datetime.timedelta(days = 3)
datetime.timedelta(days=3)
>>> t1 - datetime.timedelta(days = 3)
datetime.datetime(2020, 10, 16, 16, 24, 17, 407845)
>>> t1 - datetime.timedelta(days = 3,minutes = 5)
datetime.datetime(2020, 10, 16, 16, 19, 17, 407845)
>>> t1 + datetime.timedelta(days = -3,minutes = 5)
datetime.datetime(2020, 10, 16, 16, 29, 17, 407845)
5.时间替换
>>> t1.replace(year = 2015,month = 10,minute = 1) 时间替换
datetime.datetime(2015, 10, 19, 16, 1, 17, 407845)
6.时区
import pytz
>>> import pytz
>>> pytz.all_timezones 查看所有时区
['Africa/Abidjan', 'Africa/Accra'
>>> pytz.timezone("Asia/Shanghai") 生成时区
<DstTzInfo 'Asia/Shanghai' LMT+8:06:00 STD>
>>> datetime.datetime.now(tz = pytz.timezone("Asia/Saigon")) 给时间配时区
datetime.datetime(2020, 10, 19, 15, 36, 42, 128838, tzinfo=<DstTzInfo 'Asia/Saigon' +07+7:00:00 STD>)
六、random随机数模块
>>> random.randrange(1,10) #返回1-10之间的一个随机数,不包括10
>>> random.randint(1,10) #返回1-10之间的一个随机数,包括10
>>> random.randrange(0, 100, 2) #随机选取0到100间的偶数
>>> random.random() #返回一个0-1直间的随机浮点数
>>> random.choice('abce3#$@1') #返回一个给定数据集合中的随机字符
'#'
>>> random.sample('abcdefghij',3) #从多个字符中选取特定数量的字符
['a', 'd', 'b']
#生成随机字符串
import string
print("".join(random.sample(string.digits + string.ascii_lowercase,5)))
h8gsn
#洗牌
a = list(range(100))
random.shuffle(a)
print(a)
[96, 41, 37, 49, 45, 72, 5, 59, 48, 14, 90, 80, 69, 54, 55, 10, 32, 0, 24, 53, 76, 13, 9, 25, 92, 27, 70, 75, 56, 35, 18, 38, 6, 73, 21, 12, 28, 16, 86, 30, 84, 65, 52, 94, 63, 77, 71, 23, 88, 61, 50, 93, 51, 67, 44, 39, 74, 34, 87, 64, 83, 42, 3, 1, 31, 60, 85, 36, 58, 68, 20, 66, 17, 33, 98, 19, 47, 99, 22, 62, 81, 8, 4, 78, 89, 15, 29, 79, 97, 2, 11, 26, 40, 57, 91, 46, 7, 82, 95, 43]
七、序列化pickle&json模块
pickle
import pickle
#dump写入文件
f = open("game.pkl","wb")
pickle.dump(d,f)
#dumps生成序列化字符串
d_dump = pickle.dumps(d) #序列化
print(d_dump)
b'\x80\x04\x95=\x00\x00\x00\x00\x00\x00\x00}\x94(\x8c\x04name\x94\x8c\x04alex\x94\x8c\x04role\x94\x8c\x06police\x94\x8c\x05blood\x94KL\x8c\x06weapon\x94\x8c\x04ak47\x94u.'
#load从文件加载
f = open("game.pkl","rb")
print(pickle.load(f))
b'\x80\x04\x95=\x00\x00\x00\x00\x00\x00\x00}\x94(\x8c\x04name\x94\x8c\x04alex\x94\x8c\x04role\x94\x8c\x06police\x94\x8c\x05blood\x94KL\x8c\x06weapon\x94\x8c\x04ak47\x94u.'
#loads 把序列化的字符串反向解析
print(pickle.loads(d_dump))
{'name': 'alex', 'role': 'police', 'blood': 76, 'weapon': 'ak47'}
json
import json
d = {
"name":"alex",
"role":"police",
"blood":76,
"weapon":"ak47"
}
alive_players = ["alex","jack","rain"]
f = open("game.json","w")
json.dump(d,f)
f = open("game.json","r")
json.load(f)
pickle vs json
pickle:
只支持python
支持python所有数据类型
class->object
function
datetime
json:
所有语言都支持
只支持python常规数据类型 str,int,dict,set,list,tuple
web fronted
html/js/css
function(){}
backed
python --json–>fronted dict
def nfname()
八、hashlib加密
sdfdsgfd->2333333 碰撞
hfgrwerb->2333333
import hashlib
m = hashlib.md5()
m.update(b"hello alex")
print(m.hexdigest())
m.update("欢迎来到这里".encode("utf-8"))
# print(m.digest()) #消化
print(m.hexdigest())
m2 = hashlib.md5()
m2.update("hello alex欢迎来到这里".encode("utf-8"))
print(m.hexdigest())
九、文件copy模块shutil
拷贝文件
import shutil
shutil.copyfile('f1.log', 'f2.log') #目标文件无需存在
zipfile压缩&解压缩
import zipfile
# 压缩
z = zipfile.ZipFile('laxi.zip', 'w')
z.write('a.log')
z.write('data.data')
z.close()
# 解压
z = zipfile.ZipFile('laxi.zip', 'r')
z.extractall(path='.')
z.close()
十、正则表达式re模块
匹配手机号
phone_list = re.search("[0-9]{11}",f.read()) #从全局找一个
print(phone_list)
常用的表达式规则:
‘.’ 默认匹配除\n之外的任意一个字符
>>> re.search(".","alex")
<re.Match object; span=(0, 1), match='a'>
打印
>>> re.search(".","alex").group()
'a'
‘^’ 匹配字符开头
>>> re.search("^alex","alex").group()
'alex'
>>> re.search("^alex","falex").group()
Traceback (most recent call last):
File "" , line 1, in <module>
AttributeError: 'NoneType' object has no attribute 'group'
‘$’ 匹配字符结尾
>>> re.search("^alex$","alex").group()
'alex'
>>> re.search("^alex$","alexop").group()
Traceback (most recent call last):
File "" , line 1, in <module>
AttributeError: 'NoneType' object has no attribute 'group'
** 匹配*号前的字符0次或多次,开头没有就返回空
>>> re.search("a*","ddd")
<re.Match object; span=(0, 0), match=''>
>>> re.search("a*","daaaddd")
<re.Match object; span=(0, 0), match=''>
>>> re.search("a*","adaaaddd")
<re.Match object; span=(0, 1), match='a'>
>>> re.search("a*","aaaadaaaddd")
<re.Match object; span=(0, 4), match='aaaa'>
‘+’ 匹配前一个字符1次或多次,可以到中间找
>>> re.search("a+","aaaadaaaddd")
<re.Match object; span=(0, 4), match='aaaa'>
>>> re.search("a+","daaaddd")
<re.Match object; span=(1, 4), match='aaa'>
>>> re.search("a+","dddd")
‘?’ 匹配前一个字符1次或0次,0次或1次
>>> re.search("a?","dddd")
<re.Match object; span=(0, 0), match=''>
>>> re.search("a?","aaadddd")
<re.Match object; span=(0, 1), match='a'>
‘{m}’ 匹配前一个字符m次
>>> re.search("a{4}","aaadddd")
>>> re.search("a{3}","aaadddd")
<re.Match object; span=(0, 3), match='aaa'>
‘{n,m}’ 匹配前一个字符n到m次
>>> re.search("a{1,2}","aaadddd")
<re.Match object; span=(0, 2), match='aa'>
>>> re.search("a{3,5}","aaadddd")
<re.Match object; span=(0, 3), match='aaa'>
>>> re.search("a{3,5}","aaaaaadddd")
<re.Match object; span=(0, 5), match='aaaaa'>
‘|’ 匹配|左或|右的字符
>>> re.search("abc|ABC","abcABC")
<re.Match object; span=(0, 3), match='abc'>
>>> re.search("abc|ABC","addggbcABdddfgC")
>>>
‘(…)’ 分组匹配
>>> re.search("(abc){2}a(123|45)", "abcabca456c")
<re.Match object; span=(0, 9), match='abcabca45'>
‘\A’ 只从字符开头匹配,相当于re.match(‘abc’,“alexabc”) 或^
>>> re.search("\Aabc","alexabc")
>>> re.search("\Aabc","abclexabc")
<re.Match object; span=(0, 3), match='abc'>
‘\Z’ 匹配字符结尾,同$
>>> re.search("abc\Z","dddabc")
<re.Match object; span=(3, 6), match='abc'>
[]
>>> re.search("[a-zA-Z0-9]{4}","jack")
<re.Match object; span=(0, 4), match='jack'>
‘\d’ 匹配数字0-9
>>> re.search("\d","ja455ck")
<re.Match object; span=(2, 3), match='4'>
>>> re.search("\d{3}","ja455ck")
<re.Match object; span=(2, 5), match='455'>
>>> re.search("\d+","ja455ck")
<re.Match object; span=(2, 5), match='455'>
‘\D’ 匹配非数字
>>> re.search("\D+","ja455ck")
<re.Match object; span=(0, 2), match='ja'>
>>> re.findall("\D+","ja455ck2523dggfd")
['ja', 'ck', 'dggfd']
>>> re.findall("\d+","ja455ck2523dggfd")
['455', '2523']
‘\w’ 匹配[A-Za-z0-9]
>>> re.findall("\w+","ja455ck25'>23dggfd")
['ja455ck25', '23dggfd']
‘\W’ 匹配非[A-Za-z0-9]
>>> re.findall("\W+","a*dvd+lombf/")
['*', '+', '/']
‘s’ 匹配空白字符、\t、\n、\r , re.search("\s+",“ab\tc1\n3”).group() 结果 ‘\t’
>>> re.findall("\s","a*\ndvd\t+lo\nmbf/")
['\n', '\t', '\n']
‘(?P…)’ 分组匹配 re.search("(?P[0-9]{4})(?P[0-9]{2})(?P[0-9]{4})
>>> re.search("([0-9]{3})([0-9]{3})([0-9]{4})",id_num)
<re.Match object; span=(0, 10), match='3714811993'>
>>> a = re.search("([0-9]{3})([0-9]{3})([0-9]{4})",id_num)
>>> a.groups()
('371', '481', '1993')
>>> a = re.search("(?P[0-9]{3})(?P[0-9]{3})(?P[0-9]{4})" ,id_num)
>>> a.groupdict()
{'province': '371', 'city': '481', 'birthday': '1993'}
re的匹配语法有以下几种:
re.match 从头开始匹配
re.search 匹配包含
re.findall 把所有匹配到的字符放到以列表中的元素返回
re.findall("[0-9]{11}",phone)
re.split 以匹配到的字符当做列表分隔符
>>> import re
>>> re.split("[0-9]","alex3jack4rain6mike")
['alex', 'jack', 'rain', 'mike']
>>> re.split("[a-z]","alex3jack4rain6mike")
['', '', '', '', '3', '', '', '', '4', '', '', '', '6', '', '', '', '']
>>> re.findall("[0-9]","alex3jack4rain6mike")
['3', '4', '6']
取数字
>>> s='9-2*5/3+7/3*99/4*2998+10*568/14'
>>> re.split("[+\-\*/]",s)加\后面的语法不解释
['9', '2', '5', '3', '7', '3', '99', '4', '2998', '10', '568', '14']
re.sub 匹配字符并替换
>>> re.sub("abc","ABC","abcdefg")
'ABCdefg'
>>> re.sub("abc","ABC","abcdefgabc",count=2)
'ABCdefgABC'
>>> re.sub("[a-z]","0","abcdefg")
'0000000'
>>> re.sub("[a-z]","0","abcdefgAFB")
'0000000AFB'
re.fullmatch 全部匹配/精确匹配
>>> re.fullmatch("aaa","aaa")
<re.Match object; span=(0, 3), match='aaa'>
re.compile定义规则
>>> p = re.compile("[0-9]{11}")
>>> p
re.compile('[0-9]{11}')
>>> p.search("1222555555555")
<re.Match object; span=(0, 11), match='12225555555'>
Flags标志符:
re.I(re.IGNORECASE): 忽略大小写
>>> re.search("Efg","alexEFg",re.I)
<re.Match object; span=(4, 7), match='EFg'>
re.M(MULTILINE): 多行模式,改变’^’和’$’的行为
>>> re.search("^alex","alexjackrain")
<re.Match object; span=(0, 4), match='alex'>
>>> re.search("^alex","mack\nalexjackrain")
>
>>> re.search("^alex","mack\nalexjackrain",re.M)
<re.Match object; span=(5, 9), match='alex'>
>>> re.search("alex$","mack\nalex\njackrain",re.M)
<re.Match object; span=(5, 9), match='alex'>
re.S(DOTALL): 改变’.’的行为
>>> re.search(".","\n")
>>> re.search(".","\n",re.S)
<re.Match object; span=(0, 1), match='\n'>
re.X(re.VERBOSE) 可以给你的表达式写注释,使其更可读
a = re.compile(r"""\d + # the integral part
\. # the decimal point
\d * # some fractional digits""",
re.X)
b = re.compile(r"\d+\.\d*")
十一、软件开发目录设计规范

- bin/: 存放项目的一些可执行文件,当然你可以起名script/之类的也行,启动,管理。
- foo/: 存放项目的所有源代码。
- (1) 源代码中的所有模块、包都应该放在此目录。不要置于顶层目录。
- (2)其子目录tests/存放单元测试代码;
- (3) 程序的入口最好命名为main.py。
- docs/: 存放一些文档。
- setup.py: 安装、部署、打包的脚本。
- requirements.txt: 存放软件依赖的外部Python包列表。
- README: 项目说明文件。
requirements.txt
1.生成requirement
pip freeze > requirements
2.安装requirements中的包
pip install -r requirements
这个文件存在的目的是:
方便开发者维护软件的包依赖。将开发过程中新增的包添加进这个列表中,避免在setup.py安装依赖时漏掉软件包。
方便读者明确项目使用了哪些Python包。
这个文件的格式是每一行包含一个包依赖的说明,通常是flask>=0.10这种格式,要求是这个格式能被pip识别,这样就可以简单的通过pip install -r requirements.txt来把所有Python包依赖都装好了。
十二、包&跨模块代码调用
一个文件夹管理多个模块文件,这个文件夹就被称为包:
一个包就是一个文件夹,但该文件夹下必须存在init.py 文件, 该文件的内容可以为空,int.py用于标识当前文件夹是一个包。
这个init.py的文件主要是用来对包进行一些初始化的,当当前这个package被别的程序调用时,init.py文件会先执行,一般为空, 一些你希望只要package被调用就立刻执行的代码可以放在init.py里。
在package路径下
init文件先执行
print("----welcome invoke my first pacckage-----")
跨目录导入
import sys
import os
base_dir = os.path.abspath(os.path.dirname(os.path.dirname(__file__))) #找到根目录
print(base_dir)
sys.path.append(base_dir) #将目录添加到查找路径
from logging_mod import log_test
def home_page():
print("welcome to applend")
print(log_test.sayhi)
home_page()
print("hahaha")
官方推荐方法
在manage中
print("---run my pro---")
from my_package import test
在test中
from logging_mod import log_test
def home_page():
print("welcome to applend")
print(log_test.sayhi)
home_page()
print("hahaha")
项目里创建个入口程序,整个程序调用的开始应该是从入口程序发起,这个入口程序一般放在项目的顶级目录
这样做的好处是,项目中的二级目录 apeland_web/views.py中再调用他表亲my_proj/settings.py时就不用再添加环境变量了。
原因是由于manage.py在顶层,manage.py启动时项目的环境变量路径就会自动变成….xxx/my_proj/这一级别
十三、常用模块学习-logging模块基础
python的logging模块提供了标准的日志接口,你可以通过它存储各种格式的日志
logging的日志可以分为 debug(), info(), warning(), error() and critical()5个级别
- DEBUG 出问题,调试10
- INFO 无错误,普通记录20
- WARNING 潜在问题30
- ERROR 故障40
- CRITICAL 严重问题50
import logging
输出到屏幕
logging.warning("user [alex] attempted wrong password more than 3 times")
logging.critical("server is down")
WARNING:root:user [alex] attempted wrong password more than 3 times
CRITICAL:root:sever is down
写到文件
import logging
logging.basicConfig(filename='example.log',level=logging.INFO)
#输入只记录info及以上级别的日志
logging.debug('This message should go to the log file')
logging.info('So should this')
logging.warning('And this, too')
#定义格式
logging.basicConfig(filename="log_test.log",level=logging.DEBUG,
format='%(asctime)s:%(levelname)s#级别:%(filename)s:#打印文件名%(funcName)s:#哪个函数%(lineno)d:#哪行代码%(process)d#进程id %(message)s'#用户信息,datefmt='%Y-%m-%d %I:%M:%S %p'#时间)
同时向屏幕和文件输出日志
Python 使用logging模块记录日志涉及四个主要类,使用官方文档中的概括最为合适:
- logger提供了应用程序可以直接使用的接口;
- handler将(logger创建的)日志记录发送到合适的目的输出;
- filter提供了细度设备来决定输出哪条日志记录;
- formatter决定日志记录的最终输出格式。
每个组件的主要功能
- logger
每个程序在输出信息之前都要获得一个Logger。 - handler
handler对象负责发送相关的信息到指定目的地。Python的日志系统有多种Handler可以使用。有些Handler可以把信息输出到控制台,有些Handler可以把信息输出到文件,还有些 Handler可以把信息发送到网络上。
每个Logger可以附加多个Handler。
- logging.StreamHandler
使用这个Handler可以向类似与sys.stdout或者sys.stderr的任何文件对象(file object)输出信息。 - logging.FileHandler 和StreamHandler
类似,用于向一个文件输出日志信息。不过FileHandler会帮你打开这个文件 - logging.handlers.RotatingFileHandler
这个Handler类似于上面的FileHandler,但是它可以管理文件大小。当文件达到一定大小之后,它会自动将当前日志文件改名,然后创建
一个新的同名日志文件继续输出。比如日志文件是chat.log。当chat.log达到指定的大小之后,RotatingFileHandler自动把
文件改名为chat.log.1。不过,如果chat.log.1已经存在,会先把chat.log.1重命名为chat.log.2。。。最后重新创建
chat.log,继续输出日志信息。 - logging.handlers.TimedRotatingFileHandler
这个Handler和RotatingFileHandler类似,不过,它没有通过判断文件大小来决定何时重新创建日志文件,而是间隔一定时间就 自动创建新的日志文件。重命名的过程与RotatingFileHandler类似,不过新的文件不是附加数字,而是当前时间。
RotatingFileHandler方法
import logging
from logging import handlers
class IgnoreBackupLogFilter(logging.Filter):
"""忽略带db backup 的日志"""
def filter(self, record): #固定写法
return "db backup" not in record.getMessage()
#1.生成logger对象
logger = logging.getLogger("web")
logger.setLevel(logging.DEBUG)
# 1.1把filter对象添加到logger中
logger.addFilter(IgnoreBackupLogFilter())
#2.生成handler对象
ch = logging.StreamHandler()
fh = handlers.RotatingFileHandler(filename="web.log",maxBytes=10,backupCount=3)
#2.1把handler对象绑定到logger对象
logger.addHandler(ch)
logger.addHandler(fh)
#3生成formatter对象
file_formatter = logging.Formatter('%(asctime)s - %(name)s - %(levelname)s - %(message)s')
console_formatter = logging.Formatter('%(asctime)s - %(name)s - %(levelname)s - %(lineno)d - %(message)s')
#3.1把formatter对象绑定到handler对象
ch.setFormatter(console_formatter)
fh.setFormatter(file_formatter)
logger.info("test_log3")
logger.warning("test_log4")
logger.debug("test_log")
logger.debug("test log db backup")
TimedRotatingFileHandler方法
import logging
from logging import handlers
class IgnoreBackupLogFilter(logging.Filter):
"""忽略带db backup 的日志"""
def filter(self, record): #固定写法
return "db backup" not in record.getMessage()
#1.生成logger对象
logger = logging.getLogger("web")
logger.setLevel(logging.DEBUG)
# 1.1把filter对象添加到logger中
logger.addFilter(IgnoreBackupLogFilter())
#2.生成handler对象
ch = logging.StreamHandler()
fh = handlers.TimedRotatingFileHandler("web.log",when="S",interval=5,backupCount=3)
#2.1把handler对象绑定到logger对象
logger.addHandler(ch)
logger.addHandler(fh)
#3生成formatter对象
file_formatter = logging.Formatter('%(asctime)s - %(name)s - %(levelname)s - %(message)s')
console_formatter = logging.Formatter('%(asctime)s - %(name)s - %(levelname)s - %(lineno)d - %(message)s')
#3.1把formatter对象绑定到handler对象
ch.setFormatter(console_formatter)
fh.setFormatter(file_formatter)
logger.info("test_log3")
logger.warning("test_log4")
logger.debug("test_log")
logger.debug("test log db backup")
formatter 组件
日志的formatter是个独立的组件,可以跟handler组合
import logging
#1.生成logger对象
logger = logging.getLogger("web")
#设置整体日志级别
logger.setLevel(logging.DEBUG)
#2.生成handler对象
ch = logging.StreamHandler()
#设置日志级别
ch.setLevel(logging.INFO)
fh = logging.FileHandler("web.log")#输出到文件
#设置日志级别
fh.setLevel(logging.WARNING)
#2.1把handler对象绑定到logger对象
logger.addHandler(ch)
logger.addHandler(fh)
#3生成formatter对象
file_formatter = logging.Formatter('%(asctime)s - %(name)s - %(levelname)s - %(message)s')
console_formatter = logging.Formatter('%(asctime)s - %(name)s - %(levelname)s - %(lineno)d - %(message)s')
#3.1把formatter对象绑定到handler对象
ch.setFormatter(console_formatter)
fh.setFormatter(file_formatter)
#默认日志级别是warning
logger.debug("test_log")
#全局设置为debug后,console handler设置为info,如果输出的日志级别是debug,那就不会在屏幕上打印
filter 组件
如果你想对日志内容进行过滤,就可自定义一个filter
import logging
from logging import handlers
class IgnoreBackupLogFilter(logging.Filter):
"""忽略带db backup 的日志"""
def filter(self, record): #日志对象传进来,固定写法
return "db backup" not in record.getMessage()#不在日志里,返回true
#1.生成logger对象
logger = logging.getLogger("web")
logger.setLevel(logging.DEBUG)
# 1.1把filter对象添加到logger中
logger.addFilter(IgnoreBackupLogFilter())
#2.生成handler对象
ch = logging.StreamHandler()
# fh = handlers.RotatingFileHandler(filename="web.log",maxBytes=10,backupCount=3)
fh = handlers.TimedRotatingFileHandler("web.log",when="S",interval=5,backupCount=3)
# fh = logging.FileHandler("web.log")
#2.1把handler对象绑定到logger对象
logger.addHandler(ch)
logger.addHandler(fh)
#3生成formatter对象
file_formatter = logging.Formatter('%(asctime)s - %(name)s - %(levelname)s - %(message)s')
console_formatter = logging.Formatter('%(asctime)s - %(name)s - %(levelname)s - %(lineno)d - %(message)s')
#3.1把formatter对象绑定到handler对象
ch.setFormatter(console_formatter)
fh.setFormatter(file_formatter)
logger.info("test_log3")
logger.warning("test_log4")
logger.debug("test_log")
logger.debug("test log db backup")
总结
基础常用模块