爬虫程序采集网络数据
目录
一、Xampp搭建本地网站
二、认识Html标签
三、爬虫程序范例
(一)调用模块
(二)加载需要爬虫的网址
(三)爬取内容选取
(四)爬取内容保存
(五) 完整爬虫程序
一、Xampp搭建本地网站
第一步:启动web服务:运行Xampp,启动Apache.


第二步:设置本地网站


此时,本地网站地址就设置好了,地址为:http://127.0.0.1/wholesale.html
二、认识Html标签








三、爬虫程序范例
第一步:打开第一部分设置好的地址:http://127.0.0.1/wholesale.html,可以看到网页内容

(一)调用模块
调用爬虫模块
import bs4
import requests调用excel和日期时间模块
import xlwt
import datetime(二)加载需要爬虫的网址
date = datetime.datetime.now().strftime('%Y-%m-%d') # 给文件打上时间戳,便于数据更新
url = 'http://127.0.0.1/wholesale.html' # 网址
payload = {'SearchText': 'nike', 'page': '1', 'ie': 'utf8', 'g': 'y'} # 字典传递url参数(三)爬取内容选取
soup.find_all 中的两个参数 :爬取的网页内容的标签名称和标签属性class的值
all_title = soup.find_all('a', class_='item-title')class的值填写:
第一步:选择商品标题,右击鼠标,选择【检查】

第二步:网页会自动定位到商品标题内容部分。可以显示为a标签,class为item-title,将其填入到python代码中即可。

因此,代码含义为:
all_title = soup.find_all('a', class_='item-title')#爬取页面代码中所有属性为item-title的a标签内容,并写入到all_title列表需要注意的是,如果选取的内容没有class,则返回上一级标签的内容:
即:
all_title = soup.find_all('div', class_='item-title-wrap') 
title.append参数:读取列表中某个标签内的字符串。下面代码的含义为:将a标签的内容增加到title列表
title.append(soup_title.a.string)(四)爬取内容保存
将爬取的数据保存在程序同一目录下生成的以“%s-%s.xls”以日期命名的文件中。如果是想把xls名字改为“淘宝”,则代码更改为"淘宝.xls",则爬取的数据将保存在"淘宝.xls"文件中。
wookbook.save("%s-%s.xls" % (payload['SearchText'], date)) #保存文件
print("写入excel表格成功!")(五) 完整爬虫程序
# -*- coding: utf-8 -*-
import bs4
import requests
import xlwt
import datetime
date = datetime.datetime.now().strftime('%Y-%m-%d') # 给文件打上时间戳,便于数据更新
url = 'http://127.0.0.1/wholesale.html' # 网址
payload = {'SearchText': 'nike', 'page': '1', 'ie': 'utf8', 'g': 'y'} # 字典传递url参数
# 初始化数据容器
title = []
price = []
order = []
store = []
# 爬取网页上的数据
for i in range(0, 5): # 循环5次,就是5个页的商品数据
payload['page'] = i+ 1 # 此处为页码,根据网页参数具体设置
resp = requests.get(url, params=payload)
soup = bs4.BeautifulSoup(resp.text, "html.parser")
print(resp.url) # 打印访问的网址
resp.encoding = 'utf-8' # 设置编码
# 标题
all_title = soup.find_all('a', class_='item-title')
for j in all_title:
soup_title = bs4.BeautifulSoup(str(j), "html.parser",)
title.append(soup_title.a.string)
# 价格
all_price = soup.find_all('span', class_="price-current")
for k in all_price:
soup_price = bs4.BeautifulSoup(str(k), "html.parser")
price.append(soup_price.span.string)
# 订单量
all_order = soup.find_all('a', class_="sale-value-link")
for l in all_order:
soup_order = bs4.BeautifulSoup(str(l), "html.parser")
order.append(soup_order.a.string)
# 店铺名称
all_store = soup.find_all('a', class_="store-name")
for m in all_store:
soup_store = bs4.BeautifulSoup(str(m), "html.parser")
store.append(soup_store.a.string)
# 数据验证
print(len(title))
print(len(price))
print(len(order))
print(len(store))
if len(title) == len(price) == len(order) == len(store):
print("数据完整,生成 %d 组商品数据!" % len(title))
# 写入excel文档
print("正在写入excel表格...")
wookbook = xlwt.Workbook(encoding='utf-8') # 创建工作簿
data_sheet = wookbook.add_sheet('demo') # 创建sheet
# 生成每一行数据
for n in range(len(title)):
data_sheet.write(n, 0, n+1)
data_sheet.write(n, 1, title[n]) # n 表示行, 1 表示列
data_sheet.write(n, 2, price[n])
data_sheet.write(n, 3, order[n])
data_sheet.write(n, 4, store[n])
wookbook.save("%s-%s.xls" % (payload['SearchText'], date)) #保存文件
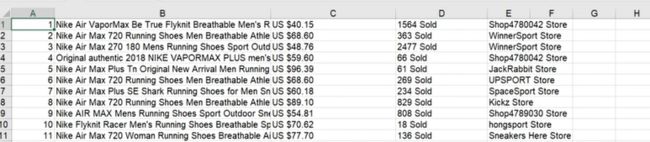
print("写入excel表格成功!")输出结果:

爬取成功,数据自动保存在以爬取当天日期命名的excel文件中

结果: