mpi实现矩阵乘法,卷积,池化(gemm,covn,pooling)
矩阵乘法:

卷积:

池化:


Mpi基本原理:
1.什么是MPI
Massage Passing Interface:是消息传递函数库的标准规范,由MPI论坛开发。
一种新的库描述,不是一种语言。共有上百个函数调用接口,提供与C和Fortran语言的绑定
MPI是一种标准或规范的代表,而不是特指某一个对它的具体实现
MPI是一种消息传递编程模型,并成为这种编程模型的代表和事实上的标准
2.MPI的特点
MPI有以下的特点:
消息传递式并行程序设计
指用户必须通过显式地发送和接收消息来实现处理机间的数据交换。
在这种并行编程中,每个并行进程均有自己独立的地址空间,相互之间访问不能直接进行,必须通过显式的消息传递来实现。
这种编程方式是大规模并行处理机(MPP)和机群(Cluster)采用的主要编程方式。
并行计算粒度大,特别适合于大规模可扩展并行算法
用户决定问题分解策略、进程间的数据交换策略,在挖掘潜在并行性方面更主动,并行计算粒度大,特别适合于大规模可扩展并行算法
消息传递是当前并行计算领域的一个非常重要的并行程序设计方式
二、MPI的基本函数
MPI调用借口的总数虽然庞大,但根据实际编写MPI的经验,常用的MPI函数是以下6个:
MPI_Init(…);
MPI_Comm_size(…);
MPI_Comm_rank(…);
MPI_Send(…);
MPI_Recv(…);
MPI_Finalize();
三、MPI的通信机制
MPI是一种基于消息传递的编程模型,不同进程间通过消息交换数据。
1.MPI点对点通信类型
所谓点对点的通信就是一个进程跟另一个进程的通信,而下面的聚合通信就是一个进程和多个进程的通信。

- 标准模式:
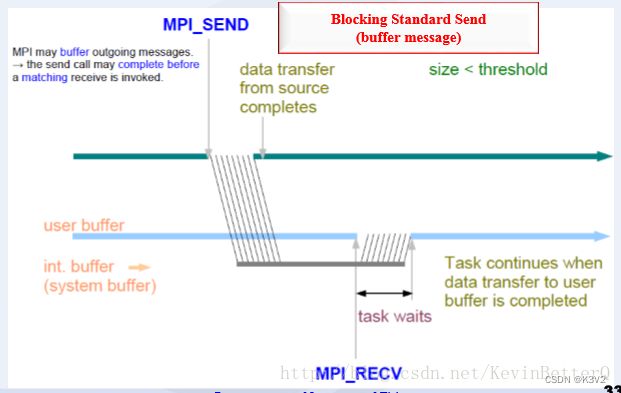
该模式下MPI有可能先缓冲该消息,也可能直接发送,可理解为直接送信或通过邮局送信。是最常用的发送方式。
由MPI决定是否缓冲消息
没有足够的系统缓冲区时或出于性能的考虑,MPI可能进行直接拷贝:仅当相应的接收完成后,发送语句才能返回。
这里的系统缓冲区是指由MPI系统管理的缓冲区。而非进程管理的缓冲区。
MPI环境定义有三种缓冲区:应用缓冲区、系统缓冲区、用户向系统注册的通信用缓冲区
MPI缓冲消息:发送语句在相应的接收语句完成前返回。
这时后发送的结束或称发送的完成== 消息已从发送方发出,而不是滞留在发送方的系统缓冲区中。
该模式发送操作的成功与否依赖于接收操作,我们称之为非本地的,即发送操作的成功与否跟本地没关系。
矩阵乘法代码实现:
#include
#include
#include
#include
int main(int argc,char *argv[])
{
double start, stop;
int i, j, k, l;
int *a, *b, *c, *buffer, *ans;
int size;
size = atoi(argv[1]);
int rank, numprocs, line;
MPI_Init(&argc, &argv);//MPI Initialize
MPI_Comm_rank(MPI_COMM_WORLD,&rank);//获得当前进程号
MPI_Comm_size(MPI_COMM_WORLD,&numprocs);//获得进程个数
line = size/numprocs;//将数据分为(进程数)个块,主进程也要处理数据
a = (int*)malloc(sizeof(int)*size*size);
b = (int*)malloc(sizeof(int)*size*size);
c = (int*)malloc(sizeof(int)*size*size);
//缓存大小大于等于要处理的数据大小,大于时只需关注实际数据那部分
buffer = (int*)malloc(sizeof(int)*size*line);//数据分组大小
ans = (int*)malloc(sizeof(int)*size*line);//保存数据块计算的结果
//主进程对矩阵赋初值,并将矩阵N广播到各进程,将矩阵M分组广播到各进程
if (rank==0)
{
printf("tast %d start\n", rank);
//从文件中读入矩阵
FILE *fp;
fp=fopen("a.txt","r");//打开文件
start = MPI_Wtime();
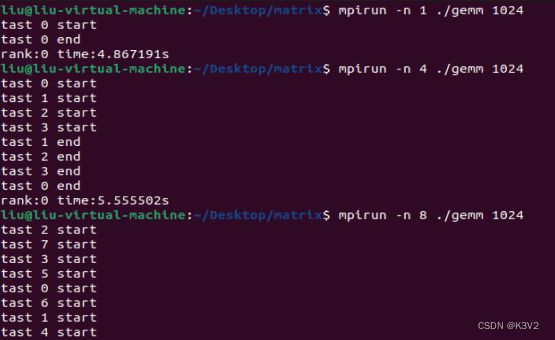
for(i=0;i 运行结果:
矩阵相乘:
卷积代码实现:
#include
#include
#include
#include
using namespace std;
// 定义卷积函数
vector> convolution(vector> image, vector> kernel) {
int image_height = image.size();
int image_width = image[0].size();
int kernel_height = kernel.size();
int kernel_width = kernel[0].size();
int output_height = image_height - kernel_height + 1;
int output_width = image_width - kernel_width + 1;
vector> output(output_height, vector(output_width, 0.0));
for (int i = 0; i < output_height; i++) {
for (int j = 0; j < output_width; j++) {
for (int k = 0; k < kernel_height; k++) {
for (int l = 0; l < kernel_width; l++) {
output[i][j] += image[i + k][j + l] * kernel[k][l];
}
}
}
}
return output;
}
int main(int argc, char** argv) {
MPI_Init(&argc, &argv);
int rank, size;
double start, stop;
MPI_Comm_rank(MPI_COMM_WORLD, &rank);
MPI_Comm_size(MPI_COMM_WORLD, &size);
// 定义图像和卷积核
vector> image = {{1, 2, 3, 4}, {5, 6, 7, 8}, {9, 10, 11, 12}, {13, 14, 15, 16}};
vector> kernel = {{1, 0}, {0, 1}};
// 计算每个进程需要处理的行数
int rows_per_process = image.size() / size;
int remainder = image.size() % size;
int start_row = rank * rows_per_process;
int end_row = start_row + rows_per_process;
if (rank == size - 1) {
end_row += remainder;
}
// 每个进程处理自己的部分图像
vector> local_image(end_row - start_row, vector(image[0].size(), 0.0));
for (int i = start_row; i < end_row; i++) {
for (int j = 0; j < image[0].size(); j++) {
local_image[i - start_row][j] = image[i][j];
}
}
// 每个进程计算自己的卷积结果
vector> local_output = convolution(local_image, kernel);
// 将每个进程的卷积结果发送给主进程
if (rank == 0) {
printf("tast %d start\n", rank);
start = MPI_Wtime();
vector> output(image.size() - kernel.size() + 1, vector(image[0].size() - kernel[0].size() + 1, 0.0));
for (int i = 0; i < local_output.size(); i++) {
for (int j = 0; j < local_output[0].size(); j++) {
output[i][j] = local_output[i][j];
}
}
for (int i = 1; i < size; i++) {
int start_row = i * rows_per_process;
int end_row = start_row + rows_per_process;
if (i == size - 1) {
end_row += remainder;
}
vector> temp_output(end_row - start_row, vector(image[0].size() - kernel[0].size() + 1, 0.0));
MPI_Recv(&temp_output[0][0], (end_row - start_row) * (image[0].size() - kernel[0].size() + 1), MPI_DOUBLE, i, 0, MPI_COMM_WORLD, MPI_STATUS_IGNORE);
for (int j = start_row; j < end_row; j++) {
for (int k = 0; k < image[0].size() - kernel[0].size() + 1; k++) {
output[j - kernel.size() + 1][k] = temp_output[j - start_row][k];
}
}
}
// 输出卷积结果
// for (int i = 0; i < output.size(); i++) {
// for (int j = 0; j < output[0].size(); j++) {
// cout << output[i][j] << " ";
//}
//cout << endl;
//}
stop = MPI_Wtime();
printf("tast %d end\n", rank);
printf("rank:%d time:%lfs\n",rank,stop-start);
} else {
printf("tast %d start\n", rank);
MPI_Send(&local_output[0][0], (end_row - start_row) * (image[0].size() - kernel[0].size() + 1), MPI_DOUBLE, 0, 0, MPI_COMM_WORLD);
printf("tast %d end\n", rank);
}
MPI_Finalize();
return 0;
}
运行结果:
卷积:

池化代码实现:
#include
#include
#include
#include
using namespace std;
vector> max_pooling(vector> img, int kernel_size, int rank, int size) {
int img_height = img.size();
int img_width = img[0].size();
int pool_height = img_height / kernel_size;
int pool_width = img_width / kernel_size;
int pool_size = pool_height * pool_width;
int pool_per_process = pool_size / size;
int remainder = pool_size % size;
int start_index = rank * pool_per_process;
int end_index = (rank + 1) * pool_per_process;
if (rank == size - 1) {
end_index += remainder;
}
vector> pool(end_index - start_index, vector(1));
int pool_index = 0;
for (int i = 0; i < pool_height; i++) {
for (int j = 0; j < pool_width; j++) {
if (pool_index >= start_index && pool_index < end_index) {
int max_val = INT_MIN;
for (int k = 0; k < kernel_size; k++) {
for (int l = 0; l < kernel_size; l++) {
int val = img[i * kernel_size + k][j * kernel_size + l];
if (val > max_val) {
max_val = val;
}
}
}
pool[pool_index - start_index][0] = max_val;
}
pool_index++;
}
}
return pool;
}
int main(int argc, char** argv) {
int rank, size;
double start, stop;
MPI_Init(&argc, &argv);
MPI_Comm_rank(MPI_COMM_WORLD, &rank);
MPI_Comm_size(MPI_COMM_WORLD, &size);
int img_height = 8;
int img_width = 8;
int kernel_size = 4;
vector> img(img_height, vector(img_width));
for (int i = 0; i < img_height; i++) {
for (int j = 0; j < img_width; j++) {
//img[i][j] = i * img_width + j + 1;
}
}
vector> pool = max_pooling(img, kernel_size, rank, size);
vector> all_pool(4 * 4, vector(1));
MPI_Gather(&pool[0][0], pool.size() * pool[0].size(), MPI_INT, &all_pool[0][0], pool.size() * pool[0].size(), MPI_INT, 0, MPI_COMM_WORLD);
if (rank == 0) {
//printf("task:%d start\n",rank);
start = MPI_Wtime();
for (int i = 0; i < all_pool.size(); i++) {
cout << "";
}
cout << endl;
// printf("task:%d end\n",rank);
}
stop = MPI_Wtime();
if (rank == 0){
printf("rank:%d time:%lfs\n",rank,stop-start);
}
MPI_Finalize();
return 0;
}
池化:
