Go内存管理模型
文章目录
-
- 一、引入
-
- 内存为什么需要管理?
- 操作系统是如何管理内存的?
- 虚拟内存
- 内存分配知识
- 二、Go内存管理
-
- 1、内存四区概念
- 2、几个重要概念
-
- mcentral
- mcache
- Tiny对象
- 大对象
- 3、Go内存分配
-
- 动态存储分配器
- mmap函数
- 数据频繁分配与回收
- 4、Go的内存分配
- 5、Go的内存模型
- 6、总结
相关链接:
Go设计与实现:https://draveness.me/golang/docs/part3-runtime/ch07-memory/golang-memory-allocator/
参考连接:https://www.topgoer.cn/docs/go-internals/go-internals-1d2ah5r9d6uhu
参考连接:https://www.jianshu.com/p/7405b4e11ee2
参考连接:https://www.topgoer.cn/docs/data-structures-questions/data-structures-questions-1d94t1t1sb68s
一、引入
性能越大的计算机硬件的合理利用和分配就越重要。
空间:内存<<固态盘<机械盘
价格:内存>>固态盘>机械盘
性能:内存>>固态盘>机械盘

性能要求我们将大部分程序逻辑临时用的数据,全部都存在内存之中,
比如,变量、全局变量、函数跳转地址、静态库、执行代码、临时开辟的内存结构体(对象)等。
内存为什么需要管理?
因为内存贵啊!
当我们希望存储的东西越来越多,也就发现物理内存的容量依然是不够用,那么对物理内存的利用率和合理的分配,管理就变得非常的重要。
1、首先操作系统就会对内存进行非常详细的管理。
2、其次基于操作系统的基础上,不同语言的内存管理机制也应允而生,但是有的一些语言并没有提供自动的内存管理模式,有的语言就已经提供了自身程序的内存管理模式:
| 内存自动管理的语言(部分) | 非自动管理的语言(部分) |
|---|---|
| Golang | C |
| Java | C++ |
| Python | Rust |
所以为了降低内存管理的难度,像C、C++完全将分配和回收内存的权限交给开发者,而Rust则是通过生命周期限定开发者对非法权限内存的访问来自动回收,因而并没有提供自动管理的一套机制。但是像Golang、Java、Python这类为了完全让开发则关注代码逻辑本身,语言层提供了一套管理模式。
操作系统是如何管理内存的?
计算机对于内存真正的载体是“内存条”,这个是实打实的物理硬件容量,所以,在操作系统中,我们定义为这部门的容量叫“物理内存”。
物理内存的布局实际上就是一个内存大“数组”。
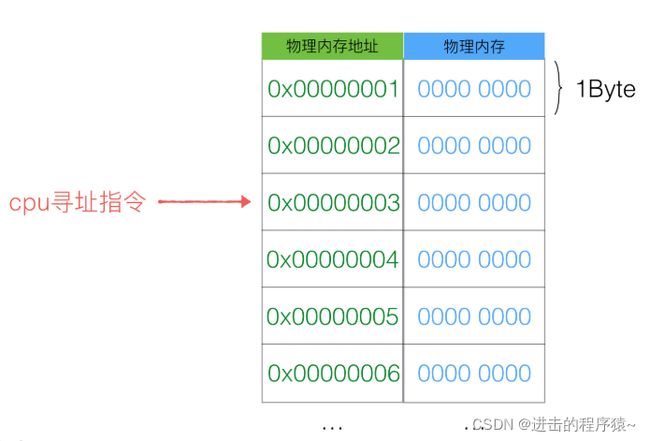
每一个元素都会对应一个地址,这个我们称之为物理内存地址。那么cpu在运算的过程中,如果需要从内存中取1个字节的数据,就需要机制这个数据的物理内存地址就好了,而且物理内存地址是连续的,可以根据一个基准地址进行偏移来取得相应的一块连续内存数据。
但我们知道,我们的一个操作系统是不可能只运行一个程序的,那么这个“大数组”物理内存势必要被n个程序分成N分,供每个程序使用。
但是程序是“活”的,他可能一会需要1G内存,一会需要1MB内存,我们只能取这个程序允许的最大内存极限来分配内存给这个进程,那么很显然,每个进程都会多要去一大部分内存,却不常使用。
但如果N个程序同时使用同一块内存,那么读写的冲突也在所难免。
这些昂贵的内存条,几乎跑不了几个程序,内存的利用率也提高不上来。
所以就需要所谓的操作系统的内存管理方式了, 他就是“虚拟内存”。
虚拟内存
虚拟,当然就是“假", "凭空而造”的大致意思。对比上个图,你可以大致理解为虚拟内存的表现方式如下:

这样,用户程序(进程)只能使用虚拟的内存地址来获取数据,系统会将这个虚拟地址翻译成实际的物理地址。
并且这里面每一个程序统一使用一套连续虚拟地址,比如 0x 0000 0000 ~ 0x ffff ffff。从程序的角度来看,它觉得自己独享了一整块内存。不用考虑访问冲突的问题。系统会将虚拟地址翻译成物理地址,从内存上加载数据。
但如果你把虚拟内存直接理解为地址的映射关系,那就是太低估虚拟内存的虚拟了。
虚拟内存的目的一共是为了解决以下几件事:
- 1、物理内存无法被最大化利用。
- 2、程序逻辑内存空间使用独立。
- 3、内存不够,继续虚拟磁盘空间。
内存分配知识
- 计算机系统的主存被组织成一个由M个连续的字节大小的单元组成的数组,每个字节都有一个唯一的物理地址(PA)
- 现代处理器使用的是一种为虚拟寻址(VA)的寻址形式,最少的寻址单位是字
- 虚拟地址映射物理地址是通过读取页表(page table)进行地址翻译完成的:页表存放在物理存储器中
- MMU(内核吧物理页作为内存管理的基本单位)以页(page)大小为单位来管理系统中的页表
- 在虚拟存储器的习惯说法中,DRAM缓存不命中的成为:缺页
- page的结构与物理页相关,而非与虚拟页相关
- 系统中的每个物理页都要分配一个page结构体
二、Go内存管理
用户程序(Mutator)会通过内存分配器(Allocator)在堆上申请内存,而垃圾收集器(Collector)负责回收堆上的内存空间,内存分配器和垃圾收集器共同管理着程序中的堆内存空间。
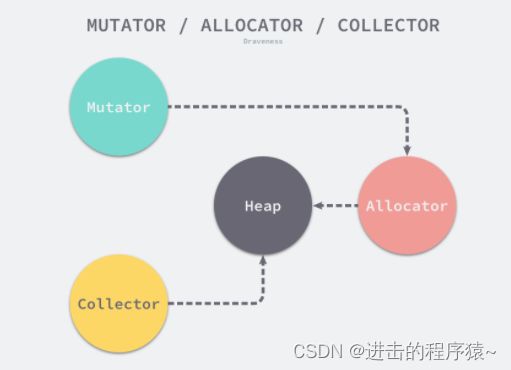
程序中的数据和变量都会被分配到程序所在的虚拟内存中,内存空间包含两个重要区域:栈区(Stack)和堆区(Heap)。函数调用的参数、返回值以及局部变量大都会被分配到栈上,这部分内存会由编译器进行管理;不同编程语言使用不同的方法管理堆区的内存,C++ 等编程语言会由工程师主动申请和释放内存,Go 以及 Java 等编程语言会由工程师和编译器共同管理,堆中的对象由内存分配器分配并由垃圾收集器回收。
Golang 的内存管理本质上就是一个内存池,只不过内部做了很多的优化。比如自动伸缩内存池大小,合理的切割内存块等等。
1、内存四区概念
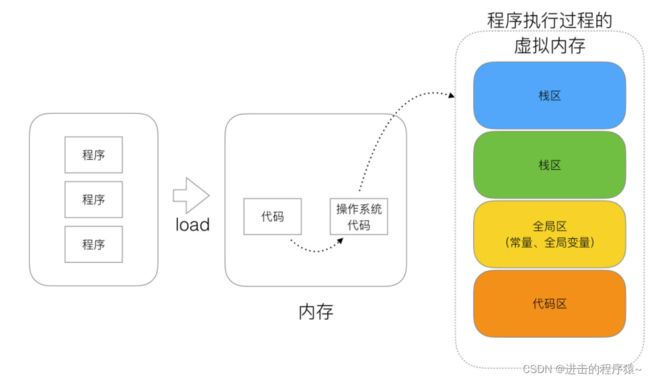
流程说明
1、操作系统把物理硬盘代码load到内存。
2、操作系统把c代码分成四个区。
3、操作系统找到main函数入口执行。
- 栈区(Stack):
空间较小,要求数据读写性能高,数据存放时间较短暂。由编译器自动分配和释放,存放函数的参数值、函数的调用流程方法地址、局部变量等(局部变量如果产生逃逸现象,可能会挂在在堆区) - 堆区(heap):
空间充裕,数据存放时间较久。一般由开发者分配及释放(但是Golang中会根据变量的逃逸现象来选择是否分配到栈上或堆上),启动Golang的GC由GC清除机制自动回收。 - 全局区-[静态]全局变量区:
全局变量的开辟是在程序在main之前就已经放在内存中。而且对外完全可见。即作用域在全部代码中,任何同包代码均可随时使用,在变量会搞混淆,而且在局部函数中如果同名称变量使用:=赋值会出现编译错误。
全局变量最终在进程退出时,由操作系统回收。 - 全局区-常量区:
常量区也归属于全局区,常量为存放数值字面值单位,即不可修改。或者说的有的常量是直接挂钩字面值的。
在golang中,常量是无法取出地址的,因为字面量符号并没有地址而言。
2、几个重要概念
-
内存池mheap
Golang 的程序在启动之初,会一次性从操作系统那里申请一大块内存作为内存池。这块内存空间会放在一个叫 mheap 的 struct 中管理,mheap 负责将这一整块内存切割成不同的区域,并将其中一部分的内存切割成合适的大小,分配给用户使用。 -
内存页page
一块 8K 大小的内存空间。Go 与操作系统之间的内存申请和释放,都是以 page 为单位的。 -
内存块span
一个或多个连续的 page 组成一个 span。 -
空间规格sizeclass
每个 span 都带有一个 sizeclass,标记着该 span 中的 page 应该如何使用。 -
对象object
用来存储一个变量数据内存空间,一个 span 在初始化时,会被切割成一堆等大的 object。假设 object 的大小是 16B,span 大小是 8K,那么就会把 span 中的 page 就会被初始化 8K / 16B = 512 个 object。所谓内存分配,就是分配一个 object 出去。
示意图:不同颜色代表不同的 span,不同 span 的 sizeclass 不同,表示里面的 page 将会按照不同的规格切割成一个个等大的 object 用作分配。

GO整体内存布局如下图所示【Go1.10】
Go 语言程序的 1.10 版本在启动时会初始化整片虚拟内存区域,如下所示的三个区域 spans、bitmap 和 arena 分别预留了 512MB、16GB 以及 512GB 的内存空间,这些内存并不是真正存在的物理内存,而是虚拟内存:
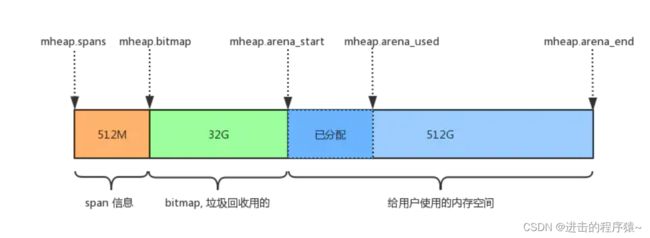
- mheap.spans
用来存储 page 和 span 信息,比如一个 span 的起始地址是多少,有几个 page,已使用了多大等等。 - mheap.bitmap
存储着各个 span 中对象的标记信息,比如对象是否可回收等等。 - mheap.arena_start:
将要分配给应用程序使用的空间。 - mheap.arena_used:
已经分配给应用程序使用的空间。
GO整体内存布局如下图所示【Go1.11】——稀疏内存
稀疏内存是 Go 语言在 1.11 中提出的方案,使用稀疏的内存布局不仅能移除堆大小的上限5,还能解决 C 和 Go 混合使用时的地址空间冲突问题6。不过因为基于稀疏内存的内存管理失去了内存的连续性这一假设,这也使内存管理变得更加复杂:
二维数组的二维大小是 4,194,304,因为每一个指针占用 8 字节的内存空间,所以元信息的总大小为 32MB。由于每个 runtime.heapArena 都会管理 64MB 的内存,整个堆区最多可以管理 256TB 的内存,这比之前的 512GB 多好几个数量级。
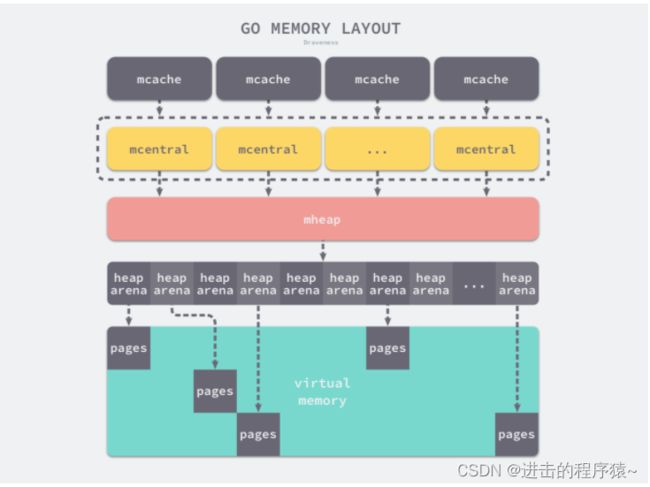
所有的 Go 语言程序都会在启动时初始化如上图所示的内存布局,每一个处理器都会分配一个线程缓存 runtime.mcache 用于处理微对象和小对象的分配,它们会持有内存管理单元 runtime.mspan。
每个类型的内存管理单元都会管理特定大小的对象,当内存管理单元中不存在空闲对象时,它们会从 runtime.mheap 持有的 134 个中心缓存 runtime.mcentral 中获取新的内存单元,中心缓存属于全局的堆结构体 runtime.mheap,它会从操作系统中申请内存。
在 amd64 的 Linux 操作系统上,runtime.mheap 会持有 4,194,304 runtime.heapArena,每个 runtime.heapArena 都会管理 64MB 的内存,单个 Go 语言程序的内存上限也就是 256TB。
mcentral
用途相同的 span 会以链表的形式组织在一起。 这里的用途用 sizeclass 来表示,就是指该 span 用来存储哪种大小的对象。比如当分配一块大小为 n 的内存时,系统计算 n 应该使用哪种 sizeclass,然后根据 sizeclass 的值去找到一个可用的 span 来用作分配。其中 sizeclass 一共有 67 种。如下图。找到合适的 span 后,会从中取一个 object 返回给上层使用。这些 span 被放在一个叫做 mcentral 的结构中管理。
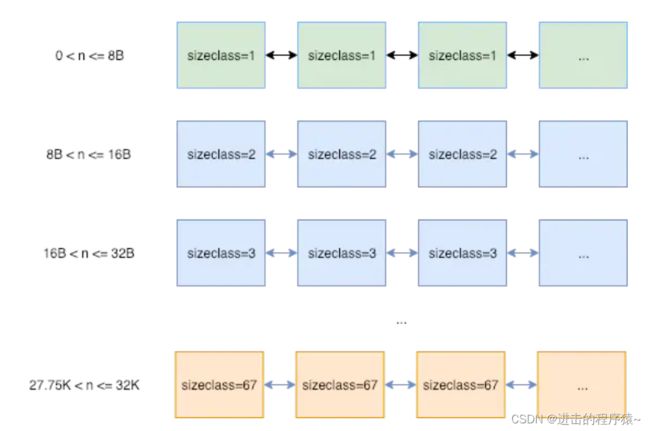
mheap 将从 OS 那里申请过来的内存初始化成一个大 span(sizeclass=0)。然后根据需要从这个大 span 中切出小 span,放在 mcentral 中来管理。大 span 由 mheap.freelarge 和 mheap.busylarge 等管理。如果 mcentral 中的 span 不够用了,会从 mheap.freelarge 上再切一块,如果 mheap.freelarge 空间不够,会再次从 OS 那里申请内存重复上述步骤。
mcache
mcentral 结构中有一个 lock 字段;因为并发情况下,很有可能多个线程同时从 mcentral 那里申请内存的,必须要用锁来避免冲突。
但锁是低效的,在高并发的服务中,它会使内存申请成为整个系统的瓶颈;所以在 mcentral 的前面又增加了一层 mcache。
每一个 mcache 和每一个处理器§是一一对应的,也就是说每一个 P 都有一个 mcache 成员。 Goroutine 申请内存时,首先从其所在的 P 的 mcache 中分配,如果 mcache 没有可用 span,再从 mcentral 中获取,并填充到 mcache 中。
从 mcache 上分配内存空间是不需要加锁的,因为在同一时间里,一个 P 只有一个线程在其上面运行,不可能出现竞争。没有了锁的限制,大大加速了内存分配。
所以整体的内存分配模型大致如下图所示

Tiny对象
sizeclass=1 的 span,用来给 <= 8B 的对象使用,所以像 int32, byte, bool 以及小字符串等常用的微小对象,都会使用 sizeclass=1 的 span,但分配给他们 8B 的空间,大部分是用不上的。并且这些类型使用频率非常高,就会导致出现大量的内部碎片。
所以 Go 尽量不使用 sizeclass=1 的 span, 而是将 < 16B 的对象为统一视为 tiny 对象(tinysize)。分配时,从 sizeclass=2 的 span 中获取一个 16B 的 object 用以分配。如果存储的对象小于 16B,这个空间会被暂时保存起来 (mcache.tiny 字段),下次分配时会复用这个空间,直到这个 object 用完为止。
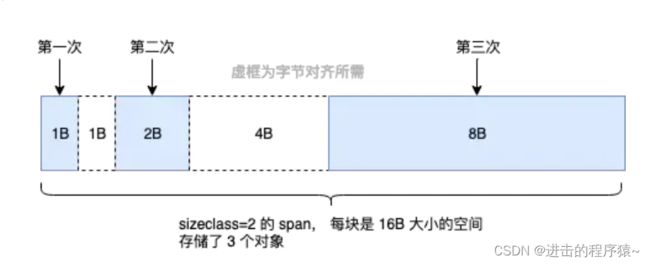
对 tiny 对象的特殊处理,平均会节省 20% 左右的内存。比如上图:(1+2+8) / 16 * 100% = 68.75%。而若以sizeclass=1 的span来分配则:(1+2+8) / (8 * 3) = 45.83% 。
如果要存储的数据里有指针,即使 <= 8B 也不会作为 tiny 对象对待,而是正常使用 sizeclass=1 的 span。
大对象
如上面所述,最大的 sizeclass 最大只能存放 32K 的对象。如果一次性申请超过 32K 的内存,系统会直接绕过 mcache 和 mcentral,直接从 mheap 上获取,mheap 中有一个 freelarge 字段管理着超大 span。
3、Go内存分配
Go内存管理基于TCMalloc,使用连续虚拟地址,以页(8k)为单位、多级缓存进行管理;在分配内存时,需要对size进行对齐处理,根据best-fit找到合适的mspan,对未用完的内存还会拆分成其他大小的mspan继续使用。
在new一个object时(忽略逃逸分析),根据object的size做不同的分配策略:
- 极小对象(size<16byte)直接在当前P的mcache上的tiny缓存上分配;
- 小对象(16byte <= size <= 32k)在当前P的mcache上对应slot的空闲列表中分配,无空闲列表则会继续向mcentral申请(还是没有则向mheap申请);
- 大对象(size>32k)直接通过mheap申请。
动态存储分配器
动态存储分配器维护着一个进程的虚拟存储区域,这个区域称为 “堆”,堆可以视为一组大小不同的 “块”(chunk: 连续的虚拟存储片,无论内存分配器和垃圾回收算法都依赖连续地址)的集合,并交由动态存储器维护。
动态分配器主要分为:
- 显式:常见的malloc
- 隐式:垃圾回收
在Go中,分配器将其管理(大块 –> 小块)的内存块分为两种:
- span:由多个连续的页(page)组成的大块内存。
- object:将span按特定大小切分多个小块,每个小块可存储一个对象。
按照其用途,span面向内部管理,object面向对象分配。
用于存储对象的object,按照8字节倍数分为n种。这种方式虽然会造成一些内存浪费,但分配器只须面对有限的规格的小块内存,优化了分配和复用管理策略。
分配器会尝试将多个微小对象组合到一个object块内,以节约内存。可以指定若对象大小超出特定阈值限制,会被当做大对象特别对待。
分配器初始化时,会构建对照表存储大小和规格对应关系,包括用来切分的span页数。
分配器按页数来区分不同大小的span。比如,以页数为单位将span存放到管理数组中,需要时就以页数为索引进行查找。当然,span大小并非固定不变。在获取闲置span时,如果没找到大小合适的,那就返回页数更多的,此时会引发裁剪操作,多余部分将构成新的span被放回管理数组。分配器还会尝试将地址相邻的空闲span合并,以构建更大的内存块,减少碎片,提供更灵活的分配策略。
mmap函数
Unix进程可以使用mmap函数来创建新的虚拟存储区域并将对象映射到这些区域中。
mmap函数要求内核创建一个新的虚拟存储区域,最好是从起始地址start开始的一个区域,并将文件描述符fd指定的对象的一个连续的片(chunk)映射到新的区域。
数据频繁分配与回收
对于有效地进行数据频繁分配与回收,减少碎片,一般有两种手段:
- 空闲链表: 提供直接可供使用,已分配的结构块,缺点是不能全局控制。
- slab:linux提供的,可以把不同的对象划分为所谓高速缓存组。
4、Go的内存分配
Go的内存分配器是采用google自家的tcmalloc,tcmalloc是一个带内存池的分配器,底层直接调用mmap函数,并使用bestfit进行动态分配。
Go为每个系统线程分配了一个本地MCache,少量的地址分配就是从MCache分配的,并且定期进行垃圾回收,所以可见go的分配器包含了显式与隐式的调用。
Go定义的小块内存,大小上是指32K或以下的对象,go底层会把这些小块内存按照指定规格(大约100种)进行切割,为了避免随意切割,申请任意字节内存时会向上取整到接近的块,将整块分配(从空闲链表)给到申请者。
Go内存分配主要组件:
- MCache:层次与MHeap类似,对于每个尺寸的类别都有一个空闲链表。每个M都有自己的局部Mcache(小对象从它取,无需加锁),这就是Go能够在多线程中高效内存管理的重要原因.
- MCentral:在无空闲内存的时候,向Mheap申请一个span,而不是多个,申请的span包含多少个page由central的sizeclass来确定(跨进程复用)
- MHeap:负责将MSpan组织和管理起来。
(1). 分配过程:从free中分配,如果发生切割则将剩余的部分放回到free中.
(2). 回收过程:回收一个Mspan时,首选查找它相邻的地址,再通过map映射得到对应的Mspan,如果Mspan的state是未使用,则可以将 两者进行合并。最后将这页或者合并后的页归还到free分配池或者large中。简单理解:就是分配的返过程,当 mcache 中存在较多空闲 span 时,会归还给 mcentral;而 mcentral 中存在较多空闲 span 时,会归还给 mheap;mheap 再归还给操作系统。
5、Go的内存模型
Go的内存模型可以视为两级的内存模型:
第一级:Mheap为主要组件:分配的单位是页,但管理的单位是MSpan,每次分配都是用bestFit的原则分配连续的页,回收是采用位图的方式。
第二级:MCache为主要组件:相当于一个内存池, 回收采用引用计数器。
- 内存分配流程
1、将小对象的大小向上取整到一个对应的尺寸类别(大约100种),查找相应的MCache的空闲链表,如果链表不空,直接从上面分配一个对象,这个过程不加锁。
2、如果MCache自由链表是空的,通过MCentral的自由链表取一些对象进行补充。
3、如果MCentral的自由链表是空的,则往MHeap中取用一些页对MCentral进行补充,然后将这些内存截断成特定规格。
4、如果MHeap空或者没有足够大的页的情况下,从操作系统分配一组新的页面,一般在1MB以上。
6、总结
Go 内存管理也是一个金字塔结构:
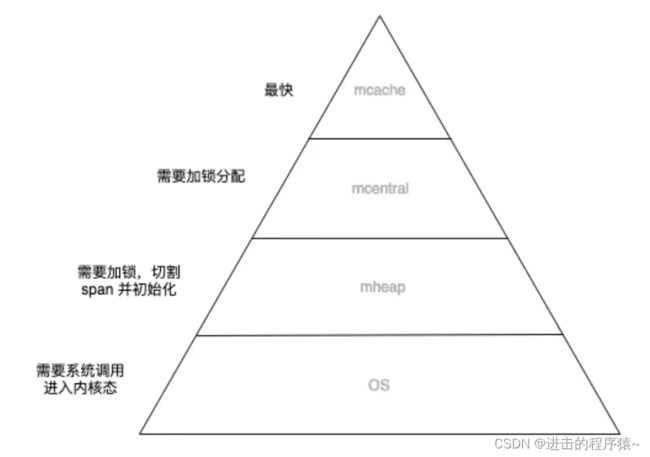
将有限的计算资源布局成金字塔结构,再将数据从热到冷分为几个层级,放置在金字塔结构上。调度器不断做调整,将热数据放在金字塔顶层,冷数据放在金字塔底层。
这种设计利用了计算机的局部性原理,认为冷热数据的交替是缓慢的。所以最怕的就是,数据访问出现冷热骤变。在操作系统上我们称这种现象为内存颠簸,系统架构上通常被说成是缓存穿透。其实都是一个意思,就是过度的使用了金字塔低端的资源。
总结一下,Go内存管理的这种设计之所以快,主要有以下几个优势:
1、内存分配大多时候都是在用户态完成的,不需要频繁进入内核态。
2、每个 P 都有独立的 span cache,多个 CPU 不会并发读写同一块内存,进而减少 CPU L1 cache 的 cacheline 出现 dirty 情况,增大 cpu cache 命中率。
3、内存碎片的问题,Go 是自己在用户态管理的,在 OS 层面看是没有碎片的,使得操作系统层面对碎片的管理压力也会降低。
4、mcache 的存在使得内存分配不需要加锁。