zabbix-4-触发器
4.触发器
4.1什么是触发器
当监控的值发现变化后,对应的值不符合预期,则应该通过触发器通知管理人员介入;
比如:监控TCP的80端口,如果存活则符合预期,如果不存活则不符合预期,应该通过触发器通知。
- 监控项仅仅负责收集数据,而通常收集数据的目的还包括指标对应的数据超出合理范围时给相关人员发送告警信息,触发器正是用于为监控项所收集的数据定义阈值;
- 每一个触发器仅能关联至一个监控项,但可以为一个监控项同时使用多个触发器;
- 事实上为一个监控项定义多个具有不同阈值的触发器可以实现不同级别的报警功能;
- 一个触发器由一个表达式构成,它定义了监控项所采取的数据的一个阈值;
- 一旦某次采集的数据超出了此触发器定义的阈值,触发器状态将会转变成problem,而当采集的数据再次回归至合理范围内时,其状态将重新返回ok状态 。
4.2触发器严重性
触发器严重性定义了触发器的重要程度,Zabbix支持下列触发器的严重程度:
| 严重性 | 定义 | 颜色 |
|---|---|---|
| 未分类 | 未知严重性 | 灰色 |
| 信息 | 提示 | 浅灰色 |
| 警告 | 警告 | 黄色 |
| 一般严重 | 一般问题 | 橙色 |
| 严重 | 发生重要的事情 | 浅红色 |
| 灾难 | 灾难,财务损失等 | 红色 |
- 通过不同颜色代表不同的严重程度
- 报警音频,不同的音频代表不同的严重程度
- 用户媒介,不同的用户媒介代表不同的严重程度。例如SMS-高严重性,email -其他
- 通过触发器执行对应的条件动作
4.3配置一个触发器
配置一个触发器,监控主机TCP80端口是否存活,如果不存活则通知,存活则不通知
- 配置→主机
- 点击主机一行的触发器
- 点击右上角的创建触发器(或者点击触发器名称去修改已存在的触发器)
- 在窗口中输入触发器的参数
为主机配置触发器,监测80端口是否存活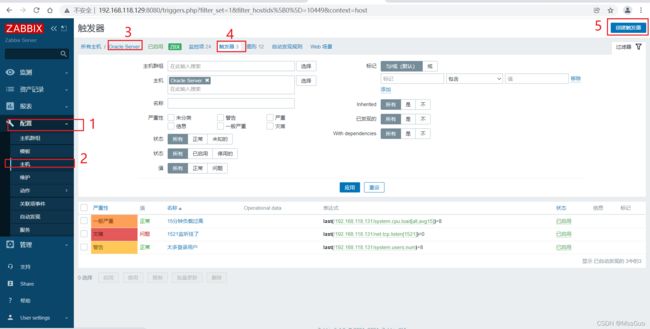

1,名称:可以用中文,自行编辑
2.选择严重性,不同的严重,警告信息会呈现不同颜色。
3.表达式 右侧有个添加 ,可以选择对应的监控项及表达式的算法。
4.可选,应用举例:加入表达式是cpu 使用率大于80时触发报警,但是如果cpu率在79和80之间震荡,报警会频繁的触及,就不太好了,这是我们可以使用恢复表达式,使用率小于70才恢复正常,这样就不担心震荡了
5.点击-添加
4.4 触发器表达式
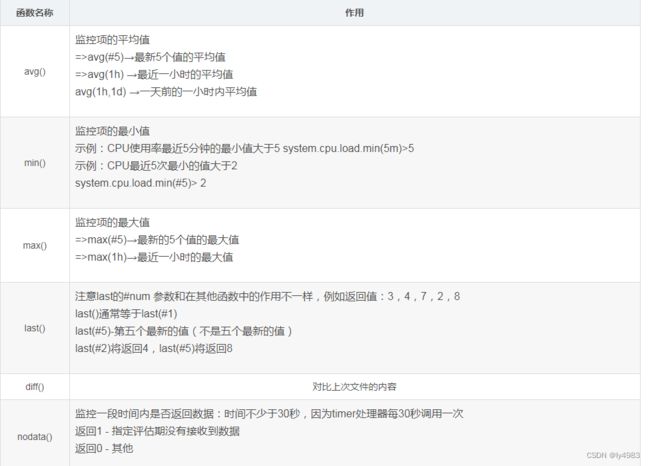
4.4.1 触发器示例场景1
www.zabbix.com的处理器负载过高
www.zabbix.com:system.cpu.load[all,avg1].last()>5
服务器是www.zabbix.com,监控项键值是system.cpu.load[all,avg1]
通过使用函数“last()”获取最新的值。最后>5 意味着当www.zabbix.com最新获取的处理器负载值大于5时触发器就会处于异常状态。
4.4.2 触发器示例场景2
当前处理器负载大于5或者最近10分钟内最小值大于2,表达式为True
{www.zabbix.com:system.cpu.load[all,avg1].last()>5} and {www.zabbix.com:system.cpu.load[all.avg1].min(10m)>2}
4.4.3 触发器示例场景3
监控/etc/passwd 文件是否被修改,当文件/etc/passwd的checksum值与最近的值不同时,表达式为true。
{www.zabbix.com:vfs.file.cksum[/etc/passwd].diff()}=1
4.4.4 触发器示例场景4
最近5分钟,如果eth0上接受字节数大于100kb时,则表达式为真
{www.zabbix.com:net.if.in[eth0,bytes].min(5m)}>100k
4.4.5 触发器示例场景5
当www.zabbix.com在30分钟内超过5次不可达(值为0状态),则表达式为真
{www.zabbix.com:icmpping.count(30m,0)}>5
4.4.6 触发器示例场景6
比较今天的平均负载和昨天同一时间的平均负载, 使用第二个“时间偏移参数”
如果最近一小时的平均负载超过昨天相同小时负载的2倍,触发器将会触发
{server:system.cpu.load.avg(1h)}/{server:system.cpu.load.avg(1h,1d)}>2
4.4.7 触发器示例场景7
如果表达式中至少有2个触发器大于5,触发器将触发
({server1:system.cpu.load[all.avg1].last()}>5)+
({server2:system.cpu.load[all.avg1].last()}>5)+
({server3:system.cpu.load[all.avg1].last()}>5)>=2
4.4.8 触发器示例场景8
使用nodata()函数:如果在180秒内没有接收到数据,则触发为异常状态
{www.zabbix.com:tick.nodata(3m)}=1
4.5 触发器滞后
有时候我们需要触发器处于OK和问题状态直接的区间,而不是一个简单的“阈值报警”就完事了。
例如,我们希望定义一个触发器,当机房温度超过20℃时,触发异常,我们希望它保持在那种状态,直到温度下降到15℃以下,为了做到这一点,我们首先要定义问题事件的触发表达式,然后再定义事件成功迭代中选择恢复表达式为OK事件输入恢复表达式
4.5.1 滞后示例1
机房温度过高
问题表达式:当机房温度大于20℃
{server:temp.last()}>=20
恢复表达式:当机房温度小于或者等于15℃
{server:temp.last()}<=15
4.5.2 滞后示例2
磁盘剩余空间过低
问题表达式:在最近5分钟内最大值小于10G
{server:vfs.fs.size[/,free].max(5m)}<10G
恢复表达式:最近10分钟内最小值大于40G
{server:vfs.fs.size[/,free].min(10m)}>40G
4.6 自定义触发器场景
4.6.1 配置单条件触发器
自定义单条件触发器:设置内存低于30%进行警告,点击对应主机→创建触发器
1.获取内存剩余百分比:
剩余30%可用,则需要告警通知;
剩余50%可用,就算恢复;
编辑触发器表达式
问题表达式:{server:Mem_pre.last()}<30
恢复表达式:{server:Mem_pre.last()}>50
使用dd if=/dev/zero of=/dev/null bs=500M count=1024 压低内存
4.6.2 配置多条件触发器
多条件触发器:设置内存低于30%并且swap使用大于1%进行告警
增加swap的监控UserParameter=Swap_pre,free -m |awk ‘/^Swap/{print $3*100/$2}’
编辑触发器表达式
问题表达式:{server:Mem_pre.last()}<30 and {server:Swap_pre.last()}>1
恢复表达式:{server:Mem_pre.last()}>30 and {server:Swap_pre.last()}<1
使用命令压测
dd if=/dev/zero of=/dev/null bs=300M count=1024 只满足内存低于百分之30,不会告警
dd if=/dev/zero of=/dev/null bs=800M count=1024 内存低于30%,并且swap使用超过1%