A Survey of Large Language Models
本文是LLM系列的第一篇文章,针对《A Survey of Large Language Models》的翻译。
大语言模型综述
- 摘要
- 1 引言
- 2 概述
-
- 2.1 LLM的背景
- 2.2 GPT系列模型 的技术演化
- 3 LLMs的资源
-
- 3.1 公开可用的模型检查点或APIs
- 3.2 常用的语料库
- 3.3 库资源
- 4 预训练
-
- 4.1 数据收集
-
- 4.1.1 数据源
- 4.1.2 数据预处理
- 4.1.3 预训练数据对LLMs的影响
- 4.2 架构
-
- 4.2.1 主流架构
- 4.2.2 详细配置
- 4.2.3 预训练任务
- 4.2.4 总结与讨论
- 4.3 模型训练
-
- 4.3.1 优化设置
- 4.3.2 可扩展训练技术
- 5 LLMs的自适应调整
-
- 5.1 指令调整
-
- 5.1.1 格式化实例构造
- 5.1.2 指令调整策略
- 5.1.3 指令调整的效果
- 5.2 对齐调整
-
- 5.2.1 对齐的背景与标准
- 5.2.2 收集人类反馈
- 5.2.3 从人类反馈中增强学习
- 5.3 有效调整
-
- 5.3.1 参数高效的微调方法
- 5.3.2 LLMs上的参数高效微调
- 6 利用
-
- 6.1 上下文学习
-
- 6.1.1 提示形式化
- 6.1.2 示例设计
- 6.1.3 机制
- 6.2 思维链提示
-
- 6.2.1 带有CoT的上下文学习
- 6.2.2 CoT的进一步讨论
- 7 能力评估
-
- 7.1 基本的评估任务
-
- 7.1.1 语言生成
- 7.1.2 知识利用
- 7.1.3 复杂推理
- 7.2 高级能力评估
-
- 7.2.1 人类对齐
- 7.2.2 与外部环境的互动
- 7.2.3 工具操纵
- 7.3 公开的基准与实证分析
-
- 7.3.1 评估基准
- 7.3.2 大模型能力的综合分析
- 8 结论与未来方向
摘要
自从20世纪50年代提出图灵测试以来,人类一直在探索通过机器掌握语言智能。语言本质上是一个由语法规则控制的复杂的人类表达系统。开发能够理解和掌握语言的人工智能算法是一个重大挑战。在过去的二十年里,语言建模作为一种主要的语言理解和生成方法得到了广泛的研究,从统计语言模型发展到神经语言模型。最近,通过在大规模语料库上对Transformer模型进行预训练,提出了预训练语言模型(PLM),在解决各种自然语言处理(NLP)任务方面表现出强大的能力。由于研究人员发现模型缩放可以提高模型容量,他们通过将参数缩放增加到更大的尺寸来进一步研究缩放效应。有趣的是,当参数尺度超过一定水平时,这些放大的语言模型不仅实现了显著的性能改进,而且还表现出了一些小规模语言模型(如BERT)中不存在的特殊能力(如上下文学习)。为了区分不同参数尺度下的语言模型,研究界为具有显著规模的PLM(例如,包含数百亿或数千亿个参数)创造了“大型语言模型”(LLM)一词。近年来,学术界和工业界对LLM的研究都取得了很大进展,其中一个显著的进展是ChatGPT(一种基于LLM开发的强大的人工智能聊天机器人)的推出,引起了社会的广泛关注。LLM的技术发展对整个人工智能社区产生了重要影响,这将彻底改变我们开发和使用人工智能算法的方式。考虑到这一快速的技术进步,在本次综述中,我们通过介绍背景、关键发现和主流技术来回顾LLM的最新进展。特别是,我们关注LLM的四个主要方面,即预训练、适应调整、利用和能力评估。此外,我们还总结了开发LLM的可用资源,并讨论了未来方向的剩余问题。这项综述提供了LLM文献的最新综述,这对研究人员和工程师来说都是一个有用的资源。
1 引言
语言是人类表达和交流的一种突出能力,它在儿童早期发展,并在一生中进化。然而,除非配备强大的人工智能算法,否则机器无法自然地掌握以人类语言形式进行理解和交流的能力。实现这一目标,使机器能够像人类一样阅读、书写和交流,一直是一个长期的研究挑战。
从技术上讲,语言建模(LM)是提高机器语言智能的主要方法之一。一般来说,LM旨在对单词序列的生成可能性进行建模,从而预测未来(或丢失)标记的概率。LM的研究在文献中受到了广泛的关注,可分为四个主要的发展阶段:
- 统计语言模型。SLM是基于20世纪90年代兴起的统计学习方法开发的。其基本思想是基于马尔可夫假设建立单词预测模型,例如,基于最近的上下文预测下一个单词。具有固定上下文长度n的SLM也称为n-gram语言模型,例如,bigram和trigram语言模型。SLM已被广泛应用于提高信息检索(IR)和自然语言处理(NLP)中的任务性能。然而,它们经常遭受维度的诅咒:由于需要估计指数数量的转换概率,因此很难准确估计高阶语言模型。因此,引入了专门设计的平滑策略,如退避估计和Good–Turing估计,以缓解数据稀疏性问题。
- 神经语言模型(NLM)。NLM通过神经网络(例如递归神经网络)来表征单词序列的概率。作为一项显著的贡献,[15]中的工作引入了单词的分布式表示的概念,并建立了以聚合上下文特征(即分布式单词向量)为条件的单词预测函数。通过扩展学习单词或句子的有效特征的思想,开发了一种通用的神经网络方法来为各种NLP任务构建统一的解决方案。此外,word2vec被提议建立一个用于学习分布式单词表示的简化浅层神经网络,该网络在各种NLP任务中被证明是非常有效的。这些研究开创了将语言模型用于表示学习(超越单词序列建模),对NLP领域产生了重要影响。
- 预训练的语言模型(PLM)。作为早期的尝试,ELMo被提出通过首先预训练双向LSTM(biLSTM)网络(而不是学习固定的单词表示),然后根据特定的下游任务微调biLSTM网络来捕获上下文感知的单词表示。此外,基于具有自注意机制的高度并行化的Transformer架构,通过在大规模未标记语料库上使用专门设计的预训练任务预训练双向语言模型,提出了BERT。这些预训练的上下文感知单词表示作为通用语义特征非常有效,这在很大程度上提高了NLP任务的性能标准。这项研究启发了大量的后续工作,确立了“预训练和微调”的学习范式。根据这一范式,已经开发了大量关于PLM的研究,引入了不同的架构(例如,GPT-2和BART)或改进的预训练策略。在这种模式下,通常需要对PLM进行微调,以适应不同的下游任务。
- 大型语言模型(LLM)。研究人员发现,扩展PLM(例如,扩展模型大小或数据大小)通常会提高下游任务的模型容量(即,遵循扩展定律)。许多研究已经通过训练越来越大的PLM(例如,175B参数GPT-3和540B参数PaLM)来探索性能极限。尽管缩放主要在模型大小上进行(具有类似的架构和预训练任务),但这些大型PLM表现出与较小PLM不同的行为(例如,330M参数BERT和1.5B参数GPT-2),并在解决一系列复杂任务时表现出令人惊讶的能力(称为涌现能力)。例如,GPT-3可以通过上下文学习解决小样本任务,而GPT-2则不能很好地解决。因此,研究界为这些大型PLM创造了“大型语言模型(LLM)”一词。LLM的一个显著应用是ChatGPT,它将GPT系列的LLM用于对话,展现了与人类惊人的对话能力。
在现有文献中,PLM已被广泛讨论和综述,而LLM很少以系统的方式进行综述。为了激励我们的综述,我们首先强调LLM和PLM之间的三个主要区别。首先,LLM显示出一些令人惊讶的涌现能力,这在以前的较小PLM中可能没有观察到。这些能力是语言模型在复杂任务中表现的关键,使人工智能算法空前强大和有效。其次,LLM将彻底改变人类开发和使用人工智能算法的方式。与小型PLM不同,访问LLM的主要方法是通过提示界面(例如,GPT-4 API)。人类必须了解LLM是如何工作的,并以LLM可以遵循的方式格式化他们的任务。第三,LLM的发展不再明确区分研究和工程。LLM的训练需要在大规模数据处理和分布式并行训练方面有丰富的实践经验。为了开发有能力的LLM,研究人员必须解决复杂的工程问题,与工程师合作或成为工程师。
如今,LLM正在对人工智能社区产生重大影响,而ChatGPT和GPT-4的出现导致了对人工通用智能(AGI)可能性的重新思考。OpenAI发表了一篇题为“AGI及其后的规划”的技术文章,讨论了接近AGI的短期和长期计划,最近的一篇论文认为GPT-4可能被视为AGI系统的早期版本。随着LLM的快速发展,人工智能的研究领域正在发生革命性的变化。在NLP领域,LLM可以作为通用语言任务求解器(在某种程度上),研究范式已经转向LLM的使用。在IR领域,传统的搜索引擎受到了通过AI聊天机器人(即ChatGPT)寻找信息的新方式的挑战,而new Bing提出了一种基于LLM增强搜索结果的初步尝试。在CV领域,研究人员试图开发类似ChatGPT的视觉语言模型,这些模型可以更好地服务于多模式对话,GPT-4通过整合视觉信息支持多模式输入。这一新的技术浪潮可能会带来一个繁荣的基于LLM的现实世界应用生态系统。例如,微软365被LLM(即Copilot)授权自动化办公工作,而OpenAI支持在ChatGPT中使用插件来实现特殊功能。
尽管取得了进展并产生了影响,但LLM的基本原则仍然没有得到很好的探索。首先,为什么新兴能力出现在LLM中,而不是较小的PLM中,这是很神秘的。作为一个更普遍的问题,缺乏对LLM卓越能力的关键因素的深入、详细的调查。研究LLM何时以及如何获得这种能力是很重要的。尽管对这个问题进行了一些有意义的讨论,需要更有原则的综述来揭开“秘密”“LLM。其次,研究界很难培养出有能力的LLM。由于对计算资源的巨大需求,进行重复的、消融的研究以综述各种训练LLM策略的效果是非常昂贵的。事实上,LLM主要由行业训练,其中许多重要的训练细节(如数据收集和清洁)不向公众披露。第三,使LLM与人类价值观或偏好保持一致是一项挑战。尽管有这种能力,LLM也可能产生有毒、虚构或有害的内容。它需要有效和高效的控制方法来消除LLM使用的潜在风险。
面对机遇和挑战,LLM的研发需要更多的关注。为了对LLM有一个基本的了解,本综述从四个主要方面对LLM的最新进展进行了文献综述,包括预训练(如何预训练一个有能力的LLM)、适应调整(如何从有效性和安全性两个角度有效地调整预训练的LLM,利用率(如何使用LLM来解决各种下游任务)和能力评估(如何评估LLM的能力和现有的经验发现)。我们彻底梳理了文献,总结了LLM的关键发现、技术和方法。对于本次综述,我们还通过收集LLM的支持资源创建了一个GitHub项目网站,链接为https://github.com/RUCAIBox/LLMSurvey.我们还知道一些关于PLM或LLM的相关综述文章。这些论文要么讨论了有限法律责任或有限法律责任的某些特定(或一般)方面。与它们相比,我们专注于开发和使用LLM的技术和方法,并为LLM的重要方面提供了相对全面的参考。
本综述的其余部分组织如下:第2节介绍了LLM的背景,包括术语、设置、资源和组织大纲,然后在第3节中总结了开发LLM的可用资源。第4、5、6和7节分别从预训练、适应调整、利用和能力评估四个方面回顾和总结了最近的进展。最后,我们在第8节中总结了主要综述结果,并讨论了未来工作的剩余问题。
2 概述
在本节中,我们概述了LLM的背景,然后总结了GPT系列模型的技术演变。
2.1 LLM的背景
通常,大型语言模型(LLM)是指包含数千亿(或更多)参数的Transformer语言模型,这些参数是在大量文本数据上训练的,如GPT-3、PaLM、Galactica和LLaMA。LLM在理解自然语言和解决复杂任务(通过文本生成)方面表现出强大的能力。为了快速了解LLM的工作原理,本部分介绍了LLM的基本背景,包括缩放定律、涌现能力和关键技术。
LLM的缩放定律。
目前,LLM主要建立在Transformer架构的基础上,其中多头注意力层堆叠在非常深入的神经网络中。现有的LLM采用类似的Transformer架构和预训练目标(例如,语言建模)作为小型语言模型。而LLM在很大程度上扩展了模型大小、数据大小和总计算量(放大倍数)。广泛的研究表明,缩放可以在很大程度上提高LLM的模型容量。因此,建立一种定量方法来表征缩放效应是有用的。接下来,我们介绍Transformer语言模型的两个有代表性的缩放定律。
- KM比例定律。2020年,Kaplan等人(OpenAI团队)首次提出对神经语言模型的模型性能与三个主要因素的幂律关系进行建模,即模型大小(N)、数据集大小(D)和训练计算量(C)。在给定计算预算 c c c的情况下,他们根据经验给出了缩放定律的三个基本公式:
L ( N ) = ( N c N ) α N , α N ∼ 0.076 , N c ∼ 8.8 × 1 0 13 L ( D ) = ( D c D ) α D , α D ∼ 0.095 , D c ∼ 5.4 × 1 0 13 L ( C ) = ( C c C ) α C , α C ∼ 0.050 , C c ∼ 3.1 × 1 0 13 \begin{gather} L(N)=\Big(\frac{N_c}{N}\Big)^{\alpha_N},\alpha_N\sim0.076,N_c\sim8.8\times10^{13} \\ L(D)=\Big(\frac{D_c}{D}\Big)^{\alpha_D},\alpha_D\sim0.095,D_c\sim5.4\times10^{13} \notag \\ L(C)=\Big(\frac{C_c}{C}\Big)^{\alpha_C},\alpha_C\sim0.050,C_c\sim3.1\times10^{13} \notag \end{gather} L(N)=(NNc)αN,αN∼0.076,Nc∼8.8×1013L(D)=(DDc)αD,αD∼0.095,Dc∼5.4×1013L(C)=(CCc)αC,αC∼0.050,Cc∼3.1×1013
其中 L ( ⋅ ) L(\cdot) L(⋅)表示nats中的交叉熵损失。这三个定律是通过在一些假设下(例如,一个因素的分析不应受到其他两个因素的阻碍),用不同的数据大小(22M到23B词元)、模型大小(768M到1.5B非嵌入参数)和训练计算来拟合模型性能得出的。他们表明,模型性能与这三个因素有很强的依赖关系。 - Chinchilla缩放定律。作为另一项具有代表性的研究,Hoffmann等人(Google DeepMind团队)提出了一种缩放定律的替代形式,以指导LLM的计算机优化训练。他们通过改变更大范围的模型大小(70M到16B)和数据大小(5B到500B词元)进行了严格的实验,并拟合了类似的缩放定律,但具有不同的系数,如下:
L ( N , D ) = E + A N α + B D β , \begin{gather} L(N,D)=E+\frac{A}{N^\alpha}+\frac{B}{D^\beta}, \end{gather} L(N,D)=E+NαA+DβB,
其中 E = 1.69 , A = 406.4 , B = 410.7 , α = 0.34 E=1.69,A=406.4,B=410.7,\alpha=0.34 E=1.69,A=406.4,B=410.7,α=0.34和 β = 0.28 \beta=0.28 β=0.28。通过在约束 C ≈ 6 N D C\approx6ND C≈6ND下优化损失 L ( N , D ) L(N,D) L(N,D),他们表明计算资源预算分配给模型大小和数据大小的最佳配置可以推导如下:
N o p t ( C ) = G ( C 6 ) a , D o p t ( C ) = G − 1 ( C 6 ) b , \begin{gather} N_{opt}(C)=G\Big(\frac{C}{6}\Big)^a,D_{opt}(C)=G^{-1}\Big(\frac{C}{6}\Big)^b, \end{gather} Nopt(C)=G(6C)a,Dopt(C)=G−1(6C)b,
其中 a = α α + β , b = β α + β a=\frac{\alpha}{\alpha+\beta},b=\frac{\beta}{\alpha+\beta} a=α+βα,b=α+ββ,同时 G G G是缩放系数能够通过 A , B , α A,B,\alpha A,B,α和 β \beta β来计算。如[34]中所分析的,在计算预算增加的情况下,KM缩放定律倾向于在模型大小上比数据大小更大的预算分配,而Chinchilla缩放定律认为,这两个大小应该以相等的比例增加,即方程(3)中的a和b具有相似的值。
尽管有一些有限的假设,但这些缩放定律提供了对缩放效应的直观理解,使预测LLM在训练期间的性能变得可行。然而,根据缩放定律,一些能力(例如,上下文学习)是不可预测的,只有当模型大小超过一定水平时才能观察到(如下所述)。
LLM的涌现能力。
在文献[31]中,LLM的涌现能力被正式定义为“不存在于小模型中但出现于大模型中的能力”,这是LLM与以前的PLM区别开来的最突出特征之一。它进一步介绍了当涌现能力出现时的一个显著特征:当规模达到一定水平时,性能显著高于随机。类似地,这种涌现模式与物理学中的相变现象有着密切的联系。原则上,涌现能力可以定义为与一些复杂任务有关,而我们更关心的是可以应用于解决各种任务的一般能力。在这里,我们简要介绍了LLM的三种典型涌现能力以及具有这种能力的代表性模型。
- 上下文学习。GPT-3正式引入了上下文学习(ICL)能力:假设语言模型已经提供了一个自然语言指令和/或几个任务示例,它可以通过完成输入文本的单词序列来生成测试实例的预期输出,而不需要额外的训练或梯度更新。在GPT系列模型中,175B GPT-3模型总体上表现出较强的ICL能力,但GPT-1和GPT-2模型则不然。同时,这种能力也取决于具体的下游任务。例如,对于13B GPT-3,ICL能力可以出现在算术任务(例如,3位数的加法和减法)上,但175B GPT–3甚至不能很好地工作在波斯QA任务上。
- 指令跟随。通过对通过自然语言描述格式化的多任务数据集的混合进行微调(称为指令调整),LLM在同样以指令形式描述的看不见的任务上表现良好。通过指令调整,LLM能够在不使用显式示例的情况下遵循新任务的任务指令,从而具有改进的泛化能力。根据[62]中的实验,当模型大小达到68B时,指令调整的LaMDA PT在看不见的任务上开始显著优于未调整的,但在8B或更小的模型大小下则不然。最近的一项研究发现,PaLM至少需要62B的模型大小才能在四个评估基准(即MMLU、BBH、TyDiQA和MGSM)中的各种任务上表现良好,尽管对于一些特定任务(例如MMLU)来说,更小的大小可能足够了。
- 逐步推理。对于小型语言模型,通常很难解决涉及多个推理步骤的复杂任务,例如数学单词问题。而通过思维链(CoT)提示策略,LLM可以通过利用提示机制来解决此类任务,该提示机制涉及推导最终答案的中间推理步骤。据推测,这种能力可能是通过对代码进行训练获得的。一项实证研究表明,当应用于模型大小大于60B的PaLM和LaMDA变体时,CoT提示可以带来性能增益(在算术推理基准上),而当模型大小超过100B时,其相对于标准提示的优势变得更加明显。此外,CoT提示的性能改进似乎也因不同的任务而异,例如,GSM8K>MAWPS>PaLM的SWAMP。
LLM的关键技术。
LLM发展到目前的状态已经有很长的路要走:普通和有能力的学习者。在开发过程中,提出了一些重要的技术,极大地提高了LLM的能力。在这里,我们简要列出了(可能)导致LLM成功的几个重要技术,如下所示。
- 缩放。如前几部分所述,Transformer语言模型中存在明显的缩放效应:更大的模型/数据大小和更多的训练计算通常会提高模型容量。作为两个有代表性的模型,GPT-3和PaLM分别通过将模型大小增加到175B和540B来探索缩放极限。此外,由于计算预算通常是有限的,因此可以采用缩放定律来进行计算资源的更高效的分配。例如,Chinchilla(具有更多的训练词元)通过在相同的计算预算下增加数据规模,优于其对应的模型Gopher(具有更大的模型大小)。同时,应该注意的是,数据缩放应该经过仔细的清理过程,因为预训练数据的质量在模型容量中起着关键作用。
- 训练。由于模型尺寸巨大,成功训练一个有能力的LLM是非常具有挑战性的。需要分布式训练算法来学习LLM的网络参数,其中经常联合使用各种并行策略。为了支持分布式训练,已经发布了几个优化框架来促进并行算法的实现和部署,如DeepSpeed和Megatron LM。此外,优化技巧对训练稳定性和模型性能也很重要,例如,重新启动以克服训练损失峰值和混合精度训练。最近,GPT-4提出开发特殊的基础设施和优化方法,用更小的模型可靠地预测大型模型的性能。
- 启发能力。经过大规模语料库的预训练,LLM被赋予了作为通用任务解决者的潜在能力。然而,当LLM执行某些特定任务时,这些能力可能不会明确表现出来。作为技术方法,设计合适的任务指令或具体的情境学习策略来激发这种能力是有用的。例如,思维链提示已被证明通过包括中间推理步骤来解决复杂的推理任务是有用的。此外,我们可以通过用自然语言表达的任务描述进一步对LLM进行指令调整,以提高LLM在看不见的任务上的可推广性。然而,这些技术主要对应于LLM的涌现能力,这可能在小型语言模型上没有表现出相同的效果。
- 对齐调整。由于LLM是为了捕捉预训练语料库的数据特征而训练的(包括高质量和低质量的数据),因此它们很可能会对人类产生有毒、有偏见甚至有害的内容。有必要使LLM与人类价值观保持一致,例如有益、诚实和无害。为此,InstructGPT设计了一种有效的调整方法,使LLM能够遵循预期的指令,该方法利用了人类反馈的强化学习技术。它通过精心设计的标签策略将人融入训练循环。ChatGPT确实是在与InstructionGPT类似的技术上开发的,该技术在产生高质量、无害的回答方面表现出强大的协调能力,例如拒绝回答侮辱性问题。
- 工具操作。从本质上讲,LLM是作为大量纯文本语料库上的文本生成器进行训练的,因此在不能最好地以文本形式表达的任务(例如,数值计算)上执行得不太好。此外,他们的能力也局限于训练前的数据,例如无法获取最新信息。为了解决这些问题,最近提出的一种技术是使用外部工具来弥补LLM的不足。例如,LLM可以利用计算器进行精确计算,并使用搜索引擎检索未知信息。最近,ChatGPT启用了使用外部插件(现有或新创建的应用程序)的机制,与LLM的“眼睛和耳朵”类似。这种机制可以广泛扩大LLM的能力范围。
此外,许多其他因素(例如硬件的升级)也有助于LLM的成功。尽管如此,我们的讨论仅限于开发LLM的主要技术方法和关键发现。
2.2 GPT系列模型 的技术演化


由于ChatGPT在与人类交流方面的卓越能力,自发布以来,它点燃了人工智能社区的兴奋。ChatGPT是基于强大的GPT模型开发的,具有特别优化的会话能力。考虑到人们对ChatGPT和GPT模型越来越感兴趣,我们增加了一个关于GPT系列模型技术演变的特别讨论,以简要总结它们在过去几年中的发展进展。总体而言,OpenAI对LLM的研究大致可以分为以下几个阶段。
早期探索。
根据对Ilya Sutskever(OpenAI的联合创始人兼首席科学家)的一次采访,在OpenAI的早期就已经探索过用语言模型接近智能系统的想法,而在循环神经网络(RNN)中也尝试过。随着Transformer的出现,OpenAI开发了两个初始的GPT模型,即GPT-1和GPT-2,这两个模型可以被视为随后更强大的模型(即GPT-3和GPT-4)的基础。
- GPT-1。2017年,谷歌推出了Transformer模型,OpenAI团队迅速将他们的语言建模工作适应了这种新的神经网络架构。他们在2018年发布了第一个GPT模型,即GPT-1,并创造了缩写词GPT作为模型名称,代表生成预训练。GPT-1是基于生成的、仅解码器的Transformer架构开发的,并采用了无监督预训练和有监督微调的混合方法。GPT1为GPT系列模型建立了核心架构,并确立了对自然语言文本建模的基本原则,即预测下一个单词。
- GPT-2。遵循GPT-1的类似架构,GPT-2将参数规模增加到1.5B,并使用大型网页数据集WebText进行训练。正如GPT-2的论文中所声称的那样,它试图通过无监督的语言建模来执行任务,而无需使用标记数据进行明确的微调。为了激励这种方法,他们引入了一种用于多任务求解的概率形式,即 p ( o u t p u t ∣ i n p u t , t a s k ) p(output|input,task) p(output∣input,task)([106]中也采用了类似的方法),它根据输入和任务信息预测输出。为了对这种条件概率进行建模,语言文本可以自然地作为一种统一的方式来格式化输入、输出和任务信息。通过这种方式,解决任务的过程可以被转换为用于生成解决文本的单词预测问题。此外,他们为这一想法引入了一个更正式的说法:“由于(特定任务的)监督目标与无监督(语言建模)目标相同,但仅在序列的子集上进行评估,因此无监督目标的全局最小值也是监督目标(针对各种任务)的全局最小”。对这一主张的基本理解是,每个(NLP)任务都可以被视为基于世界文本子集的单词预测问题。因此,如果无监督语言建模被训练成具有足够的恢复世界文本的能力,那么它就能够解决各种任务。GPT-2论文中的这些早期讨论与黄仁勋(Jensen Huang)对伊利亚·萨茨克弗(Ilya Sutskever)的采访相呼应:“神经网络学习的是产生文本的过程的一些表征。文本实际上是世界的投影……你预测下一个单词的准确性越高,在这个过程中获得的分辨率就越高……”
容量飞跃。
尽管GPT-2旨在成为一种“无监督的多任务学习器”,但与现有技术的有监督微调方法相比,它的总体性能较差。虽然它的模型尺寸相对较小,但它在下游任务中进行了广泛的微调,尤其是对话框任务。在GPT-2的基础上,GPT-3通过扩展(几乎相同)生成预训练架构,展示了一个关键的能力飞跃。
- GPT-3。GPT-3于2020年发布,将模型参数扩展到175B的更大尺寸。在GPT-3的论文中,它正式引入了上下文学习(ICL)的概念,它以较少或零样本的方式使用LLM。ICL可以教授(或指导)LLM以自然语言文本的形式理解任务。使用ICL,LLM的预训练和利用收敛到相同的语言建模范式:预训练预测以下基于上下文的文本序列,而ICL预测正确的任务解决方案,在给定任务描述和示例的情况下,该解决方案也可以格式化为文本序列。GPT-3不仅在各种NLP任务中表现出非常出色的性能,而且在许多需要推理或领域自适应能力的特殊设计任务中也表现出非常优异的性能。尽管GPT-3的论文没有明确讨论LLM的涌现能力,但我们可以观察到可能超越基本缩放定律的巨大性能飞跃,例如,更大的模型具有更强的ICL能力(如GPT-3论文的原始图1.2所示)。总的来说,GPT-3可以被视为从PLM到LLM发展历程中的一个非凡里程碑。经验证明,将神经网络扩展到一个显著的规模可以导致模型容量的巨大增加。
能力提升。
由于强大的能力,GPT3一直是为OpenAI开发更强大LLM的基础模型。总体而言,OpenAI探索了两种主要方法来进一步改进GPT-3模型,即对代码数据进行训练和与人类偏好保持一致,具体如下。
- 代码数据训练。原始GPT-3模型(在纯文本上预先训练)的一个主要限制在于缺乏对复杂任务的推理能力,例如完成代码和解决数学问题。为了增强这一能力,OpenAI于2021年7月推出了Codex,这是一个在大型GitHub代码库上微调的GPT模型。它证明了Codex可以解决非常困难的编程问题,也可以显著提高解决数学问题的性能。此外,2022年1月报道了一种训练文本和代码嵌入的对比方法,该方法被证明可以改进一系列相关任务(即线性探针分类、文本搜索和代码搜索)。实际上,GPT-3.5模型是在基于代码的GPT模型(即code-davinci-002)的基础上开发的,这表明对代码数据的训练是提高GPT模型的模型能力,特别是推理能力的一种非常有用的实践。此外,也有人猜测,对代码数据进行训练可以大大提高LLM的思维链提示能力,但仍值得进一步研究和更彻底的验证。
- 人类对齐。关于人类比对的相关研究可以追溯到OpenAI的2017年(或更早):一篇题为“从人类偏好中学习”的博客文章发布在OpenAI博客上,描述了一项应用强化学习(RL)从人类注释的偏好比较中学习的工作(类似于图6中InstructGPT的对齐算法中的奖励训练步骤)。在这篇RL论文发布后不久,近端策略优化(PPO)的论文于2017年7月发表,该论文目前已成为从人类偏好中学习的基础RL算法。从人类偏好中学习的RL算法。2020年1月晚些时候,GPT-2使用上述RL算法进行了微调,该算法利用人类偏好来提高GPT-2在NLP任务上的能力。同年,另一项工作以类似的方式训练了一个用于优化人类偏好的摘要模型。基于这些先前的工作,InstructGPT于2022年1月提出,以改进用于人类比对的GPT-3模型,该模型正式建立了一个三阶段的人类反馈强化学习(RLHF)算法。请注意,在OpenAI的论文和文档中,似乎很少使用“指令调整”的措辞,取而代之的是对人类示例的监督微调(即RLHF算法的第一步)。除了提高指令跟随能力外,RLHF算法还特别有助于缓解LLM产生危害或有毒内容的问题,这是LLM在实践中安全部署的关键。OpenAI在一篇技术文章中描述了他们的对齐研究方法,该文章总结了三个有希望的方向:“训练人工智能系统使用人类反馈,帮助人类评估和进行对齐研究”。
这些增强技术使GPT-3模型得到了改进,具有更强的功能,OpenAI将其称为GPT-3.5模型(请参阅第3.1节中关于OpenAI API的讨论)。
语言模型的里程碑。
基于所有的探索努力,OpenAI已经实现了两个主要的里程碑,即ChatGPT和GPT-4,这在很大程度上提高了现有人工智能系统的容量。
- ChatGPT。2022年11月,OpenAI发布了基于GPT模型(GPT-3.5和GPT-4)的会话模型ChatGPT。正如官方博客文章所介绍的,ChatGPT以与InstructionGPT类似的方式进行训练(在原文章中称为“InstructionGPt的兄弟模型”),同时专门针对对话进行了优化。他们报告了ChatGPT和InstructionGPT在数据收集设置中的训练之间的差异:人工生成的对话(同时扮演用户和人工智能的角色)以对话格式与InstructionGPt数据集相结合,用于训练ChatGPT。ChatGPT在与人类交流方面表现出卓越的能力:拥有丰富的知识储备,对数学问题进行推理的技能,在多回合对话中准确追踪上下文,并与人类价值观保持良好一致以确保安全使用。后来,插件机制在ChatGPT中得到了支持,这进一步扩展了ChatGPT与现有工具或应用程序的能力。到目前为止,它似乎是人工智能历史上最强大的聊天机器人。ChatGPT的推出对未来的人工智能研究产生了重大影响,为探索类人人工智能系统提供了线索。
- GPT-4。作为另一个显著的进展,GPT-4于2023年3月发布,将文本输入扩展到多模态信号。总体而言,GPT-4在解决复杂任务方面的能力比GPT-3.5更强,在许多评估任务上表现出很大的性能改进。最近的一项研究通过对人类产生的问题进行定性测试,调查了GPT-4的能力,涵盖了各种各样的困难任务,并表明GPT-4可以实现比以前的GPT模型(如ChatGPT)更优越的性能。此外,由于六个月的迭代校准(在RLHF训练中有额外的安全奖励信号),GPT-4对恶意或挑衅性查询的响应更安全。在技术报告中,OpenAI强调了如何安全地开发GPT-4,并应用了一系列干预策略来缓解LLM可能存在的问题,如幻觉、隐私和过度依赖。例如,他们引入了一种名为“阅读团队”的机制,以减少危害或有毒内容的产生。作为另一个重要方面,GPT4是在完善的深度学习基础设施上开发的,具有改进的优化方法。他们引入了一种称为可预测缩放的新机制,该机制可以在模型训练期间用少量计算准确预测最终性能。
尽管取得了巨大进展,但这些高级LLM仍然存在局限性,例如,在某些特定背景下产生具有事实错误或潜在风险反应的幻觉。LLM的更多限制或问题将在第7节中讨论。开发能力更强、更安全的LLM是长期存在的研究挑战。从工程的角度来看,OpenAI采用了迭代部署策略,按照五个阶段的开发和部署生命周期来开发模型和产品,旨在有效降低使用模型的潜在风险。在下文中,我们将深入了解技术细节,以便具体了解它们是如何开发的。
3 LLMs的资源
考虑到具有挑战性的技术问题和对计算资源的巨大需求,开发或复制LLM绝非易事。一种可行的方法是从现有的LLM中学习经验,并重用公共资源进行增量开发或实验研究。在本节中,我们简要总结了用于开发LLM的公开资源,包括模型检查点(或API)、语料库和库。
3.1 公开可用的模型检查点或APIs
考虑到模型预训练的巨大成本,训练有素的模型检查点对于研究界LLM的研究和开发至关重要。由于参数规模是使用LLM需要考虑的关键因素,我们将这些公共模型分为两个规模级别(即数百亿个参数和数千亿个参数),这有助于用户根据其资源预算确定合适的资源。此外,对于推理,我们可以直接使用公共API来执行我们的任务,而无需在本地运行模型。接下来,我们将介绍公开可用的模型检查点和API。
具有数百亿参数的模型。
这一类别中的大多数模型的参数范围从10B到20B,除了LLaMA(在最大版本中包含65B参数)和NLLB(在最大版中包含54.5B参数)。该范围内的其他型号包括mT5、PanGu- α \alpha α、T0、GPT-Neox-20B、CodeGen、UL2、Flan-T5和mT0。其中,Flan-T5(11B版本)可以作为研究指令调优的首要模型,因为它从三个方面探索了指令调优:增加任务数量、扩大模型规模和使用思想链提示数据进行微调。此外,CodeGen(11B版本)作为一种用于生成代码的自回归语言模型,可以被认为是探索代码生成能力的良好候选者。它还引入了一个新的基准MTPB,专门用于多回合程序合成,由115个专家生成的问题组成。为了解决这些问题,LLM需要获得足够的编程知识(例如,数学、数组运算和算法)。对于多语言任务,mT0(13B版本)可能是一个很好的候选模型,它已经在带有多语言提示的多语言任务上进行了微调。此外,PanGu- α \alpha α在基于深度学习框架MindSpore开发的零样本或小样本设置下的中文下游任务中表现出良好的性能。请注意,PanGu- α \alpha α持有多个版本的模型(最多200B参数),而最大的公共版本具有13B参数。作为最近的一个版本,LLaMA(65B版本)包含的参数大约是其他模型的五倍,在与指令遵循相关的任务中表现出了卓越的性能。由于其开放性和有效性,LLaMA吸引了研究界的极大关注,许多努力都致力于微调或持续预训练其不同的模型版本,以实现新的模型或工具。通常,这种规模的预训练模型需要数百甚至数千个GPU或TPU。例如,GPT-NeoX-20B使用12个超微型服务器,每个服务器配备8个NVIDIA A100-SXM4-40GB GPU,而LLaMA使用2048个A100-80G GPU,如其原始出版物中所述。为了准确估计所需的计算资源,建议使用测量所涉及计算数量的指标,如FLOPS(即每秒浮点运算次数)。
具有数千亿参数的模型。
对于这一类别的模型,只有少数模型公开发布。例如,OPT、OPT-IML、BLOOM和BLOOMZ具有与GPT-3(175B版本)几乎相同数量的参数,而GLM和Galactica分别具有130B和120B参数。其中,OPT(175B版本)特别致力于开放共享,旨在使研究人员能够大规模开展可重复的研究。对于跨语言泛化的研究,BLOOM(176B版本)和BLOOMZ(176B版)可以作为基础模型,因为它们具有多语言建模任务的能力。在这些模型中,OPT-IML已经用指令进行了调整,这可能是研究指令调整效果的好候选者。这种规模的模型通常需要数千个GPU或TPU来训练。例如,OPT(175B版本)使用992个A100-80GB GPU,而GLM(130B版本)则使用96个NVIDIA DGX-A100(8x40G)GPU节点的集群。
LLM的公共API。
API不是直接使用模型副本,而是为普通用户提供了一种更方便的方式来使用LLM,而无需在本地运行模型。作为使用LLM的代表性接口,GPT系列模型的API已被学术界和工业界广泛使用。OpenAI为GPT-3系列中的模型提供了七个主要接口:ada、babbage、curie、davinci(GPT-3序列中最强大的版本)、text-ada-001、text-babbage-001和text-curie-001。其中,前四个接口可以在OpenAI的主机服务器上进行进一步的微调。特别是,babbage、curie和davinci分别对应于GPT-3(1B)、GPT-3(6.7B)和GPT-3)(175B)模型。此外,还有两种与Codex相关的API,称为code-cushman-001(Codex(12B)的强大的多语言版本)和code-davinci-002。此外,GPT-3.5系列包括一个代号为code-davinci-002的基础型号和三个增强版本,即text-davinci-002、text-davici-003和GPT-3.5-turbo-0301。值得注意的是,gpt-3.5-turbo-0301是调用ChatGPT的接口。最近,OpenAI还发布了GPT-4的相应API,包括GPT-4、GPT-4-0314、GPT-4-32k和GPT-4-32k-0314。总的来说,API接口的选择取决于具体的应用场景和响应要求。详细用法可在其项目网站上找到。
3.2 常用的语料库
与早期的PLM相比,由大量参数组成的LLM需要更大量的训练数据,这些数据涵盖了广泛的内容。为了满足这一需求,已经发布了越来越多可访问的训练数据集用于研究。在本节中,我们将简要总结几种广泛用于训练LLM的语料库。根据它们的内容类型,我们将这些语料库分为六组:书籍、CommonCrawl、Reddit链接、维基百科、代码和其他。
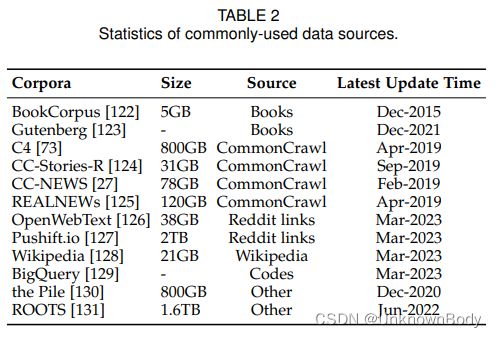
书
BookCorpus是以前小规模模型(例如GPT和GPT-2)中常用的数据集,由11000多本涵盖广泛主题和流派(例如小说和传记)的书籍组成。另一个大型图书语料库是古腾堡计划,由70000多本文学书籍组成,包括小说、散文、诗歌、戏剧、历史、科学、哲学和其他类型的公共领域作品。它是目前最大的开源图书收藏之一,用于MT-NLG和LLaMA的训练。至于GPT-3中使用的Books1和Books2,它们比BookCorpus大得多,但迄今尚未公开发布。
CommonCrawl。
CommonCrawl是最大的开源网络爬行数据库之一,包含PB级的数据量,已被广泛用作现有LLM的训练数据。由于整个数据集非常大,现有研究主要从中提取特定时期内的网页子集。然而,由于网络数据中普遍存在噪声和低质量的信息,因此有必要在使用前进行数据预处理。基于CommonCrawl,现有工作中常用的过滤数据集有四个:C4、CC-Stories、CC-News和RealNews。Colossal Clean Crawled Corpus(C4)包括五种变体,即en(806G)、en.noclean(6T)、realnews-like(36G)、webtext-like(17G)和多语言(38T)。en版本已用于预训练T5、LaMDA、Gopher和UL2。多语言C4,也称为mC4,已在mT5中使用。CC-Stories(31G)由CommonCrawl数据的子集组成,其中的内容以类似故事的方式制作。然而,CC-Stories的原始来源现在还不可用,因此复制版本CC-Stories-R已包含在表2中。此外,从CommonCrawl中提取的两个新闻语料库REALNEWS(120G)和CC news(76G)也常用作预训练数据。
Reddit链接。
Reddit是一个社交媒体平台,用户可以提交链接和文本帖子,其他人可以通过“赞成票”或“反对票”对其进行投票。投票率高的帖子通常被认为是有用的,可以用来创建高质量的数据集。WebText是一个著名的语料库,由来自Reddit的高度支持的链接组成,但它还没有公开。作为替代,有一种易于访问的开源替代方案,称为OpenWebText。从Reddit中提取的另一个语料库是PushShift.io,这是一个实时更新的数据集,由Reddit自创建之日以来的历史数据组成。Pushshift不仅提供每月的数据转储,还提供有用的实用工具,支持用户搜索、总结和对整个数据集进行初步调查。这使得用户可以轻松地收集和处理Reddit数据。
维基百科。
维基百科是一个在线百科全书,包含大量关于不同主题的高质量文章。这些文章大多是以解释性的写作风格撰写的(有辅助参考文献),涵盖了广泛的语言和领域。通常,维基百科的纯英文过滤版本被广泛用于大多数LLM(例如,GPT-3、LaMDA和LLaMA)。维基百科有多种语言,因此可以在多语言环境中使用。
代码。
为了收集代码数据,现有工作主要从互联网上抓取开源许可代码。两个主要来源是开源许可证下的公共代码库(如GitHub)和与代码相关的问答平台(如StackOverflow)。谷歌已经公开发布了BigQuery数据集,其中包括大量各种编程语言的开源许可代码片段,作为代表性的代码数据集。CodeGen利用BigQuery数据集的子集BIGQUERY来训练CodeGen的多语言版本(CodeGen Multi)。
其他。
Pile是一个大规模、多样化和开源的文本数据集,由来自多个来源的超过800GB的数据组成,包括书籍、网站、代码、科学论文和社交媒体平台。它由22个不同的高质量子集构成。Pile数据集广泛用于具有不同参数尺度的模型,如GPT-J(6B)、CodeGen(16B)和MegatronTuring NLG(530B)。此外,ROOTS由各种较小的数据集(总共1.61TB的文本)组成,涵盖59种不同的语言(包括自然语言和编程语言),这些语言已用于训练BLOOM。
在实践中,它通常需要不同数据源的混合来预训练LLM(见图2),而不是单个语料库。因此,现有的研究通常将几个现成的数据集(如C4、OpenWebText和Pile)混合,然后进行进一步的处理以获得预训练语料库。此外,为了训练适应特定应用的LLM,从相关来源(如维基百科和BigQuery)提取数据也很重要,以丰富预训练数据中的相应信息。为了快速参考现有LLM中使用的数据源,我们提供了三个具有代表性的LLM的预训练语料库:
- GPT-3(175B)是在300B词元的混合数据集上训练的,包括CommonCrawl、WebText2、Books1、Books2和Wikipedia。
- PaLM(540B)使用780B词元的预训练数据集,该数据集来源于社交媒体对话、过滤后的网页、书籍、Github、多语言维基百科和新闻。
- LLaMA从各种来源提取训练数据,包括CommonCrawl、C4、Github、维基百科、书籍、ArXiv和StackExchange。LLaMA(6B)和LLaMA的训练数据大小是1.0T词元,而1.4T词元用于LLaMA和LLaMA65B。

3.3 库资源
在这一部分中,我们简要介绍了一系列可用于开发LLM的库。
- Transformers是一个开源Python库,用于使用Transformer架构构建模型,该架构由Hugging Face开发和维护。它有一个简单且用户友好的API,使其易于使用和定制各种预训练模型。它是一个强大的库,拥有庞大而活跃的用户和开发人员社区,他们定期更新和改进模型和算法。
- DeepSpeed是微软开发的一个深度学习优化库(与PyTorch兼容),已用于训练许多LLM,如MTNLG和BLOOM。它为分布式训练提供了各种优化技术的支持,如内存优化(ZeRO技术、梯度检查点)和流水线并行。
- Megatron-LM是NVIDIA开发的深度学习库,用于训练大规模语言模型。它还为分布式训练提供了丰富的优化技术,包括模型和数据并行、混合精度训练和FlashAttention。这些优化技术可以在很大程度上提高训练效率和速度,从而实现跨GPU的高效分布式训练。
- JAX是谷歌开发的一个用于高性能机器学习算法的Python库,允许用户在具有硬件加速的阵列(例如GPU或TPU)上轻松执行计算。它能够在各种设备上进行高效计算,还支持多种功能,如自动微分和实时编译。
- Colossal-AI是HPC-AI Tech开发的一个深度学习库,用于训练大型AI模型。它是基于PyTorch实现的,并支持丰富的并行训练策略集合。此外,它还可以使用PatrickStar提出的方法优化异构内存管理。最近,一种名为ColossalChat的类似ChatGPT的模型公开发布了两个版本(7B和13B),这两个版本是使用基于LLaMA的Colossal AI开发的。
- BMTrain是OpenBMB开发的一个高效库,用于以分布式方式训练具有大规模参数的模型,强调代码简单性、低资源和高可用性。BMTrain已经将几种常见的LLM(例如,Flan-T5和GLM)纳入其模型中心,开发人员可以直接使用这些模型。
- FastMoE是MoE(即专家混合)模型的专业训练库。它是基于PyTorch开发的,在设计中优先考虑效率和用户友好性。FastMoE简化了将Transformer模型转换为MoE模型的过程,并在训练过程中支持数据并行和模型并行。
除了上述库资源之外,现有的深度学习框架(例如,PyTorch、TensorFlow、MXNet、PaddlePaddle、MindSpore和OneFlow)也提供了对并行算法的支持,这些算法通常用于训练大规模模型。
4 预训练
预训练为LLM的能力奠定了基础。通过大规模语料库的预训练,LLM可以获得基本的语言理解和生成技能。在这个过程中,预训练语料库的规模和质量对于LLM获得强大的能力至关重要。此外,为了有效地预训练LLM,需要精心设计模型架构、加速方法和优化技术。在接下来的内容中,我们首先在第4.1节中讨论数据收集和处理,然后在第4.2节中介绍常用的模型架构,最后在第4.3节中介绍稳定有效地优化LLM的训练技术。
4.1 数据收集
与小规模的语言模型相比,LLM对模型预训练的高质量数据有更强的需求,其模型能力在很大程度上取决于预训练语料库及其预处理方式。在这一部分中,我们讨论了预训练数据的收集和处理,包括数据源、预处理方法,以及预训练数据如何影响LLM性能的重要分析。
4.1.1 数据源
要开发一个有能力的LLM,关键是从各种数据源中收集大量的自然语言语料库。现有的LLM主要利用各种公共文本数据集的混合作为预训练语料库。图2显示了一些具有代表性的LLM的预训练数据来源的分布。
预训练语料库的来源大致可以分为两类:一般数据和专业数据。一般数据,如网页、书籍和会话文本,由于其庞大、多样和可访问的性质,被大多数LLM使用,这可以增强LLM的语言建模和泛化能力。鉴于LLM表现出令人印象深刻的泛化能力,也有研究将其预训练语料库扩展到更专业的数据集,如多语言数据、科学数据和代码,赋予LLM特定的任务解决能力。在下文中,我们描述了这两种类型的预训练数据源及其对LLM的影响。关于常用语料库的详细介绍,可以参考第3.2节。
常规文本数据。
如图2所示,绝大多数LLM采用通用的预训练数据,如网页、书籍和会话文本,这些数据提供了各种主题的丰富文本源。接下来,我们简要总结了三种重要的一般数据。
- 网页。由于互联网的普及,已经创建了各种类型的数据,这使得LLM能够获得不同的语言知识并增强其泛化能力。为了方便使用这些数据资源,在以前的工作中,如CommonCrawl中,从web上抓取了大量数据。然而,抓取的网页数据往往既包含维基百科等高质量文本,也包含垃圾邮件等低质量文本,因此过滤和处理网页对于提高数据质量非常重要。
- 对话文本。会话数据可以提高LLM的会话能力,并有可能提高他们在一系列问答任务中的表现。研究人员可以利用公共对话语料库的子集(例如,PushShift.io Reddit语料库)或从在线社交媒体收集对话数据。由于在线会话数据通常涉及多个参与者之间的讨论,因此一种有效的处理方法是将会话转换为树结构,将话语链接到其响应的话语。这样,多方会话树可以划分为多个子会话,这些子会话可以收集在预训练语料库中。此外,一个潜在的风险是,将对话数据过度整合到LLM中可能会导致副作用:陈述性指令和直接询问被错误地视为对话的开始,从而导致指令的有效性下降。
- 书籍。与其他语料库相比,书籍提供了正式长文本的重要来源,这可能有利于LLM学习语言知识,建立长期依赖关系模型,并生成叙事和连贯的文本。为了获得开源书籍数据,现有研究通常采用Books3和Bookcorpus2数据集,这些数据集可在Pile数据集中获得。
专用文本数据。
专门的数据集有助于提高LLM在下游任务中的特定能力。接下来,我们将介绍三种专门的数据。
- 多语言文本。除了目标语言中的文本外,整合多语言语料库还可以增强多语言理解和生成语言的能力。例如,BLOOM和PaLM在其预训练语料库中分别策划了涵盖46种和122种语言的多语言数据。这些模型在多语言任务(如翻译、多语言摘要和多语言问答)中表现出了令人印象深刻的性能,并实现了与在目标语言的语料库上进行微调的最先进的模型相当或优越的性能。
- 科学文本。科学出版物的不断增长见证了人类对科学的探索。为了增强对LLMs科学知识的理解,将科学语料库纳入模型预训练是有用的。通过对大量科学文本进行预训练,LLM可以在科学和推理任务中取得令人印象深刻的表现。为了构建科学语料库,现有的工作主要是收集arXiv论文、科学教科书、数学网页和其他相关的科学资源。由于科学领域中数据的复杂性,如数学符号和蛋白质序列,通常需要特定的标记化和预处理技术来将这些不同格式的数据转换为可以由语言模型处理的统一形式。
- 代码。程序合成在研究界得到了广泛的研究,尤其是在代码上训练的PLM的使用。然而,这些PLM(例如,GPT-J)生成高质量和准确的程序仍然具有挑战性。最近的研究发现,在庞大的代码语料库上训练LLM可以显著提高合成程序的质量。生成的程序可以成功通过专家设计的单元测试用例或解决竞争性编程问题。通常,两种类型的代码语料库通常用于预训练LLM。第一个来源来自编程问答社区,如Stack Exchange。第二个来源来自公共软件存储库,如GitHub,其中收集代码数据(包括注释和文档字符串)以供使用。与自然语言文本相比,代码采用编程语言的格式,对应于长依赖关系和精确的执行逻辑。最近的一项研究还推测,代码训练可能是复杂推理能力(例如,思维链能力)的来源。此外,已经表明,将推理任务格式化为代码可以帮助LLM生成更准确的结果。
4.1.2 数据预处理
在收集了大量文本数据后,对数据进行预处理以构建预训练语料库至关重要,尤其是去除噪声、冗余、无关和潜在的有毒数据,这些数据可能会在很大程度上影响LLM的容量和性能。在这一部分中,我们回顾了详细的数据预处理策略,以提高收集数据的质量。LLM预处理预训练数据的典型流程如图3所示。
质量过滤。
为了从收集的语料库中去除低质量的数据,现有的工作通常采用两种方法:(1)基于分类器的方法和(2)基于启发式的方法。前一种方法基于高质量文本训练选择分类器,并利用它来识别和过滤低质量数据。通常,这些方法训练一个二元分类器,将精心策划的数据(例如维基百科页面)作为正实例,将样本候选数据作为负实例,并预测衡量每个数据实例质量的分数。然而,几项研究也发现,基于分类器的方法可能会导致方言、口语和社会方言中高质量文本的无意删除,这可能会导致预训练语料库中的偏见,并减少语料库的多样性。作为第二种方法,一些研究,如BLOOM和Gopher,采用基于启发式的方法,通过一组精心设计的规则来消除低质量的文本,可以总结如下:
- 基于语言的过滤。如果LLM主要用于某些语言的任务,则可以过滤其他语言的文本。
- 基于度量的过滤。关于生成的文本的评估度量,例如困惑,可以用于检测和去除不自然的句子。
- 基于统计的过滤。语料库的统计特征,例如标点符号分布、符号与单词的比例和句子长度,可以用来测量文本质量并过滤低质量数据。
- 基于关键字的过滤。根据特定的关键词集,可以识别并删除文本中嘈杂或无用的元素,如HTML标签、超链接、样板和冒犯性单词。

重复数据消除。
现有工作发现,语料库中的重复数据会降低语言模型的多样性,这可能导致训练过程变得不稳定,从而影响模型性能。因此,有必要对预训练语料库进行去重处理。特别地,重复数据消除可以以不同的粒度执行,包括句子级别、文档级别和数据集级别的重复数据消除。首先,应该删除包含重复单词和短语的低质量句子,因为它们可能会在语言建模中引入重复模式。在文档层面,现有的研究大多依赖于文档之间表面特征的重叠率(例如,单词和n-gram重叠)来检测和删除包含类似内容的重复文档。此外,为了避免数据集污染问题,通过从训练集中删除可能的重复文本,防止训练集和评估集之间的重叠也是至关重要的。已经表明,三个级别的重复数据消除有助于改进LLM的训练,应在实践中联合使用。
隐私补救措施。
大多数预训练文本数据来自网络来源,包括用户生成的涉及敏感或个人信息的内容,这可能会增加隐私泄露的风险。因此,有必要从预训练语料库中去除个人可识别信息(PII)。一种直接有效的方法是采用基于规则的方法,如关键词识别,来检测和删除姓名、地址和电话号码等PII。此外,研究人员还发现,LLM在隐私攻击下的脆弱性可归因于预训练语料库中存在重复的PII数据。因此,重复数据消除也可以在一定程度上降低隐私风险。
分词。
分词也是数据预处理的关键步骤。它旨在将原始文本分割成单个词元的序列,这些标记随后用作LLM的输入。尽管利用现有的分词是有利的(例如,OPT和GPT-3利用GPT-2的分词),但使用专门为预训练语料库设计的分词可能是非常有益的,尤其是对于由不同域、语言和格式组成的语料库。因此,最近的几个LLM专门为带有句子片段的预训练语料库训练定制的分词。字节级字节对编码(BPE)算法用于确保分词后的信息是无损的。而BPE中的规范化技术,如NFKC,可能会降低分词性能。
4.1.3 预训练数据对LLMs的影响
与小规模的PLM不同,由于对计算资源的巨大需求,多次迭代LLM的预训练通常是不可行的。因此,在训练LLM之前,构建一个准备充分的预训练语料库尤为重要。在这一部分中,我们讨论了预训练语料库的质量和分布如何潜在地影响LLM的性能。
混合来源。
如前所述,来自不同领域或场景的预训练数据具有不同的语言特征或语义知识。通过对来自不同来源的文本数据的混合进行预训练,LLM可以获得广泛的知识范围,并可能表现出强大的泛化能力。当混合不同的来源时,需要仔细设置预训练数据的分布,因为这也可能影响LLM在下游任务中的性能。Gopher对数据分布进行消融实验,以检查混合源对下游任务的影响。LAMBADA数据集的实验结果表明,增加书籍数据的比例可以提高模型从文本中捕获长期依赖关系的能力,增加C4数据集的比例可以改善C4验证数据集的性能。而作为副作用,对某个领域的过多数据进行训练会影响LLM在其他领域的泛化能力。因此,建议研究人员仔细确定来自不同领域的数据在预训练语料库中的比例,以便开发出更好地满足其特定需求的LLM。读者可以参考图2来比较不同LLM的数据源。
预训练数据量。
为了预训练有效的LLM,收集足够的高质量数据以满足LLM的数据量需求是很重要的。现有研究发现,随着LLM中参数规模的增加,还需要更多的数据来训练模型:就模型性能而言,在数据规模方面也观察到与模型规模相似的规模规律。最近的一项研究表明,由于预训练数据不足,许多现有LLM受到次优训练的影响。通过进行广泛的实验,它进一步证明,在给定的计算预算下,以相等的规模增加模型大小和数据大小可以产生更高效的计算模型(即Chinchilla模型)。最近,LLaMA表明,通过更多的数据和更长的训练,较小的模型也可以获得良好的性能。总体而言,建议研究人员更多地关注高质量数据的数量,以充分训练模型,尤其是在缩放模型参数时。
预训练数据的质量。
现有工作表明,在低质量语料库上进行预训练,如噪声、有毒和重复数据,可能会损害模型的性能。为了开发一个性能良好的LLM,至关重要的是要考虑收集的训练数据的数量和质量。最近的研究,如T5、GLaM和Gopher,已经调查了数据质量对下游任务性能的影响。通过比较在过滤和未过滤语料库上训练的模型的性能,他们得出了相同的结论,即在干净的数据上预训练LLM可以提高性能。更具体地说,数据的重复可能导致“双重下降”(指表现最初恶化,随后改善的现象),甚至压垮训练过程。此外,研究表明,重复数据会降低LLM从上下文中复制的能力,这可能会进一步影响LLM在上下文学习中的泛化能力。因此,如[56,59,69]中所建议的,必须小心地将预处理方法纳入预训练语料库中(如第4.1.2节所示),以提高训练过程的稳定性,避免影响模型性能。
4.2 架构
在本节中,我们将回顾LLM的架构设计,即主流架构、预训练目标和详细配置。表3列出了几个具有代表性的LLM的模型卡以及公开的详细信息。

4.2.1 主流架构

由于出色的并行性和容量,Transformer架构已成为开发各种LLM的事实骨干,使语言模型能够扩展到数百或数千亿个参数。通常,现有LLM的主流架构可以大致分为三大类型,即编码器-解码器、因果解码器和前缀解码器,如图4所示。
编码器-解码器体系结构。
vanilla Transformer模型建立在编码器-解码器架构上,该架构由两堆Transformer块组成,分别作为编码器和解码器。编码器采用堆叠的多头自注意层对输入序列进行编码,以生成其潜在表示,而解码器对这些表示进行交叉注意,并自回归生成目标序列。编码器-解码器PLM(例如T5和BART)在各种NLP任务上显示出有效性。到目前为止,只有少量的LLM是基于编码器-解码器架构构建的,例如Flan-T5。我们在第4.2.4节中留下了关于架构选择的详细讨论。
因果解码器体系结构。
因果解码器架构结合了单向注意力掩码,以确保每个输入词元只能关注过去的词元及其自身。通过解码器以相同的方式处理输入和输出词元。作为该体系结构的代表性语言模型,GPT系列模型是基于因果编码器体系结构开发的。特别是,GPT-3成功地证明了该架构的有效性,也展示了LLM惊人的上下文学习能力。有趣的是,GPT-1和GPT-2并没有表现出GPT-3中那样优越的能力,而且扩展似乎在增加该模型架构的模型容量方面发挥着重要作用。到目前为止,因果解码器已被各种现有的LLM广泛采用作为LLM的架构,如OPT、BLOOM和Gopher。注意,接下来讨论的因果解码器和前缀解码器都属于仅解码器架构。而当提到“仅解码器架构”时,除非另有说明,它主要是指现有文献中的因果解码器架构。
前缀解码器体系结构。
前缀解码器架构(也称为非因果解码器)修改了因果解码器的掩码机制,以使能够对前缀词元执行双向关注,并仅对生成的词元执行单向关注。这样,与编码器-解码器架构一样,前缀解码器可以对前缀序列进行双向编码,并逐个自回归预测输出词元,其中在编码和解码期间共享相同的参数。与其从头开始进行预训练,一个实用的建议是不断训练因果解码器,然后将它们转换为前缀解码器,以加速收敛,例如,U-PaLM是从PaLM导出的。现有的基于前缀解码器的代表性LLM包括GLM130B和U-PaLM。
对于这三种类型的架构,我们还可以考虑通过专家混合(MoE)缩放来扩展它们,其中每个输入的神经网络权重的子集被稀疏激活,例如,Switch Transformer和GLaM。研究表明,通过增加专家数量或总参数大小,可以观察到显著的性能改进。
4.2.2 详细配置
自Transformer推出以来,人们提出了各种改进方案,以增强其训练稳定性、性能和计算效率。在这一部分中,我们将讨论Transformer的四个主要部分的相应配置,包括正则化、位置嵌入、激活函数以及注意力和偏差。为了使这项综述更加独立,我们在表4中列出了这些配置的详细公式。

归一化。
训练不稳定是训练前LLM面临的一个具有挑战性的问题。为了缓解这个问题,层归一化(layer Norm,LN)被广泛应用于Transformer架构中。LN的地位对LLM的性能至关重要。虽然最初的Transformer使用后LN,但大多数LLM使用前LN进行更稳定的训练,尽管性能有所下降。在预先LN的基础上,Sandwich-LN在残差连接之前添加额外的LN,以避免值爆炸。然而,研究发现,Sandwich-LN有时无法稳定LLM的训练,并可能导致训练的崩溃。最近,已经提出了几种先进的归一化技术作为LN的替代方案。在Gopher和Chinchilla中,RMS Norm因其在训练速度和性能方面的优势而被采用。与LN相比,DeepNorm在训练中表现出更好的稳定性保证能力,这已被GLM-130B采用,并进行了后归一化。此外,在嵌入层之后添加额外的LN也可以稳定LLM的训练。然而,它往往会导致性能显著下降,这在最近的几次LLM中已经被删除。
激活函数。
为了获得良好的性能,还需要在前馈网络中正确设置激活函数。在现有的LLM中,GeLU激活被广泛使用。此外,在最新的LLM(例如,PaLM和LaMDA)中,还使用了GLU激活的变体,特别是SwiGLU和GeGLU变体,它们在实践中通常获得更好的性能。然而,与GeLU相比,它们在前馈网络中需要额外的参数(约50%)。
位置嵌入。
由于Transformer中的自注意模块是置换等变的,因此使用位置嵌入来注入用于建模序列的绝对或相对位置信息。vanilla Transformer中有两种绝对位置嵌入变体,即正弦和学习位置嵌入,后者通常用于LLM。与绝对位置嵌入不同,相对位置编码根据键和查询之间的偏移生成嵌入,因此它可以在比训练期间看到的序列更长的序列上执行良好,即外推。ALiBi使用基于键和查询之间距离的惩罚来偏移注意力得分。实验结果表明,与其他位置嵌入相比,它具有更好的零样本泛化能力和更强的外推能力。此外,通过基于绝对位置设置特定的旋转矩阵,RoPE中的键和查询之间的分数可以用相对位置信息计算,这对长序列建模很有用。因此,RoPE已在几个最新的LLM中被广泛采用。
注意力和偏差。
除了原始Transformer中的完全自注意之外,GPT-3中采用了计算复杂度较低的稀疏注意(即因子化注意)。为了有效和高效地对较长序列进行建模,已经通过引入特殊注意力模式或考虑GPU内存访问(即FlashAttention)进行了更多尝试。此外,在最初的Transformer之后,大多数LLM保留了每个密集核和层范数中的偏差。然而,在PaLM和Galactica中,消除了偏差。这表明,没有偏差可以提高LLM的训练稳定性。
为了将所有这些讨论放在一起,我们总结了现有文献中关于详细配置的建议。为了增强泛化能力和训练稳定性,建议选择预RMS范数进行层归一化,并选择SwiGLU或GeGLU作为激活函数。然而,LN可能不会在嵌入层之后立即使用,这可能会导致性能下降。此外,对于位置嵌入,RoPE或ALiBi是更好的选择,因为它在长序列上表现更好。
4.2.3 预训练任务
预训练在将大规模语料库中的一般知识编码为大规模模型参数方面发挥着关键作用。对于LLM的训练,有两个常用的预训练任务,即语言建模和去噪自动编码。
语言建模。
语言建模任务(LM)是预训练仅解码器LLM的最常用目标,例如GPT3和PaLM。给定标记序列 x = { x 1 , ⋯ , x n } x=\{x_1,\cdots,x_n\} x={x1,⋯,xn},LM任务旨在基于序列中前面的词元 x < i x_{
L L M ( x ) = ∑ i = 1 n log P ( x i ∣ x < i ) . \begin{gather} \mathcal{L}_{LM}(x)=\sum^n_{i=1}\log P(x_i|x_{
由于大多数语言任务都可以被视为基于输入的预测问题,因此这些仅解码器的LLM可能有利于隐含地学习如何以统一的LM方式完成这些任务。一些研究还表明,通过自回归预测下一个词元,仅解码器的LLM可以自然地迁移到某些任务,而无需微调。LM的一个重要变体是前缀语言建模任务,该任务是为使用前缀解码器架构预训练模型而设计的。随机选择的前缀内的词语元将不会用于计算前缀语言建模的损失。在预训练过程中看到的词元数量相同的情况下,前缀语言建模的性能略低于语言建模,因为序列中用于模型预训练的词元较少。
去噪自动编码。
除了传统的LM,去噪自动编码任务(DAE)也被广泛用于预训练语言模型。DAE任务的输入 x \ x ~ x_{\backslash\tilde x} x\x~是带有随机替换跨度的损坏文本。然后,对语言模型进行训练以恢复替换的词元 x ~ \tilde x x~。形式上,DAE的训练目标表示如下:
L D A E ( x ) = log P ( x ~ ∣ x \ x ~ ) . \begin{gather} \mathcal{L}_{DAE}(x)=\log P(\tilde x|x_{\backslash\tilde x}). \end{gather} LDAE(x)=logP(x~∣x\x~).
但是,DAE任务在实现上似乎比LM任务更复杂。因此,它还没有被广泛用于预训练大型语言模型。将DAE作为训练前目标的现有LLM包括T5和GLM-130B。这些模型主要用于以自回归的方式恢复替换的跨度。
4.2.4 总结与讨论
架构和预训练任务的选择可能会导致LLM产生不同的归纳偏差,这将导致不同的模型能力。在这一部分中,我们总结了现有文献中关于这一问题的一些重要发现或讨论。
- 通过对LM目标进行预训练,因果解码器体系结构似乎可以实现更优越的零样本和小样本泛化能力。现有研究表明,在没有多任务微调的情况下,因果解码器比其他架构具有更好的零样本性能。GPT-3的成功表明,大型因果解码器模型可以成为一个很好的小样本学习器。此外,第5节中讨论的指令调整和对齐调整已被证明可以进一步增强大型因果解码器模型的能力。
- 在因果解码器中已广泛观察到缩放定律。通过缩放模型大小、数据集大小和总计算量,可以显著提高因果解码器的性能。因此,通过缩放来增加因果解码器的模型容量已成为一种重要的策略。然而,对编码器-解码器模型的更详细研究仍然缺乏,需要更多的努力来大规模研究编码器-解码器的性能。
需要对架构和预训练目标的讨论进行更多的研究,以分析架构和预训练任务的选择如何影响LLM的容量,特别是对于编码器-解码器架构。除了主要架构外,LLM的详细配置也值得注意,第4.2.2节对此进行了讨论。
4.3 模型训练
在这一部分中,我们回顾了训练LLM的重要设置、技术或技巧。
4.3.1 优化设置
对于LLM的参数优化,我们提供了批量训练、学习率、优化器和训练稳定性的常用设置。
批量训练。
对于语言模型预训练,现有工作通常将批量大小设置为很大(例如,8196个示例或16M个词元),以提高训练稳定性和吞吐量。对于GPT-3和PaLM等LLM,他们引入了一种新策略,在训练过程中动态增加批量大小,最终达到百万规模。具体而言,GPT-3的批量大小正在从32K词元逐渐增加到3.2M词元。经验结果表明,批量大小的动态调度可以有效地稳定LLM的训练过程。
学习率。
现有的LLM通常采用类似的学习率计划,在预训练期间采用warm-up和衰减策略。具体而言,在最初0.1%至0.5%的训练步骤中,采用线性warm-up计划将学习率逐渐提高到最大值,该最大值范围约为 5 × 1 0 − 5 5\times10^{-5} 5×10−5至 1 × 1 0 − 4 1\times10^{-4} 1×10−4(例如,GPT-3为 6 × 1 0 − 5 6\times10^{-5} 6×10−5)。然后,在随后的步骤中采用余弦衰减策略,逐渐将学习率降低到其最大值的大约10%,直到训练损失收敛。
优化器。
Adam优化器和AdamW优化器被广泛用于训练LLM(例如,GPT3),其基于基于一阶梯度的优化的低阶矩的自适应估计。通常,其超参数设置如下: β 1 = 0.9 , β 2 = 0.95 \beta_1=0.9,\beta_2=0.95 β1=0.9,β2=0.95和 ϵ = 1 0 − 8 \epsilon=10^{-8} ϵ=10−8。同时,Adafactor优化器也被用于训练LLM(例如,PaLM和T5),这是Adam优化器的一个变体,专门设计用于在训练期间节省GPU内存。Adafactor优化器的超参数设置为: β 1 = 0.9 \beta_1=0.9 β1=0.9和 β 2 = 1.0 − k − 0.8 \beta_2=1.0-k^{-0.8} β2=1.0−k−0.8,其中 k k k表示训练步骤的数量。
稳定训练。
在LLM的预训练过程中,它经常会遇到训练不稳定的问题,这可能会导致模型崩溃。为了解决这个问题,权重衰减和梯度截断已被广泛使用,现有研究通常将梯度截断的阈值设置为1.0,将权重衰减率设置为0.1。然而,随着LLM的扩展,训练损失峰值也更有可能发生,导致训练不稳定。为了缓解这个问题,PaLM和OPT使用了一种简单的策略,该策略在尖峰发生之前从较早的检查点重新启动训练过程,并跳过可能导致问题的数据。此外,GLM发现嵌入层的异常梯度通常会导致尖峰,并提出缩小嵌入层梯度以缓解这种情况。

4.3.2 可扩展训练技术
随着模型和数据大小的增加,在有限的计算资源下有效地训练LLM变得具有挑战性。特别是,需要解决两个主要技术问题,即提高训练吞吐量和将更大的模型加载到GPU内存中。在这一部分中,我们回顾了现有工作中广泛使用的几种方法来解决上述两个挑战,即3D并行、ZeRO和混合精度训练,并就如何利用它们进行训练提出了一般性建议。
3D并行。
3D并行实际上是三种常用的并行训练技术的组合,即数据并行、流水线并行和张量并行。接下来我们将介绍三种并行训练技术。
- 数据并行性。数据并行是提高训练吞吐量的最基本方法之一。它在多个GPU中复制模型参数和优化器状态,然后将整个训练语料库分发到这些GPU中。这样,每个GPU只需要为其处理分配的数据,并执行前向和后向传播以获得梯度。不同GPU上计算的梯度将被进一步聚合以获得整个批次的梯度,用于更新所有GPU中的模型。通过这种方式,由于梯度的计算是在不同的GPU上独立执行的,因此数据并行机制是高度可扩展的,从而实现了增加GPU数量以提高训练吞吐量的方式。此外,该技术实现简单,现有大多数流行的深度学习库已经实现了数据并行,如TensorFlow和PyTorch。
- 流水线并行。流水线并行旨在将LLM的不同层分布到多个GPU中。特别是,在Transformer模型的情况下,流水线并行性将连续层加载到同一GPU上,以降低在GPU之间传输计算出的隐藏状态或梯度的成本。然而,流水线并行的朴素实现可能会导致较低的GPU利用率,因为每个GPU都必须等待前一个GPU完成计算,从而导致不必要的气泡开销成本。为了减少流水线并行性中的这些气泡,GPipe和PipeDream提出了填充多批数据和异步梯度更新的技术,以提高流水线效率。
- 张量并行。张量并行也是一种常用的技术,旨在分解LLM以进行多GPU加载。与流水线并行不同,张量并行侧重于分解LLM的张量(参数矩阵)。对于LLM中的矩阵乘法运算 Y = X A Y=XA Y=XA,参数矩阵 A A A可以按列划分为两个子矩阵 A 1 A_1 A1和 A 2 A_2 A2,其可以表示为 Y = [ X A 1 , X A 2 ] Y=[XA_1,XA_2] Y=[XA1,XA2]。通过将矩阵 A 1 A_1 A1和 A 2 A_2 A2放置在不同的GPU上,矩阵乘法运算将在两个GPU上并行调用,并且可以通过跨GPU通信将来自两个GPU的输出组合来获得最终结果。目前,张量并行已经在几个开源库中得到支持,例如Megatron LM,并且可以扩展到更高维张量。此外,Colossal AI还为高维张量实现了张量并行,并提出了序列并行,特别是对序列数据,可以进一步分解Transformer模型的注意力操作。
ZeRO
ZeRO技术由DeepSpeed库提出,主要研究数据并行中的内存冗余问题。如前所述,数据并行性要求每个GPU存储LLM的相同副本,包括模型参数、模型梯度和优化器参数。然而,并非所有上述数据都需要保留在每个GPU上,这将导致内存冗余问题。为了解决这个问题,ZeRO技术的目标是在每个GPU上只保留一小部分数据,而其余数据可以在需要时从其他GPU中检索。具体来说,ZeRO提供了三种解决方案,这取决于数据的三个部分的存储方式,即优化器状态分区、梯度分区和参数分区。经验结果表明,前两种解决方案没有增加通信开销,第三种解决方案增加了约50%的通信开销,但节省了与GPU数量成比例的内存。PyTorch实现了与ZeRO类似的技术,称为FSDP。
混合精度训练。
在以前的PLM(例如,BERT)中,32位浮点数,也称为FP32,主要用于预训练。近年来,为了预训练超大的语言模型,一些研究已经开始使用16位浮点数(FP16),这减少了内存使用和通信开销。此外,由于流行的NVIDIA GPU(例如A100)的FP16计算单元数量是FP32的两倍,因此可以进一步提高FP16的计算效率。然而,现有工作发现,FP16可能会导致计算精度的损失,从而影响最终的模型性能。为了缓解这种情况,一种称为脑浮点(BF16)的替代方案被用于训练,它比FP16分配更多的指数位和更少的有效位。对于预训练,BF16在表示精度方面通常比FP16表现得更好。
整体训练建议。
在实践中,上述训练技术,特别是3D并行性,经常被联合使用,以提高训练吞吐量和大模型加载。例如,研究人员结合了8路数据并行、4路张量并行和12路流水线并行,使BLOOM能够在384个A100 GPU上进行训练。目前,DeepSpeed、Colossal AI和Alpa等开源库可以很好地支持这三种并行训练方法。为了减少内存冗余,还可以使用ZeRO、FSDP和激活重新计算技术来训练LLM,这些技术已经集成到DeepSpeed、PyTorch和Megatron LM中。此外,混合精度训练技术(如BF16)也可以用于提高训练效率和减少GPU内存使用,同时需要硬件(如A100 GPU)的必要支持。由于训练大型模型是一个耗时的过程,因此预测模型性能和在早期检测异常问题是非常有用的。
为此,GPT-4最近引入了一种新机制,称为建立在深度学习堆栈上的可预测缩放,能够用更小的模型预测大型模型的性能,这可能对开发LLM非常有用。在实践中,可以进一步利用主流深度学习框架的辅助训练技术。例如,PyTorch支持数据并行训练算法FSDP(即,完全分片数据并行),如果需要,它允许将训练计算部分卸载到CPU。除了上述训练策略外,提高LLM的推理速度也很重要。通常,量化技术被广泛用于减少推理阶段LLM的时间和空间成本。在模型性能有所损失的情况下,量化语言模型的模型大小较小,可以实现更快的推理速度。对于模型量化,一个流行的选择是INT8量化。此外,一些研究工作试图开发更积极的INT4量化方法。最近,一些公开可用的语言模型的量化模型副本已经在hugging face上发布,包括BLOOM、GPT-J和ChatGLM。
5 LLMs的自适应调整
经过预训练,LLM可以获得解决各种任务的一般能力。然而,越来越多的研究表明,LLM的能力可以根据具体目标进行进一步调整。在本节中,我们将介绍两种主要的方法来调整预先训练的LLM,即指令调整和对齐调整。前一种方法主要旨在增强(或解锁)LLM的能力,而后一种方法旨在使LLM的行为与人类的价值观或偏好保持一致。此外,我们还将讨论用于快速模型自适应的有效调整。在下文中,我们将详细介绍这三个部分。
5.1 指令调整
本质上,指令调整是在自然语言形式的格式化实例集合上微调预训练的LLM的方法,这与监督微调和多任务提示训练高度相关。为了执行指令调优,我们首先需要收集或构造指令格式的实例。然后,我们使用这些格式化的实例以监督学习的方式对LLM进行微调(例如,使用序列到序列损失进行训练)。在指令调整后,LLM可以表现出对看不见的任务进行概括的卓越能力,即使在多语言环境中也是如此。
最近的一项综述对指令调整的研究进行了系统综述。相比之下,我们主要关注指令调整对LLM的影响,并提供了详细的指导方针或策略,例如收集和调整。此外,我们还讨论了使用指令调整来满足用户的真实需求,这在现有的LLM中得到了广泛应用,例如InstructGPT和GPT-4。
5.1.1 格式化实例构造
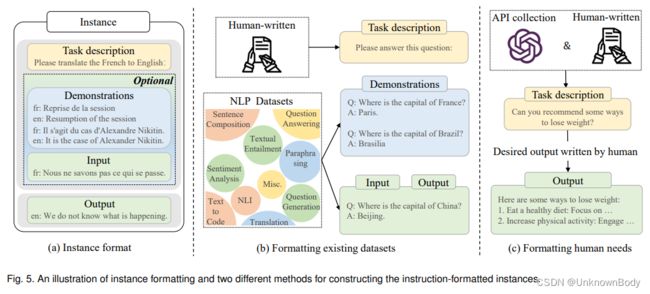
通常,指令格式的实例由任务描述(称为指令)、输入输出对和少量示例(可选)组成。作为重要的公共资源,现有研究已经发布了大量以自然语言格式化的标记数据(见表6中的可用资源列表)。接下来,我们将介绍构造格式化实例的两种主要方法(见图5),然后讨论实例构造的几个关键因素。
格式化现有数据集。
在提出指令调整之前,几项早期研究收集了来自各种任务(例如,文本摘要、文本分类和翻译)的实例,以创建有监督的多任务训练数据集。作为指令调优实例的主要来源,使用自然语言任务描述来格式化这些多任务训练数据集是很方便的。具体而言,最近的工作用人工编写的任务描述扩充了标记的数据集,这指导LLM通过解释任务目标来理解任务。例如,在图5(b)中,为问答任务中的每个示例添加了任务描述“Please answer this question”。在指令调整之后,LLM可以通过遵循其任务描述,很好地推广到其他看不见的任务。特别是,已经表明,指令是LLM任务泛化能力的关键因素:通过在删除任务描述的标记数据集上微调模型,会导致模型性能急剧下降。为了更好地生成用于指令调整的标记实例,已经提出了一个众包平台PromptSource来有效地创建、共享和验证不同数据集的任务描述。为了丰富训练实例,几项研究还试图用专门设计的任务描述来反转现有实例的输入输出对,以进行教学调整。例如,给定一个问答对,我们可以通过预测问题条件答案来创建一个新的实例(例如,“请根据答案生成问题:”)。此外,一些工作还利用启发式任务模板将大量未标记的文本转换为标记的实例。
格式化人类需求。
尽管大量的训练实例都是用指令格式化的,但它们主要来自公共NLP数据集,要么缺乏指令多样性,要么与真实的人类需求不匹配。为了克服这个问题,InstructGPT建议将真实用户提交给OpenAI API的查询作为任务描述。用户查询是用自然语言表达的,特别适合于激发LLM的指令遵循能力。此外,为了丰富任务的多样性,人类标注者还被要求为现实生活中的任务编写指令,包括开放式生成、开放式问答、头脑风暴和聊天。然后,他们让另一组标记员直接回答这些指令作为输出。最后,他们将一条指令(即收集的用户查询)和预期输出(即人工编写的答案)配对作为训练实例。请注意,InstructionGPT还使用这些以自然语言格式化的真实世界任务进行对齐调整(在第5.2节中讨论)。此外,GPT-4设计了潜在的高风险指令,并指导模型通过出于安全考虑的监督微调来拒绝这些指令。此外,为了减轻人工注释的负担,还提出了几种半自动方法,通过将现有实例输入LLM来构建实例,以生成不同的任务描述和实例。
实例构建的关键因素。
指令实例的质量对模型的性能有着重要的影响。在这里,我们讨论一些基本因素,例如实例构建。
- 缩放指令。已经广泛表明,缩放任务数量可以在很大程度上增强LLM的泛化能力。随着任务数量的增加,模型性能最初呈现出持续增长的模式,而当增益达到一定水平时,增益变得可以忽略不计。一个合理的推测是,一定数量的代表性任务可以提供相对足够的知识,增加更多的任务可能不会带来额外的收益。此外,在长度、结构和创造力等几个方面增强任务描述的多样性也是有益的。至于每个任务的实例数量,已经发现少量的实例通常会使模型的泛化性能饱和。然而,将某些任务的实例数量增加到大量(例如几百个)可能会导致过拟合问题,并损害模型性能。
- 格式化设计。作为一个重要因素,自然语言格式的设计也高度影响LLM的泛化性能。通常,我们可以将任务描述和可选示例添加到现有数据集的输入输出对中,其中任务描述是LLM理解任务的最关键部分。此外,通过使用适当数量的样本作为示例,它可以带来实质性的改进,这也减轻了模型对指令工程的敏感性。然而,将其他组成部分(例如,要避免的事情、原因和建议)纳入指令可能会对LLM的性能产生微不足道甚至不利的影响。最近,为了引出LLM的逐步推理能力,一些工作建议为一些推理数据集包括思想链(CoT)示例,例如算术推理。已经表明,使用CoT和非CoT示例对LLM进行微调可以在各种推理任务中获得良好的性能,包括那些需要多跳推理能力的任务(例如,常识性问答和算术推理),以及那些不需要这种推理方式的任务(例如,情绪分析和提取式问答)。
总之,指令的多样性似乎比实例的数量更重要,因为性能良好的InstructionGPT和Alpaca使用的指令(或实例)比Flan系列LLM更少但更多样。此外,邀请标注人员编写人工需求任务比使用特定于数据集的任务更有用。尽管如此,它仍然缺乏注释人类需求实例的指导方针,使得任务组合在某种程度上具有启发性。为了减少人工操作,我们可以重用现有的格式化数据集(表6),也可以使用现有的LLM自动构建指令。
5.1.2 指令调整策略
与预训练不同,指令调整通常更有效,因为只有中等数量的实例用于训练。由于指令调整可以被视为一个有监督的训练过程,其优化在几个方面与预训练不同,例如训练目标(即序列到序列的损失)和优化配置(例如较小的批量大小和学习率),这些在实践中需要特别注意。除了这些优化配置之外,指令调优还需要考虑两个重要方面:
平衡数据分布。
由于指令调整涉及不同任务的混合,因此在微调过程中平衡不同任务的比例很重要。一种广泛使用的方法是示例比例混合策略,即组合所有数据集,并从混合的数据集中平均采样每个实例。此外,根据最近的研究结果,增加高质量集合(例如,FLAN和P3)的采样率通常可以提高性能。然而,通常设置最大上限来控制数据集在指令调整过程中可以包含的最大示例数,这是为了防止较大的数据集压倒整个分布。在实践中,根据不同的数据集,最大上限通常设置为数千或数万。
将指令调整与预训练相结合。
为了使调整过程更加有效和稳定,OPT-IML在指令调整期间合并了预训练数据,这可以被视为模型调整的正则化。此外,一些研究试图使用多任务学习,使用预训练数据(即纯文本)和指令调整数据(即格式化数据集)的混合,从头开始训练模型,而不是使用单独的两阶段过程(预训练,然后是指令调整)。具体而言,GLM-130B和Galactica将指令格式的数据集作为预训练语料库的一小部分集成到预训练LLM中,这可能同时实现预训练和指令调整的优势。
5.1.3 指令调整的效果
在这一部分中,我们从两个主要方面讨论了指令调整对LLM的影响。
性能改进。
尽管在中等数量的实例上进行了调整,但指令调整已成为提高或解锁LLM能力的重要方式。最近的研究对多个尺度(从77M到540B)的语言模型进行了实验,表明不同尺度的模型都可以从指令调整中受益,随着参数尺度的增加,性能得到改善。此外,具有指令调整的较小模型甚至可以比没有微调的较大模型执行得更好。除了模型规模之外,指令调整还证明了各种模型架构、预训练目标和模型自适应方法的一致改进。在实践中,指令调整为增强现有语言模型(包括小型PLM)的能力提供了一种通用方法。此外,它也比预训练成本低得多,因为LLM所需的指令数据量明显小于预训练数据。
任务概括。
指令调整鼓励模型理解用于完成任务的自然语言指令。它赋予LLM遵循人类指令执行特定任务而无需示例的能力(通常被认为是一种涌现能力),即使是在看不见的任务上。大量研究已经证实了指令调整的有效性,以在可见和不可见的任务上实现卓越的性能。此外,指令调整已被证明有助于缓解LLM的几个弱点(例如,在没有完成特定任务的情况下重复生成或补充输入),从而提高LLM解决现实世界任务的能力。此外,经过指令调优训练的LLM可以推广到跨语言的相关任务。例如,BLOOMZ-P3是在BLOOM的基础上使用纯英语任务集合P3进行微调的。有趣的是,与BLOOM相比,BLOOMZ-P3在多语言句子完成任务方面可以实现50%以上的改进,这表明指令调整可以帮助LLM从纯英语数据集中获得一般任务技能,并将这些技能转移到其他语言。此外,研究发现,仅使用英语指令可以在多语言任务上产生令人满意的结果,这有助于减少针对特定语言的指令工程的工作量。
5.2 对齐调整
本部分首先介绍了对齐的背景及其定义和标准,然后重点介绍了用于对齐LLM的人类反馈数据的收集,最后讨论了从人类反馈中强化学习用于对齐调整的关键技术。
5.2.1 对齐的背景与标准
背景
LLM在广泛的NLP任务中显示出非凡的能力。然而,这些模型有时可能表现出意想不到的行为,例如编造虚假信息、追求不准确的目标以及产生有害、误导和有偏见的表达。对于LLM,语言建模目标通过单词预测预训练模型参数,同时缺乏对人类价值观或偏好的考虑。为了避免这些意想不到的行为,有人提出了人类对齐,以使LLM的行为符合人类的期望。然而,与最初的预训练和适应调整(例如,指令调整)不同,这种调整需要考虑非常不同的标准(例如,有用性、诚实性和无害性)。已经表明,对齐可能在一定程度上损害LLM的一般能力,这在相关文献中被称为对齐税。
对齐标准。
近年来,人们越来越关注制定多种标准来规范LLM的行为。在这里,我们以三个具有代表性的比对标准(即有用、诚实和无害)为例进行讨论,这些标准在现有文献中已被广泛采用。此外,从不同的角度来看,LLM还有其他对齐标准,包括行为、意图、激励和内部,这些标准与上述三个标准基本相似(或至少具有相似的对齐技术)。根据具体需要修改这三个标准也是可行的,例如,用正确取代诚实或专注于一些特定的标准。接下来,我们将简要解释三个具有代表性的对齐标准:
- 有帮助。为了提供帮助,LLM应该展示一种明确的尝试,以尽可能简洁高效的方式帮助用户解决任务或回答问题。在更高的层面上,当需要进一步澄清时,LLM应表现出通过相关询问获得额外相关信息的能力,并表现出适当的敏感性、洞察力和谨慎性。实现有益行为的一致性对LLM来说是一项挑战,因为很难准确定义和衡量用户的意图。
- 诚实。在基本层面上,一个诚实的LLM应该向用户提供准确的内容,而不是编造信息。此外,LLM在其输出中传达适当程度的不确定性,以避免任何形式的欺骗或虚假信息,这一点至关重要。这需要模型了解其能力和知识水平(例如,“知道未知”)。根据[223]中的讨论,与有益和无害相比,诚实是一个更客观的标准,因此,可以在较少依赖人类努力的情况下发展诚实对齐。
- 无害。为了无害,它要求该模型产生的语言不应具有攻击性或歧视性。尽其所能,该模型应该能够检测到旨在为恶意目的招揽请求的秘密行为。理想情况下,当模型被诱导进行危险行为(例如犯罪)时,LLM应该礼貌地拒绝。尽管如此,哪些行为被认为是有害的,以及个人或社会之间的差异程度在很大程度上取决于谁在使用LLM、提出的问题的类型以及使用LLM的背景(例如时间)。
正如我们所看到的,这些标准是相当主观的,是在人类认知的基础上发展起来的。因此,很难将它们直接表述为LLM的优化目标。在现有的工作中,有许多方法可以在对齐LLM时满足这些标准。一种很有前途的技术是rea teaming,它涉及使用手动或自动手段以对抗性的方式探测LLM,以产生有害的输出,然后更新LLM以防止此类输出。
5.2.2 收集人类反馈
在预训练阶段,LLM使用大规模语料库上的语言建模目标进行训练。然而,它不能考虑人类对LLM输出的主观和定性评估(在本综述中称为人类反馈)。高质量的人类反馈对于使LLM与人类偏好和价值观保持一致非常重要。在这一部分中,我们将讨论如何选择一组人类标签员进行反馈数据收集。
人工标记员选择。
在现有工作中,生成人类反馈数据的主要方法是人类注释。这突出了选择合适的人工标记员的关键作用。为了提供高质量的反馈,人工标记员应该具有合格的教育水平和出色的英语熟练程度。例如,Sparrow要求人工标记员必须是以英语为母语的英国人,并且至少获得了本科学历。此外,在[224]中,约有一半的高优先级任务的人工标记员是从美国亚马逊机械土耳其公司招聘的,具有硕士资格。即便如此,几项研究[112226]发现,研究人员和人工标记员的意图之间仍然存在不匹配,这可能导致低质量的人类反馈,并导致LLM产生意想不到的输出。为了解决这个问题,InstructionGPT通过评估人工标记员和研究人员之间的协议,进一步进行了筛选过程来过滤标记员。具体来说,研究人员首先标记少量数据,然后测量他们与人工标记员之间的一致性。将选择协议最高的标记员进行后续的标注工作。在其他一些工作中,“超级评分者”被用来确保人类反馈的高质量。研究人员评估人工标记员的性能,并选择一组性能良好的人工标记员(例如,高一致性)作为超级评分机。在随后的研究中,超级评分者将优先与研究人员合作。当人工标记员对LLM的输出进行注释时,有助于指定详细的说明,并为人工标记员提供即时指导,这可以进一步规范标记员的注释。
人类反馈收集。
在现有的工作中,主要有三种方法来收集人工标记员的反馈和偏好数据。
- 基于排名的方法。在早期的工作中,人工标记员通常以粗粒度的方式(即仅选择最佳)评估模型生成的输出,而不考虑更细粒度的对齐标准。尽管如此,不同的标注者可能对最佳候选输出的选择持有不同的意见,并且这种方法忽略了未选择的样本,这可能导致不准确或不完整的人类反馈。为了解决这个问题,随后的研究引入了Elo评级系统,通过比较候选输出来推导偏好排名。输出的排序作为训练信号,引导模型更喜欢某些输出而不是其他输出,从而产生更可靠、更安全的输出。
- 基于问题的方法。此外,人工标记员可以通过回答研究人员设计的某些问题来提供更详细的反馈,包括对齐标准以及LLM的额外约束。特别地,在WebGPT中,为了帮助模型过滤和利用检索到的文档中的相关信息,需要人工标注人员回答具有多个选项的问题,即检索到的文件是否有助于回答给定的输入。
- 基于规则的方法。此外,许多研究开发了基于规则的方法来提供更详细的人类反馈。作为一个典型的案例,Sparrow不仅选择了标记者认为最好的响应,而且还使用了一系列规则来测试模型生成的响应是否符合有用、正确和无害的对齐标准。通过这种方式,可以获得两种人类反馈数据:(1)通过成对比较模型生成的输出的质量来获得响应偏好反馈,以及(2)通过收集来自人工标记员的评估(即,指示生成的输出在多大程度上违反了规则的分数)来获得规则违反反馈。此外,GPT-4使用一组零样本分类器(基于GPT-4本身)作为基于规则的奖励模型,可以自动确定模型生成的输出是否违反了一组人工编写的规则。
在下文中,我们将重点介绍一种众所周知的技术,即来自人类反馈的强化学习(RLHF),该技术已被广泛用于最近强大的LLM,如ChatGPT。如下文所述,第5.2.1节中引入的对齐标准可以通过学习LLM对用户查询的响应的人类反馈来实现。
5.2.3 从人类反馈中增强学习
为了使LLM与人类价值观保持一致,已经提出了从人类反馈中强化学习(RLHF),以利用收集的人类反馈数据对LLM进行微调,这有助于改进一致标准(例如,有用性、诚实性和无害性)。RLHF采用强化学习(RL)算法(例如,近端策略优化(PPO)),通过学习奖励模型使LLM适应人类反馈。这种方法将人类纳入训练循环,以开发良好对齐的LLM,如InstructGPT所示。
RLHF系统。
RLHF系统主要包括三个关键组件:预训练的待对齐LM、从人类反馈中学习的奖励模型和训练LM的RL算法。具体地说,预训练的LM通常是用现有的预训练LM参数初始化的生成模型。例如,OpenAI使用175B GPT-3作为其第一个流行的RLHF模型InstructGPT,DeepMind使用2800亿参数模型Gopher作为其GopherCite模型。此外,奖励模型(RM)通常以标量值的形式提供反映人类对LM生成的文本的偏好的(学习的)引导信号。奖励模型可以采取两种形式:微调的LM或使用人类偏好数据从头训练的LM。现有工作通常采用具有不同于对齐LM的参数尺度的奖励模型。例如,OpenAI分别使用6B GPT-3和DeepMind使用7B Gopher作为奖励模型。最后,为了使用来自奖励模型的信号来优化预训练的LM,设计了一种用于大规模模型调整的特定RL算法。具体而言,近端策略优化(PPO)是现有工作中广泛使用的RL算法。
RLHF的关键步骤。

图6说明了RLHF的整体三步过程,如下所述。
- 监督微调。为了使LM最初执行所需的行为,它通常需要收集一个监督数据集,该数据集包含用于微调LM的输入提示(指令)和所需输出。这些提示和输出可以由人工标注员为某些特定任务编写,同时确保任务的多样性。例如,InstructGPT要求人工标记员为一些生成性任务(如开放式QA、头脑风暴、聊天和重写)编写提示(例如,“列出如何重新获得对我的职业热情的五个想法”)和所需输出。请注意,在特定设置或场景中,第一步是可选的。
- 奖励模型训练。第二步是使用人类反馈数据来训练RM。具体而言,我们使用LM使用采样提示(来自监督数据集或人工生成的提示)作为输入来生成一定数量的输出文本。然后,我们邀请人工标记员来注释对这些配对的偏好。注释过程可以以多种形式进行,一种常见的方法是通过对生成的候选文本进行排序来进行注释,这可以减少注释者之间的不一致性。然后,对RM进行训练,以预测人类偏好的输出。在InstructGPT中,标记员将模型生成的输出从最好到最差进行排序,并训练RM(即6B GPT-3)来预测排序。
- RL微调。在这个步骤中,将LM的对齐(即微调)形式化为RL问题。在这种设置中,预先训练的LM充当策略,该策略将提示作为输入并返回输出文本,其动作空间是词汇表,状态是当前生成的词元序列,并且奖励由RM提供。为了避免与初始(调整前)LM显著偏离,惩罚项通常被纳入奖励函数中。例如,InstructGPT使用PPO算法针对RM优化LM。对于每个输入提示,InstructGPT计算当前LM和初始LM的生成结果之间的KL偏差作为惩罚。要注意的是,第二步和最后一步可以多次迭代,以便更好地对准LLM。
5.3 有效调整
在上文中,我们讨论了根据特定目标调整LLM的指令调整和对齐调整方法。由于LLM由大量的模型参数组成,因此执行全参数调整的成本很高。在本节中,我们将讨论如何对LLM进行有效的调优。我们首先回顾了Transformer语言模型的几种具有代表性的参数有效微调方法,然后总结了现有的参数有效调优LLM工作。
5.3.1 参数高效的微调方法
在现有文献中,参数有效微调一直是一个重要的主题,旨在减少可训练参数的数量,同时尽可能保持良好的性能。在接下来的内容中,我们简要回顾了Transformer语言模型的四种参数高效微调方法,包括适配器调优、前缀调优、提示调优和LoRA。
适配器调整。
适配器调整将小型神经网络模块(称为适配器)纳入Transformer模型。为了实现适配器模块,在[233234]中提出了一种瓶颈架构,该架构首先将原始特征向量压缩到较小的维度(然后进行非线性变换),然后将其恢复到原始维度。适配器模块将集成到每个Transformer层中,通常在Transformer层的两个核心部分(即注意力层和前馈层)中的每一个之后使用串行插入。或者,并行适配器也可以用于Transformer层,其中它相应地将两个适配器模块与注意力层和前馈层并行放置。在微调过程中,适配器模块将根据特定的任务目标进行优化,而原始语言模型的参数在此过程中被冻结。通过这种方式,我们可以有效地减少微调过程中可训练参数的数量。
前缀调整。
前缀调整为语言模型中的每个Transformer层预先准备一系列前缀,这些前缀是一组可训练的连续向量。这些前缀向量是特定于任务的,可以被视为虚拟词元嵌入。为了优化前缀向量,已经提出了一种重新参数化技巧,通过学习将较小矩阵映射到前缀的参数矩阵的MLP函数,而不是直接优化前缀。事实证明,这个技巧对稳定的训练是有用的。优化后,映射函数将被丢弃,只保留导出的前缀向量,以增强特定任务的性能。由于只训练前缀参数,因此可以实现参数有效的模型优化。与前缀调优类似,ptuning v2将逐层提示向量合并到Transformer架构中,专门用于自然语言理解,该架构还利用多任务学习来联合优化共享提示。它已被证明有助于提高自然语言理解任务中不同参数尺度的模型性能。
提示调整。
与前缀调优不同,提示调优主要关注在输入层合并可训练的提示向量。基于离散提示方法,它通过包括一组软提示词元(以自由形式或前缀形式)来增强输入文本,然后采用提示增强输入来解决特定的下游任务。在实现中,将特定于任务的提示嵌入和输入文本嵌入相结合,然后将其输入到语言模型中。P-tuning提出了一种结合上下文、提示和目标标记的自由形式,可以应用于自然语言理解和生成的架构。他们通过双向LSTM进一步学习软提示词元的表示。另一种有代表性的方法命名为提示调优,直接在输入前添加前缀提示。在训练过程中,根据特定任务的监督,只学习提示嵌入。然而,由于该方法在输入层仅包括少量可训练参数,因此发现性能高度依赖于底层语言模型的模型容量。
低秩自适应(LoRA)。
LoRA在每个密集层施加用于近似更新矩阵的低秩约束,以减少用于适应下游任务的可训练参数。考虑优化参数矩阵 W W W的情况。更新过程可以用一般形式写成: W ← W + Δ W W\leftarrow W+\Delta W W←W+ΔW。LoRA的基本思想是冻结原始矩阵 W ∈ R m × n W\in\mathbb{R}^{m\times n} W∈Rm×n,同时用低秩分解矩阵逼近参数更新 Δ W \Delta W ΔW,即 Δ W = A ⋅ B ⊤ \Delta W=A\cdot B^\top ΔW=A⋅B⊤,其中 A ∈ R m × k A\in\mathbb{R}^{m\times k} A∈Rm×k和 B ∈ R n × k B\in\mathbb{R}^{n\times k} B∈Rn×k是任务自适应的可训练参数, r ≪ min ( m , n ) r\ll\min(m,n) r≪min(m,n)是降秩。LoRA的主要优点是它可以在很大程度上节省内存和存储使用(例如,VRAM)。此外,只能保留单个大型模型副本,同时保留许多特定于任务的低秩分解矩阵,以适应不同的下游任务。此外,一些研究还讨论了如何以更原则的方法设置秩,例如,基于重要性分数的分配和无搜索的最优秩选择。
除了上述方法之外,还对Transformer语言模型的有效调优进行了广泛的研究。然而,关于高效调优的更全面的讨论超出了本文的范围,可以在有关该主题的相关论文中找到。
5.3.2 LLMs上的参数高效微调
随着LLM的兴起,高效调优因在下游任务中开发更轻量级的自适应方法而引起了越来越多的研究关注。
特别是,LoRA已被广泛应用于开源LLM(如LLaMA和BLOOM),用于参数高效微调。在这些研究尝试中,LLaMA及其变体在参数有效调整方面受到了广泛关注。例如,Alpaca-LoRA已经使用LoRA作为Alpaca的轻量级调优版本(一个微调的7B LLaMA模型,具有52K的人类指令示例)进行了训练。Alpaca-LoRA有多种不同语言或模型大小的探索,可以在收藏页面中找到。此外,LLaMA-Adapter将可学习的提示向量插入到每个Transformer层中,其中提出了零初始化注意力,以通过减轻拟合不足的提示向量的影响来改进训练。此外,他们还将这种方法扩展到多模态环境中,例如视觉问答。
此外,还进行了一项实证研究,以检验不同的调整方法对语言模型的影响。他们在三种开源LLM(即GPT-J(6B)、BLOOM(7.1B)和LLaMA(7B))上比较了四种有效的调整方法,包括串行适配器调整、并行适配器调整和LoRA,以进行评估。基于在六个数学推理数据集上的实验结果,他们表明,这些高效的调优方法在困难任务上的性能低于参考基线GPT-3.5,而在简单任务上的表现相当。总体而言,在这些比较方法中,LoRA表现相对较好,使用的可训练参数明显较少。
作为一个重要的资源,库PEFT(代表参数有效微调)已经在GitHub上发布。它包括几种广泛使用的有效调整方法,包括LoRA/AdaLoRA、前缀调整、P-调整和提示调整。此外,它支持许多语言模型,如GPT-2和LLaMA,还涵盖了几个具有代表性的视觉转换器模型(例如,ViT和Swin-Transformer)。
如第5.3.1节所述,现有文献中提出了大量有效的调整方法。然而,这些方法中的大多数都是在小型的预训练的语言模型上测试的,而不是LLM。到目前为止,在不同的设置或任务下,不同的高效调优方法对大型语言模型的影响仍然缺乏深入的研究。
6 利用
在预训练或适应调整之后,使用LLM的一个主要方法是设计合适的提示策略来解决各种任务。一种典型的提示方法是上下文学习,它以自然语言文本的形式制定任务描述和/或示例。此外,思维链提示可以通过将一系列中间推理步骤引入提示来增强上下文学习。接下来,我们将详细介绍这两种技术。
6.1 上下文学习
作为一种特殊的提示形式,上下文学习(ICL)与GPT-3一起首次提出,它已成为利用LLM的典型方法。
6.1.1 提示形式化

如[55]所述,ICL使用格式化的自然语言提示,包括任务描述和/或一些任务示例作为示例。图7显示了ICL的示意图。首先,从任务描述开始,从任务数据集中选择几个例子作为示例。然后,将它们按特定的顺序组合起来,用专门设计的模板形成自然语言提示。最后,将测试实例附加到示例中,作为LLM生成输出的输入。基于任务示例,LLM可以在没有显式梯度更新的情况下识别并执行新任务。
形式上,设 D k = { f ( x 1 , y 1 ) , ⋯ , f ( x k , y k ) } D_k=\{f(x_1,y_1),\cdots,f(x_k,y_k)\} Dk={f(x1,y1),⋯,f(xk,yk)}表示一组具有 k k k个示例的示例,其中 f ( x k , y k ) f(x_k,y_k) f(xk,yk)是将第 k k k个任务示例转换为自然语言提示的提示函数。给定任务描述 I I I、示例 D k D_k Dk和新的输入查询 x k + 1 x_{k+1} xk+1,从LLM生成的输出 y ^ k + 1 \hat y_{k+1} y^k+1的预测可以公式化如下:
L L M ( I , f ( x 1 , y 1 ) , ⋯ , f ( x k , y k ) , ⏟ d e m o s t r a t i o n s f ( x k + 1 ⏟ i n p u t , _ _ _ ⏟ a n s w e r ) ) → y ^ k + 1 . \begin{gather} LLM(I,\underbrace{f(x_1,y_1),\cdots,f(x_k,y_k),}_{demostrations}f(\underbrace{x_{k+1}}_{input},\underbrace{\_\_\_}_{answer}))\rightarrow\hat y_{k+1}. \end{gather} LLM(I,demostrations f(x1,y1),⋯,f(xk,yk),f(input xk+1,answer ___))→y^k+1.
其中实际答案 y k + 1 y_{k+1} yk+1被保留为待由LLM预测的空白。由于ICL的性能在很大程度上依赖于示例,因此在提示中正确设计示例是一个重要问题。根据公式(6)中的构建过程,我们重点讨论了在提示中格式化示例的三个主要方面,包括如何选择组成示例的示例,使用函数 f ( ⋅ ) f(\cdot) f(⋅)将每个示例格式化为提示,以及以合理的顺序排列示例。
综述论文中对ICL进行了全面的综述,我们建议读者参考它,对该主题进行更全面、详细的讨论。与本次综述相比,我们特别从两个主要方面讨论了将ICL应用于LLM,即示范设计和ICL的底层机制。此外,ICL还与指令调优(在第5.1节中讨论)有着密切的联系,因为两者都使用自然语言来格式化任务或实例。然而,指令调优需要对LLM进行微调以进行自适应,而ICL只提示LLM进行使用。此外,指令调优可以增强LLM执行目标任务的ICL能力,特别是在零样本设置下(仅使用任务描述)。
6.1.2 示例设计
几项研究表明,ICL的有效性受到示例设计的高度影响。在第6.1.1节的讨论之后,我们将从示例选择、格式和顺序三个主要方面介绍ICL的示例设计。
示例选择。
ICL的性能往往与不同的示例有很大的差异,因此选择能够有效利用LLM的ICL能力的示例子集很重要。有两种主要的示例选择方法,即启发式和基于LLM的方法:
- 启发式方法。由于其简单性和低成本,现有工作广泛采用启发式方法来选择示例。一些研究使用基于k-NN的检索器来选择与查询语义相关的示例。但是,它们为每个示例单独执行选择,而不是将示例集作为一个整体进行评估。为了解决这个问题,提出了基于多样性的选择策略,为特定任务选择最具代表性的示例集。此外,在[254]中,在选择示例时同时考虑了相关性和多样性。
- 基于LLM的方法。另一条工作线通过使用LLM来选择示例。例如,LLM可用于根据添加示例后的性能增益直接测量每个示例的信息性。此外,EPR提出了一种两阶段检索方法,该方法首先用无监督方法(例如,BM25)回忆类似的例子,然后使用密集检索器(用LLM标记的正性和负性例子进行训练)对它们进行排序。作为一种替代方法,示例选择的任务可以公式化为RL问题,其中LLM作为奖励函数,为训练策略模型提供反馈。由于LLM在文本注释方面表现良好,最近的一些研究在没有人为干预的情况下将LLM本身用作示例生成器。
总之,如[261]所述,对于上述两种选择方法,ICL中选择的示例应包含关于要解决的任务的足够信息,并与测试查询相关。
示例格式。
选择任务示例后,下一步是将它们集成并格式化为LLM的自然语言提示。一种简单的方法是用相应的输入输出对实例化预定义的模板。为了构建更具信息性的模板,最近的研究考虑添加任务描述或通过思维链提示增强LLM的推理能力。例如,在[208]中,作者收集了一个大规模的数据集,其中包含由人类编写的任务描述。在使用该数据集进行调优后,可以提高可见任务的性能,LLM也可以在一定程度上推广到不可见任务。为了降低注释成本,[219]中提出了一种半自动化方法,即使用由人工编写的任务描述组成的种子集来指导LLM为新任务生成任务描述。由于为不同的任务手动注释示例格式的成本很高,一些工作还研究了如何自动生成高质量的示例格式。作为两种具有代表性的方法,Auto-CoT利用带有零样本提示“让我们一步一步思考”的LLM来生成中间推理步骤,而至少至多提示首先查询LLM以执行问题分解,然后利用LLM根据之前解决的中间答案顺序解决子问题。
示例顺序。
LLM有时会受到近因偏见的影响,即他们倾向于重复接近示例结束的答案。因此,以合理的顺序安排示例(即任务示例)非常重要。早期的工作提出了几种启发式方法来快速找到一个好的顺序。例如,可以根据它们与嵌入空间中查询的相似性直接组织示例:越相似,越接近结尾。此外,全局和局部熵度量可用于对不同的示例顺序进行评分。为了整合更多的任务信息,最近的一些研究提出最小化压缩和传输任务标签所需的代码长度,这受到了信息论的启发。然而,这些方法需要额外的标记数据作为验证集,以评估特定示例订单的性能。为了消除这种需要,作者在[248]中建议对LLM本身的验证数据进行采样。
6.1.3 机制
经过预训练后,LLM可以在不更新的情况下展现出有趣的ICL能力。在下文中,我们讨论了关于LLM的ICL能力的两个关键问题,即“预训练如何影响ICL能力”和“LLM如何在推理过程中执行ICL”。
预训练如何影响ICL?
ICL是在GPT-3中首次提出的,它表明随着模型尺寸的增大,ICL的能力变得更加重要。然而,一些研究表明,小规模的PLM也可以在专门设计的训练任务中表现出强大的ICL能力(例如,学习以任务示例和查询作为输入来预测标签),甚至可能超过更大的模型。这表明训练任务的设计是影响LLM ICL能力的一个重要因素。除了训练任务,最近的研究还调查了ICL和预训练语料库之间的关系。研究表明,ICL的性能在很大程度上取决于预训练语料库的来源,而不是规模。另一项研究对训练数据分布的影响进行了深入分析。他们发现,当训练数据可以聚集到许多不常见的类中,而不是均匀分布时,ICL就会出现。此外,作者在[261]中从理论上解释了ICL是对表现出长程连贯性的文档进行预训练的产物。
LLM如何执行ICL?
在推理阶段,研究人员专注于基于给定的示例来分析ICL能力是如何运行的,因为不涉及显式学习或更新。他们通常从梯度下降的角度进行分析,并将ICL视为隐式微调。在这个框架下,ICL过程可以解释如下:通过前向计算,LLM生成关于示例的元梯度,并通过注意力机制隐式地执行梯度下降。实验还表明,LLM中的某些注意力头能够执行与任务无关的原子操作(例如,复制和前缀匹配),这与ICL能力密切相关。为了进一步探索ICL的工作机制,一些研究将ICL抽象为一个算法学习过程。具体而言,作者在[272]中发现,LLM在预训练期间基本上通过其参数对隐式模型进行编码。通过ICL中提供的示例,LLM可以实现诸如梯度下降之类的学习算法,或者直接计算闭合形式的解以在前向计算期间更新这些模型。在这种解释框架下,已经表明LLM可以有效地学习简单的线性函数,甚至可以使用ICL学习一些复杂的函数,如决策树。
6.2 思维链提示
思想链(CoT)是一种改进的提示策略,用于提高LLM在复杂推理任务上的性能,如算术推理、常识推理和符号推理。CoT没有像ICL中那样简单地用输入输出对构建提示,而是结合了中间推理步骤,这些步骤可以将最终输出引导到提示中。在下文中,我们将详细说明与ICL一起使用CoT,并讨论CoT提示何时以及为什么有效。
6.2.1 带有CoT的上下文学习
通常,CoT可以在两种主要设置中与ICL一起使用,即小样本和零样本设置,如下所述。
小样本CoT。
小样本CoT是ICL的一个特例,它通过结合CoT推理步骤,将每个示例的输入、输出扩充为输入、CoT、输出。为了应用这一策略,我们接下来讨论两个关键问题,即如何设计适当的CoT提示和如何利用生成的CoT来获得最终答案。
- CoT提示设计。设计合适的CoT提示对于有效地激发LLM的复杂推理能力至关重要。作为一种直接的方法,研究表明,使用不同的CoT(即每个问题的多个推理路径)可以有效地提高其性能。另一个直观的想法是,具有更复杂推理路径的提示更有可能引发LLM的推理能力,这可以导致生成正确答案的准确性更高。然而,这两种方法都依赖于带注释的CoT数据集,这限制了它们在实践中的使用。为了克服这一限制,AutoCoT建议利用Zero-shot-CoT(详见下文“零样本CoT”),通过专门提示LLM来生成CoT推理路径,从而消除了手动操作。为了提高性能,Auto CoT将训练集中的问题进一步划分为不同的聚类,然后选择最接近每个聚类质心的问题,这应该很好地代表训练集中的提问。尽管小样本CoT可以被视为ICL的一种特殊提示情况,但与ICL中的标准提示相比,示例的排序似乎影响相对较小:在大多数任务中,重新排序示例只会导致小于2%的性能变化。
- 强化CoT策略。除了丰富上下文信息外,CoT提示还提供了更多的选项来推断给定问题的答案。现有的研究主要集中在生成多条推理路径,并试图在得出的答案中找到共识。例如,在生成CoT和最终答案时,提出了自一致性作为一种新的解码策略。它首先生成几个推理路径,然后对所有答案进行综合(例如,通过在这些路径中投票来选择最一致的答案)。自一致性在很大程度上提高了CoT推理的性能,甚至可以改进一些CoT提示通常比标准提示差的任务(例如,闭书问答和自然语言推理)。此外,作者在[283]中将自一致性策略扩展到更通用的集成框架(扩展到提示上的集成),他们发现不同的推理路径是提高CoT推理性能的关键。上述方法可以很容易地集成到CoT提示中,以提高性能,而无需额外的训练。相反,其他研究训练评分模型来测量生成的推理路径的可靠性,或者在自己生成的推理道路上连续训练LLM来提高性能。
零样本CoT
与小样本CoT不同,零样本CoT不包括提示中的人工注释任务示例。相反,它直接生成推理步骤,然后使用生成的CoT来导出答案。零样本CoT最早在[281]中提出,其中LLM首先由“让我们一步一步思考”提示生成推理步骤,然后由“因此,答案是”提示得出最终答案。他们发现,当模型规模超过一定规模时,这种策略会大大提高性能,但对小规模模型无效,显示出显著的涌现能力模式。为了在更多任务上释放CoT能力,Flan-T5和Flan-PaLM进一步对CoT注释执行指令调优,并且改进了在不可见任务上的零样本性能。
6.2.2 CoT的进一步讨论
在这一部分中,我们讨论了与CoT相关的两个基本问题,即“CoT何时适用于LLM”和“LLM为什么可以执行CoT推理”。
CoT何时为LLM工作?
由于CoT是一种涌现能力,它只对足够大的模型(例如,通常包含10B或更多的参数)有积极影响,但对小模型没有影响。此外,由于CoT通过中间推理步骤增强了标准提示,因此它主要有效地改进了需要逐步推理的任务,如算术推理、常识推理和符号推理。然而,对于不依赖复杂推理的其他任务,它可能显示出比标准提示更差的性能,例如GLUE的MNLI-m/mm、SST-2和QQP。有趣的是,似乎只有当标准提示产生较差的结果时,CoT提示带来的性能增益才会显著。
为什么LLM可以执行CoT推理?
作为第二个问题,我们从以下两个方面讨论了CoT的潜在机制。
- CoT能力的来源。关于CoT能力的来源,人们普遍假设它可以归因于对代码的训练,因为在代码上训练的模型显示出强大的推理能力。直观地说,代码数据通过算法逻辑和编程流程组织得很好,这可能有助于提高LLM的推理性能。然而,这一假设仍然缺乏消融实验的公开报道证据(有和没有代码训练)。此外,指令调优似乎不是获得CoT能力的关键原因,因为经验表明,对非CoT数据的指令调优并不能提高保持的CoT基准的性能。
- 提示组件的效果。CoT提示和标准提示之间的主要区别是在最终答案之前加入了推理路径。因此,一些研究人员调查了推理路径中不同成分的影响。具体而言,最近的一项研究确定了CoT提示中的三个关键组成部分,即符号(例如,算术推理中的数字量)、模式(例如,数学推理中的方程)和文本(即,不是符号或模式的其余词元)。结果表明,后两个部分(即模式和文本)对模型性能至关重要,删除其中任何一个都会导致性能显著下降。然而,符号和图案的正确性似乎并不重要。此外,文本和模式之间存在共生关系:文本帮助LLM生成有用的模式,模式帮助LLM理解任务并生成有助于解决问题的文本。
总之,CoT提示为激发LLM的推理能力提供了一种通用而灵活的方法。也有一些初步尝试将该技术扩展到解决多模态任务和多语言任务。除了将LLM与ICL和CoT直接结合使用外,最近的一些研究还探讨了如何将LLM的能力专门化为特定任务,这被称为模型专门化。例如,[294]中的研究人员通过微调LLM生成的CoT推理路径上的小规模Flan-T5,专门研究LLM的数学推理能力。模型专业化也可用于解决各种任务,如问答、代码合成和信息检索。
7 能力评估
为了检验LLM的有效性和优越性,利用大量的任务和基准进行了实证评估和分析。我们首先介绍了用于语言生成和理解的LLM的三种基本评估任务,然后介绍了几种具有更复杂设置或目标的LLM高级任务,最后讨论了现有的基准和实证分析。
7.1 基本的评估任务

在这一部分中,我们主要关注LLM的三种评估任务,即语言生成、知识利用和复杂推理。值得注意的是,我们并不打算完全覆盖所有相关任务,而是只关注LLM中讨论或研究最广泛的任务。接下来,我们将详细介绍这些任务。
7.1.1 语言生成
根据任务定义,现有的语言生成任务大致可以分为语言建模任务、条件文本生成任务和代码合成任务。请注意,代码合成不是一个典型的NLP任务,我们将其包括在内进行讨论,因为它可以通过与自然语言文本类似的生成方法中的许多LLM(根据代码数据训练)直接解决。
语言建模。
作为LLM最基本的能力,语言建模旨在基于先前的词元预测下一个词元,主要关注基本的语言理解和生成能力。为了评估这种能力,现有工作使用的典型语言建模数据集包括Penn Treebank、WikiText-103和Pile,其中困惑度量通常用于评估零样本设置下的模型性能。实证研究表明,在这些评估数据集上,LLM比以前最先进的方法带来了显著的性能提升。为了更好地测试文本中长程依赖关系的建模能力,引入了LAMBADA数据集,其中LLM被要求基于上下文的段落来预测句子的最后一个单词。然后,利用预测的最后单词的准确性和困惑性来评估LLM。如现有工作所示,语言建模任务的性能通常遵循缩放定律,这意味着缩放语言模型将提高准确性并减少困惑。
条件文本生成。
作为语言生成中的一个重要主题,条件文本生成专注于基于给定条件生成满足特定任务需求的文本,通常包括机器翻译、文本摘要和问答。为了测量生成的文本的质量,通常使用自动度量(例如准确性、BLEU和ROUGE)和人工评级来评估性能。由于强大的语言生成能力,LLM在现有的数据集和基准测试上取得了显著的性能,甚至超过了人类的性能(在测试数据集上)。例如,仅给定32个示例作为输入,具有上下文学习的GPT-3在SuperGLUE的平均得分上可以优于全数据微调的BERT-Large;在MMLU上,5-shot Chinchilla几乎是人类评分器平均精度的两倍,GPT-4在5-shot设置中进一步实现了最先进的性能,与之前的最佳模型相比,平均精度提高了10%以上。因此,它引起了人们对现有的条件文本生成任务基准是否能够适当地评估和反映LLM的能力的严重关注。考虑到这个问题,研究人员试图通过收集当前无法解决的任务(即LLM不能很好地执行的任务)或创建更具挑战性的任务,例如超长文本生成,来制定新的评估基准(例如,BIG bench Hard)。此外,最近的研究还发现,自动度量可能低估了LLM的生成质量。在OpenDialKG中,ChatGPT在BLEU和ROUGE-L指标上的表现不如微调后的GPT-2,同时赢得了人类判断的更多青睐。因此,需要投入更多的精力来开发更符合人类判断的新指标。
代码合成。
除了生成高质量的自然语言外,现有的LLM还显示出生成形式语言的强大能力,特别是满足特定条件的计算机程序(即代码),称为代码合成。与自然语言生成不同,由于生成的代码可以通过与相应的编译器或解释器执行来直接检查,现有工作大多通过计算测试用例的通过率来评估LLM生成的代码的质量,即pass@k。最近,提出了几个专注于功能正确性的代码基准来评估LLM的代码合成能力,如APPS、HumanEval和MBPP。通常,它们包括各种编程问题,以及用于正确性检查的文本规范和测试用例。为了提高这种能力,对代码数据进行微调(或预训练)LLM是关键,这可以有效地使LLM适应代码合成任务。此外,现有工作提出了生成代码的新策略,例如,对多个候选解决方案进行采样和规划引导解码,这可以被认为是程序员对错误修复和代码规划过程的模仿。令人印象深刻的是,LLM最近在编程竞赛平台Codeforces的用户中排名前28%,显示出了与人类的竞争表现。此外,GitHub Copilot已经发布,以帮助编程在编译IDE(例如,Visual Studio和JetBrains IDE),这些IDE可以支持多种语言,包括Python、JavaScript和Java。ACM通讯中一篇题为“编程的终结”的观点文章讨论了人工智能编程在计算机科学领域的影响,强调了向高度自适应LLM作为一种新的原子计算单元的重要转变。
主要问题。
尽管LLM在生成类人文本方面取得了出色的表现,但它们在语言生成中容易受到以下两个主要问题的影响。
- 可控生成。对于LLM来说,在给定条件下生成文本的主流方式是通过使用自然语言指令或提示。尽管简单,但这种机制在对这些模型的生成输出施加细粒度或结构约束方面提出了重大挑战。现有工作表明,当生成结构上有复杂约束的文本时,LLM可以很好地处理局部规划(例如,近端句子之间的交互),但可能难以处理全局规划(即,长期相关性)。例如,要生成一个包含多个段落的复杂长段,考虑到整个文本,仍然很难直接确保特定的文本结构(例如概念的顺序和逻辑流程)。对于需要形式规则或语法的生成任务,例如代码合成,这种情况将变得更加具有挑战性。为了解决这个问题,一个潜在的解决方案是将一次性生成扩展到LLM的迭代提示中。这模拟了人类写作过程,将语言生成分解为多个步骤,如计划、起草、重写和编辑。几项研究已经证明,迭代提示可以引出相关知识,以在子任务中获得更好的性能。从本质上讲,思维提示链利用了将复杂任务分解为多步骤推理链的思想。此外,生成文本的安全控制对于实际部署也很重要。研究表明,LLM可能生成包含敏感信息或冒犯性表达的文本。尽管RLHF算法可以在一定程度上缓解这个问题,但它仍然依赖于大量的人工标记数据来调整LLM,而没有遵循客观的优化目标。因此,必须探索有效的方法来克服这些限制,并对LLM的输出进行更安全的控制。
- 特定生成。尽管LLM已经学会了生成连贯文本的通用语言模式,但在处理特定领域或任务时,他们在生成方面的熟练程度可能会受到限制。例如,在生成涉及许多医学术语和方法的医学报告时,经过一般网络文章训练的语言模型可能会面临挑战。直观地说,领域知识应该是模型专业化的关键。然而,将这样的专业知识注入LLM并不容易。正如最近的分析中所讨论的那样,当LLM被训练成表现出某种特定的能力,使他们能够在某些领域表现出色时,他们可能会在其他领域遇到困难。这样的问题与训练神经网络中的灾难性遗忘有关,灾难性遗忘是指整合新旧知识的冲突现象。类似的情况也发生在LLM的人为调整中,其中必须支付“对齐税”(例如,上下文学习能力的潜在损失),以适应人类的价值观和需求。因此,开发有效的模型专业化方法非常重要,这种方法可以灵活地将LLM适应各种任务场景,同时尽可能保留原有的能力。
7.1.2 知识利用
知识利用是智能系统在支持事实证据的基础上完成知识密集型任务(如常识性问答和事实填充)的重要能力。具体而言,它要求LLM正确利用预训练语料库中丰富的事实知识,或在必要时检索外部数据。特别是,问答(QA)和知识填充是评估这种能力的两个常用任务。根据测试任务(问答或知识填充)和评估设置(有或没有外部资源),我们将现有的知识利用任务分为三类,即闭书QA、开卷QA和知识完成。
闭卷QA。
闭卷QA任务测试从预训练语料库中获得的LLM的事实知识,其中LLM应仅根据给定的上下文回答问题,而不使用外部资源。为了评估这种能力,有几个数据集可以利用,包括Natural Questions、Web Questions和TriviaQA,其中准确度度量被广泛采用。经验结果表明,LLM在这种情况下可以表现良好,甚至可以与最先进的开放域QA系统的性能相匹配。此外,LLM在闭卷QA任务上的性能也在模型大小和数据大小方面显示出一种缩放定律模式:缩放参数和训练词元可以增加LLM的容量,并帮助他们从预训练数据中学习(或记忆)更多知识。此外,在类似的参数量表下,具有更多与评估任务相关的预训练数据的LLM将获得更好的性能。此外,闭卷QA设置还为探究LLM编码的事实知识的准确性提供了一个试验台。然而,如现有工作所示,LLM在依赖细粒度知识的QA任务中可能表现不佳,即使它存在于预训练数据中。
开卷QA。
与闭卷QA不同,在开卷QA任务中,LLM可以从外部知识库或文档集合中提取有用的证据,然后根据提取的证据回答问题。典型的开卷QA数据集(例如,Natural Questions、OpenBookQA和SQuAD)与闭卷QA数据集重叠,但它们包含外部数据源,例如维基百科。准确性和F1分数的度量被广泛用于开卷QA任务的评估。为了从外部资源中选择相关知识,LLM通常与文本检索器(甚至搜索引擎)配对,文本检索器独立或与LLM联合训练。在评估中,现有的研究主要集中在测试LLM如何利用提取的知识来回答问题,并表明检索到的证据可以在很大程度上提高生成答案的准确性,甚至使较小的LLM优于10倍较大的LLM。此外,开卷QA任务还可以评估知识信息的最近性。预训练或从过时的知识资源中检索可能会导致LLM为时间敏感的问题生成错误的答案。
知识填充。
在知识填充任务中,LLM可能(在某种程度上)被视为一个知识库,可以利用它来填充或预测知识单元(例如,知识三元组)的缺失部分。这类任务可以调查和评估LLM从预训练数据中学习了多少和什么样的知识。现有的知识填充任务可以大致分为知识图填充任务(例如,FB15k237和WN18RR)和事实填充任务(如,WikiFact),其目的分别是填充知识图中的三元组和关于特定事实的不完整句子。实证研究表明,现有的LLM很难完成与特定关系类型相关的知识填充任务。如WikiFact上的评估结果所示,LLM在预训练数据中出现的几种频繁关系(如currency和作者)上表现良好,而在罕见关系(如发现者_或_事件者和地点_出生)上表现不佳。有趣的是,在相同的评估设置下(例如,在上下文学习中),InstructionGPT(即text-davinci-002)在WikiFact的所有子集中都优于GPT-3。这表明指令调整有助于LLM完成知识填充任务。

主要问题。
尽管LLM在获取和利用知识信息方面取得了关键进展,但仍存在以下两个主要问题。
- 幻觉。在生成事实文本时,一个具有挑战性的问题是幻觉生成,其中生成的信息要么与现有来源相冲突(内在幻觉),要么无法通过可用来源进行验证(外在幻觉),如图8中的两个例子所示。幻觉广泛发生在现有的LLM中,甚至是最高级的LLM,如GPT4。从本质上讲,LLM似乎“无意识地”在任务解决中使用知识,而任务解决仍然缺乏准确控制内部或外部知识使用的能力。幻觉会误导LLM产生不期望的输出,并在很大程度上降低性能,导致在现实应用中部署LLM时存在潜在风险。为了缓解这个问题,对齐调整策略(如第5.2节所述)已在现有工作中广泛使用,这些工作依赖于根据高质量数据调整LLM或使用人类反馈。为了评估幻觉问题,已经提出了一组幻觉检测任务,例如,TruthfulQA,用于检测模型模仿的人类虚假信息。
- 知识的近期性。作为另一个主要挑战,LLM在解决需要训练数据之外的最新知识的任务时会遇到困难。为了解决这个问题,一个简单的方法是定期用新数据更新LLM。然而,微调LLM的成本非常高,而且在增量训练LLM时也可能导致灾难性的遗忘问题。因此,有必要制定高效和有效的方法,将新知识整合到现有的LLM中,使其与时俱进。现有研究探索了如何利用外部知识源(如搜索引擎)来补充LLM,LLM可以与LLM联合优化,也可以用作即插即用模块。例如,ChatGPT利用检索插件来访问最新的信息源。通过将提取的相关信息纳入上下文,LLM可以获得新的事实知识,并更好地执行相关任务。然而,这种做法似乎仍然停留在表面上。据透露,很难直接修改内在知识或将特定知识注入LLM,这仍然是一个悬而未决的研究问题。
7.1.3 复杂推理
复杂推理是指理解和利用支持性证据或逻辑得出结论或做出决定的能力。根据推理过程中涉及的逻辑和证据的类型,我们考虑将现有的评估任务分为三大类,即知识推理、符号推理和数学推理。
知识推理。
知识推理任务依赖于关于事实知识的逻辑关系和证据来回答给定的问题。现有工作主要使用特定的数据集来评估相应类型知识的推理能力,例如,用于常识性知识推理的CSQA/StrategyQA和用于科学知识推理的ScienceQA。除了预测结果的准确性外,现有工作还通过自动度量(例如BLEU)或人工评估评估了生成的推理过程的质量。通常,这些任务要求LLM根据事实知识进行逐步推理,直到找到给定问题的答案。为了获得逐步推理能力,已经提出了思维链(CoT)提示策略来增强LLM的复杂推理能力。如第6.2节所述,CoT将可以手动创建或自动生成的中间推理步骤纳入提示中,以指导LLM执行多步骤推理。这种方式在很大程度上提高了LLM的推理性能,在几个复杂的知识推理任务上产生了新的最先进的结果。此外,在将知识推理任务重新表述为代码生成任务后,研究人员发现LLM的性能可以进一步提高,尤其是在代码上预训练的LLM。然而,由于知识推理任务的复杂性,当前LLM在常识推理等任务上的性能仍然落后于人类结果。作为最常见的错误之一,LLM可能会基于错误的事实知识生成不准确的中间步骤,从而导致错误的最终结果。为了解决这个问题,现有工作提出了特殊的解码或集成策略,以提高整个推理链的准确性。最近,一项实证研究表明,LLM可能很难明确推断出特定任务所需的常识性知识,尽管它们可以成功地解决该问题。此外,它进一步表明,利用自我生成的知识可能无助于提高推理性能。
符号推理。
符号推理任务主要集中于在形式规则设置中操纵符号以实现一些特定目标,其中LLM在预训练过程中可能从未见过操作和规则。现有工作通常在最后一个字母串联和掷硬币的任务中评估LLM,其中评估示例需要与上下文中示例相同的推理步骤(称为域内测试)或更多步骤(称为域外测试)。对于域外测试的示例,LLM只能在上下文中看到带有两个单词的示例,但它要求LLM连接三个或更多单词的最后一个字母。通常,采用生成的符号的准确性来评估LLM在这些任务上的性能。因此,LLM需要理解复杂场景中符号操作及其组成之间的语义关系。然而,在域外环境下,由于LLM没有看到符号运算和规则的复杂组成(例如,上下文示例中运算数量的两倍),LLM很难捕捉到它们的准确含义。为了解决这个问题,现有的研究结合了草稿本和导师策略,以帮助LLM更好地操纵符号运算,从而生成更长、更复杂的推理过程。另一项研究工作利用形式化编程语言来表示符号运算和规则,这需要LLM生成代码,并通过使用外部解释器执行来执行推理过程。这种方式可以将复杂的推理过程分解为LLM和解释器的代码合成和程序执行,从而简化推理过程,获得更准确的结果。
数学推理。
数学推理任务需要综合利用数学知识、逻辑和计算来解决问题或生成证明语句。现有的数学推理任务主要分为数学问题求解和定理自动证明。对于数学问题解决任务,SVAMP、GSM8k和math数据集通常用于评估,其中LLM需要生成准确的具体数字或方程来回答数学问题。由于这些任务也需要多步骤推理,思维链提示策略已被广泛用于LLM,以提高推理性能。作为一种实用的策略,在大规模数学语料库上持续预训练LLM可以在很大程度上提高它们在数学推理任务中的性能。此外,由于不同语言的数学问题具有相同的数学逻辑,研究人员还提出了一个多语言数学单词问题基准来评估LLM的多语言数学推理能力。作为另一项具有挑战性的任务,自动定理证明(ATP)要求推理模型严格遵循推理逻辑和数学技能。为了评估该任务的性能,PISA和miniF2F是两个典型的ATP数据集,以验证成功率作为评估指标。作为一种典型的方法,现有的ATP工作利用LLM来帮助使用交互式定理证明器(ITP)搜索证明,如Lean、Metamath和Isabelle。ATP研究的一个主要局限是缺乏形式语言中的相关语料库。为了解决这一问题,一些研究利用LLM将非正式陈述转换为正式证明,以扩充新数据,或者生成草稿和证明草图,以减少证明的搜索空间。
主要问题。
尽管取得了进步,LLM在解决复杂推理任务方面仍然存在一些局限性。
- 不一致。通过改进的推理策略(例如,CoT提示),LLM可以通过基于支持逻辑和证据进行逐步推理来解决一些复杂的推理任务。尽管有效,但在分解推理过程中经常会出现不一致问题。具体而言,LLM可能会按照无效的推理路径生成正确的答案,或者在正确的推理过程后生成错误的答案,导致导出的答案与推理过程之间不一致。为了缓解这一问题,现有工作提出通过外部工具或模型指导LLM的整个生成过程,或者重新检查推理过程和最终答案以纠正它们。作为一种很有前途的解决方案,最近的方法将复杂的推理任务重新表述为代码生成任务,其中生成的代码的严格执行确保了推理过程和结果之间的一致性。此外,研究表明,具有相似输入的任务之间也可能存在不一致性,其中任务描述的微小变化可能导致模型产生不同的结果。为了缓解这个问题,可以应用多个推理路径的集成来增强LLM的解码过程。
- 数值计算。对于复杂的推理任务,LLM在所涉及的数值计算中仍然面临困难,尤其是对于预训练过程中很少遇到的符号,例如大数算术。为了解决这个问题,一种直接的方法是调整合成算术问题上的LLM。大量研究遵循了这种方法,并通过特殊的训练和推理策略(例如,草稿纸跟踪)进一步提高了数值计算性能。此外,现有工作也包含了外部工具(例如计算器),特别是用于处理算术运算。最近,ChatGPT提供了一种使用外部工具的插件机制。通过这种方式,LLM需要学习如何正确地操作这些工具。为此,研究人员使用工具(甚至LLM本身)来调整LLM,或者设计了用于上下文学习的指令和示例来扩充示例。然而,这些LLM仍然依赖于文本上下文来捕捉数学符号的语义(在预训练阶段),这在本质上并不最适合数值计算。
7.2 高级能力评估
除了上述基本评估任务外,LLM还表现出一些卓越的能力,需要特别考虑评估。在这一部分中,我们讨论了几种具有代表性的高级能力和相应的评估方法,包括人的一致性、与外部环境的互动和工具操作。接下来,我们将详细讨论这些高级能力。
7.2.1 人类对齐
希望LLM能够很好地符合人类的价值观和需求,即人类的一致性,这是LLM在现实世界应用中广泛使用的关键能力。
为了评估这种能力,现有的研究考虑了人类对齐的多种标准,如乐于助人、诚实和安全。为了提供帮助和诚实,可以利用对抗性问答任务(例如,TruthfulQA)来检查LLM在检测文本中可能的虚假方面的能力。此外,无害性也可以通过几个现有的基准进行评估,例如CrowS Pairs和Winogender。尽管使用上述数据集进行了自动评估,但人类评估仍然是有效测试LLM人类对齐能力的更直接的方法。OpenAI邀请了许多与AI风险相关领域的专家来评估和改进GPT-4在遇到风险内容时的行为。此外,对于人类对齐的其他方面(如真实性),一些研究建议使用特定的说明和设计注释规则来指导注释过程。实证研究表明,这些策略可以极大地提高LLM的人际协调能力。例如,在对通过与专家交互收集的数据进行对齐调整后,当GPT-4处理敏感或不允许的提示时,它的错误行为率可以大大降低。此外,高质量的预训练数据可以减少对齐所需的工作量。例如,由于科学语料库中的偏见较少,Galactica可能更无害。
7.2.2 与外部环境的互动
除了标准评估任务外,LLM还能够接收来自外部环境的反馈,并根据行为指令执行行动,例如,用自然语言生成行动计划以操纵代理。这种能力也出现在LLM中,LLM可以生成详细且高度现实的行动计划,而较小的模型(例如GPT-2)往往会生成较短或无意义的计划。
为了测试这种能力,可以使用几个具体的人工智能基准进行评估,如下所述。VirtualHome为清洁和烹饪等家庭任务构建了一个3D模拟器,其中代理可以执行LLM生成的自然语言动作。ALFRED包括更具挑战性的任务,这些任务需要LLM来实现组成目标。BEHAVIOR专注于模拟环境中的日常琐事,并要求LLM生成复杂的解决方案,例如更改对象的内部状态。基于LLM生成的行动计划,现有的工作要么采用基准中的常规指标(例如,生成行动计划的可执行性和正确性),要么直接进行真实世界的实验并测量成功率,以评估这种能力。现有工作已经表明LLM在与外部环境互动和制定准确行动计划方面的有效性。最近,已经提出了几种改进的方法来增强LLM的交互能力,例如,设计类似代码的提示和提供真实世界的基础。
7.2.3 工具操纵
在解决复杂问题时,如果LLM认为有必要,他们可以求助于外部工具。通过用API调用封装可用工具,现有工作涉及多种外部工具,例如搜索引擎、计算器和编译器,以提高LLM在几个特定任务上的性能。最近,OpenAI支持在ChatGPT中使用插件,这可以为LLM提供语言建模之外的更广泛的能力。例如,网络浏览器插件使ChatGPT能够访问新信息。此外,结合第三方插件对于创建一个繁荣的基于LLM的应用程序生态系统尤其关键。
为了检验工具操作的能力,现有的工作大多采用复杂的推理任务进行评估,如数学问题解决(如GSM8k和SVAMP)或知识问答(如TruthfulQA),其中工具的成功利用对于提高LLM无法掌握的所需技能(如数值计算)非常重要。这样,评估的这些任务的性能可以反映LLM在工具操作中的能力。为了教LLM使用工具,现有研究添加了使用上下文中的工具来引出LLM的示例,或对关于工具使用的模拟数据进行微调LLM。现有工作发现,在工具的帮助下,LLM变得更有能力处理它们不擅长的问题,例如方程计算和利用实时信息,并最终提高最终性能。
总结以上三种能力对LLM的实际性能具有重要价值:符合人类的价值观和偏好(人类对齐)、在现实世界场景中正确行动(与外部环境的交互)和扩大能力范围(工具操纵)。除了上述三种高级能力外,LLM还可能表现出与某些任务(例如,数据注释)或学习机制(例如,自我完善)特别相关的其他能力。发现、衡量和评估这些新兴能力,以更好地利用和改进LLM,将是一个开放的方向。
7.3 公开的基准与实证分析
在前面的部分中,我们讨论了LLM的评估任务及其相应的设置。接下来,我们将介绍现有的LLM评估基准和实证分析,重点是从一般角度探索更全面的讨论。
7.3.1 评估基准
最近,已经发布了几个用于评估LLM的综合基准。在这一部分中,我们介绍了几个具有代表性且广泛使用的基准,即MMLU、BIG基准和HELM。
- MMLU是大规模评估多任务知识理解的通用基准,涵盖了从数学和计算机科学到人文社会科学的广泛知识领域。这些任务的难度从基本到高级各不相同。如现有工作所示,在该基准上,LLM大多以相当大的优势优于小型模型,这表明了模型大小的缩放定律。最近,GPT-4在MMLU中取得了显著的记录(在5-shot中为86.4%),这明显优于以前最先进的模型。
- BIG bench是一个协作基准,旨在从各个方面调查现有LLM。它包括204项任务,涵盖了广泛的主题,包括语言学、儿童发展、数学、常识推理、生物学、物理学、社会偏见、软件开发等。通过缩放模型大小,LLM甚至可以在BIG bench中65%的任务中,在小样本设置下的平均人类表现。考虑到整个基准的高评估成本,提出了一个轻量级基准BIG bench Lite,它包含来自BIG Benk的24个小而多样且具有挑战性的任务。此外,BIG Benchhard(BBH)基准已被提出,通过选择LLM表现出低于人类性能的具有挑战性的任务,专注于研究LLM目前无法解决的任务。由于BBH变得更加困难,小型模型的性能大多接近随机。作为比较,CoT提示可以引发LLM执行逐步推理以提高性能的能力,甚至超过BBH中的平均人类性能。
- HELM是一个全面的基准,目前实现了16种场景和7类指标的核心集合。它建立在许多先前研究的基础上,对语言模型进行了全面评估。如HELM的实验结果所示,指令调优可以持续提高LLM在准确性、稳健性和公平性方面的性能。此外,对于推理任务,已经在代码语料库上预训练的LLM显示出优越的性能。
上述基准涵盖了评估LLM的各种主流评估任务。此外,还有几个基准侧重于评估LLM的特定能力,如用于多语言知识利用的TyDiQA和用于多语言数学推理的MGSM。为了进行评估,可以根据具体目标选择合适的基准。此外,还有一些开源评估框架可供研究人员在现有基准上评估LLM,或扩展新任务进行定制评估,如Language Model Evaluation Harness和OpenAI Evals。
7.3.2 大模型能力的综合分析
除了建立大规模的评估基准外,大量研究还进行了全面分析,以调查LLM的优势和局限性。在这一部分中,我们从多面手(通用能力)和专家(特定领域能力)两个主要方面简要讨论了它们。
通用能力。
由于其卓越的表现,现有工作系统地评估了LLM的一般能力,以探索其在各种不同任务或应用中的能力。通常,这些研究主要集中在新出现的LLM(例如,ChatGPT和GPT-4)上,这些LLM以前没有得到很好的研究,讨论如下:
- 精通。为了评估LLM在解决一般任务中的掌握程度,现有工作通常收集一组涵盖一系列任务和域的数据集,然后在少数/零样本设置下测试LLM。经验结果显示了LLM作为通用任务求解器的优越能力。作为一项显著的进步,GPT-4在广泛的任务中,如语言理解、常识推理和数学推理,通过基准特定训练,已经超过了最先进的方法。此外,它可以在为人类设计的现实世界考试中取得类似人类的成绩(例如,高级入学考试和研究生成绩考试)。最近,一项全面的定性分析显示,GPT-4在各个领域(如数学、计算机视觉和编程)的各种具有挑战性的任务中接近人类水平的表现,并将其视为“人工通用智能系统的早期版本”。尽管取得了有希望的结果,但这项分析也表明,GPT-4仍有严重的局限性。例如,GPT-4很难校准其对生成结果的信心,也无法验证其与训练数据及其自身的一致性。此外,它在需要规划(例如,解决“汉诺塔”问题)或概念跳跃(例如,提出新的科学假设)的任务上表现较差。此外,几项研究还表明,LLM可能会误解来自特定领域的信息提取任务中不熟悉的概念,并在解决语用情绪相关任务(例如,个性化情绪识别)方面面临挑战,与特定的微调模型相比,表现出较差的性能。
- 坚固性。除了掌握之外,另一个需要考虑的方面是LLM对噪声或扰动的稳定性,这对实际应用尤其重要。为了评估LLM对噪声或扰动的鲁棒性,现有工作对输入进行对抗性攻击(例如,词元替换),然后根据输出结果的变化评估LLM的鲁棒性。研究表明,在各种任务中,LLM比小型语言模型更具鲁棒性,但可能会遇到关于鲁棒性的新问题,例如鲁棒性不稳定性和提示敏感性。具体而言,当使用相同输入的不同表达式时,LLM倾向于提供不同的答案,即使与自身生成的内容相冲突。当使用不同的提示评估稳健性时,这样的问题也会导致结果不稳定,使得稳健性分析的评估结果本身不太可靠。
专业能力
由于LLM已经在大规模混合源语料库上进行了预训练,因此它们可以从预训练数据中获取丰富的知识。因此,LLM也被聘为特定领域的领域专家或专家。因此,最近的研究广泛探索了LLM用于解决特定领域任务的方法,并评估了LLM的适应能力。通常,这些研究收集或构建特定领域的数据集,以使用上下文学习来评估LLM的性能。由于我们的重点不是涵盖所有可能的应用领域,我们简要讨论了研究界相当关注的三个代表性领域,即医疗保健、教育和法律。
- 医疗保健是一个与人类生活密切相关的重要应用领域。自ChatGPT出现以来,一系列研究将ChatGPT或其他LLM应用于医学领域。研究表明,LLM能够处理各种医疗保健任务,例如生物信息提取、医疗咨询和报告简化,甚至可以通过专门为专业医生设计的医疗执照考试。然而,LLM可能会编造医学错误信息,例如,误解医学术语并提出与医学指南不一致的建议。此外,上传患者的健康信息也会引发隐私问题。
- 教育也是LLM可能产生重大影响的一个重要应用领域。现有工作发现,LLM可以在数学、物理、计算机科学等科目的标准化考试中,在多项选择题和自由反应题中取得学生水平的成绩。此外,实证研究表明,LLM可以作为教育的写作或阅读助理。最近的一项研究表明,ChatGPT能够跨学科生成逻辑一致的答案,平衡深度和广度。另一项定量分析显示,在计算机安全领域的一些课程中,使用ChatGPT的学生比使用不同使用方法(例如,保留或完善LLM的结果作为自己的答案)的普通学生表现更好。然而,LLM越来越受欢迎,这引发了人们对合理使用这种智能助理进行教育的担忧(例如,在家庭作业中作弊)。
- 法律是一个建立在专业领域知识基础上的专业领域。最近,许多研究将LLM应用于解决各种法律任务,例如,法律文书分析、法律判决预测和法律文书写作。最近的一项研究发现,LLM拥有强大的法律解释和推理能力。此外,与人类考生相比,最新的GPT-4模型在模拟律师考试中获得了最高10%的分数。然而,LLM在法律中的使用也引发了人们对法律挑战的担忧,包括版权问题、个人信息泄露或偏见和歧视。
除了上述工作外,还从其他角度分析了LLM的能力。例如,最近的一些工作研究了LLM的类人特征,如自我意识、心理理论(ToM)和情感计算。特别是,对两个经典的错误信念任务进行的ToM实证评估推测,LLM可能具有类似ToM的能力,因为GPT-3.5系列中的模型在ToM任务中与九岁儿童的表现相当。此外,另一项工作已经调查了关于LLM的现有评估设置的公平性和准确性,例如,源预训练数据的大规模混合可能包含测试集中的数据。
8 结论与未来方向
在这项综述中,我们回顾了大型语言模型(LLM)的最新进展,并介绍了理解和使用LLM的关键概念、发现和技术。我们关注的是大型模型(即大小大于10B),而排除了现有文献中已充分涵盖的早期预训练语言模型(如BERT和GPT-2)的内容。特别是,我们的综述讨论了LLM的四个重要方面,即预训练、适应调整、利用和评估。对于每一个方面,我们都强调LLM成功的关键技术或发现。此外,我们还总结了开发LLM的可用资源,并讨论了复制LLM的重要实施指南。这项调查试图涵盖LLM的最新文献,并为研究人员和工程师提供了一个很好的参考资源。
接下来,我们总结了本次综述的讨论,并从以下几个方面介绍了LLM面临的挑战和未来的发展方向。
理论与原理。
为了理解LLM的潜在工作机制,最大的谜团之一是信息是如何通过非常大的深度神经网络分布、组织和利用的。揭示大语言模型能力的基础基本原理与要素这一点很重要。特别是,扩展似乎在提高LLM的容量方面发挥着重要作用。研究表明,当语言模型的参数规模增加到临界规模(例如,10B)时,一些涌现能力会以意想不到的方式出现(突然的性能飞跃),通常包括上下文学习、指令跟随和逐步推理。这些涌现的能力令人着迷但又令人困惑:LLM何时以及如何获得这些能力尚不清楚。最近的研究要么进行了广泛的实验来研究涌现能力的影响和对这些能力的贡献因素,要么用现有的理论框架解释一些特定的能力。一篇颇有见地的技术帖子也专门讨论了这个话题,以GPT系列模型为目标。然而,理解、表征和解释LLM的能力或行为的更正式的理论和原则仍然缺失。由于涌现能力与自然界中的相变非常相似,跨学科理论或原理(例如,LLM是否可以被视为某种复杂系统)可能有助于解释和理解LLM的行为。这些基本问题值得研究界探索,对开发下一代LLM很重要。
模型体系结构。
由于其可扩展性和有效性,由堆叠的多头自注意力层组成的Transformer已成为构建LLM的事实架构。已经提出了各种策略来提高该架构的性能,例如神经网络配置和可扩展的并行训练(见第4.2.2节中的讨论)。为了增强模型容量(例如,多回合会话能力),现有LLM通常保持较长的上下文窗口,例如,GPT-4-32k具有32768个令牌的超大上下文长度。因此,一个实际的考虑是降低标准自注意机制产生的时间复杂性(最初是二次成本)。研究更有效的Transformer变体在构建LLM中的影响很重要,例如,GPT3中使用了稀疏注意力。此外,灾难性遗忘对神经网络来说是一个长期的挑战,这也对LLM产生了负面影响。当用新数据调整LLM时,最初学习的知识很可能会被破坏,例如,根据一些特定任务微调LLM会影响LLM的总体能力。当LLM与人类价值观一致时,也会出现类似的情况(称为一致税)。因此,有必要考虑用更灵活的机制或模块来扩展现有的体系结构,这些机制或模块可以有效地支持数据更新和任务专门化。
模型训练。
在实践中,由于巨大的计算消耗以及对数据质量和训练技巧的敏感性,很难预训练有能力的LLM。因此,考虑到模型有效性、效率优化和训练稳定性等因素,开发更系统、更经济的预训练方法来优化LLM变得尤为重要。应该开发更多的模型检查或性能诊断方法(例如,GPT-4中的可预测缩放),以检测训练期间的早期异常问题。此外,它还要求更灵活的硬件支持或资源调度机制,以便更好地组织和利用计算集群中的资源。由于从头开始预训练LLM的成本非常高,因此设计一种合适的机制来基于公开可用的模型检查点(例如,LLaMA和Flan-T5)持续预训练或微调LLM是很重要的。为此,必须解决一些技术问题,例如灾难性遗忘和任务专门化。然而,到目前为止,仍然缺乏用于LLM的开源模型检查点,该检查点具有完整的预处理和训练日志(例如,准备预训练数据的脚本)以供复制。我们相信,在开源模型中报告更多的技术细节对LLM的研究将具有巨大的价值。此外,开发更多有效激发模型能力的改进调整策略也很重要。
模型利用率。
由于微调在实际应用中成本高昂,提示已成为使用LLM的突出方法。通过将任务描述和演示示例结合到提示中,上下文学习(一种特殊的提示形式)赋予LLM在新任务上表现良好的能力,在某些情况下甚至优于全数据微调模型。此外,为了增强复杂推理的能力,已经提出了先进的提示技术,以思维链策略为例,该策略将中间推理步骤包括在提示中。然而,现有的提示方法仍然存在以下几个不足之处。首先,它在提示的设计上涉及到大量的人力工作。自动生成用于解决各种任务的有效提示将非常有用。其次,一些复杂的任务(如形式证明和数值计算)需要特定的知识或逻辑规则,这些知识或规则可能无法用自然语言很好地表达或通过例子来证明。因此,为提示开发信息量更大、更灵活的任务格式化方法是很重要的。第三,现有的激励策略主要集中在单轮性能上。开发交互式提示机制(例如,通过自然语言对话)来解决复杂任务是有用的,ChatGPT已经证明这非常有用。
安全和对准。
尽管LLM有能力,但它们也面临着与小型语言模型类似的安全挑战。例如,LLM表现出产生幻觉的倾向,这些文本看起来似乎合理,但事实上可能不正确。更糟糕的是,LLM可能是由为恶意系统生成有害、有偏见或有毒文本的故意指令引发的,从而导致潜在的滥用风险。要详细讨论LLM的安全问题(例如,隐私、过度依赖、虚假信息和影响操作),读者可以参考GPT3/4技术报告。作为避免这些问题的主要方法,从人类反馈中强化学习(RLHF)已被广泛使用,将人类纳入训练循环中,以开发一致的LLM。如GPT-4所示,为了提高模型的安全性,在RLHF期间包括安全相关提示也很重要。然而,RLHF严重依赖于来自专业标记员的高质量人类反馈数据,这使得它很难在实践中得到正确实施。因此,有必要改进RLHF框架,以减少人类标注人员的工作量,并寻求一种更有效、数据质量有保证的标注方法,例如,可以使用LLM来协助标注工作。最近,红团队已被用于提高LLM的模型安全性,它利用收集的对抗性提示来细化LLM(即,避免来自红团队的攻击)。此外,为LLM建立适当的学习机制,通过聊天获得人类反馈,并直接利用它进行自我完善,也是有意义的。
应用和生态系统。
由于LLM在解决各种任务方面表现出强大的能力,它们可以应用于广泛的现实世界应用程序(即,遵循特定任务的自然语言指令)。作为一个显著的进步,ChatGPT可能改变了人类访问信息的方式,这一点在新Bing的发布中得到了实现。在不久的将来,可以预见LLM将对信息搜索技术产生重大影响,包括搜索引擎和推荐系统。此外,随着LLM的技术升级,智能信息助理的开发和使用将得到大力推动。在更广泛的范围内,这一波技术创新将导致LLM授权应用程序的生态系统(例如,ChatGPT对插件的支持),这与人类生活有着密切的联系。最后,LLM的兴起为人工通用智能(AGI)的探索提供了线索。它有望开发出比以往更多的智能系统(可能具有多模态信号)。然而,在这个发展过程中,人工智能的安全应该是主要关注的问题之一,即让人工智能为人类带来好处而不是坏处。
CODA:
这项综述是在我们的研究团队举行的一次讨论会上计划的,我们旨在总结大型语言模型的最新进展,作为团队成员可读性强的报告。初稿于2023年3月13日完成,我们的团队成员尽最大努力以相对客观、全面的方式纳入关于LLM的相关研究。然后,我们对文章的写作和内容进行了几次大范围的修改。尽管我们做出了种种努力,但这项调查仍然远非完美:我们可能会错过重要的参考文献或主题,也可能会有不严谨的表达或讨论。由于空间限制,通过设置选择标准,我们只能在图1和表1中包括一小部分现有LLM。然而,我们在GitHub页面上设置了一个更宽松的模型选择标准(https://github.com/RUCAIBox/LLMSurvey),将定期维护。我们将不断更新这项综述,并尽可能提高质量。对我们来说,综述写作也是LLM自己的一个学习过程。对于对改进本次综述有建设性建议的读者,欢迎您在我们综述的GitHub页面上留言或直接给我们的作者发电子邮件。我们将在未来的版本中根据收到的意见或建议进行修订,并感谢在我们的综述中提出建设性建议的读者。
更新日志。在这一部分中,我们定期维护向arXiv提交本次综述的更新日志:
- 2023年3月31日首次发布:初始版本。
- 2023年4月9日更新:添加隶属关系信息,修改图1和表1,明确LLM的相应选择标准,改进写作,纠正一些小错误。
- 2023年4月11日更新:更正库资源的错误。
- 2023年4月12日更新:修订图1和表1,并澄清LLM的发布日期。
- 2023年4月16日更新:添加关于GPT系列模型技术演变的新第2.2节。
- 2023年4月24日更新:添加关于缩放定律的讨论,并添加关于涌现能力的模型大小的一些解释(第2.1节);在图4中添加不同架构的注意力模式的示意图,并在表4中添加详细的公式。
- 2023年4月25日更新:修改图表中的一些复制错误。
- 2023年4月27日更新:在第5.3节中添加高效调优。
- 2023年4月28日更新:修订第5.3节。
- 2023年5月7日更新:修订表1、表2和一些要点。
规划内容。我们将定期在这项综述中加入新的内容,使其更加独立和最新。在这里,我们列出了下一个主要版本中可能出现的几个潜在主题:(1)从GPT-1到ChatGPT的技术演变(部分完成),(2)基于LLaMA的调整(例如,Alpaca),(3)轻量级调整策略(完成),以及(4)模型细节的详细公式(完成)。如果您对本次综述有具体的建议,请给我们留言。