java多线程基础——Callable接口及线程池补充
目录
1.Collable接口
2.线程池
1.Callable接口
Callable接口用法
Callable 是一个 interface . 相当于把线程封装了一个 "返回值". 方便程序猿借助多线程的方式计算结果。下面针对同一个问题我们写出两种代码。
代码示例: 创建线程计算 1 + 2 + 3 + ... + 1000, 不使用 Callable 版本
创建一个类 Result , 包含一个 sum 表示最终结果, lock 表示线程同步使用的锁对象.
main 方法中先创建 Result 实例, 然后创建一个线程 t. 在线程内部计算 1 + 2 + 3 + ... + 1000.
主线程同时使用 wait 等待线程 t 计算结束. (注意, 如果执行到 wait 之前, 线程 t 已经计算完了, 就不 必等待了).
当线程 t 计算完毕后, 通过 notify 唤醒主线程, 主线程再打印结果.
static class Result {
public int sum = 0;
public Object lock = new Object();
}
public static void main(String[] args) throws InterruptedException {
Result result = new Result();
Thread t = new Thread() {//Thread匿名内部类
@Override
public void run() {
int sum = 0;
for (int i = 1; i <= 1000; i++) {
sum += i;
}
synchronized (result.lock) {
result.sum = sum;
result.lock.notify();
}
}
};
t.start();
synchronized (result.lock) {
while (result.sum == 0) {//防止t线程还未执行就打印结果
result.lock.wait();
}
System.out.println(result.sum);
}
}
可以看到, 上述代码需要一个辅助类 Result, 还需要使用一系列的加锁和 wait notify 操作, 代码复 杂, 容易出错。
当然有的同学可能会问,为什么还要创建一个辅助类来记录结果,直接创建一个变量不好吗?
由于变量捕获(不了解的可自行百度)的原因,假如使用变量,那么这个变量必须不被更改或者被final修饰,很明显不管哪种方式都不满足我们的要求。
代码示例: 创建线程计算 1 + 2 + 3 + ... + 1000, 使用 Callable 版本
创建一个匿名内部类, 实现 Callable 接口. Callable 带有泛型参数. 泛型参数表示返回值的类型
重写 Callable 的 call 方法, 完成累加的过程. 直接通过返回值返回计算结果
把 callable 实例使用 FutureTask 包装一下
创建线程, 线程的构造方法传入 FutureTask . 此时新线程就会执行 FutureTask 内部的
Callable 的 call 方法, 完成计算. 计算结果就放到了 FutureTask 对象中
在主线程中调用 futureTask.get() 能够阻塞等待新线程计算完毕. 并获取到 FutureTask 中的结 果.
public static void main(String[] args) throws ExecutionException, InterruptedException {
Callable callable = new Callable() {
@Override
public Integer call() throws Exception {
int sum = 0;
for (int i = 1; i <= 1000; i++) {
sum += i;
}
return sum;
}
};
//包装,目的是为了获取到后续的结果.
FutureTask task = new FutureTask<>(callable);
Thread t = new Thread(task);
t.start();
// 在线程 t 执行结束之前, get 会阻塞. 直到说 t 执行完了, 结果算好了,
// get 才能返回. 返回值就是 call 方法 return 的内容.
System.out.println(task.get());
} 可以看到, 使用 Callable 和 FutureTask 之后, 代码简化了很多, 也不必手动写线程同步代码了.
理解 Callable
Callable 和 Runnable 相对, 都是描述一个 "任务". Callable 描述的是带有返回值的任务, Runnable 描述的是不带返回值的任务.
Callable 通常需要搭配 FutureTask 来使用. FutureTask 用来保存 Callable 的返回结果. 因为 Callable 往往是在另一个线程中执行的, 啥时候执行完并不确定.
FutureTask 就可以负责这个等待结果出来的工作.(只有当计算完成时才能获取到计算结果)
2.线程池
前面我们已经讲过线程池的基本概念和一些使用,这次我们来补充一些线程池的创建操作。没看过之前线程池介绍的可以看一下java多线程基础——定时器与线程池_invictusQAQ的博客-CSDN博客
Java 标准库线程池的几种创建方式 :
import java.util.concurrent.*;
public class ThreadPool {
public static void main(String[] args) {
// 1. 用来处理大量短时间工作任务的线程池,如果池中没有可用的线程将创建新的线程,如果线程空闲60秒将收回并移出缓存
ExecutorService cachedThreadPool=Executors.newCachedThreadPool();
// 2. 创建一个操作无界队列且固定大小线程池
ExecutorService fixedThreadPool = Executors.newFixedThreadPool(3);
// 3. 创建一个操作无界队列且只有一个工作线程的线程池
ExecutorService singleThreadExecutor=Executors.newSingleThreadExecutor();
// 4. 创建一个单线程执行器,可以在给定时间后执行或定期执行。
ScheduledExecutorService singleThreadScheduleExecutor=Executors.newSingleThreadScheduledExecutor();
// 5. 创建一个指定大小的线程池,可以在给定时间后执行或定期执行。
ScheduledExecutorService scheduledThreadPool = Executors.newScheduledThreadPool(3);
// 6. 创建一个指定大小(不传入参数,为当前机器CPU核心数)的线程池,并行地处理任务,不保证处理顺序
Executors.newWorkStealingPool();
// 7. 自定义线程池
ThreadPoolExecutor threadPoolExecutor=new ThreadPoolExecutor(3,10,1000,TimeUnit.MICROSECONDS,new LinkedBlockingQueue());
}
}
前面六种大家应该能够自行通过注释理解,我重点讲一下第七种自定义线程池。

他的参数列表我已经放在上面,我们逐个来讲这些参数代表什么。
corePoolSize:核心线程数
maximumPoolSize:最大线程数
其中 最大线程数-核心线程数得到的就是临时线程数。其中核心线程无论是否繁忙都会始终存在,不会被销毁,而临时线程繁忙时才创建,空闲就销毁。
long keepAliveTime代表最大可空闲时间(线程摸鱼),而Time unit表示时间单位
BlockingQueue
workQueue:虽然线程池内部可以内置任务队列,但我们也能自定义队列交给线程池使用 RejectedExecutionHandler handler:拒绝策略,当任务队列满了之后再次尝试添加任务线程池会怎么做
关于最后一点拒绝策略:
- 第一种拒绝策略是 AbortPolicy,这种拒绝策略在拒绝任务时,会直接抛出一个类型为 RejectedExecutionException 的 RuntimeException,让你感知到任务被拒绝了,于是你便可以根据业务逻辑选择重试或者放弃提交等策略。
- 第二种拒绝策略是 DiscardPolicy,这种拒绝策略正如它的名字所描述的一样,当新任务被提交后直接被丢弃掉,也不会给你任何的通知,相对而言存在一定的风险,因为我们提交的时候根本不知道这个任务会被丢弃,可能造成数据丢失。
- 第三种拒绝策略是 DiscardOldestPolicy,如果线程池没被关闭且没有能力执行,则会丢弃任务队列中的头结点,通常是存活时间最长的任务,这种策略与第二种不同之处在于它丢弃的不是最新提交的,而是队列中存活时间最长的,这样就可以腾出空间给新提交的任务,但同理它也存在一定的数据丢失风险。
- 第四种拒绝策略是 CallerRunsPolicy,相对而言它就比较完善了,当有新任务提交后,如果线程池没被关闭且没有能力执行,则把这个任务交于提交任务的线程执行,也就是谁提交任务,谁就负责执行任务。这样做主要有两点好处。
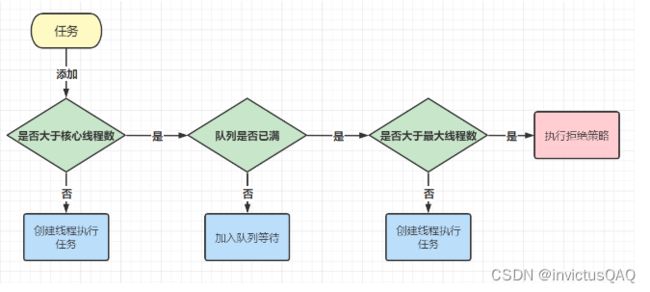
线程池的执行流程:
- 当新加入一个任务时,先判断当前线程数是否大于核心线程数,如果结果为 false,则新建线程并执行任务;
- 如果结果为 true,则判断任务队列是否已满,如果结果为 false,则把任务添加到任务队列中等待线程执行
- 如果结果为 true,则判断当前线程数量是否超过最大线程数?如果结果为 false,则新建线程执行此任务
- 如果结果为 true,执行拒绝策略。