C语言数组
在我们平时定义一个变量时(例如) : int a = 10; 那么问题来了要定义多个相同类型的变量,该咋办呢?难道要一个一个的来定义?答案是当然不是啦!为解决这个为题C语言专门引入了一种特殊的数据类型---数组!
什么是数组?
数组是一块连续的内存空间,用来存储相同类型元素的集合!
数组的分类(维):数组可以分为 一维数组 和 多维数组(一般常见的是二维数组)
一维数组的创建和初始化
一维数组的定义:
type_t arr_name [const_n]
type_t 数组类型 arr_name 数组名
const_n 是一个常量值或表达式,用来指定数组的大小
一维数组的创建:
栗子:
int arr[ 20 ]; double arr1 [ 20 ]; char arr2[10 ];
思考下面的创建方式是否正确?
int n = 20;
int arr[ n ];
答案是看编译器!!因为在C99标准之前,创建数组时[ ]中必须是一个常量才行,不能是变量!但在C99标准中引入了变长数组的概念,数组的大小可以由变量来指定,但数组不能初始化!!小编的VS2019的编译器就不支持变长数组,而在牛客网上的那个编译器是支持变长数组的!
一维数组的初始化:
数组的初始化是指,在创建数组的时候给数组赋一些合理的值;
数组的初始化分为完全初始化和不完全初始化两种!
栗子:
#include
int main()
{
int arr1[5] = { 1,2,3,4,5 };//完全初始化
int arr2[10] = { 1,2,3,4,5 };//不完全初始化
char str1[4] = { 'a','b','c','d' };//完全初始化
char str2[10] = { 'a','b','c','d' };//不完全初始化
return 0;
}
除此之外当你进行完全初始化时,你还可以省略数组的大小!数组会自动给你计算好数组大小的!
这里我猜您会好奇不完全初始化,剩下的在数组中存的是啥呢?我们通过调试一起来看一看: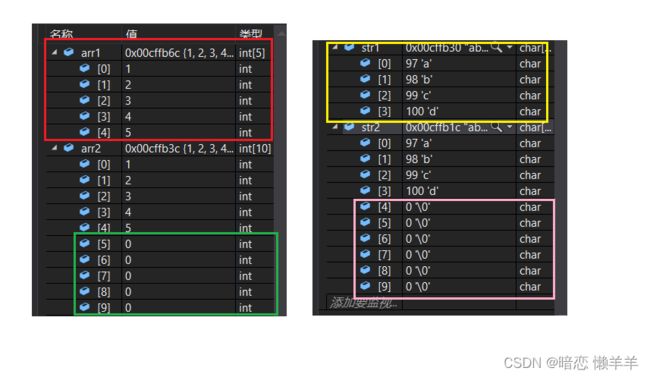
我们发现当不完全初始化时,其余没有被初始化的里面放的是 其类型所对应的 0 值!
下来我们再来看一下面两段代码看有没有区别:
char arr1[] = "a,b,c";
char arr2[3] = {'a','b','c'};
答案是不一样!第一个数组中4个元素,第二个数组中3个元素!下面来看:
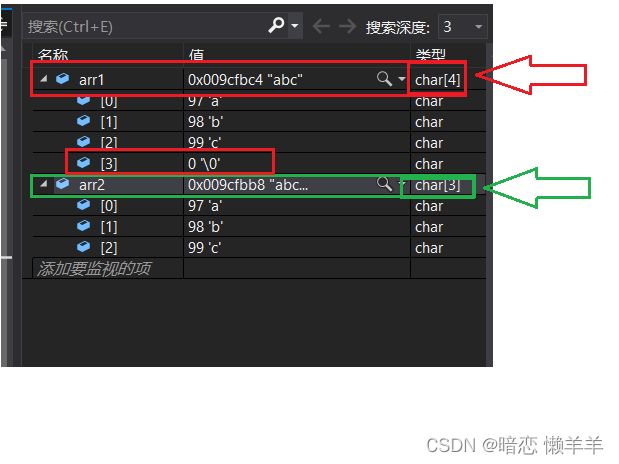
没错!多了一个‘\0’ ,这也与我们之前学的相对应:字符串的结束标志是‘\0’;另外你也可能注意到了char类型在存的时候存的是数字,其实他存的是其字符相对应的ASCII值!这也就是为什么把char归类为整型家族的原因!这个我们后面还会说明!
一维数组的使用:
在进行数组使用之前我们先介绍一个操作符:[ ] -----> 下标引用操作符!它是专门用来访问数组的一个操作符!有很多初学者都不知道这是一种操作符。
我们已经在上面学会了数组定义和初始化,数组必须先定义在使用。那数组定义好了该如何用呢?答案是:用下标(索引)。在C语言和java等语言中数组的下标都是从0开始的。
栗子:
int main()
{
//创建数组并进行不完全初始化
int arr[10] = { 0 };
//计算数组大小
int sz = sizeof(arr) / sizeof(arr[0]);
//定义下标
int i = 0;
//给数组赋值
for (i = 0; i < sz; i++)
{
arr[i] = i;
}
//数组的使用
for (i = 0; i < sz; i++)
{
printf("%d ", arr[i]);
}
return 0;
}
思考:上面把sz换成10可不可以?可不可以是 i <= sz(10)?
答案是:sz在本例中可以换成10,但不推荐。因为如果数组进行完全初始化,可以不指定大小。这时如果不用数组就得数了,不方便而且还有数错的情况;
不可写成 i <=sz(10);因为数组中只有10个元素,下标0--9,如果等于sz(10)的话,就访问到了不是本数组的那块空间上了,即下标越界了!!!所以平时使用数组时一定要注意不要越界!
一维数组的存储:
上面介绍了一维数组的创建和使用,那他是如何存储的呢?我们来一起讨论一下:在讨论它的存储前,我们应该先要知道,数组存储在内存的哪块空间?答案是:在C语言中数组存储在栈区!我们再来一起回顾一下以前的那张简易内存图:

我们知道栈区的使用习惯是先使用高地址,在使用低地址。那么也就是说 i 的地址比 arr的大(i比arr创建的早),而数组的使用习惯是从第地址到高地址arr[0]---->arr[9]的地址是增大的;我们打印它的地址来一起看一看是否是这样呢:
int main()
{
//定义下标
int i = 0;
printf("&i = %p\n", &i);
//创建数组并进行不完全初始化
int arr[10] = { 0 };
//计算数组大小
int sz = sizeof(arr) / sizeof(arr[0]);
//给数组赋值
for (i = 0; i < sz; i++)
{
arr[i] = i;
}
//数组的使用
for (i = 0; i < sz; i++)
{
//%p是以地址的形式打印,一般地址是一个十六进制的数字
printf("\n&arr[%d] = %p\n",i, &arr[i]);
}
return 0;
}结果:
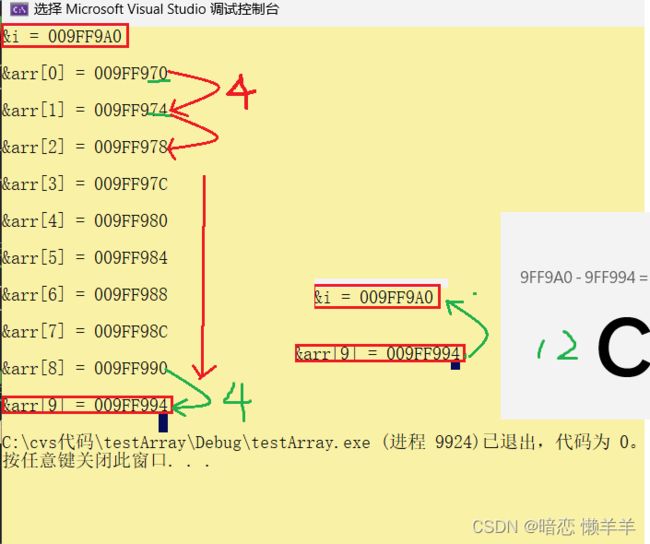
果然是这样,而且我们发现每个数组元素的地址相差4,这其实是应为这个数组是整型数组,每个元素是int类型占4个字节。这也正好再次验证了数组是在内存中是连续存放的!
二维数组的创建和初始化:
二维数组的定义:
type_t arr_name [ const_r] [const_l];
type_t 类型 arr_name 数组名
const_r 行 const_l 列
二维数组的创建:
int arr[3][5];
char str[4][2];
double arr1[2][2];
这里分别定义了三个数组:int 类型的arr 是3行5列,char 类型的str 是4行2列, double类型的arr1是2行2列;
二维数组的初始化:
int main()
{
int arr[2][3] = { 1,2,3,4,5,6 };
int arr1[2][3] = { {1,2,3},{4,5,6} };
int arr3[][3] = { 1,2,3,4,5,6 };
int arr4[][3]= { 1,2,3,4,5,6 };
return 0;
}这四个数组都是完全初始化的四种形式!他们的初始化效果一样!我们用调试来验证一下:
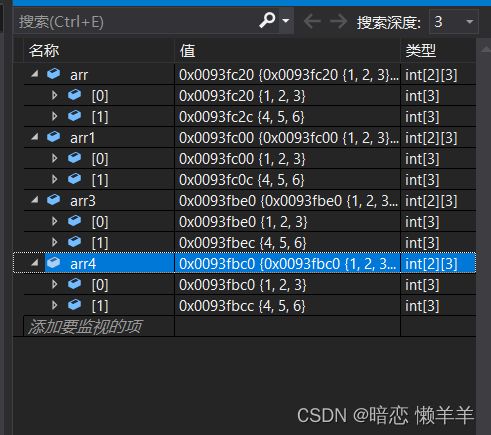
注意:二维数组进行完全初始化时可以省略行而不可以省略列 ! 如果是不熟悉建议都不要省;
二维数组的使用:
二维数组的使用一维数组的使用一样,也是用下标来访问的!
栗子:
int main()
{
//定义下标
int i = 0, j = 0;
//定义数组并进行不完全初始化
int arr[3][4] = { 0 };
//给数组赋值
for (i = 0; i < 3; i++)
{
for (j = 0; j < 4; j++)
{
arr[i][j] = j;
}
}
//打印数组
for (i = 0; i < 3; i++)
{
for (j = 0; j < 4; j++)
{
printf("%d ", arr[i][j]);
}
printf("\n");//打印完一行换行
}
return 0;
}看效果:

这里我进行了每一行打印完后进行了一次换行!
二维数组在内存中的存储:
我们先把上面那段代码的打印结果不换行了看一看打印结果:
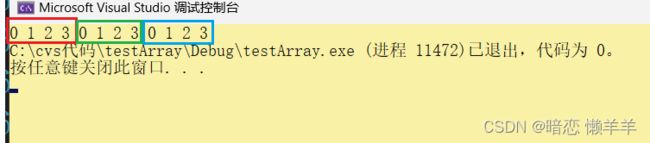
看完结果我们想是不是它的地址和上面打印的结果一样呢?还是三行四列的?我们打印其地址来look 一look:
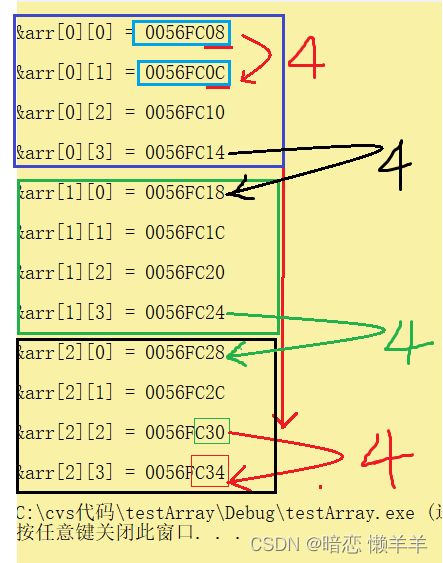
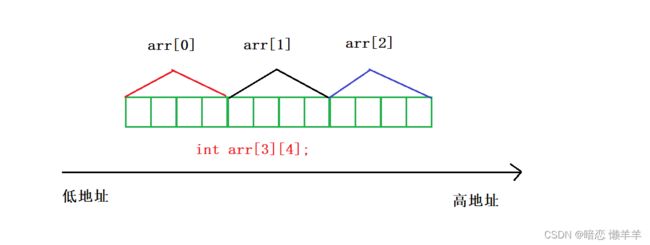
哎,我们发现它的地址好像不是三行四列的而是连续存的和一维数组的存储一样!这也正好说明了一开始 数组的定义: 数组是一块连续的内存空间,是相同类型元素的集合!!!但我们访问二维数组时却是arr[1][2]; 这样的。其实二维数组可以以理解为特殊的数组 ------》元素是数组的数组!OK,这里可能不好理解,我们来一幅图理解一下:

这里arr1,arr2,arr3又是三个一维数组 他们的访问是数组名+下标;也即是 : arr1[2];
如果把arr也用来用下标访问的话arr1就是arr[0]; 如果把上面两部联合起来,直接用arr来访问某个元素不就是arr[2][3];这种形式吗!
也就是说:二维数组是特殊的数组,是一位数组的数组!既然是数组就得有数组名,数组名是arr[i],访问它的元素是就arr[i]+j;也就是arr[i][j];理解到这里我们就可以结合撒谎那个面的地址图画出二维数组的内存图了:
数组的越界:
数组的下标是有范围的;数组的下标是从0开始,如果数组长度是sz的话,那么它的最后一个元素的下标就是sz - 1; 即数组的下标范围是0 ~ sz - 1; 如果你超过了这个范围不管前后,就都出现了数组越界了!但C语言本身不做下标越界检查的,这取决于编译器,有的编译器会报做错,有的则不会!但不报错不一定对,写的时候一定要注意!下面看一个越界的栗子:
int main()
{
int i = 0, j = 0;
int arr[3][4] = { 0 };
//打印数组
for (i = 0; i <= 3; i++)
{
for (j = 0; j <=4; j++)
{
printf("&arr[%d][%d] = %d\n", i, j, arr[i][j]);
}
}
return 0;
}
编译没有问题!看运行结果:

这是一个二维数组的越界,我们发现,虽然越界了但还是运行成功了!但越界的部分打印的是随机值!
建议:平时写的时候,尽量注意下标,不要越界以免造成不必要的麻烦!!!
数组作为函数的参数:
OK,我们直接来个栗子来说明(冒泡排序):
冒泡排序思路讲解:
第一个元素开始,每次比较相邻的元素,符合条件则交换;
下面用画图的方式来演示一下(小编目前还不会动画演示见谅一下):
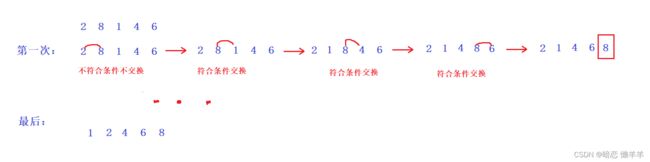
这是进行一趟的,每一趟只能排好一个也元素,排好之后就不再动了!继续进行下一趟...直到排好!
OK,代码演示:
void Bubble_sort(int arr[])
{
int sz = sizeof(arr) / sizeof(arr[0]);
int i = 0;
for (i = 0; i < sz - 1; i++)
{
int j = 0;
for (j = 0; j < sz - 1 - i; j++)
{
if (arr[j] > arr[j + 1])
{
int temp = arr[j];
arr[j] = arr[j + 1];
arr[j + 1] = temp;
}
}
}
}
int main()
{
int arr[] = { 1,3,5,7,9,8,6,4,2,0 };
Bubble_sort(arr);
int i = 0;
for (i = 0; i < sizeof(arr)/sizeof(arr[0]); i++)
{
printf("%d ", arr[i]);
}
return 0;
}OK,来看运行结果!
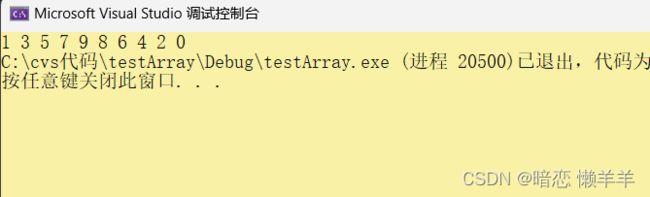
wc,怎么没变呢!不要慌,压力面前保持优雅!!直接调试走起:
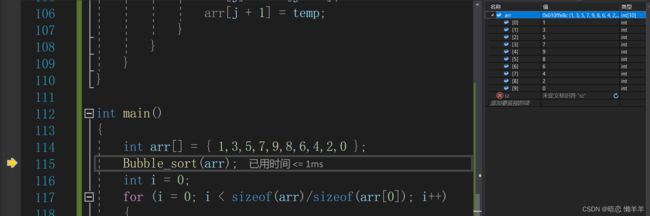
我们可以看到走到这一步时数组刚刚创建好并已经完成了初始化!
进入函数看看到底是怎么样回事:
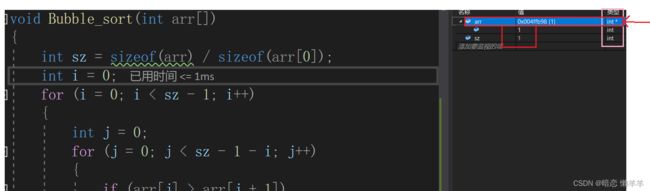
进来之后看见arr中的值是1;sz的值也是1;再仔细观察后发现此时的arr的类型是int*指针类型,那么难道数组在传参的时候没有把整个数组传进进去?要弄清楚这个问题,我们就得知道数组名代表的是什么?
数组名是什么?
刚刚调试的时候我们发现arr中是1,而我们数组中的首元素是1,会不会arr在传参的时候传的是数组的首元素呢?我将数组首元素改为111来验证一下:
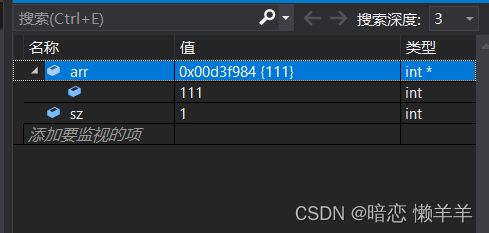
看起来好像是!到底是不是呢? 我们用一段代码来验证一下:
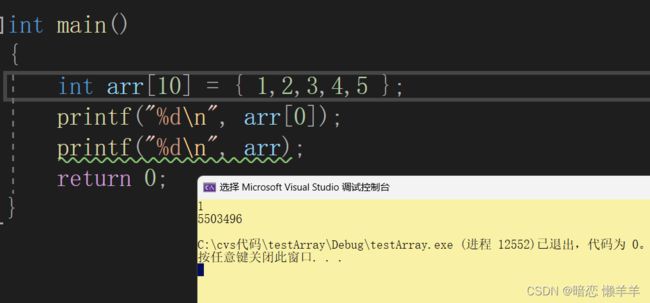
这好像相差甚远!!!我看了一下警告:
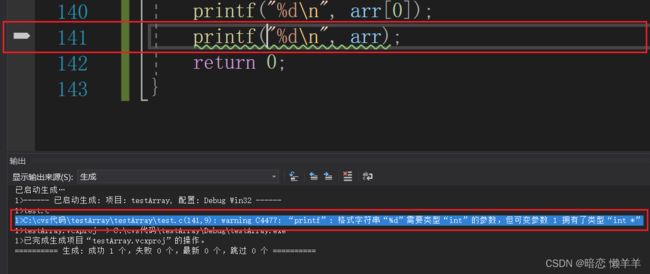 意思就是说arr不是数组首元素他是一个指针!指针是一个16进制数%d是以十进制打印所以是一个很大的数!那么他不是数组首元素,他会不会是数组首元素的地址(指针)呢?继续进行验证:
意思就是说arr不是数组首元素他是一个指针!指针是一个16进制数%d是以十进制打印所以是一个很大的数!那么他不是数组首元素,他会不会是数组首元素的地址(指针)呢?继续进行验证:
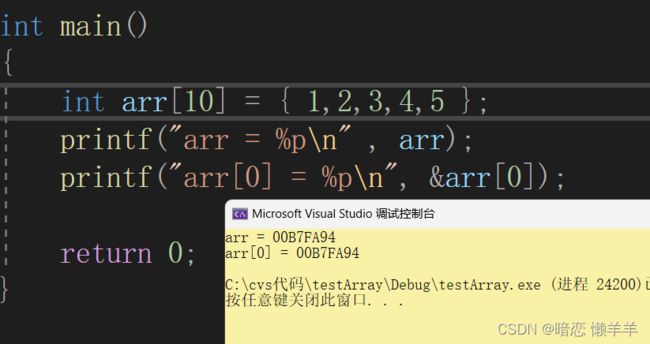
打印的地址一样,这就说明了数组名代表的是数组首元素的地址!那他代表数组首元素的地址(指针),对他解引用操作后打印的值应该与arr[0];的值一样:
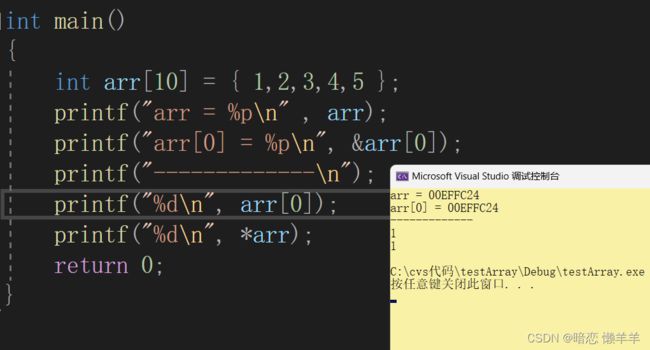
ok!数组名代表数组首元素的这一点可以完全确定了!那也就能解释sz = 1了,arr是数组首元素的地址,而指针的大小是4/8个字节(32位平台4,64位平台8);小编的是32位平台,所以是4,然后再用4/sizeof(arr[0])----->arr的每个元素都是int 类型的4个字节!所以sz =1; 那它任何时候都代表数组首元素的地址吗?答案是不一定!有两种特殊情况!
1 . sizeof(数组名),计算的是整个数组的大小,sizeof内部单独放一个数组名时,此时数组名代表整个数组!
2 . &数组名,取出的是数组的地址。&数组名,数组名代表的时整个数组!
int main()
{
int arr[10] = { 1,2,3,4,5 };
printf("sizeof(arr) = %d\n", sizeof(arr));//40
printf("&arr = %p\n", &arr);
printf("&arr+1 = %p\n", &arr+1);
printf("&arr[0] = %p\n", &arr[0]);
printf("&arr[0] + 1 = %p\n", &arr[0]+1);
return 0;
}运行结果:

到这里就能改正上面的那个错误的冒泡排序了:
既然传过去的时指针,不能计算准确的数组大小,那不如就在冒泡函数以外算好,直接传过去!就OK了:
void Bubble_sort(int arr[],int sz)
{
int i = 0;
for (i = 0; i < sz - 1; i++)
{
int j = 0;
for (j = 0; j < sz - 1 - i; j++)
{
if (arr[j] > arr[j + 1])
{
int temp = arr[j];
arr[j] = arr[j + 1];
arr[j + 1] = temp;
}
}
}
}
int main()
{
int arr[] = { 1,3,5,7,9,8,6,4,2,0 };
int sz = sizeof(arr) / sizeof(arr[0]);
Bubble_sort(arr,sz);
int i = 0;
for (i = 0; i < sizeof(arr)/sizeof(arr[0]); i++)
{
printf("%d ", arr[i]);
}
return 0;
}运行结果:

这样就OK了!!!
好兄弟下期再见!!