JavaEE期末复习
目录
- mybaits:
-
- 1.1
- 1.2
- 1.3 动态SQL
- 1.4
- 第四章
-
- 4.2 一对一查询
-
- 4.2.1 嵌套查询方式
- 4.2.2嵌套结果方式
- 4.2.3 总结
- 4.3 一对多查询
-
- 4.3.1 嵌套查询方式
- 4.3.2 嵌套结果方式
- 4.4 多对多查询
- 4.5 一级缓存
- 第五章
-
- 5.1 基于注解的单表增删改查
-
- 5.1.1 @Select注解
- 5.1.2 @Insert注解
- 5.1.3 @Update注解
- 5.1.4 @Delete注解
- 5.1.5 @Param注解
- 5.2 基于注解的关联查询
- 第六章
-
- 6.1 Spring介绍
-
- 6.1.1 Spring概述
-
- String框架的核心技术
- String在表现层、业务逻辑层和持久层的作用
- 6.1.2 Spring框架的优点
-
- 非侵入式设计
- 降低耦合性
- 支持AOP编程
- 支持声明式事务
- 方便程序的测试
- 方便集成框架
- 降低Java EE API的使用难度
- 6.1.3 Spring的体系结构
- 6.1.5 Spring的下载及目录结构
- 6.2 Spring的入门程序
- 6.3 控制反转与依赖注入
-
- 6.3.1 控制反转
- 6.3.2 依赖注入(Dependency Inject,缩写DI)
- 6.3.3依赖注入和控制反转的比较(最重要)
- 6.3.4 依赖注入的类型
- 6.3.5 依赖注入的应用
- 第七章 Spring中的Bean的管理
-
-
- 7.1.1 BeanFactory接口
- 7.1.2 ApplicationContext接口
- 7.4 Bean的作用域
-
- 7.4.1 singleton作用域
- 7.4.2 prototype作用域
- 7.5 Bean的装配方式
-
- 7.5.1 基于XML的装配
- 7.5.1.1 属性setter方法注入
- 7.5.1.2 构造方法注入
- 7.5.2 基于注解的装配
-
- 7.5.2.1 XML与注解装配的比较
- 7.5.2.2 Spring的常用注解
- 7.5.3 自动装配
- 7.6 Bean的生命周期
-
- 第8章 Spring AOP
-
- 8.1Spring AOP介绍
-
- 8.1.1 AOP面向切面编程的优势
- 8.1.2 Spring AOP术语
- 8.2 Spring AOP的实现机制
-
- 8.2.1 JDK动态代理(不用怎么管)
- 8.3 基于XML的AOP实现
-
- 8.3.1 使用AOP代理对象的好处
- 8.3.2 Spring提供了一系列配置Spring AOP的XML元素。
-
- 8.3.3
- 8.3.3
- 8.4 基于注解的AOP实现
- 第9章 Spring的数据库编程
-
- 9.1Spring JDBC
- 9.2 JDBCTemplate的增删改查操作
-
- 配置文件
- 9.2.1 excute()方法
- 9.2.2 update()方法
- 9.2.3 query()方法
- 9.3 Spring事务管理概述(*)
-
- 9.3.1 事务管理的核心接口
- 9.3.2 事务管理的方式
- 9.4 声明式事务管理(*)
-
- 9.4.1 基于XML方式的声明式事务
- 9.4.2 基于注解方式的声明式事务
- 第10章 初识Spring MVC框架
-
-
- 10.1.1 Spring MVC概述(简答*)
- 10.1.2 Spring MVC特点
- 10.2 Spring MVC入门程序
- 10.3 Spring MVC工作原理(*)
-
- 第11章 Spring MVC的核心类和注解
-
- 11.1 DispatcherServlet(前端控制器*)
- 11.2 @Controller注解
- 11.3 @RequestMapping注解
-
- 11.3.1 @RequestMapping注解的使用
- 11.3.2 @RequestMapping注解的属性
- 11.3.3 请求映射方式
-
- 基于请求方式的URL路径映射
- Ant风格通配符的路径匹配
- 基于RESTful风格的URL路径映射
- 使用RESTful风格的优势
- 第12章 Spring MVC数据绑定和响应
-
- 12.1 数据绑定
- 12.2 简单数据绑定
-
- 12.2.1 默认类型数据绑定
- 12.2.2 简单数据类型绑定
- 12.2.3 POJO绑定
- 12.2.4 自定义类型转换器
- 12.3 复杂数据绑定
-
- 12.3.1 数组绑定
- 12.3.3 复杂POJO绑定
-
- 复杂POJO数组绑定的格式
- 属性为List类型的数据绑定
- 12.3.4 JSON数据绑定
- 12.4 页面跳转
-
-
- 12.4.1 返回值为void类型的页面跳转到默认页面
- 12.4.2 返回值为String类型的页面跳转
-
- 12.5 数据回写
- 第13章 Spring MVC的高级功能
-
- 13.1异常处理(HandlerExceptionResolver)
-
- 13.1.2 自定义异常处理器(resolveException()方法)
- 13.1.3 异常处理注解(@ControllerAdvice注解)
- 13.2 拦截器
- 第14章 SSM框架整合
- 配置文件
mybaits:
1.1
早期javaee开发使用jsp+servlet缺点:1.软件应用和系统可维护性差 2.代码重用性低
框架优势:1.提高开发效率 2.提高代码规范性和可维护性 3.提高软件性能
主要框架:…
spring框架:分层架构、以POJO为对象提供企业级别的服务
spring MVC框架:Web开发框架、作为控制器,有更强的扩展性和灵活性。
MyBatis:持久层框架,它可以在实体类和SQL语句之间建立映射关系,是一种半自动化的ORM(对象/关系映射)实现。
1.2
JDBC的缺点:…
什么是mybaits:MyBatis是一个支持普通SQL查询、存储过程以及高级映射的持久层框架,
它消除了几乎所有的JDBC代码和参数的手动设置以及对结果集的检索,
使用简单的XML或注解进行配置和原始映射,
将接口和Java的POJO映射成数据库中的记录,
使得Java开发人员可以使用面向对象的编程思想来操作数据库。
ORM框架工作原理:
ppt25页
Mybatis工作原理:
PPT49页
工作原理步骤:
MyBatis框架在操作数据库时,大体经过了8个步骤。下面结合MyBatis工作原理图对每一步流程进行详细讲解,具体如下。
(1)MyBatis读取核心配置文件mybatis-config.xml:mybatis-config.xml核心配置文件主要配置了MyBatis的运行环境等信息。
(2)加载映射文件Mapper.xml:Mapper.xml文件即SQL映射文件,该文件配置了操作数据库的SQL语句,需要在mybatis-config.xml中加载才能执行。
(3)构造会话工厂:通过MyBatis的环境等配置信息构建会话工厂SqlSessionFactory,用于创建SqlSession。
(4)创建SqlSession对象:由会话工厂SqlSessionFactory创建SqlSession对象,该对象中包含了执行SQL语句的所有方法。
(5)动态生成SQL语句:MyBatis底层定义了一个Executor接口用于操作数据库,它会根据SqlSession传递的参数动态的生成需要执行的SQL语句,同时负责查询缓存地维护。
(6)MappedStatement对象将传入的Java对象映射到SQL语句中:SqlSession内部通过执行器Executor操作数据库,增删改语句通过Executor接口的update()方法执行,查询语句通过query()方法执行。这两个执行方法中包含一个MappedStatement类型的参数,该参数是对映射信息的封装,存储了要映射的SQL语句的id、参数等。Mapper.xml文件中一个SQL语句对应一个MappedStatement对象,SQL语句的id即是MappedStatement的id。
(7)输入参数映射:在执行Executor类的update()方法和query()方法时,MappedStatement对象会对用户执行SQL语句时输入的参数进行定义,Executor执行器会在执行SQL语句之前,通过MappedStatement对象将输入的参数映射到SQL语句中。Executor执行器对输入参数的映射过程类似于JDBC编程对PreparedStatement对象设置参数的过程。
(8)输出结果映射:excutor()方法在数据库中执行完SQL语句后,MappedStatement对象会对输出的结果进行定义,Executor执行器会在执行SQL语句之后,通过MappedStatement对象将输出结果映射至Java对象中。Executor执行器将输出结果映射到Java对象的过程类似于JDBC编程对结果的解析处理过程。
SqlSessionFactory的build()方法有三种形式:
SqlSessionFactory是线程安全的,一但被创建整个执行期间都存在
一个数据库都只创建一个SqlSessionFactory对象,通常使用单例模式
SqlSession是Mybatis框架中的另一个重要对象,是程序与持久层之间执行交互操作的单线程对象,主要作用–执行持久化操作;可执行已映射的SQL语句。
每个线程都有一个自己的SqlSession对象,不能被共享。是线程不安全的;绝对不能放在类的静态字段、对象字段或者任何类型的管理范围中使用。使用完要释放。
主要元素:
根元素
需要注意的是,在核心配置文件中,的子元素必须按照上图由上到下的顺序进行配置,否则MyBatis在解析XML配置文件的时候会报错。
配置属性的元素,作用为读取外部文件的配置信息。
开启缓存和开启延迟加载
方式一:在元素下,使用多个元素为每一个全限定类逐个配置别名。
方式二:通过自动扫描包的形式自定义别名。
mybatis为常见java类型提供了默认别名,不区分大小写
可以配置多套运行环境 一对一 包括事物管理器和数据源
因为在项目中使用spring+Mybatis 所以没必要配置Mybatis的事物管理器
1.使用类路径引入映射文件
2.使用本地文件路径引入
3.使用接口类引入
4.使用包名引入
namespace的作用:
1.区分不同的mapper,全局唯一
2.面向接口编程,namespace必须是接口的全路径
定义可重用的SQL代码片段
结果映射集
1.3 动态SQL
多个选项选择一个执行 : 在使用元素进行字段信息更新时,要确保传入的更新字段不能都为空 : 的值为必须的 若入参为单参数且参数类型是一个List,collection属性值为list。 若入参为单参数且参数类型是一个数组,collection属性值为array。 若传入参数为多参数,就需要把参数封装为一个Map进行处理,collection属性值为Map。若传入参数为多参数,就需要把参数封装为一个Map进行处理,collection属性值为Map。 #{id}
#{id}
#{roleMap}
1.4
一对一:就是在本类中定义与之关联的类的对象作为属性,例如,A类中定义B类对象b作为属性,在B类中定义A类对象a作为属性。
一对多: 就是一个A类对象对应多个B类对象的情况,例如,定义在A类中,定义一个B类对象的集合作为A类的属性;在B类中,定义A类对象a作为B类的属性。
多对多:在两个相互关联的类中,都可以定义多个与之关联的类的对象。例如,在A类中定义B类类型的集合作为属性,在B类中定义A类类型的集合作为属性。
:的子元素
a.嵌套查询:
SELECT * FROM tb_person WHERE id =1tb_person
SELECT * FROM tb_idcard WHERE id =1
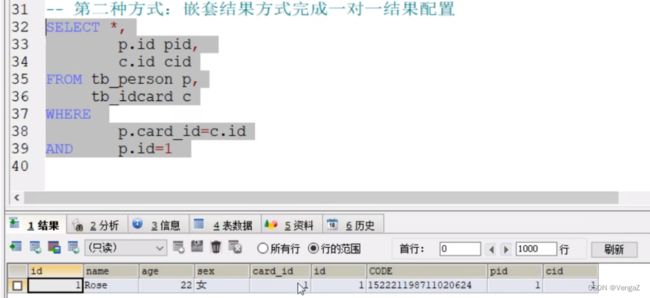
b.嵌套结果:
SELECT *
FROM tb_person p
tb_idcard c
WHERE
p.card_id = c.id
AND p.id =1
User{
private List orderList
}
1.5 SqlSession级别-1级缓存,如:执行了查询,后面如果没有增删改(如果有会情况一级缓存),第二次则直接读取第一次缓存的数据,而不是查询数据库。
1.6
接口类 表名+Mapper
@SELECT
public interface WorkerMapper {
@Select(“select * from tb_worker where id = #{id}”)
Worker selectWorker(int id);
}
测试:
WorkerMapper mapper = session.getMapper(WorkerMapper.class);
Worker worker = mapper.selectWorker(1);
@INSERT
@Insert(“insert into tb_worker(name,age,sex,worker_id)”
+“values(#{name},#{age},#{sex},#{worker_id})”)
int insertWorker(Worker worker);
Worker worker = new Worker();
worker.set属性
WorkerMapper mapper = session.getMapper(WorkerMapper.class);
int result = mapper.insertWorker(worker);
// 输出语句省略…
session.commit();
session.close();
@UPDATE
类似添加
@DELETE
类似查 但是需要session.commit();
同时可以通过result返回的值判断是否删除成功
int result = mapper.deleteWorker(4);
if(result>0){
System.out.println(“成功删除”+result+“条数据”);
}
@PARAM-制定SQL语句中的参数
如:@Select(“select * from tb_worker where id = #{param01}
and name = #{param02}”)
Worker selectWorkerByIdAndName(@Param(“param01”) int id,
@Param(“param02”) String name);
一对一:
多表查询要拆成多条查询
同时在Person类中要定义 private IdCard card;
@ONE:
package com.itheima.dao;
import com.itheima.pojo.IdCard;
import org.apache.ibatis.annotations.Select;
public interface IdCardMapper {
@Select(“select * from tb_idcard where id=#{id}”)
IdCard selectIdCardById(int id);
}
package com.itheima.dao;
public interface PersonMapper {
@Select(“select * from tb_person where id=#{id}”)
@Results({@Result(column = “card_id”,property = “card”,
one = @One(select = “com.itheima.dao.IdCardMapper.selectIdCardById”))})
Person selectPersonById(int id);
}
@MANY:
需要
User{
private List orderList
}
public interface OrdersMapper {
@Select("select * from tb_orders where user_id=#{id} ")
@Results({@Result(id = true,column = “id”,property = “id”),
@Result(column = “number”,property = “number”) })
List selectOrdersByUserId(int user_id);
}
public interface UsersMapper {
@Select("select * from tb_user where id=#{id} ")
@Results({@Result(id = true,column = “id”,property = “id”),
@Result(column = “username”,property = “username”),
@Result(column = “address”,property = “address”),
@Result(column = “id”,property = “ordersList”,
many = @Many(select = “com.itheima.dao.OrdersMapper.selectOrdersByUserId”))})
Users selectUserById(int id);
}
第四章
4.2 一对一查询
掌握一对一查询,能够使用元素实现一对一关联关系
在MyBatis中,通过元素来处理一对一关联关系。元素提供了一系列属性用于维护数据表之间的关系。

4.2.1 嵌套查询方式

需求:根据人的id查询人的信息以及对应的身份证信息
以上一次查询的结果中的数据到另一张表中查询相关信息
- 首先持久化类,用于封装属性(idcard为示例,person类同理)


- 映射文件XXMapper.xml

- 最重要的是人员持有idcard,也就是第一次查询的表的结果集映射
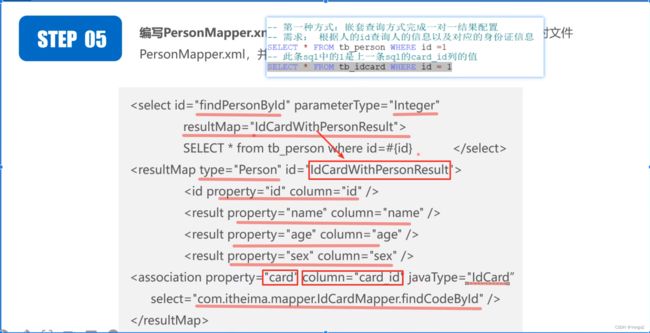
- 结果集映射(resultMap 映射),先映射单表查询的结果集映射,然后针对一对一的属性进行子查询映射,主要是属性的值来自一个sql查询,以及这条sql传参。
- 主键使用id标签来配置,非主键列使用result标签,association来配置一对一映射;
property对应的是程序里定义的属性名,column对应的数据库里的列名也就是属性名。 - javaType对应实体类

association属性里的 property对应的是程序里定义的,是一个定义的类的实例,嵌套查询,外键;column对应的数据库里的列名也就是属性名,后边还要跟一个javaType,是里边定义的类
- 引入映射文件:在核心配置文件mybatis-config.xml中,引入IdCardMapper.xml和PersonMapper.xml映射文件,并为com.itheima.pojo包下的所有实体类定义别名。

- 编写测试类:在测试类MyBatisTest中,编写测试方法findPersonByIdTest()。
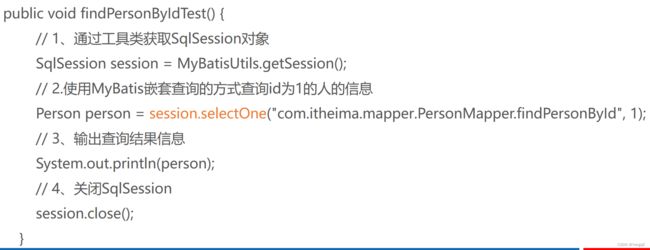
4.2.2嵌套结果方式


4.2.3 总结
嵌套查询方式需要执行两条sql,效率更低;而嵌套结果集方式只需要一条sql,效率更高,后者更加主流。
4.3 一对多查询
- 掌握一对多查询,能够使用****元素实现一对多关联关系
- 在MyBatis中,通过元素来处理一对多关联关系。元素的属性大部分与元素相同,但其还包含一个特殊属性一ofType。ofType属性与javaType属性对应,它用于指定实体类对象中集合类属性所包含的元素的类型。
4.3.1 嵌套查询方式

4.3.2 嵌套结果方式


javaType = “list” ; ofType = “orders”
4.4 多对多查询
4.5 一级缓存
- MyBatis的一级缓存是SqlSession级别的缓存。如果同一个SqlSession对象多次执行完全相同的SQL语句时,在第一次执行完成后,MyBatis会将查询结果写入到一级缓存(内存)中,此后,如果程序没有执行插入、更新、删除操作,当第二次执行相同的查询语句时,MyBatis会直接读取一级缓存中的数据,而不用再去数据库查询,从而提高了数据库的查询效率。

普通的Mapper
resultType

第五章
5.1 基于注解的单表增删改查
实际开发中,大量的XML配置文件的编写是非常繁琐的,为此,MyBatis提供了更加简便的基于注解的配置方式。本章将对MyBatis的注解开发进行详细讲解。
5.1.1 @Select注解
-
创建POJO

-
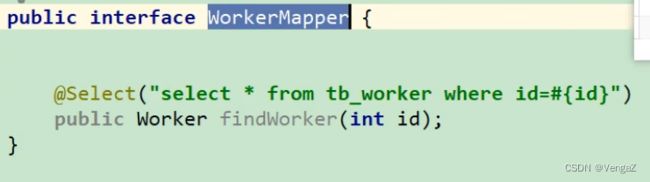
在dao包中编写,表名+Mapper的接口文件

-
加载配置文件,在mybatis-config.xml中引入这个接口,
注意是
class=“com.itheima.dao.WorkerMapper”/>
而不是
mapper resource=“com/itheima/mapper/BookMapper.xml”/

- 编写测试方法
最主要的:
WorkerMapper mapper = session.getMapper(WorkerMapper.class);
// 2.查询id为1的员工信息
Worker worker = mapper.selectWorker(1);


5.1.2 @Insert注解



5.1.3 @Update注解



5.1.4 @Delete注解



5.1.5 @Param注解
运用该注解制定SQL语句中的参数


5.2 基于注解的关联查询
第六章
Spring具有良好的设计和分层结构,它克服了传统重量型框架臃肿、低效的劣势,大大简化了项目开发中的技术复杂性。
6.1 Spring介绍
6.1.1 Spring概述
String框架的核心技术
Spring是由Rod Johnson组织和开发的一个分层的Java SE/EE一站式(full-stack)轻量级开源框架。它最为核心的理念是IoC(控制反转)和AOP(面向切面编程),其中,IoC是Spring的基础,它支撑着Spring对JavaBean的管理功能;AOP是Spring 的重要特性,AOP是通过预编译方式和运行期间动态代理实现程序功能,也就是说可以在不修改源代码的情况下,给程序统一添加功能。
String在表现层、业务逻辑层和持久层的作用
(1)在表现层(WEB)它提供了Spring MVC框架,并且Spring还可以与Struts
框架整合。
(2)在业务逻辑层(Service)可以管理事务、记录日志等。
(3)在持久层(Dao)可以整合MyBatis、Hibernate、JdbcTemplate等技术。
6.1.2 Spring框架的优点
非侵入式设计
Spring是一种非侵入式(non-invasive)框架,所谓非侵入式是指Spring框架的API不会在业务逻辑上出现,也就是说业务逻辑应该是纯净的,不能出现与业务逻辑无关的代码。由于业务逻辑中没有Spring的API,所以业务逻辑代码也可以从Spring框架快速地移植到其他框架。
降低耦合性
Spring就是一个大工厂,可以将所有对象的创建和依赖关系的维护工作都交给Spring容器管理,大大降低了组件之间的耦合性。
支持AOP编程
Spring提供了对AOP的支持,AOP可以将一些与核心业务无关的通用任务进行集中处理,如安全、事务和日志等,以减少通过传统OOP方法带来的代码冗余和繁杂。(非侵入式的一个体现)
支持声明式事务
在Spring中,可以直接通过Spring配置文件管理数据库事务(例如注解开发),省去了手动编程的繁琐,提高了开发效率。
方便程序的测试
Spring提供了对Junit的支持,开发人员可以通过Junit进行单元测试。
方便集成框架
Spring提供了一个广阔的基础平台,其内部提供了对各种框架的直接支持,如Struts、Hibernate、MyBatis、Quartz等,这些优秀框架可以与Spring无缝集成。(主要基于Spring的Ioc思想)
降低Java EE API的使用难度
Spring对Java EE开发中的一些API(如JDBC、JavaMail等)都进行了封装,大大降低了这些API的使用难度。(例如JDBC的封装,简短的代码就能完成相应的效果)
6.1.3 Spring的体系结构

6.1.5 Spring的下载及目录结构

6.2 Spring的入门程序



6.3 控制反转与依赖注入
6.3.1 控制反转
(Inversion of Control,缩写为IoC)是面向对象编程中的一个设计原则,用来降低程序代码之间的耦合度。在传统面向对象编程中,获取对象的方式是用new关键字主动创建一个对象,也就是说应用程序掌握着对象的控制权。
IoC控制反转机制指的是对象由Ioc容器统一管理,当程序需要使用对象时,可以直接从IoC容器中获取。这样对象的控制权就从应用程序转移到了IoC容器。
它是借助于IoC容器实现具有依赖关系对象之间的解耦,各个对象类封装之后,通过IoC容器来关联这些对象类。
6.3.2 依赖注入(Dependency Inject,缩写DI)
就是由IoC容器在运行期间动态地将某种依赖资源注入对象之中。例如,将对象B注入(赋值)给对象A的成员变量。依赖注入的基本思想是:明确地定义组件接口,独立开发各个组件,然后根据组件的依赖关系组装运行。
6.3.3依赖注入和控制反转的比较(最重要)
依赖注入(DI)和控制反转(IoC)是从不同角度来描述了同一件事情。依赖注入是从应用程序的角度描述,即应用程序依赖IoC容器创建并注入它所需要的外部资源;而控制反转是从IoC容器的角度描述,即IoC容器控制应用程序,由IoC容器反向地向应用程序注入应用程序所需要的外部资源。这里所说的外部资源可以是外部实例对象,也可以是外部文件对象等。
6.3.4 依赖注入的类型
依赖注入的作用就是在使用Spring框架创建对象时,动态的将其所依赖的对象注入到Bean组件中。依赖注入通常有两种实现方式,一种是构造方法注入,另一种是属性setter方法注入。这两种实现方式具体介绍如下。
依赖注入的实现方式
- 依赖注入的类型
构造方法注入是指Spring容器调用构造方法注入被依赖的实例,构造方法可以是有参的或者是无参的。Spring在读取配置信息后,会通过反射方式调用实例的构造方法,如果是有参构造方法,可以在构造方法中传入所需的参数值,最后创建类对象。



一个元素表示构造方法的一个参数,且定义时不区分顺序,只需要通过constructor-arg>元素的name属性指定参数即可。元素还提供了type属性类指定参数的类型(此时类型一样的要保证顺序),避免字符串和基本数据类型的混淆。
- 属性setter方法注入
属性setter方法注入是Spring最主流的注入方法,这种注入方法简单、直观,它是在被注入的类中声明一个setter方法,通过setter方法的参数注入对应的值。
不一样的地方:property name = “里边是set方法去掉set关键字的名字,但是要考虑驼峰命名法”
ref是给引用型命名的


6.3.5 依赖注入的应用






// 加载applicationContext.xml配置
ApplicationContext ac=new ClassPathXmlApplicationContext("applicationContext.xml");
UserService userService=(UserService) // 获取配置中的UserService实例
ac.getBean("userService");
boolean flag =userService.login("张三","123");
第七章 Spring中的Bean的管理
第6章详细讲解了控制反转Ioc和依赖注入Di,它们实现了组件的实例化不再由应用程序完成,转而交由Spring容器(Spring注册Bean java类)完成,从而将组件之间的依赖关系进行了解耦。控制反转和依赖注入都是通过Bean实现的,Bean是注册到Spring容器中的Java类,任何一个Java类都可以是一个Bean。Bean由Spring进行管理。
7.1.1 BeanFactory接口

Spring提供了几个BeanFactory接口的实现类,其中最常用的是XmlBeanFactory,它可以读取XML文件并根据XML文件中的配置信息生成BeanFactory接口的实例,BeanFactory接口的实例用于管理Bean。XmlBeanFactory类读取XML文件生成BeanFactory接口实例的具体语法格式如下。
BeanFactory beanFactory=new XmlBeanFactory
(new FileSystemResource(”D:/bean.xml”));
BeanFactory 默认第一次获取对象时,创建对象
7.1.2 ApplicationContext接口
ApplicationContext接口(是BeanFactory接口的一个子接口,在容器初始化时就创建bean了)可以为单例的Bean实行预初始化,并根据元素执行setter方法,单例的Bean可以直接使用,提升了程序获取Bean实例的性能,以及有一个错误预警的功能。

ApplicationContext ac=new ClassPathXmlApplicationContext("applicationContext.xml");
7.4 Bean的作用域

7.4.1 singleton作用域
bean id=“bean1” class=“com.itheima.Bean1” scope=“singleton”>

两次获取的是同一个对象,节省内存提升性能,在不存在线程安全的考虑
7.4.2 prototype作用域
scope=“prototype”
每次从Spring中获取Bean都是获取一个新的对象
企业开发中优先使用 singleton
7.5 Bean的装配方式
7.5.1 基于XML的装配
装配其实就是DI也就是依赖注入。
在基于XML的装配就是读取XML配置文件中的信息完成依赖注入,Spring容器提供了两种基于XML的装配方式,属性setter方法注入和构造方法注入。下面分别对这两种装配方式进行介绍。
7.5.1.1 属性setter方法注入
属性setter方法注入要求一个Bean必须满足以下两点要求。
(1)Bean类必须提供一个默认的无参构造方法。
(2)Bean类必须为需要注入的属性提供对应的setter方法。


7.5.1.2 构造方法注入
使用构造方法注入时,在配置文件里,需要使用**元素的子元素来定义构造方法的参数**,例如,可以使用其value属性(或子元素)来设置该参数的值。

7.5.2 基于注解的装配
7.5.2.1 XML与注解装配的比较
在Spring中,使用XML配置文件可以实现Bean的装配工作,但在实际开发中如果Bean的数量较多,会导致XML配置文件过于臃肿,给后期维护和升级带来一定的困难。为解决此问题,Spring提供了注解,通过注解也可以实现Bean的装配。
7.5.2.2 Spring的常用注解

1. 启动Bean的自动扫描功能
![]()
@Component(“user”)
@Scope(“singleton”)
@Value(“1”)
private int id;


@Repository(“userDao”)

不用注解:


@Service(“userService”)
//使用@Resource注解注入UserDao
@Resource(name=“userDao”)

不用注解:

@Controller
//使用@Resource注解注入UserService
@Resource(name=“userService”)

7.5.3 自动装配
![]()

只能有一个这样的类型,要是有多个则报错

7.6 Bean的生命周期
Bean的生命周期是指Bean实例被创建、初始化和销毁的过程。在Bean的两种作用域singleton和prototype中,Spring容器对Bean的生命周期的管理是不同的。在singleton作用域中,Spring容器可以管理Bean的生命周期,控制着Bean的创建、初始化和销毁。在prototype作用域中, Spring容器只负责创建Bean实例,不会管理其生命周期。
在Bean的生命周期中,有两个时间节点尤为重要,这两个时间节点分别是Bean实例初始化后和Bean实例销毁前,在这两个时间节点通常需要完成一些指定操作。

第8章 Spring AOP
8.1Spring AOP介绍
8.1.1 AOP面向切面编程的优势
- AOP的全称是Aspect Oriented Programming,即面向切面编程。和OOP不同,AOP主张将程序中相同的业务逻辑进行横向隔离,并将重复的业务逻辑抽取到一个独立的模块中,以达到提高程序可重用性和开发效率的目的。
- 在传统的业务处理代码中,通常都会进行事务处理、日志记录(与具体业务无关,但是要嵌入业务里边)等操作。虽然使用OOP可以通过组合或者继承的方式来达到代码的重用,但如果要实现某个功能(如日志记录),同样的代码仍然会分散到各个方法中。
- AOP可以将事务管理的业务逻辑从这三个方法体中抽取到一个可重用的模块,进而降低横向业务逻辑之间的耦合,减少重复代码。AOP的使用,使开发人员在编写业务逻辑时可以专心于核心业务,而不用过多地关注其他业务逻辑的实现,不但提高了开发效率,又增强了代码的可维护性。
8.1.2 Spring AOP术语




8.2 Spring AOP的实现机制
8.2.1 JDK动态代理(不用怎么管)
默认情况下,Spring AOP使用JDK动态代理,JDK动态代理是通过java.lang.reflect.Proxy 类实现的,可以调用Proxy类的newProxyInstance()方法创建代理对象。无侵入式的代码扩展,并且可以在不修改源代码的情况下,增强某些方法。







8.3 基于XML的AOP实现
8.3.1 使用AOP代理对象的好处
因为Spring AOP中的代理对象由IoC容器自动生成,所以开发者无须过多关注代理对象生成的过程,只需选择连接点、创建切面、定义切点并在XML文件中添加配置信息即可。
8.3.2 Spring提供了一系列配置Spring AOP的XML元素。

配置切面使用的是aop:aspect元素,该元素会将一个已定义好的Spring Bean转换成切面Bean,因此,在使用aop:aspect元素之前,要在配置文件中先定义一个普通的Spring Bean。Spring Bean定义完成后,通过aop:aspect元素的ref属性即可引用该Bean。配置aop:aspect元素时,通常会指定id和ref两个属性。

当aop:pointcut元素作为aop:config元素的子元素定义时,表示该切入点是全局的,它可被多个切面共享;当aop:pointcut元素作为aop:aspect元素的子元素时,表示该切入点只对当前切面有效。定义aop:pointcut元素时,通常会指定id、expression属性。

8.3.3 aop:aspect元素的常用属性

8.4 基于注解的AOP实现

第9章 Spring的数据库编程
9.1Spring JDBC
JdbcTemplate是一个模板类,Spring JDBC中的更高层次的抽象类均在JdbcTemplate模板类的基础上创建。
JdbcTemplate类提供了操作数据库的基本方法,包括添加、删除、查询和更新。在操作数据库时,JdbcTemplate类简化了传统JDBC中的复杂步骤,这可以让开发人员将更多精力投入到业务逻辑中。
DataSource:DataSource主要功能是获取数据库连接。在具体的数据操作中,它还提供对数据库连接的缓冲池和分布式事务的支持。
SQLExceptionTranslator:SQLExceptionTranslator是一个接口,它负责对SQLException异常进行转译工作。
9.2 JDBCTemplate的增删改查操作
配置文件

9.2.1 excute()方法

9.2.2 update()方法





9.2.3 query()方法


9.3 Spring事务管理概述(*)
9.3.1 事务管理的核心接口




都回滚

回滚失败的
![]()
9.3.2 事务管理的方式

9.4 声明式事务管理(*)
9.4.1 基于XML方式的声明式事务
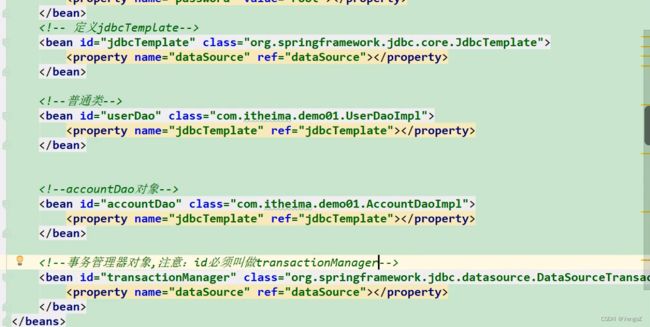





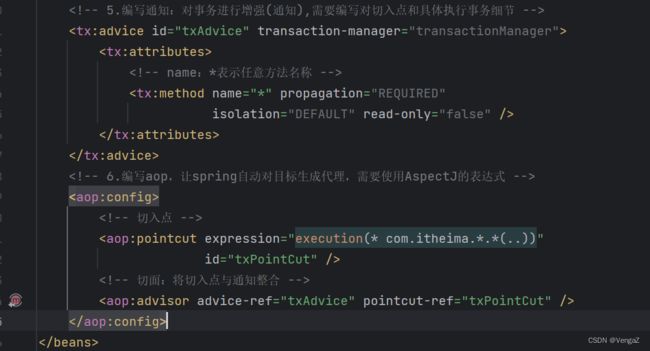
9.4.2 基于注解方式的声明式事务


@Transactional(propagation = Propagation.REQUIRED,
isolation = Isolation.DEFAULT, readOnly = false)

第10章 初识Spring MVC框架

10.1.1 Spring MVC概述(简答*)
系统经典的三层架构包括表现层、业务层和持久层。三层架构中,每一层各司其职,表现层(Web层)负责接收客户端请求,并向客户端响应结果;业务层(Service层)负责业务逻辑处理,和项目需求息息相关;持久层(Dao层)负责和数据库交互,对数据库表进行增删改查。
Spring MVC作用于三层架构中的表现层,用于接收客户端的请求并进行响应。Spring MVC中包含了控制器和视图,控制器接收到客户端的请求后对请求数据进行解析和封装,接着将请求交给业务层处理。业务层会对请求进行处理,最后将处理结果返回给表现层。表现层接收到业务层的处理结果后,再由视图对处理结果进行渲染,渲染完成后响应给客户端。
10.1.2 Spring MVC特点


Spring MVC的前端控制器也是一个Servlet,可以在项目的web.xml文件中进行配置。
10.2 Spring MVC入门程序



10.3 Spring MVC工作原理(*)



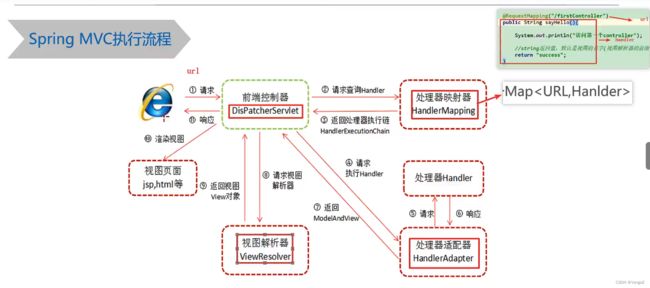
(1)用户通过浏览器向服务器发送请求,请求会被Spring MVC的前端控制器DispatcherServlet拦截。
(2)DispatcherServlet拦截到请求后,会调用HandlerMapping(处理器映射器)。
(3)处理器映射器根据请求URL找到具体的处理器,生成处理器对象及处理器拦截器(如果有则生成)一并返回给DispatcherServlet。
(4)DispatcherServlet会通过返回信息选择合适的HandlerAdapter(处理器适配器)。
(5) HandlerAdapter会调用并执行Handler(处理器),这里的处理器指的就是程序中编写的Controller类,也被称之为后端控制器。
(6)Controller执行完成后,会返回一个ModelAndView对象,该对象中会包含视图名或包含模型和视图名。
(7)HandlerAdapter将ModelAndView对象返回给DispatcherServlet。
(8)前端控制器请求视图解析器根据逻辑视图名解析真正的视图。
(9)ViewResolver解析后,会向DispatcherServlet中返回具体的View(视图)。
(10)DispatcherServlet对View进行渲染(即将模型数据填充至视图中)。
(11)前端控制器向用户响应结果。
在上述执行过程中,DispatcherServlet、HandlerMapping、HandlerAdapter和ViewResolver对象的工作是在框架内部执行的,开发人员只需要配置DispatcherServlet,完成Controller中的业务处理并在视图中(View)中展示相应信息。
第11章 Spring MVC的核心类和注解
11.1 DispatcherServlet(前端控制器*)
DispatcherServlet是Spring MVC的核心类,也是Spring MVC的流程控制中心,也称为Spring MVC的前端控制器,它可以拦截客户端的请求。拦截客户端请求之后,DispatcherServlet会根据具体规则将请求交给其他组件处理。所有请求都要经过DispatcherServlet进行转发处理,这样就降低了Spring MVC组件之间的耦合性。
DispatcherServlet的本质是一个Servlet,可以在web.xml文件中完成它的配置和映射。





11.2 @Controller注解
只需要将@Controller注解标注在普通Java类上,然后通过Spring的扫描机制找到标注了该注解的Java类,该Java类就成为了Spring MVC的处理器类。

11.3 @RequestMapping注解
11.3.1 @RequestMapping注解的使用


http://localhost:8080/firstController


http://localhost:8080/springMVC/firstControll

11.3.2 @RequestMapping注解的属性
-
只有一个value属性时可以省略value
@RequestMapping(value=“/firstController”)
@RequestMapping(“/firstController”) -
value可以映射多个URL,因为是数组,所以会用同样的方式处理
@RequestMapping(value = {“/addUser”,“/deleteUser”})


同样地址,不同处理方式


支持多个请求方式,则需要将请求方式列表存放在英文大括号中,以数组的形式给method属性赋值,并且多个请求方式之间用英文逗号分隔
@RequestMapping(value = “/method”,
method = {RequestMethod.GET,RequestMethod.POST})
11.3.3 请求映射方式
基于请求方式的URL路径映射
Spring MVC组合注解

Ant风格通配符的路径匹配
映射路径中同时使用多个通配符时,会有通配符冲突的情况。当多个通配符冲突时,路径会遵守最长匹配原则

?单字符
/* 对于最后一层可以是任意数量的字符,但是对于其他层只能是不为零的字符数
/** 是零或者任意多
基于RESTful风格的URL路径映射


使用RESTful风格的优势

第12章 Spring MVC数据绑定和响应
12.1 数据绑定
Spring MVC接收到客户端的请求后,会根据客户端请求的参数和请求头等数据信息,将参数以特定的方式转换并绑定到处理器的形参中。Spring MVC中将请求消息数据与处理器的形参建立连接的过程就是Spring MVC的数据绑定。
12.2 简单数据绑定
12.2.1 默认类型数据绑定


12.2.2 简单数据类型绑定
- @RequestParam注解的属性

- @PathVariable注解的使用

12.2.3 POJO绑定


12.2.4 自定义类型转换器
Spring MVC默认提供了一些常用的类型转换器,这些类型转换器,可以将客户端提交的参数自动转换为处理器形参类型的数据。然而默认类型转换器并不能将提交的参数转换为所有的类型。此时,就需要开发者自定义类型转换器,来将参数转换为程序所需要的类型。

12.3 复杂数据绑定
12.3.1 数组绑定
12.3.3 复杂POJO绑定
复杂POJO数组绑定的格式

属性为List类型的数据绑定

12.3.4 JSON数据绑定

12.4 页面跳转
12.4.1 返回值为void类型的页面跳转到默认页面
默认页面的路径由方法映射路径和视图解析器中的前缀、后缀拼接成,拼接格式为“前缀+方法映射路径+后缀”。
12.4.2 返回值为String类型的页面跳转
当Spring MVC方法的返回值为String类型时,控制器方法执行后,Spring MVC会根据方法的返回值跳转到对应的资源。如果Spring MVC的配置文件中没有视图解析器,处理器执行后,会将请求转发到与方法返回值一致的映射路径。

Spring MVC还提供了兼顾视图和数据的对象ModelAndView,ModelAndView对象包含视图相关内容和模型数据两部分,其中视图相关的内容可以设置逻辑视图的名称,也可以设置具体的View实例;模型数据则会在视图渲染过程中被合并到最终的视图输出。
12.5 数据回写
@RestController注解相当于@Controller+@ResponseBody两个注解的结合。
第13章 Spring MVC的高级功能
13.1异常处理(HandlerExceptionResolver)
13.1.2 自定义异常处理器(resolveException()方法)
13.1.3 异常处理注解(@ControllerAdvice注解)

13.2 拦截器
拦截器(Interceptor)是一种动态拦截Controller方法调用的对象,它可以在指定的方法调用前或者调用后,执行预先设定的代码。拦截器作用类似于Filter(过滤器),但是它们的技术归属和拦截内容不同。Filter采用Servlet技术,拦截器采用Spring MVC技术;Filter会对所有的请求进行拦截,拦截器只针对Spring MVC的请求进行拦截。

第14章 SSM框架整合
配置文件
- web.xml

- spring-mvc.xml
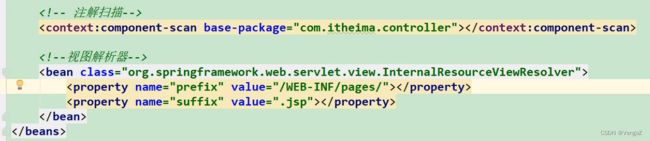
mapper标签里的
namespace属性用于指定映射器接口的全限定名,不是用于设置实体类的全限定类名
