【Python】APScheduler定时调度库
文章目录
-
- APScheduler是什么
- 功能特点
- 四大组件
-
- 触发器[triggers]
-
- date 一次性触发器
- interval 间隔触发器
- cron 周期触发器
- 任务存储器[JobStore]
-
- MemoryJobStore
- MongoDBJobStore
- RedisJobStore
-
- 示例代码
- RethinkDBJobStore
- SQLAlchemyJobStore
- ZooKeeperJobStore
- 执行器[executors]
-
- 线程池执行器[ThreadPoolExecutor]
- 进程池执行器[ProcessPoolExecutor]
- Gevent程序执行器[GeventExecutor]
- Tornado程序执行器[TornadoExecutor]
- Twisted程序执行器[TwistedExecutor]
- asyncio程序执行器[AsyncIOExecutor]
- 调度器[schedulers]
-
- 阻塞式调度器[BlockingScheduler]
- 后台调度器[BackgroundScheduler]
- AsyncIO调度器[AsyncIOScheduler]
- Gevent调度器[GeventScheduler]
- Tornado调度器[TornadoScheduler]
- Twisted调度器[TwistedScheduler]
- Qt调度器[QtScheduler]
- 任务操作
-
- 添加任务一[add_job()]
- 添加任务二[scheduled_job()]
- 移除job任务[remove_job()与job.remove()]
- 暂停/恢复job任务[pause_job()/resume()]
- 获取job列表[get_jobs()]
- 修改job[modify()]
- 开启job[start()]
- 关闭job[shutdown()]
- 给调度器绑定监视器[add_listener()]
- 调度配置
-
- jobstores 用来配置存储器
- executors 用来配置执行器
- job_defaults 创建job时的默认参数
- 示例
APScheduler是什么
APScheduler库提供了强大而灵活的任务调度功能,支持多种调度方式、持久化存储和分布式任务调度等特性,适用于各种复杂任务调度的需求。
pip install apscheduler
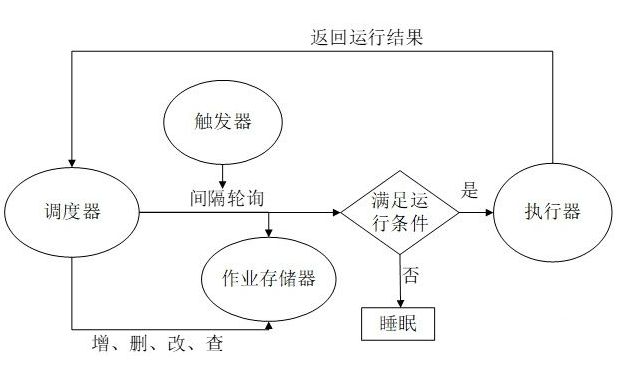
功能特点
- 多种调度方式:
APScheduler支持多种调度方式,包括定时调度、间隔调度、日期调度等。可以根据需求选择适合的调度方式来执行任务。 - 多线程支持:
APScheduler是多线程的,可以同时执行多个任务,不会阻塞其他任务的执行。这使得它适合处理大量任务并提高任务执行效率。 - 持久化存储:
APScheduler支持将任务调度信息存储到数据库中,以保证任务调度信息的持久性。在应用程序重启后,可以从数据库中恢复任务调度状态,避免任务丢失。 - 分布式任务调度:
APScheduler支持分布式任务调度,可以在多台计算机上运行调度器,并使用分布式存储来共享任务调度信息。这使得任务可以在多个节点上协同执行,提高系统的可伸缩性和容错性。 - 任务触发器:
APScheduler提供了灵活的任务触发器,可以根据各种条件来触发任务执行,例如日期、时间间隔、定时表达式、CRON表达式等。这允许用户更精细地控制任务的执行时机。 - 监听器和钩子:
APScheduler支持任务监听器和钩子,可以在任务执行前后执行自定义的操作。这使得用户可以在任务执行过程中添加额外的逻辑,例如日志记录、错误处理等。
四大组件
触发器[triggers]
用于设定触发任务的条件
date 一次性触发器
作业任务只会执行一次。它表示特定的时间点触发。
| 参数 | 说明 |
|---|---|
| run_date (datetime 或 str) | 作业的运行日期或时间 |
| timezone (datetime.tzinfo 或 str) | 指定时区 |
示例
# 在2023年4月15日执行
scheduler.add_job(my_job, 'date', run_date=date(2023, 4, 15), args=['测试任务'])
# datetime类型(用于精确时间)
scheduler.add_job(my_job, 'date', run_date=datetime(2023, 4, 15, 17, 30, 5), args=['测试任务'])
interval 间隔触发器
固定时间间隔触发
| 参数 | 说明 |
|---|---|
| weeks (int) | 间隔几周 |
| days (int) | 间隔几天 |
| hours (int) | 间隔几小时 |
| minutes (int) | 间隔几分钟 |
| seconds (int) | 间隔多少秒 |
| start_date (datetime 或 str) | 开始日期 |
| end_date (datetime 或 str) | 结束日期 |
| timezone (datetime.tzinfo 或str) | 时区 |
| jitter | 触发的时间误差 |
示例
# 每2小时触发
scheduler.add_job(job_func, 'interval', hours=2)
# 在 2023-04-15 17:00:00 ~ 2023-12-31 24:00:00 之间, 每隔两分钟执行一次 job_func 方法
scheduler.add_job(job_func, 'interval', minutes=2, start_date='2023-04-15 17:00:00' , end_date='2023-12-31 24:00:00')
cron 周期触发器
在特定时间周期性地触发,和Linux crontab格式兼容。它是功能最强大的触发器。
| 参数 | 说明 |
|---|---|
| year (int 或 str) | 年,4位数字 |
| month (int 或 str) | 月 (范围1-12或jan–dec) |
| day (int 或 str) | 日 (范围1-31) |
| week (int 或 str) | 周 (范围1-53) |
| day_of_week (int 或 str) | 周内第几天或者星期几 (范围0-6 或者 mon,tue,wed,thu,fri,sat,sun) |
| hour (int 或 str) | 时 (范围0-23) |
| minute (int 或 str) | 分 (范围0-59) |
| second (int 或 str) | 秒 (范围0-59) |
| start_date (datetime 或 str) | 最早开始日期(包含) |
| end_date (datetime 或 str) | 最晚结束时间(包含) |
| timezone (datetime.tzinfo 或str) | 指定时区 |
| jitter | 任务触发的误差时间 |
| 表达式 | 参数类型 | 描述 |
|---|---|---|
* |
所有 | 通配符。例:minutes=*即每分钟触发 |
*/a |
所有 | 可被a整除的通配符。 |
a-b |
所有 | 范围a-b触发 |
a-b/c |
所有 | 范围a-b,且可被c整除时触发 |
xth y [day] |
日 | 第x个星期y触发 |
last x [day] |
日 | 一个月中,最后一个星期x触发 |
last [day] |
日 | 一个月最后一天触发 |
x,y,z |
所有 | 组合表达式,可以组合确定值或上方的表达式 |
示例
# 在每年 1-3、7-9 月份中的每个星期一、二中的 00:00, 01:00, 02:00 和 03:00 执行 job_func 任务
scheduler.add_job(job_func, 'cron', month='1-3,7-9',day='0, tue', hour='0-3')
任务存储器[JobStore]
用于存放任务,把任务存放在内存或数据库中
持久化存储
默认是把任务保存在内存中,持久化是将任务保存在数据库中。
一个任务的数据将在保存在持久化的任务存储之前,会对任务执行序列化操作,当重新读取任务时,再执行反序列化操作。(下面第二部分代码就是用的redis存储)
MemoryJobStore
# 没有序列化,任务存储在内存中,增删改查都在内存中完成
from apscheduler.jobstores.memory import MemoryJobStore
MongoDBJobStore
# 使用mongodb作为存储器
from apscheduler.jobstores.mongodb import MongoDBJobStore
RedisJobStore
# 使用redis作为存储器
from apscheduler.jobstores.redis import RedisJobStore
示例代码
from apscheduler.schedulers.background import BackgroundScheduler
from flask import Flask, make_response
app = Flask(__name__)
jobstores = {
# 用redis作backend
'redis': RedisJobStore(),
}
executors = {
'default': ThreadPoolExecutor(10),#默认线程数
'processpool': ProcessPoolExecutor(3)#默认进程
}
conf = {
"host": "127.0.0.1",
"port": 6379,
"db": 0,
"max_connections": 10
}
job_defaults = {
'coalesce': False,
'max_instances': 3
}
# coalesce:累计的 任务是否执行。True不执行,False,执行。
# 同上,由于某种原因,比如进场挂了,导致任务多次没有调用,则前几次的累计任务的任务是否执行的策略。
# max_instances:同一个任务在线程池中最多跑的实例数。
def my_job():
print('定时任务')
sched = BackgroundScheduler(timezone='MST', jobstores=jobstores, executors=executors)
# 添加redis为作业存储
sched.add_jobstore(jobstore="redis", **conf)
sched.add_job(my_job, 'interval', id='3_second_job', seconds=3,misfire_grace_time=60)
# misfire_grace_time:超过用户设定的时间范围外,该任务依旧执行的时间(单位时间s)。比如用户设置#misfire_grace_time=60,于12:00触发任务。由于某种原因在12:00没有触发,被延时了。如果时间在12:01内,该任务仍能触发,超过3:01任务不执行
@app.route('/start')
def ds():
sched.start()
sched.remove_job('3_second_job') # 删除任务
sched.pause() # 暂定任务
sched.resume() # 恢复任务
return 'ok'
@app.route('/ssst')
def st():
sched.start()
return 'ok'
if __name__ == '__main__':
app.run(host="0.0.0.0", port=5000)
RethinkDBJobStore
SQLAlchemyJobStore
# 使用SQLAlchemy这个ORM框架作为存储方式
from apscheduler.jobstores.sqlalchemy import SQLAlchemyJobStore
ZooKeeperJobStore
执行器[executors]
用于执行任务,可以设定执行模式为单线程或线程池
线程池执行器[ThreadPoolExecutor]
默认执行器
from apscheduler.executors.pool import ThreadPoolExecutor
进程池执行器[ProcessPoolExecutor]
适用于涉及到一些CPU密集计算的操作
from apscheduler.executors.pool import ProcessPoolExecutor
Gevent程序执行器[GeventExecutor]
from apscheduler.executors.gevent import GeventExecutor
Tornado程序执行器[TornadoExecutor]
from apscheduler.executors.tornado import TornadoExecutor
Twisted程序执行器[TwistedExecutor]
from apscheduler.executors.twisted import TwistedExecutor
asyncio程序执行器[AsyncIOExecutor]
from apscheduler.executors.asyncio import AsyncIOExecutor
调度器[schedulers]
把上方三个组件作为参数,通过创建调度器实例来运行
阻塞式调度器[BlockingScheduler]
阻塞式调度器:适用于只跑调度器的程序。
调用start函数会阻塞当前线程,不能立即返回。适用于调度程序时进程中唯一运行的进程
from apscheduler.schedulers.blocking import BlockingScheduler
后台调度器[BackgroundScheduler]
适用于非阻塞的情况,调度器会在后台独立运行。
from apscheduler.schedulers.background import BackgroundScheduler
AsyncIO调度器[AsyncIOScheduler]
适用于应用使用AsnycIO的情况。
from apscheduler.schedulers.asyncio import AsyncIOScheduler
Gevent调度器[GeventScheduler]
适用于应用通过Gevent的情况。
from apscheduler.schedulers.gevent import GeventScheduler
Tornado调度器[TornadoScheduler]
适用于构建Tornado应用。
from apscheduler.schedulers.tornado import TornadoScheduler
Twisted调度器[TwistedScheduler]
适用于构建Twisted应用。
from apscheduler.schedulers.twisted import TwistedScheduler
Qt调度器[QtScheduler]
适用于构建Qt应用。
from apscheduler.schedulers.qt import QtScheduler
任务操作
添加任务一[add_job()]
返回一个
apscheduler.job.Job的实例,可以用来改变或者移除job。如果调度的job在一个持久化的存储器里,当初始化应用程序时,必须要为job定义一个显示的ID并使用replace_existing=True, 否则每次应用程序重启时都会得到那个job的一个新副本
import datetime
from apscheduler.schedulers.blocking import BlockingScheduler
scheduler = BlockingScheduler()
def my_job(text):
print(text)
# datetime类型(用于精确时间)
scheduler.add_job(my_job, 'date', run_date=datetime(2023, 4, 15, 17, 30, 5), args=['测试任务'])
scheduler.start()
添加任务二[scheduled_job()]
只适用于应用运行期间不会改变的job。
import datetime
from apscheduler.schedulers.background import BackgroundScheduler
@scheduler.scheduled_job(job_func, 'interval', minutes=2)
def job_func(text):
print(datetime.datetime.utcnow().strftime("%Y-%m-%d %H:%M:%S.%f")[:-3])
scheduler = BackgroundScheduler()
scheduler.start()
移除job任务[remove_job()与job.remove()]
remove_job()是根据job的id来移除,所以要在job创建的时候指定一个id。job.remove()则是对job执行remove方法即可remove_all_jobs()对scheduler所有任务进行移除
scheduler = BlockingScheduler()
scheduler.add_job(job_func, 'interval', minutes=2, id='job_one')
scheduler.remove_job(job_id="job_one")
# 添加任务并获取Job对象
job = add_job(job_func, 'interval', minutes=2, id='job_one')
# 移除特定的任务
job.remvoe()
# 移除所有的任务
scheduler.remove_all_jobs()
暂停/恢复job任务[pause_job()/resume()]
-
通过job实例
# 暂停job任务 job = scheduler.add_job(func, 'interval', seconds=3, args=["desire"], id="job_remove") job.pause() # 恢复job任务 job = scheduler.add_job(func, 'interval', seconds=3, args=["desire"], id="job_remove") job.resume() -
通过schedule本身
# 暂停job任务 scheduler.add_job(func, 'interval', seconds=3, args=["desire"], id="job_remove") scheduler.pause_job(job_id="job_remove") # 恢复job任务 scheduler.add_job(func, 'interval', seconds=3, args=["desire"], id="job_remove") scheduler.resume_job(job_id="job_remove")
获取job列表[get_jobs()]
获取当前调度器中的所有 job 的列表,返回一个Job实例列表
修改job[modify()]
Job.modify()或者modify_job()方法来修改 job 的属性。但是值得注意的是,job 的 id 是无法被修改的。
# 通过实例修改
job = scheduler.add_job(func, 'interval', seconds=3, args=["desire"], id="job_modify")
job.modify(name="job222")
# 通过job的ID进行修改
scheduler.add_job(my_job, 'interval', minutes=10, id='one')
scheduler.start()
# 将触发时间间隔修改成 5分钟
scheduler.modify_job(job_id='one', minutes=5)
reschedule()、reschedule_job()通过重启调度的方式,对job进行修改
job = scheduler.add_job(func, 'interval', seconds=3, args=["desire"], id="job_modify")
# reschedule
job.reschedule(trigger='cron', minute='*/5')
# reschedule_job
scheduler.reschedule_job(job_id="job_modify", trigger='cron', minute='*/5')
开启job[start()]
scheduler.start(paused=True)
# 如果没有进行过唤醒,也可以对处于暂停状态的调度器执行start操作
关闭job[shutdown()]
默认情况下调度器会等待所有正在运行的作业完成后,关闭所有的调度器和作业存储。如果你不想等待,可以将 wait 选项设置为 False。
scheduler.shutdown()
scheduler.shutdown(wait=false)
给调度器绑定监视器[add_listener()]
def my_listener(event):
if event.exception:
print("任务出错了!!!!!!!!!")
else:
print("任务正常运行。。。。。")
# 绑定事件监听器,当出现异常或者错误的时,进行监听
scheduler.add_listener(my_listener, mask=EVENT_JOB_EXECUTED | EVENT_JOB_ERROR)
调度配置
jobstores 用来配置存储器
jobstores = {
# 用redis作backend
'redis': RedisJobStore(),
}
executors 用来配置执行器
executors = {
'default': ThreadPoolExecutor(10), # 默认线程数
'processpool': ProcessPoolExecutor(3) # 默认进程
}
job_defaults 创建job时的默认参数
job_defaults = {
'coalesce': False,
'max_instances': 3
}
'''
coalesce 是否合并执行
比如由于某个原因导致某个任务积攒了很多次没有执行(比如有一个任务是1分钟跑一次,但是系统原因断了5分钟)
如果 coalesce=True,那么下次恢复运行的时候,会只执行一次,
而如果设置 coalesce=False,那么就不会合并,会5次全部执行。
max_instances 最大实例数
同一个任务同一时间最多只能有n个实例在运行
'''
示例
from apscheduler.schedulers.blocking import BlockingScheduler
from apscheduler.jobstores.sqlalchemy import SQLAlchemyJobStore
from apscheduler.executors.pool import ThreadPoolExecutor
interval_task = {
# 配置存储器
"jobstores": {
# 使用SQLAlchemy进行存储,会自动创建数据库,并创建apscheduler_jobs表
'default': SQLAlchemyJobStore(url="sqlite:///jobs.db")
},
# 配置执行器
"executors": {
# 使用线程池进行执行,最大线程数是20个
'default': ThreadPoolExecutor(20)
},
# 创建job时的默认参数
"job_defaults": {
'coalesce': False, # 是否合并执行
'max_instances': 3 # 最大实例数
}
}
scheduler = BlockingScheduler(**interval_task)