Python番外篇:Python代码生成春联 三种版本
Hello,大家好,我是wangzirui32,今天就是虎年春节了,先祝大家虎虎生威,虎年大吉!愿大家在新的一年里万事如意,心想事成!
文章目录
- 1. 普通版本
-
- 1.1 引入所需模块
- 1.2 生成春联单字图片
- 1.3 拼接单个字图并调整格式
- 1.4 运行代码
- 2. Web版本
-
- 2.1 Flask后台
- 2.2 HTML前端
- 2.3 效果展示
- 3. 爬虫版本
-
- 3.1 引入所需包
- 3.2 获取春联信息
- 3.3 批量生成春联
- 3.4 运行程序
1. 普通版本
思路如下:
- 用户输入一个春联
- 程序接收春联,并分割为单个字
- 对这些字生成背景图
- 将背景拼接,调整格式,就结束了
春联单字背景素材:

字体文件下载:
http://www.diyiziti.com/Download/498
点击页面上的“下载地址”就可以开始下载了,下载完成后,请把它改名为font.ttf,并和上面的素材一样存储到项目文件夹,再创建app.py,开始写代码。
1.1 引入所需模块
from PIL import Image, ImageDraw, ImageFont
PIL安装:
pip install pillow
1.2 生成春联单字图片
这里为了方便,把整个生成春联的流程都放到了create_couplet_image函数下:
def create_couplet_image(content):
sentences = content.split() # 以空格分隔
images = [] # 每个句子图像
font_path = "font.ttf"
font = ImageFont.truetype(font_path, size=150) # 字体大小150
for sentence in sentences:
sentence_images = []
for word in sentence:
word_image = Image.open("bg_image.png")
draw = ImageDraw.Draw(word_image)
draw.text((55, 45), text=word, font=font, direction=None, fill="#000000")
sentence_images.append(word_image.resize((100, 100)))
images.append(sentence_images)
# images的结构:
# images = [句子1, 句子2]
# 句子1 = [字1, 字2, 字3, ....., 字n]
# 句子2同理
# 每个字都是图形对象
1.3 拼接单个字图并调整格式
def create_couplet_image(content):
# .......
# 省略上方代码
height = len(images) * 100 # 高 = 句子数量 * 100
width = len(images[0]) * 100 # 宽 = 句子长度 * 100
# 新建一个图像 背景为白色
couplet_image = Image.new("RGB", (width, height), (255, 255, 255))
# 拼接
x = 0
y = 0
for sentence_image in images:
x = 0
for word_image in sentence_image:
couplet_image.paste(word_image, (x, y)) # 把单个字的图片插入(x, y)的位置
x += 100
y += 100
return couplet_image # 返回图片对象
1.4 运行代码
请在函数之外的文件末尾新增代码:
if __name__ == "__main__":
create_couplet_image(input("请输入春联内容:")).save("couplets.png")
测试:
请输入春联内容:一年好景随春到 四季财源顺意来
春联图片:

这就完成了一个普通版本,如果想进阶学习,可以参考接下来的衍生版本。
2. Web版本
Web版本为普通版本设计了一个外观简洁的网站界面,流程如下:
- 用户访问首页
- 用户输入春联内容
- 用JS脚本提交到后台
- 展示春联图片
- 用户下载后删除
这里涉及到一些前端知识和Flask框架的开发,有兴趣的小伙伴可以继续阅读。
首先,在普通版本的项目文件夹下创建website.py,再创建templates和images文件夹,在templates文件夹下创建index.html。
2.1 Flask后台
website.py:
from app import create_couplet_image
from flask import Flask, render_template, request, abort, make_response
import time
import os
app = Flask(__name__) # 建立Flask应用
# 工作目录 避免路径问题
work_dir = os.path.abspath(os.path.dirname(__file__))
# 首页
@app.route("/")
def index():
return render_template("index.html")
# 生成春联
@app.route("/couplet", methods=['POST']) # 仅支持POST请求
def couplet():
content = request.form.get("content", None, type=str) # 从表单中获取内容
if content:
timestamp = int(time.time())
# 以时间戳作为文件名保存
create_couplet_image(content).save(os.path.join(work_dir, r"images\{}.png".format(timestamp)))
return {"image_id": timestamp} # 返回图片信息
else:
abort(400)
@app.route("/image/" )
def image(id):
try:
with open(os.path.join(work_dir, r"images\{}.png".format(id)), "rb") as img:
image_bytes = img.read() # 读取图片字节
except FileNotFoundError:
abort(404)
else:
# 返回图片
response = make_response(image_bytes)
response.headers['Content-Type'] = 'bytes'
if request.args.get("is_downloading", False, type=bool):
# 删除图片
os.remove(os.path.join(work_dir, r"images\{}.png".format(id)))
return response
if __name__ == "__main__":
app.run()
2.2 HTML前端
index.html:
DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<meta http-equiv="X-UA-Compatible" content="IE=edge">
<meta name="viewport" content="width=device-width, initial-scale=1.0">
<title>生成春联在线系统title>
<script src="https://code.jquery.com/jquery-3.6.0.js">script>
<link rel="stylesheet" href="https://stackpath.bootstrapcdn.com/bootstrap/3.4.1/css/bootstrap.min.css" integrity="sha384-HSMxcRTRxnN+Bdg0JdbxYKrThecOKuH5zCYotlSAcp1+c8xmyTe9GYg1l9a69psu" crossorigin="anonymous">
head>
<body>
<div class="container">
<h1 class="page-header">生成春联在线系统h1>
<script>
image_id = "";
create_couplet = function(){ // js提交到后台
$.ajax({
url: "{{url_for('couplet')}}",
type: "POST",
async: false, // 禁止异步
data: {
content: $("#content").val()
},
success: function(data){
image_id = data.image_id; // 设置image_id的值
}
});
};
show_couplet = function(){ // 展示春联
$("#couplet-form").remove() // 删除表单
var show_couplet_div = $("#show-couplet");
// 信息生成
show_couplet_div.append(' + image_id + '" class="img img-rounded" />');
show_couplet_div.append("
+ image_id + '" class="img img-rounded" />');
show_couplet_div.append("
");
show_couplet_div.append("以上为春联效果图,请查看。
");
show_couplet_div.append("注:下载一次后,服务器便会删除春联文件。
");
show_couplet_div.append("");
show_couplet_div.append(" ")
show_couplet_div.append("");
};
download = function(){ // 下载
window.location.href = "/image/" + image_id + "?is_downloading=1";
};
script>
<form class="form-group" onsubmit="return false;" method="POST" id="couplet-form">
<div class="input-group" style="width: 500px">
<span class="input-group-addon" style="height: 40px;">春联内容:span>
<input type="text" class="form-control" style="height: 40px;" placeholder="两句请用空格隔开......" id="content">
div>
<p style="height: 13px;">p>
<button type="submit" class="btn btn-primary" onclick="create_couplet();show_couplet();">提交button>
form>
<div id="show-couplet">div>
div>
body>
html>
2.3 效果展示
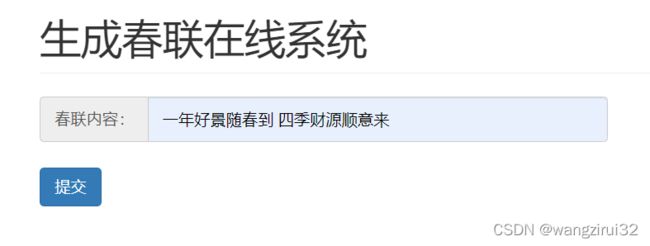

3. 爬虫版本
这个版本我们要运用爬虫技术,自动爬取并生成春联。
思路:
- 获取用户输入的爬取页数
- 调用百度汉语接口获取春联数据
- 解析春联数据,删除干扰的符号
- 将所有春联保存到一个文件夹中
首先,创建crawler.py,创建couplets文件夹存储春联。
3.1 引入所需包
from app import create_couplet_image # 之前app.py文件的生成函数
import requests
import os
requests是用来实现网络请求的库,安装命令:
pip install requests
3.2 获取春联信息
# 工作目录 为了避免出现路径错误
work_dir = os.path.abspath(os.path.dirname(__file__))
# 百度汉语查询接口
url = "https://hanyu.baidu.com/hanyu/ajax/motto_list?wd=春联&device=pc&from=home&ptype=sentence&pn={}"
# 获取春联
def get_couplets(page=1):
response = requests.get(url.format(page)) # 拼接网址并请求
couplets_list = []
for result in response.json()['ret_array']: # 获取结果
couplets_list.append(result['name'][0]) # 春联内容
return couplets_list # 返回数据
3.3 批量生成春联
def create_couplets(couplets):
for i in couplets:
# 过滤一些符号
couplet = i.replace(";", " ") # 注意这里是" "
couplet = couplet.replace(",", "") # 其他都是""
couplet = couplet.replace("。", "")
couplet = couplet.replace("、", "")
# 生成并保存到couplets文件夹
create_couplet_image(couplet).save(os.path.join(work_dir, r"couplets\{}.png".format(couplet)))
3.4 运行程序
请在文件结尾添加:
if __name__ == "__main__":
page = int(input("请输入你想获取的页数:"))
for i in range(1, page+1): # page控制获取页数
create_couplets(get_couplets(i))
运行代码:
请输入你想获取的页数:1
couplets文件夹:

其中一幅春联:

好了,今天的课程就到这里,我是wangzirui32,喜欢的可以点个收藏和关注,我们下次再见!