损失函数——KL散度(Kullback-Leibler Divergence,KL Divergence)
KL散度(Kullback-Leibler Divergence,简称KL散度)是一种度量两个概率分布之间差异的指标,也被称为相对熵(Relative Entropy)。KL散度被广泛应用于信息论、统计学、机器学习和数据科学等领域。
KL散度衡量的是在一个概率分布 �P 中获取信息所需的额外位数相对于使用一个更好的分布 �Q 所需的额外位数的期望值。如果 �P 和 �Q 的概率分布相同,则 KL散度为零,表示两个分布完全相同;如果 �P 和 �Q 的概率分布不同,则 KL散度为正值,表示两个分布的差异程度。
KL散度的数学公式为:
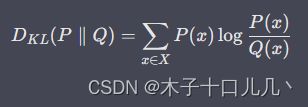
其中,P(x) 和 Q(x) 分别表示事件 x 在概率分布 P 和 Q 中的概率。
需要注意的是,KL散度不满足对称性,即DKL(P∥Q) ≠ DKL(Q∥P)。因此,在实际应用中,我们需要根据具体问题来确定应该使用哪个分布作为参考分布 Q。
在机器学习中,KL散度常常用于衡量两个概率分布之间的差异程度,例如在生成模型中使用 KL散度作为损失函数的一部分,或者在聚类和分类问题中使用 KL散度作为相似度度量。
在 PyTorch 中,可以使用 torch.nn.functional.kl_div 函数来计算 KL散度。具体实现方法如下:
假设有两个概率分布 P 和 Q,其在 PyTorch 中的张量表示为 p_tensor 和 q_tensor,则可以使用以下代码计算 KL散度:
import torch.nn.functional as F
kl_div = F.kl_div(q_tensor.log(), p_tensor, reduction='batchmean')其中,q_tensor.log() 表示对概率分布 Q 中的每个元素取对数;p_tensor 表示概率分布 P 在 PyTorch 中的张量表示;reduction='batchmean' 表示将每个样本的 KL散度求平均值,得到整个 batch 的 KL散度。
需要注意的是,KL散度的计算要求 P 和 Q 的元素都为正数,因此需要在计算前对两个概率分布进行归一化处理,使其元素和为 1。可以使用以下代码实现:
p_tensor = F.softmax(p_tensor, dim=-1)
q_tensor = F.softmax(q_tensor, dim=-1)其中,F.softmax 函数表示对输入张量在指定维度上进行 softmax 归一化操作,使得输出的每个元素均在 0 到 1 之间且元素和为 1。
最终,得到的 kl_div 即为两个概率分布 P 和 Q 之间的 KL散度。
要在训练中使用 KL散度作为损失函数,可以将其作为模型的一部分加入到损失函数的计算中。例如,在 PyTorch 中,可以自定义损失函数来实现 KL散度的计算。具体步骤如下:
1.定义自定义损失函数
import torch.nn.functional as F
import torch.nn as nn
class KLDivLoss(nn.Module):
def __init__(self):
super(KLDivLoss, self).__init__()
def forward(self, p, q):
p = F.softmax(p, dim=-1)
q = F.softmax(q, dim=-1)
loss = F.kl_div(q.log(), p, reduction='batchmean')
return loss在自定义损失函数中,首先将概率分布 P 和 Q 进行归一化处理,然后调用 torch.nn.functional.kl_div 函数计算 KL散度,最后返回 KL散度作为损失函数的值。
2.在训练过程中调用自定义损失函数
import torch.optim as optim
# 初始化模型和优化器
model = MyModel()
optimizer = optim.Adam(model.parameters(), lr=0.001)
# 初始化自定义损失函数
kl_div_loss = KLDivLoss()
# 训练模型
for epoch in range(num_epochs):
for batch_idx, (data, target) in enumerate(train_loader):
# 前向传播
output = model(data)
# 计算 KL散度损失
kl_loss = kl_div_loss(output, target)
# 计算总损失
total_loss = kl_loss + other_loss
# 反向传播
optimizer.zero_grad()
total_loss.backward()
optimizer.step()在训练过程中,调用自定义损失函数 kl_div_loss 来计算 KL散度损失,并将其加入到总损失 total_loss 中。在反向传播时,只需对总损失进行反向传播即可。
通过以上步骤,就可以在训练中使用 KL散度作为损失函数来优化模型。