第一章 基础算法(三)—— 双指针,位运算,离散化与区间合并
文章目录
-
- 双指针
- 位运算
- 离散化
- 区间合并
- 双指针练习题
-
- 799. 最长连续不重复子序列
- 800. 数组元素的目标和
- 2816. 判断子序列
- 位运算练习题
-
- 801. 二进制中1的个数
- 离散化练习题
-
- 802. 区间和
- 区间合并练习题
-
- 803. 区间合并
为什么直接用y总的板书?
我是懒狗,不想再画啦
双指针
- 两个指针分别指向两个不同的序列
- 两个指针指向同一个序列,快排,表示一段区间
双指针模板:
for (int l = 0, r = 0; r < n; ++r)
{
while (l < r && check(l, r)) ++r;
// 每道题的具体逻辑
}
双指针算法的核心思想,运用某些单调性质将N方的朴素算法优化成N
此时每个指针遍历数字的次数不超过n
先思考暴力做法,再思考双重循环中(暴力一般是两个for循环)的单调关系,得到优化做法
最基本的运用:以空格分隔的单词,以行的形式输出

位运算
两个运用:
- n的二进制表示中第k位是几?
- 先把第k位移到最后一位
- 看二进制的个位是几
结合就是:n >> k & 1,根据题目具体要求,第k位是从0开始还是从1开始?这里涉及一个差一问题,需要根据实际情况考虑一下
lowbit(x):返回x的最后一位1,具体是lowbit(1010) = 10b,lowbit(10100) = 100b
具体实现是:x & -x=x & (~x + 1),注意-x = (~x + 1)

一个具体的运用是:统计x中1出现的次数,对x不断地lowbit,每次减去lowbit得到的数,次数加1。
直到x为0,说明x中的1被减完了,此时的次数就是x中1出现的次数
模板:
int lowbit(int x)
{
return x & (~x + 1);
}
离散化
特指整数离散化
值域比较大,但是数字个数比较少,将这些离散的数映射到连续的区间上的过程,叫做离散化
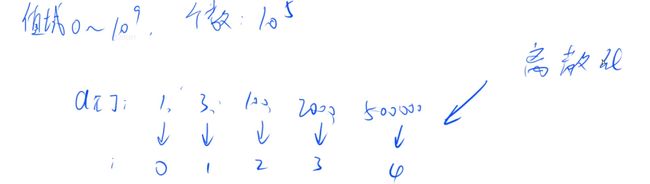
当数据存储的很分散(位置之间相差很大),比如0, 555,10000, 99999999999,数组中这些位置上的数据都不为0,我要统计某个区间或者整个数组的元素和,怎么办?若遍历所有元素,那么绝大部分的元素遍历是无效的,因为它们的值不会影响结果
对于这些不影响结果的值,我们可以将其忽略。对于影响结果的值,保存它们的位置到一个数组中,此时这些位置与数组下标旧构成了一个唯一的映射关系。将数组下标作为这些位置的新位置,那么原来离散的值就被整合成连续的了
我们可以根据数据原来的位置,在保存离散数据位置的数组中二分,找到该位置的下标,该下标就是原位置的新位置,也就是连续存储的位置
比如数组保存[1, 3, 100, 2000, 500000]这些元素,要找2000的新位置,只要在数组中二分查找2000,得到其下标,即得到其新位置
两个问题:
- 数组中可能有重复元素。需要排序并去重
- 如何算出 a i a_i ai离散化后的值?使用二分
排序去重模板:
sort(alls.begin(), alls.end());
erase(unique(alls.begin(), alls.end()), alls.end());
unique:在原数组的基础上,将数组去重,并返回不重合数组的后一个位置
用erase将去重后的重复元素删除,此时的alls中的元素唯一
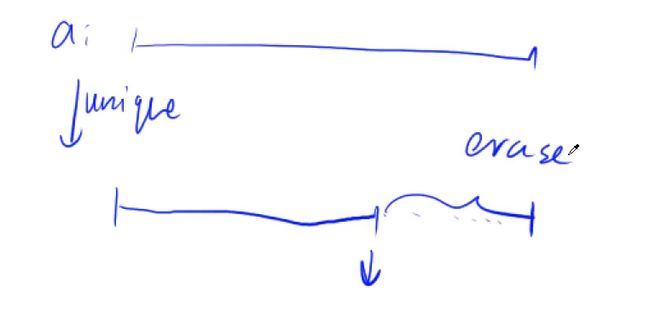
unique的实现思路:首先,数组不为空时,第一个数肯定能作为不重复的数
其次,因为数组已经排过序,只要一个数与之前的数不一样,那么这个数也能作为不重复的数
当某个数能作为不重复的数时,我们需要保存该数,这里直接在原地保存,即从原数组的开头往后保存这些不重复的数
两个指针:i用来遍历原数组中的所有数,j用来保存不重复的数,即区间[0, j - 1]中的数是不重复的,[j, ed]区间中的数无用

vector<int>::iterator unique(vector<int>& a)
{
int j = 0;
for (int i = 0; i < a.size(); ++ i)
{
if (!i || a[i] != a[i - 1]) a[j++] = a[i];
}
return a.begin() + j;
}
区间合并
给定多个区间,将有交集的区间合并为一个区间,输出最后区间的数量
- 将所有区间按照左端点进行升序排序(C++对
pair的排序,先比较first,再比较second) - 选择一个最小的未被遍历过的区间,根据该区间的右端点r,与之后的区间进行比较
- 此时会出现两种情况: 两区间有交集,两区间无交集
- 当两区间有交集时,根据两者较大的
r更新当前区间 - 当两区间无交集时,说明当前区间无法合并了,最终区间的数量+1
双指针练习题
799. 最长连续不重复子序列
799. 最长连续不重复子序列 - AcWing题库
双指针:l与r
用r遍历序列,每次遍历r时,l尽可能地往左走,使l与r之间的序列在满足字符不重复的情况下,达到最长
这样每次遍历r,就能得到一个[l, r]区间,并且该区间是以r为右端点的最长不重复子序列。因此,每次计算该序列的长度,更新出整个序列中最长不重复子序列
这里要思考每次更新r时,l怎样移动的问题。有点类似dp,在上次的状态更新中,我们已经找出了一个最长子序列[l, r - 1]
此时将更新r - 1为r,由于[l, r - 1]区间中不含重复元素,当r更新时,可以理解为向旧区间添加了一个新字符
若新字符与旧区间中的字符重复,那么l就要向前走,因为只有向前走,才可能剔除区间中字符的字符
直到区间中无重复字符时,l停下,此时的区间[l, r]为以r做为右端点的最长不重复子序列,更新最长的长度即可
若更新 r i r_i ri为 r i + 1 r_{i+1} ri+1后,l可以向前走,即将 l i l_i li更新为 l i − 1 l_{i-1} li−1,那么就说明区间[ l i − 1 l_{i-1} li−1, r i + 1 r_{i+1} ri+1]无重复字符。若区间[ l i − 1 l_{i-1} li−1, r i + 1 r_{i+1} ri+1]无重复字符,那么旧区间应该是[ l i − 1 l_{i-1} li−1, r i r_i ri],而不是[ l i l_i li, r i r_i ri],这与我们确定的状态矛盾
也就是说,每次更新r时,得到的区间[l, r]是以r为右端点,往左能构造的最长无重复子序列。也就是说l - 1指向的字符与[l, r]中的某个字符重复
#include 800. 数组元素的目标和
800. 数组元素的目标和 - AcWing题库

利用有序数列的单调性,假设现在有两个数组 a n a_n an与 b n b_n bn,分别用i和j两个指针遍历,j指针从头开始遍历,i指针从尾开始遍历
用二分找到第一个 a i a_i ai + b j b_j bj <= x的 a i a_i ai,之后再判断 a i a_i ai + b j b_j bj == x
此时 a n a_n an搜索区间就缩小成了[0, i],因为 b j b_j bj + a i a_i ai中, a i a_i ai是第一个小于等于x的数。 b j b_j bj + a i + 1 a_{i+1} ai+1 必定大于x
b j + 1 b_{j+1} bj+1 + a i + 1 a_{i+1} ai+1 也必定大于x,所以 b j + 1 b_{j+1} bj+1 + a i a_i ai 才可能小于等于x,此时从 a 0 a_0 a0 ~ a i a_i ai之间中,找到第一个满足 a k a_k ak + b j + 1 b_{j+1} bj+1 <= x的 a k a_k ak
#include 2816. 判断子序列
2816. 判断子序列 - AcWing题库

这个实在想不到怎么用暴力解,双指针一下就看出来了。不像上一题,只能想到暴力,然后再根据单调性,用双指针优化
两个指针i和j分别指向两个数组的开头,j不断移动,当a[i] == b[j]时,i移动,当i遍历完数组,输出Yes
#include while (i < n && j < m && a[i] == b[j]) i++, j++;
没有注意细节:之前判断条件i < n && j < m没写
a[i] == b[j]写成了a[i+] == b[j++]
WA了两次
不要被模板限制,这题可以直接用while写
#include 位运算练习题
801. 二进制中1的个数
801. 二进制中1的个数 - AcWing题库
lowbit的使用,减去n次lowbit,n即为答案
#include 离散化练习题
802. 区间和
802. 区间和 - AcWing题库
题目有两个操作,一是将某个位置的数加上特定值,二是询问某个区间中的值总和
求区间的值总和,使用前缀和数组完成
现在的问题是,这些值过于分散,前缀和数组以及保存这些值的数组将浪费大量空间
所以需要进行预处理,使这些离散的值连续,用数组将值的位置保存,将这些离散的位置用数组下标重新映射,使之成为连续的位置
这样处理后,离散的值变得连续
所以我们需要知道题目会用到哪些离散的位置,首先是保存值的位置,其次是询问区间的端点
考虑最坏情况,将这些位置用alls数组保存起来,并用数组下标进行重新映射
当要找某个位置时,根据alls位置保存的值(位置),获取其映射后的位置(所在的数组下标)
所以alls数组用来将离散位置进行连续化,重新构建索引后的位置为数组的下标
至于这些位置上的值,另外使用其他数组进行保存
用pair保存题目的两个操作,分别是对某个位置加上某个值,以及询问某个区间的值
对离散的位置进行重新索引后,这两个操作都要转换成对新索引的操作
#include 区间合并练习题
803. 区间合并
803. 区间合并 - AcWing题库
将区间按照左端点优先,其次右端点的优先级进行排序(使用STL的sort)。维护一个当前区间并根据后续区间更新当前区间
当前区间与后续区间无交集时,说明区间无法合并,此时最终区间的数量+1
否则更新区间
需要注意的是:设置起始区间为一个题目不可能给定的区间,然后再进行更新
#include 还是有一些细节需要注意的:选择的初始区间与后续区间无交集时,最终的区间数量不能+1
最后将最终的区间数量+1,因为最后一个区间无后续区间,此时该区间可以作为一个无法合并的区间
当然,题目规定了区间数量大于0,所以这题可以不用考虑给定区间为空的情况。使用排序后的第一个区间作为起始区间,省去判断
#include