python爬虫模拟登录学校教务系统(青果教务系统)并查询个人成绩
全文简介
本文介绍用python模拟登录中国海洋大学教务系统的方法,此系统为湖南青果软件公司开发,因此如果你学校的教务系统也是青果开发的,那么此文对你的模拟登录也会有一定的借鉴意义。全文总共包含4部分,登录过程分析部分会详细分析我们在浏览器中输入账号和密码进行登录请求时,会向服务器发出哪些请求,以及请求的参数是如何构造的;验证码识别部分会介绍如何使用百度的OCR来进行验证码的识别,以实现程序的自动化操作;成绩查询部分是当我们用程序登录进教务系统之后,模拟查询成绩的操作,此处会用到execjs来在python中执行js代码。最后的代码实现部分即为模拟登录并进行成绩查询的python代码。
登录过程分析
用Chrome浏览器打开学校的教务系统登录界面,按F12打开开发者工具,在上方选中Network选项卡,并且勾选Preserve log复选框。随便输入账号、密码和验证码,点击登录按钮,这时就会在开发者工具中看到浏览器发出的所有网络请求,如下图所示。

我们可以看到,浏览器总共发出了两个网络请求,在下面的请求要早于在上面的请求。点击登录按钮后,浏览器会先发出名为logon.action的请求,它是一个验证登录信息的请求,因为账号和密码都是随便输入的,所以这次登录一定会失败,因此浏览器又发出了名为genValidateCode?..的请求来获取新的验证码。可以通过点击请求名称的方式来查看请求的详细内容,logon.action的请求信息如下图所示。

从详情页的headers选项卡中我们可以获取到很多有用的信息。请求的url是http://jwgl.ouc.edu.cn/cas/logon.action,请求方式为POST。既然是POST请求,那么一定会有请求数据,上图下方的Form Data部分就是请求时携带的数据。如果我们能手工构造出Form Data的内容,那么就可以实现模拟登录的操作,因此下面重点分析Form Data的各个字段。
从上图中可以看出,Form Data共有7个字段。从前两个字段中我们暂时得不出有用的信息,第三个字段的名称是randnumber,值是5g4n,根据此字段的名称可以猜测这是输入的验证码,根据此字段的值可以验证这种猜测。现在再回过头来看一下前两个字段,这两个字段的名称分别是_u和_p拼接上输入的验证码构成的,从它们的值看不出任何意义,但是我们可以大胆的进行猜测,要登录一定要验证账号和密码,而从后面4个字段的值可以知道,后4个字段不可能是账号密码,因此前两个字段表示的是账号和密码,且对账号和密码进行了某种加密操作。
现在我们的任务是要找出前两个字段的值是如何构造出来的,通常这种情况可以全局搜索前两个字段的名称,来查找相应的构造代码,但是因为在此网站中字段的名称是动态生成的,所以此方法行不通。因为所有的参数的构造代码基本都是相邻的,所以我们可以通过全局查找randnumber的方式来迂回的查找前两个字段,查找结果如下图所示。

点击查找的结果,即可查看相应的代码,比如我们点击第一行的查找结果,会显示如下图所示的代码。
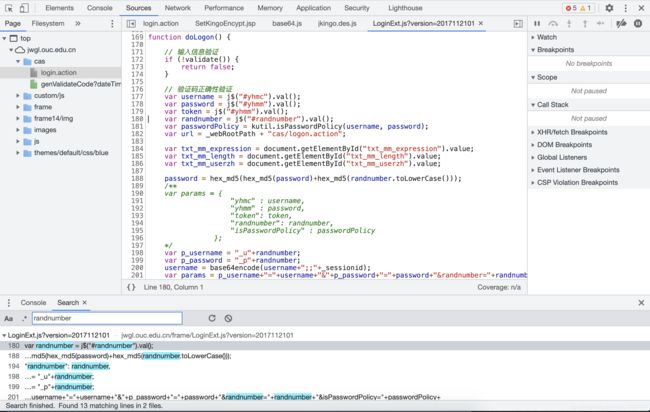
下面分析上图代码的逻辑。首先是从前端中获取username(账号),password(密码),randnumber(验证码),token在我所演示的网站中没有用到,可以不予理会,实现此部分功能的代码如下所示。
var username = j$("#yhmc").val();
var password = j$("#yhmm").val();
var token = j$("#yhmm").val();
var randnumber = j$("#randnumber").val();
接着计算了Form Data中的后四个字段的值和登录请求的url,因为在我所演示的系统中,模拟登录时有没有后四个字段都可以,所以就不去深入的分析它们的逻辑了,只说一下它们的含义。isPasswordPolicy用来标志密码是否符合规范,规范的密码有两个要求,一是不能和登录账号相同,二是长度大于等于6位且同时含有字母和数字,若输入的密码符合规范,则字段值为1,否则为0。txt_mm_expression标志密码是由哪些类型的字符构成的,比如若密码中含有数字和小写字母,则其值为12。txt_mm_length代表密码的长度。txt_mm_userzh标志密码是否包含账号,包含为1,不包含为0。
接下来是对密码和账号进行加密,并且根据验证码的值计算这两个字段的名称,最后是将所有的参数用&符号连接起来,此部分代码如下所示。
password = hex_md5(hex_md5(password)+hex_md5(randnumber.toLowerCase()));
var p_username = "_u"+randnumber;
var p_password = "_p"+randnumber;
username = base64encode(username+";;"+_sessionid);
var params = p_username+"="+username+"&"+p_password+"="+password+"&randnumber="+randnumber+"&isPasswordPolicy="+passwordPolicy+
"&txt_mm_expression="+txt_mm_expression+"&txt_mm_length="+txt_mm_length+"&txt_mm_userzh="+txt_mm_userzh;
从上面的代码中可以看出,_u开头的字段是加密后的账号,_p开头的字段是加密后的密码。密码的加密规则为:先将用户输入的密码进行md5计算,再将用户输入的验证码转小写后进行md5计算,最后将这两者拼接起来再进行一次md5计算就可以得到加密后的密码。账号的加密规则为:将用户输入的账号拼接上;;再拼接上_sessionid,然后进行base64编码即可得到加密后的账号。现在遗留的问题是_sessionid是什么,我们从它的名称可以猜测它大概是指会话的id,像这种信息一般是存放在cookie中的,那么我们看一下logon.action的请求头,发现有一个名为JSESSIONID的cookie,如下图所示。
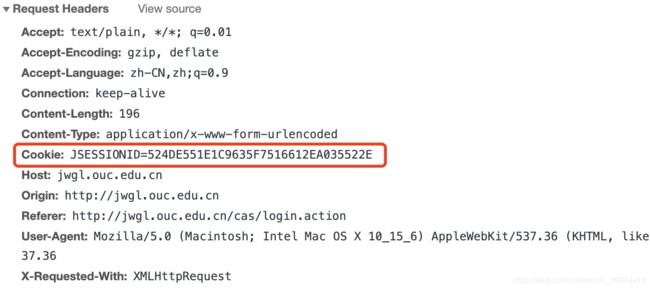
为了验证_sessionid是否就是名为JSESSIONID的cookie,我们全局搜索_sessionid看一下,搜索结果如下图所示,可以看出我们的猜想是正确的。

现在登录过程已经分析完毕,我们在模拟登录时,只需要按照前面所讲的逻辑,构造相应的Form Data即可。但是现在仍有一个问题,在用浏览器登录时,是手工输入的验证码,如果模拟登录时仍然手工输入验证码,未免太过繁琐,因此下一部分会介绍验证码的识别方法。
验证码识别
本文选择百度OCR作为识别验证码的工具,相较于tesseract,百度的文字识别有着较高的准确率,相较于深度学习,直接调用百度的服务更简单,更适合学习研究用。本文仅是作为技术交流,重点不会放在实际应用上,因此选择现有的识别产品是最好的选择。
现在回到登录界面,在验证码图片上右键,选择“检查”,然后就会在开发者工具中显示验证码对应的html代码,我们从代码中提取出验证码对应的url,可以在浏览器中直接访问这个url看一下是否会出现验证码图片,以此来验证url的正确性。提取出来的url有如下形式。
http://jwgl.ouc.edu.cn/cas/genValidateCode?dateTime=Wed%20Jun%2030%202021%2009:09:25%20GMT+0800%20(%D6%D0%B9%FA%B1%EA%D7%BC%CA%B1%BC%E4)
此url中包含了请求图片的时间,但是在实践过程中发现,服务器并不会判断时间的正确性,因此在模拟登录时,可以选择固定验证码图片的url,而不是每次都根据系统时间动态生成。
有了验证码图片的url,就可以通过此url请求验证码图片,之后用百度OCR进行文字识别,下面介绍百度OCR的使用。首先进入百度文字识别的控制台,地址为:https://console.bce.baidu.com/ai/?_=1625035708629&fromai=1#/ai/ocr/overview/index,进入后可以看到如下图所示的界面。
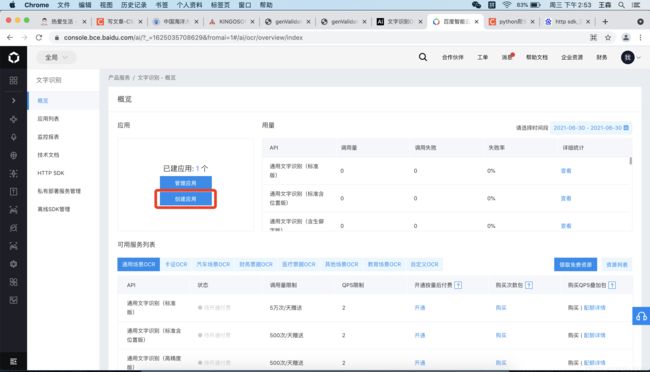
点击应用栏的创建应用(如上图红色矩形标注处所示),然后根据提示填写相关信息,默认选项不需要改动,创建完成之后在应用列表即可看到刚才创建的应用。如下图所示。

要使用百度的OCR服务,还需要安装相应的SDK,安装方法为pip install baidu-aip。AipOcr是OCR的Python SDK客户端,为使用OCR的开发人员提供了一系列的交互方法。参考如下代码可以创建一个AipOcr。
from aip import AipOcr
""" 你的 APPID AK SK """
APP_ID = '你的 App ID'
API_KEY = '你的 Api Key'
SECRET_KEY = '你的 Secret Key'
client = AipOcr(APP_ID, API_KEY, SECRET_KEY)
在上面代码中,APP_ID, API_KEY, SECRET_KEY均可在刚才创建的应用中找到。创建好AipOcr后,可以使用如下代码进行文字识别。
""" 读取图片 """
def get_file_content(filePath):
with open(filePath, 'rb') as fp:
return fp.read()
image = get_file_content('example.jpg')
""" 调用通用文字识别(高精度版) """
client.basicAccurate(image);
识别的返回结果是一个字典,如下是一个返回示例。
{
"log_id": 2471272194,
"words_result_num": 2,
"words_result":
[
{"words": " TSINGTAO"},
{"words": "青島睥酒"}
]
}
有关百度OCR文字识别的更多使用方法,可以参考官网文档:https://ai.baidu.com/ai-doc/OCR/wkibizyjk。
成绩查询
按照之前的分析,我们已经可以用代码模拟登录进教务系统了,现在我们分析一下如何用程序进行成绩查询。
在教务系统中点击“学业成绩”,然后选择“入学以来”单选按钮,再按F12打开开发者工具,选中Network选项卡,勾选Preserve log复选框,如下图所示。
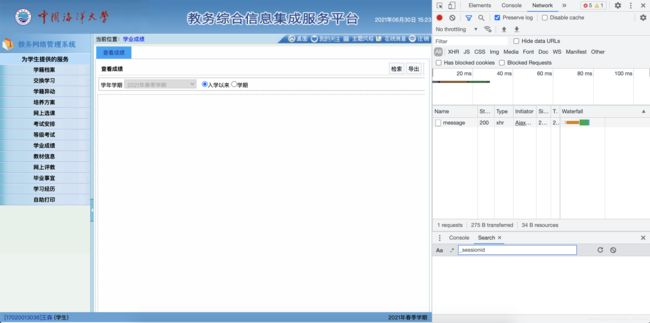
点击“检索”按钮,就会在网页中显示入学以来的所有成绩,同时会在开发者工具中显示点击“检索”按钮后发出的所有网络请求。点击查看Type为document的那个请求,成绩信息就是通过此请求获得的,如下图所示。
我们可以看到,请求的方式为GET,请求附带的参数有三个,分别是params、token、timestamp。还是老规矩,全局搜索这几个参数的名称,当搜索params时,发现结果比较多,我们可以改为搜索timestamp,这样能缩小搜索范围,以便尽快定位到计算参数的代码。
点击搜索结果,进入代码文件,可以看到这三个参数是在SetKingoEncrypt.jsp文件中的getEncParams函数中产生的,如下图所示。

getEncParams函数有一个名为params的参数,因此全局搜索此函数,查找调用这个函数的地方,可以看到在xscj.stuckcj.jsp?menucode=JW130705文件中调用了getEncParams函数,但是很遗憾的是,调用的参数不是写在代码中的,而是从前端页面中获取的,相关代码如下所示。

既然无法从代码中直接找到params这个参数,那么我们可以在上图的第75行处打个断点,然后重新检索成绩,看看params的值是什么。当点击检索按钮之后,代码会暂停在第75行处,此时可以在开发者工具的右侧查看局部变量的值,其中就包括params的值,如下图所示。

当检索入学以来的成绩时,params的值为xn=2020&xn1=2021&xq=2&ysyx=yscj&sjxz=sjxz1&ysyxS=on&sjxzS=on(请以自己实际的值为准,因为可能会发生变化),现在回到getEncParams函数中,timestamp的值在源代码中有,token的值也可以用python进行计算,而_params的值是通过调用des_encode函数和b64_encode函数得到的,深入分析这两个函数可以知道b64_encode是进行base64编码,可以很容易的通过python进行计算,而des_encode函数又调用了strEnc函数,仍然是全局搜索,找到strEnc函数的定义,它在jkingo.des.js文件中,但是这个函数比较难懂,因此我决定不去解析这个函数的逻辑,而是直接在python中通过第三方工具执行这个函数的代码。strEnc函数的参数有4个,第一个参数是要加密的数据,后三个参数是密钥,而根据调用情况来看,只给出了前两个参数,后两个参数都是null,其中第一个密钥即为SetKingoEncrypt.jsp中的_deskey。
分析完了请求的参数,就可以构造请求url了,之后解析返回的html代码即可得到成绩。
代码实现
代码中用到的请求库为requests,安装方式为pip install requests,用到的解析库为BeautifulSoup,安装方式为pip install BeautifulSoup4,执行JavaScript代码的第三方库为execjs,安装方式为pip install PyExecJS,我的Catalina操作系统安装完PyExecJS之后无法直接使用,需要再安装Nodejs,Windows应该可以直接使用。
因为百度OCR的准确率不是很高,所以对于识别结果,先判断它的长度是否是4位(通过观察,验证码的长度都是4),若不是,则重新请求验证码并识别,这样能大大提高登录的成功率。模拟登录并查询成绩的代码如下所示。
import requests
from aip import AipOcr
import base64
from hashlib import md5
import json
import re
from queryParams import get_params
from bs4 import BeautifulSoup
from time import time
headers = {
'Host': 'jwgl.ouc.edu.cn',
'Origin': 'http://jwgl.ouc.edu.cn',
'Referer': 'http://jwgl.ouc.edu.cn/cas/login.action',
'User-Agent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_6) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/91.0.4472.114 Safari/537.36',
'X-Requested-With': 'XMLHttpRequest',
'Upgrade-Insecure-Requests': '1',
}
data = {
'randnumber': 'jzfm'
}
def randnumber_ocr(image):
APP_ID = '' # 在百度官网的应用列表中查看APP_ID
API_KEY = '' # 在百度官网的应用列表中查看API_KEY
SECRET_KEY = '' # 在百度官网的应用列表中查看SECRET_KEY
client = AipOcr(APP_ID, API_KEY, SECRET_KEY)
text = client.basicAccurate(image)
if text['words_result_num'] == 1:
return text['words_result'][0]['words'].strip()
else:
return ''
def get_score(session):
url = 'http://jwgl.ouc.edu.cn/custom/js/SetKingoEncypt.jsp'
r = session.get(url)
des_key = re.search("var _deskey = '(\d+)';", r.text).group(1)
timestamp = re.search("var _nowtime = '(.*?)';", r.text).group(1)
params, token = get_params(des_key, timestamp)
url = 'http://jwgl.ouc.edu.cn/student/xscj.stuckcj_data.jsp?params={}&token={}×tamp={}'.format(
params, token, timestamp
)
headers['Referer'] = 'http://jwgl.ouc.edu.cn/student/xscj.stuckcj.jsp?menucode=JW130705'
r = session.get(url, headers=headers)
soup = BeautifulSoup(r.text, 'lxml')
tbodys = soup.select('tbody')
for tbody in tbodys:
for tr in tbody.select('tr'):
tds = tr.select('td')
print(tds[1].string + ": " + tds[6].string)
session.close()
def logon():
start = time()
url = 'http://jwgl.ouc.edu.cn/cas/logon.action'
username = '' # 输入你的用户名,也就是学号
password = '' # 输入你的密码
session = requests.Session()
randnumber = ''
while len(randnumber) != 4:
r = session.get('http://jwgl.ouc.edu.cn/cas/genValidateCode?dateTime=Mon%20Jun%2028%202021%2011:21:48%20GMT+0800%20(%D6%D0%B9%FA%B1%EA%D7%BC%CA%B1%BC%E4)', headers=headers)
randnumber = randnumber_ocr(r.content)
_sessionid = session.cookies.get_dict()['JSESSIONID']
data['randnumber'] = randnumber
p_username = '_u' + randnumber
p_password = '_p' + randnumber
username = base64.b64encode(username.encode('utf-8') + b';;' + str(_sessionid).encode('utf-8'))
password = md5(password.encode('utf-8')).hexdigest()
randnumber = md5(randnumber.lower().encode('utf-8')).hexdigest()
password = md5((password + randnumber).encode('utf-8')).hexdigest()
data[p_username] = username
data[p_password] = password
r = session.post(url, data=data, headers=headers)
info = json.loads(r.text)
status = info['status']
if status == '401':
print('验证码错误')
return
elif status == '200':
pass
else:
print(info['message'])
return
print('登录成功')
get_score(session)
end = time()
print('总共用时' + str(end - start))
if __name__ == '__main__':
logon()
queryParams.py文件中的代码如下所示,因为要执行的js代码过于冗长,所以没有在下面的代码中贴出,读者可以自行把jking.des.js文件(根据实际情况而定)中的代码复制到js_code变量中。
import execjs
import base64
from hashlib import md5
js_code = '''
//将jkingo.des.js文件中的所有代码复制到此处
'''
def get_params(des_key, timestamp):
params = 'xn=2020&xn1=2021&xq=2&ysyx=yscj&sjxz=sjxz1&ysyxS=on&sjxzS=on'
token = md5(params.encode('utf-8')).hexdigest() + md5(timestamp.encode('utf-8')).hexdigest()
token = md5(token.encode('utf-8')).hexdigest()
ctx = execjs.compile(js_code)
params = ctx.call("strEnc", params, des_key, '', '')
_params = base64.b64encode(params.encode('utf-8')).decode('utf-8')
return _params, token