SAAS-HRM系统概述与搭建环境
SAAS-HRM系统概述与搭建环境
学习目标:
理解SaaS的基本概念
了解SAAS-HRM的基本需求和开发方式掌握Power Designer的用例图
完成SAAS-HRM父模块及公共模块的环境搭建完成企业微服务中企业CRUD功能
初识SaaS
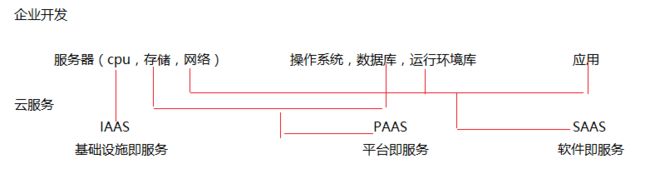
云服务的三种模式
IaaS(基础设施即服务)
IaaS(Infrastructure as a Service),即基础设施即服务。提供给消费者的服务是对所有计算基础设施的利用,包括处理CPU、内存、存储、网络和其它基本的计算资源,用户能够部署和运行任意软件,包括操作系统和应用程 序。消费者不管理或控制任何云计算基础设施,但能控制操作系统的选择、存储空间、部署的应用,也有可能获得 有限制的网络组件(例如路由器、防火墙、负载均衡器等)的控制
PaaS(平台即服务)
PaaS(Platform-as-a-Service),即平台即服务。提供给消费者的服务是把客户采用提供的开发语言和工具(例如Java,python, .Net等)开发的或收购的应用程序部署到供应商的云计算基础设施上去。客户不需要管理或控制底层的云基础设施,包括网络、服务器、操作系统、存储等,但客户能控制部署的应用程序,也可能控制运行应用程 序的托管环境配置
SaaS(软件即服务)
SaaS(Software-as-a-Service),即软件即服务。提供给消费者完整的软件解决方案,你可以从软件服务商处以租 用或购买等方式获取软件应用,组织用户即可通过 Internet 连接到该应用(通常使用 Web 浏览器)。所有基础结构、中间件、应用软件和应用数据都位于服务提供商的数据中心内。服务提供商负责管理硬件和软件,并根据适当 的服务协议确保应用和数据的可用性和安全性。SaaS 让组织能够通过最低前期成本的应用快速建成投产。
区别与联系

骚戴理解:通过下面的图更好理解这三个概念,IAAS就是在云服务上面给你提供服务器这些硬件资源,你可以不用买服务器,去租IAAS就好,PAAS就是除了给你提供硬件资源,还提供软件资源(运行环境),你只需要把项目的源码部署上来就可以了,而SAAS就是别人做好了的项目,你直接买来用,开发也不用开发,给钱就行!
SaaS的概述
Saas详解
SaaS(Software-as-a-service)的意思是软件即服务。简单说就是在线系统模式,即软件服务商提供的软件在线服务。
应用领域与行业前景
SaaS软件就适用对象而言,可以划分为针对个人的与针对企业的面向个人的SaaS产品:在线文档,账务管理,文件管理,日程计划、照片管理、联系人管理,等等云类型的服务
而面向企业的SaaS产品主要包括:CRM(客户关系管理)、ERP(企业资源计划管理)、线上视频或者与群组通话会议、HRM(人力资源管理)、OA(办公系统)、外勤管理、财务管理、审批管理等。

Saas与传统软件对比
- 降低企业成本:按需购买,即租即用,无需关注软件的开发维护。
- 软件更新迭代快速:和传统软件相比,由于saas部署在云端,使得软件的更新迭代速度加快
- 支持远程办公:将数据存储到云后,用户即可通过任何连接到 Internet 的计算机或移动设备访问其信息
SaaS-HRM 需求分析
什么是SaaS-HRM

SaaS-HRM是基于saas模式的人力资源管理系统。他不同于传统的人力资源软件应用,使用者只需打开浏览器即可 管理上百人的薪酬、绩效、社保、入职离职。
原型分析法
原型分析的理念是指在获取一组基本需求之后,快速地构造出一个能够反映用户需求的初始系统原型。让用户看到 未来系统的概貌,以 便判断哪些功能是符合要求的,哪些方面还需要改进,然后不断地对这些需求进一步补充、细化和修改。依次类推,反复进行,直到用户满意为止并由此开发出完整 的系统。
简单的说,原型分析法就是在最短的时间内,以最直观的方式获取用户最真实的需求
UML的用例图
UML统一建模语言
Unified Modeling Language (UML)又称统一建模语言或标准建模语言,是始于1997年一个OMG标准,它是一个支持模型化和软件系统开发的图形化语言,为软件开发的所有阶段提供模型化和可视化支持,包括由需求分析到 规格,到构造和配置。 面向对象的分析与设计(OOA&D,OOAD)方法的发展在80年代末至90年代中出现了一个高潮,UML是这个高潮的产物。它不仅统一了Booch、Rumbaugh和Jacobson的表示方法,而且对其作了进一步的 发展,并最终统一为大众所接受的标准建模语言。UML中包含很多图形(用例图,类图,状态图等等),其中用例图是最能体现系统结构的图形
用例图
用例图(use case)主要用来描述用户与用例之间的关联关系。说明的是谁要使用系统,以及他们使用该系统可以做些什么。一个用例图包含了多个模型元素,如系统、参与者和用例,并且显示这些元素之间的各种关系,如泛化、关联和依赖。它展示了一个外部用户能够观察到的系统功能模型图。
需求分析软件
Power Designer是Sybase公司的CASE工具集,使用它可以方便地对管理信息系统进行分析设计,他几乎包括了数据库模型设计的全过程。利用Power Designer可以制作数据流程图、概念数据模型、物理数据模型,还可以为数据仓库制作结构模型,也能对团队设计模型进行控制。
- 下载安装
使用第一天资料中准备好的安装包安装Power Designer,安装过程略
- 使用Power Designer绘制用例图绘制步骤:
文件=>建立新模型=>选择Modeltypes=>Use Case
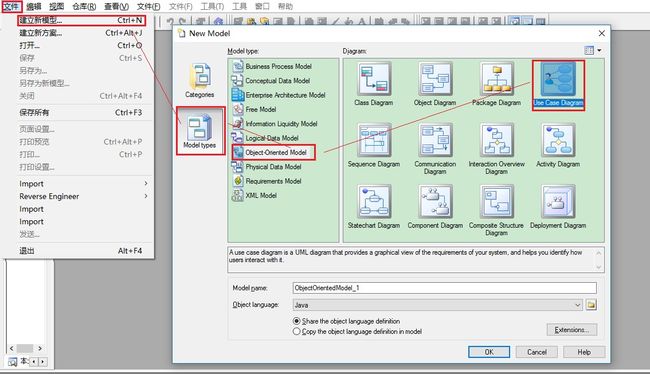
基本用例图:

系统设计
开发方式
SaaS-IHRM系统采用前后端分离的开发方式。

后端给前端提供数据,前端负责HTML渲染(可以在服务器渲染,也可以在浏览器渲染)和用户交互。双方通过文档的形 式规范接口内容
技术架构

- 前端技术栈
以Node.js为核心的Vue.js前端技术生态架构
- 后端技术栈
SpringBoot+SpringCloud+SpringMVC+SpringData(Spring全家桶)
系统结构


API文档
课程提供了前后端开发接口文档(采用Swagger语言进行编写),并与Ngin进行了整合。双击Nginx执行文件启动后,在地址栏输入http://localhost:801 即可访问API文档
骚戴提示:这里Api-ngnix如果启动了,但是访问不了,需要把这个文件夹放到没有中文的文件夹里才可以访问,然后可以跳转到下面的页面,然后我打开任务管理器,杀掉Nginx,然后重启,还是下面的页面,然后我把那个压缩包重新放到一个没中文的文件夹里,然后解压后重启就可以了,我猜应该是要把压缩包放到一个没中文的文件夹里,我一开始是把文件夹复制过去的!

工程搭建
前置知识点的说明
Saas-HRM系统后端采用SpringBoot+SpringCloud+SpringMVC+SpringData Saas-HRM系统前端采用基于nodejs的vue框架完成编写使用element-ui组件库快速开发前端界面
开发环境要求
- JDK1.8
- 数据库mysql 5.7
- 开发工具 idea 2017.1.2 maven版本3.3.9
lombok 插件
lombok是一款可以精减java代码、提升开发人员生产效率的辅助工具,利用注解在编译期自动生成setter/getter/toString()/constructor之类的代码

- idea中安装插件
- 在pom文件中添加插件的依赖
org.projectlombok
lombok
1.16.16
- 常见注解
@Data 注解在类上;提供类所有属性的 getting 和 setting 方法,此外还提供了equals、canEqual、
hashCode、toString 方法
@Setter :注解在属性上;为属性提供 setting 方法
@Setter :注解在属性上;为属性提供 getting 方法@NoArgsConstructor :注解在类上;为类提供一个无参的构造方法@AllArgsConstructor :注解在类上;为类提供一个全参的构造方法
构建父工程
在IDEA中创建父工程ihrm_parent并导入相应的坐标如下:
pom
ihrm_parent
IHRM-黑马程序员
org.springframework.boot
spring-boot-starter-parent
2.0.5.RELEASE
UTF-8
UTF-8
1.8
1.2.47
org.springframework.boot
spring-boot-starter-web
org.springframework.boot
spring-boot-starter-logging
org.springframework.boot
spring-boot-starter-test
test
com.alibaba
fastjson
${fastjson.version}
org.projectlombok
lombok
1.16.16
spring-snapshots
Spring Snapshots
https://repo.spring.io/snapshot
true
spring-milestones
Spring Milestones
https://repo.spring.io/milestone
false
spring-snapshots
Spring Snapshots
https://repo.spring.io/snapshot
true
spring-milestones
Spring Milestones
https://repo.spring.io/milestone
false
org.apache.maven.plugins
maven-compiler-plugin
3.1
${java.version}
${java.version}
org.apache.maven.plugins
maven-surefire-plugin
2.12.4
true
构建公共子模块
构建公共子模块ihrm-common
创建返回结果实体类
新建com.ihrm.common.entity包,包下创建类Result,用于控制器类返回结果
package com.ihrm.common.entity;
import com.fasterxml.jackson.annotation.JsonInclude;
import com.fasterxml.jackson.databind.annotation.JsonSerialize;
import lombok.AllArgsConstructor;
import lombok.Data;
import lombok.NoArgsConstructor;
@Data
@NoArgsConstructor
public class Result {
private boolean success;//是否成功
private Integer code;// 返回码
private String message;//返回信息
private Object data;// 返回数据
public Result(ResultCode code) {
this.success = code.success;
this.code = code.code;
this.message = code.message;
}
public Result(ResultCode code,Object data) {
this.success = code.success;
this.code = code.code;
this.message = code.message;
this.data = data;
}
public Result(Integer code,String message,boolean success) {
this.code = code;
this.message = message;
this.success = success;
}
public static Result SUCCESS(){
return new Result(ResultCode.SUCCESS);
}
public static Result ERROR(){
return new Result(ResultCode.SERVER_ERROR);
}
public static Result FAIL(){
return new Result(ResultCode.FAIL);
}
}
创建类PageResult ,用于返回分页结果
package com.ihrm.common.entity;
import lombok.AllArgsConstructor;
import lombok.Data;
import lombok.NoArgsConstructor;
import java.util.List;
@Data
@AllArgsConstructor
@NoArgsConstructor
public class PageResult {
private Long total; //总条数
private List rows;
}
返回码定义类
package com.ihrm.common.entity;
public enum ResultCode {
SUCCESS(true,10000,"操作成功!"),
//---系统错误返回码-----
FAIL(false,10001,"操作失败"),
UNAUTHENTICATED(false,10002,"您还未登录"),
UNAUTHORISE(false,10003,"权限不足"),
SERVER_ERROR(false,99999,"抱歉,系统繁忙,请稍后重试!");
//---用户操作返回码----
//---企业操作返回码----
//---权限操作返回码----
//---其他操作返回码----
//操作是否成功
boolean success;
//操作代码
int code;
//提示信息
String message;
ResultCode(boolean success,int code, String message){
this.success = success;
this.code = code;
this.message = message;
}
public boolean success() {
return success;
}
public int code() {
return code;
}
public String message() {
return message;
}
}
分布式ID生成器
目前微服务架构盛行,在分布式系统中的操作中都会有一些全局性ID的需求,所以我们不能使用数据库本身的自增 功能来产生主键值,只能由程序来生成唯一的主键值。我们采用的是开源的twitter( 非官方中文惯称:推特.是国外的一个网站,是一个社交网络及微博客服务) 的snowFlake (雪花)算法。

各个段解析:
| 分段 |
作用 |
说明 |
| 1bit |
保留(不用) |
--- |
| 41bit |
时间戳,精确到毫秒 |
最多可以支持69年的跨度 |
| 5bit |
机器id |
最多支持2的5次方(32)个节点 |
| 5bit |
业务编码 |
最多支持2的5次方(32)个节点 |
| 12bit |
毫秒内的计数器 |
每个节点每毫秒最多产生2的12次方(4096)个id |
默认情况下41bit的时间戳可以支持该算法使用到2082年,10bit的工作机器id可以支持1024台机器,序列号支持1毫秒产生4096个自增序列id ,SnowFlake的优点是整体上按照时间自增排序,并且整个分布式系统内不会产生ID碰撞(由数据中心ID和机器ID作区分),并且效率较高,经测试,SnowFlake每秒能够产生26万ID左右
骚戴理解:有四种思路,数据库自增在分布式下是无法保证唯一的,uuid太长了,占空间占内存,全局redis有网络延迟,雪花算法专用于分布式系统的id生成

雪花算法代码实现
package com.ihrm.common.utils;
import java.lang.management.ManagementFactory;
import java.net.InetAddress;
import java.net.NetworkInterface;
//雪花算法代码实现
public class IdWorker {
// 时间起始标记点,作为基准,一般取系统的最近时间(一旦确定不能变动)
private final static long twepoch = 1288834974657L;
// 机器标识位数
private final static long workerIdBits = 5L;
// 数据中心标识位数
private final static long datacenterIdBits = 5L;
// 机器ID最大值
private final static long maxWorkerId = -1L ^ (-1L << workerIdBits);
// 数据中心ID最大值
private final static long maxDatacenterId = -1L ^ (-1L << datacenterIdBits);
// 毫秒内自增位
private final static long sequenceBits = 12L;
// 机器ID偏左移12位
private final static long workerIdShift = sequenceBits;
// 数据中心ID左移17位
private final static long datacenterIdShift = sequenceBits + workerIdBits;
// 时间毫秒左移22位
private final static long timestampLeftShift = sequenceBits + workerIdBits + datacenterIdBits;
private final static long sequenceMask = -1L ^ (-1L << sequenceBits);
/* 上次生产id时间戳 */
private static long lastTimestamp = -1L;
// 0,并发控制
private long sequence = 0L;
private final long workerId;
// 数据标识id部分
private final long datacenterId;
public IdWorker(){
this.datacenterId = getDatacenterId(maxDatacenterId);
this.workerId = getMaxWorkerId(datacenterId, maxWorkerId);
}
/**
* @param workerId
* 工作机器ID
* @param datacenterId
* 序列号
*/
public IdWorker(long workerId, long datacenterId) {
if (workerId > maxWorkerId || workerId < 0) {
throw new IllegalArgumentException(String.format("worker Id can't be greater than %d or less than 0", maxWorkerId));
}
if (datacenterId > maxDatacenterId || datacenterId < 0) {
throw new IllegalArgumentException(String.format("datacenter Id can't be greater than %d or less than 0", maxDatacenterId));
}
this.workerId = workerId;
this.datacenterId = datacenterId;
}
/**
* 获取下一个ID
*
* @return
*/
public synchronized long nextId() {
long timestamp = timeGen();
if (timestamp < lastTimestamp) {
throw new RuntimeException(String.format("Clock moved backwards. Refusing to generate id for %d milliseconds", lastTimestamp - timestamp));
}
if (lastTimestamp == timestamp) {
// 当前毫秒内,则+1
sequence = (sequence + 1) & sequenceMask;
if (sequence == 0) {
// 当前毫秒内计数满了,则等待下一秒
timestamp = tilNextMillis(lastTimestamp);
}
} else {
sequence = 0L;
}
lastTimestamp = timestamp;
// ID偏移组合生成最终的ID,并返回ID
long nextId = ((timestamp - twepoch) << timestampLeftShift)
| (datacenterId << datacenterIdShift)
| (workerId << workerIdShift) | sequence;
return nextId;
}
private long tilNextMillis(final long lastTimestamp) {
long timestamp = this.timeGen();
while (timestamp <= lastTimestamp) {
timestamp = this.timeGen();
}
return timestamp;
}
private long timeGen() {
return System.currentTimeMillis();
}
/**
*
* 获取 maxWorkerId
*
*/
protected static long getMaxWorkerId(long datacenterId, long maxWorkerId) {
StringBuffer mpid = new StringBuffer();
mpid.append(datacenterId);
String name = ManagementFactory.getRuntimeMXBean().getName();
if (!name.isEmpty()) {
/*
* GET jvmPid
*/
mpid.append(name.split("@")[0]);
}
/*
* MAC + PID 的 hashcode 获取16个低位
*/
return (mpid.toString().hashCode() & 0xffff) % (maxWorkerId + 1);
}
/**
*
* 数据标识id部分
*
*/
protected static long getDatacenterId(long maxDatacenterId) {
long id = 0L;
try {
InetAddress ip = InetAddress.getLocalHost();
NetworkInterface network = NetworkInterface.getByInetAddress(ip);
if (network == null) {
id = 1L;
} else {
byte[] mac = network.getHardwareAddress();
id = ((0x000000FF & (long) mac[mac.length - 1])
| (0x0000FF00 & (((long) mac[mac.length - 2]) << 8))) >> 6;
id = id % (maxDatacenterId + 1);
}
} catch (Exception e) {
System.out.println(" getDatacenterId: " + e.getMessage());
}
return id;
}
}
搭建公共的实体类模块

构建公共子模块ihrm_common_model
引入坐标
org.springframework.boot
spring-boot-starter-data-jpa
com.ihrm
ihrm_common
1.0-SNAPSHOT
添加实体类
package com.ihrm.domain.company;
import lombok.*;
import javax.persistence.Column;
import javax.persistence.Entity;
import javax.persistence.Id;
import javax.persistence.Table;
import java.io.Serializable;
import java.util.Date;
/**
* 实体类代码:
* 属性
* 构造方法
* getter,setter方法
*
* lombok 插件 : 使用注解的形式替换getter setter,构造方法
* 如何使用插件
* 1.安装插件(在工程中引入响应的插件坐标即可)
*
org.projectlombok
lombok
1.16.16
* 2.使用注解配置
* 配置到实体类上
* @setter : setter方法
* @getter :getter方法
* @NoArgsConstructor 无参构造
* @AllArgsConstructor 满参构造
* @Data : setter,getter,构造方法
*
* 使用jpa操作数据
* 配置实体类和数据库表的映射关系:jpa注解
* 1.实体类和表的映射关系
* 2.字段和属性的映射关系
* i。主键属性的映射
* ii。普通属性的映射
*/
@Entity
@Table(name = "co_company")
@Data
@NoArgsConstructor
@AllArgsConstructor
public class Company implements Serializable {
private static final long serialVersionUID = 594829320797158219L;
//ID
@Id
private String id;
/**
* 公司名称
*/
private String name;
/**
* 企业登录账号ID
*/
private String managerId;
/**
* 当前版本
*/
private String version;
/**
* 续期时间
*/
private Date renewalDate;
/**
* 到期时间
*/
private Date expirationDate;
/**
* 公司地区
*/
private String companyArea;
/**
* 公司地址
*/
private String companyAddress;
/**
* 营业执照-图片ID
*/
private String businessLicenseId;
/**
* 法人代表
*/
private String legalRepresentative;
/**
* 公司电话
*/
private String companyPhone;
/**
* 邮箱
*/
private String mailbox;
/**
* 公司规模
*/
private String companySize;
/**
* 所属行业
*/
private String industry;
/**
* 备注
*/
private String remarks;
/**
* 审核状态
*/
private String auditState;
/**
* 状态
*/
private Integer state;
/**
* 当前余额
*/
private Double balance;
/**
* 创建时间
*/
private Date createTime;
}
骚戴理解:
@Entity和@Data是两个不同的注解,它们分别来自不同的库。
- @Entity: 这个注解来自Java Persistence API (JPA),用于标记一个类为实体类,表示它将被映射到数据库中的一个表。
- @Data: 这个注解来自Lombok库,它是一个快捷方式,可以自动生成getter、setter、toString、equals和hashCode方法。
这两个注解可以一起使用,但是需要注意的是,@Data会为所有字段生成hashCode和equals方法,这可能会与JPA规范或懒加载冲突。因此,在使用@Data时应谨慎处理。
企业微服务-企业CRUD
模块搭建
- 搭建企业微服务模块ihrm_company, pom.xml引入依赖
org.springframework.boot
spring-boot-starter-data-jpa
mysql
mysql-connector-java
com.ihrm
ihrm_common
1.0-SNAPSHOT
com.ihrm
ihrm_common_model
1.0-SNAPSHOT
- 添加配置文件application.yml
server:
port: 9001
spring:
application:
name: ihrm-company #指定服务名
datasource:
driver-class-name: com.mysql.cj.jdbc.Driver
url: jdbc:mysql://localhost:3306/ihrm?useUnicode=true&characterEncoding=utf8&useSSL=false
username: root
password: dzl+770880
jpa:
database: MySQL
show-sql: true
open-in-view: true骚戴理解:
- database: 指定了您使用的数据库类型,这里是MySQL。
- show-sql: 这个属性设置为true时,会在控制台打印出JPA生成的SQL语句1。
- open-in-view: 这个属性默认为true,它决定了是否在视图渲染期间保持数据库连接。
- 配置启动类
@SpringBootApplication(scanBasePackages = "com.ihrm")
@EntityScan("com.ihrm")
public class CompanyApplication {
public static void main(String[] args) {
SpringApplication.run(CompanyApplication.class, args);
}
@Bean
public IdWorker idWorkker() {
return new IdWorker(1, 1);
}
}骚戴理解:IdWorker(1, 1)构造器的第一个参数是工作机器ID,第二个参数是序列号

企业管理-CRUD
表结构分析
CREATE TABLE `co_company` (
`id` varchar(40) NOT NULL COMMENT 'ID',
`name` varchar(255) NOT NULL COMMENT '公司名称',
`manager_id` varchar(255) NOT NULL COMMENT '企业登录账号ID',
`version` varchar(255) DEFAULT NULL COMMENT '当前版本',
`renewal_date` datetime DEFAULT NULL COMMENT '续期时间',
`expiration_date` datetime DEFAULT NULL COMMENT '到期时间',
`company_area` varchar(255) DEFAULT NULL COMMENT '公司地区',
`company_address` text COMMENT '公司地址',
`business_license_id` varchar(255) DEFAULT NULL COMMENT '营业执照-图片ID',
`legal_representative` varchar(255) DEFAULT NULL COMMENT '法人代表',
`company_phone` varchar(255) DEFAULT NULL COMMENT '公司电话',
`mailbox` varchar(255) DEFAULT NULL COMMENT '邮箱',
`company_size` varchar(255) DEFAULT NULL COMMENT '公司规模',
`industry` varchar(255) DEFAULT NULL COMMENT '所属行业',
`remarks` text COMMENT '备注',
`audit_state` varchar(255) DEFAULT NULL COMMENT '审核状态',
`state` tinyint(2) NOT NULL DEFAULT '1' COMMENT '状态',
`balance` double NOT NULL COMMENT '当前余额',
`create_time` datetime NOT NULL COMMENT '创建时间'
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4;完成企业增删改查操作
持久层(dao)
/**
* 企业数据访问接口
*/
public interface CompanyDao extends JpaRepository, JpaSpecificationExecutor {
} JpaRepository提供了基本的增删改查 JpaSpecificationExecutor用于做复杂的条件查询
骚戴理解:这里dao只需要继承JpaRepository和JpaSpecificationExecutor即可,其中JpaRepository的泛型Company是这个dao的实体类,String是这个实体类id的类型,由于这个实体类设置的id是String类型,所以这个泛型也是String类型
业务逻辑层(service)
@Service
public class CompanyService {
@Autowired
private CompanyDao companyDao;
@Autowired
private IdWorker idWorker;
/**
* 添加企业
*
* @param company 企业信息
*/
public Company add(Company company) {
company.setId(idWorker.nextId() + "");
company.setCreateTime(new Date());
company.setState(1); //启用
company.setAuditState("0"); //待审核
company.setBalance(0d);
return companyDao.save(company);
}
public Company update(Company company) {
return companyDao.save(company);
}
public Company findById(String id) {
return companyDao.findById(id).get();
}
public void deleteById(String id) {
companyDao.deleteById(id);
}
public List findAll() {
return companyDao.findAll();
}
} 骚戴理解:这里直接就是service的实现类,并没有service接口层,我觉得不规范这个代码层次!
控制器
@RestController
@RequestMapping("/company")
public class CompanyController{
@Autowired
private CompanyService companyService;
/**
* 添加企业
*/
@RequestMapping(value = "", method = RequestMethod.POST)
public Result add(@RequestBody Company company) throws Exception {
companyService.add(company);
return Result.SUCCESS();
}
/**
* 根据id更新企业信息
*/
@RequestMapping(value = "/{id}", method = RequestMethod.PUT)
public Result update(@PathVariable(name = "id") String id, @RequestBody Company
company) throws Exception {
Company one = companyService.findById(id);
one.setName(company.getName());
one.setRemarks(company.getRemarks());
one.setState(company.getState());
one.setAuditState(company.getAuditState());
companyService.update(company);
return Result.SUCCESS();
}
/**
* 根据id删除企业信息
*/
@RequestMapping(value = "/{id}", method = RequestMethod.DELETE)
public Result delete(@PathVariable(name = "id") String id) throws Exception {
companyService.deleteById(id);
return Result.SUCCESS();
}
/**
* 根据ID获取公司信息
*/
@RequestMapping(value = "/{id}", method = RequestMethod.GET)
public Result findById(@PathVariable(name = "id") String id) throws Exception {
Company company = companyService.findById(id);
return new Result(ResultCode.SUCCESS);
}
/**
* 获取企业列表
*/
@RequestMapping(value = "", method = RequestMethod.GET)
public Result findAll() throws Exception {
List companyList = companyService.findAll();
return new Result(ResultCode.SUCCESS);
}
} 骚戴理解:add和findAll方法都是没有子路径的,也就是value = "",这里我一开始没看懂,居然还可以为空,那怎么找到这个处理器呢?这里应该是通过后面的请求方式来判断的到底发到哪个处理器的,也就是你发/company这个请求,它就根据你请求类型是get还是post去跳到对应处理器,但是我觉得这样写很不规范!
测试
测试工具postman
Postman提供功能强大的Web API & HTTP 请求调试。软件功能非常强大,界面简洁明晰、操作方便快捷,设计得很人性化,能够发送任何类型的HTTP 请求 (GET, HEAD, POST, PUT..),附带任何数量的参数。
使用资料中提供的postman安装包进行安装,注册成功之后即可使用
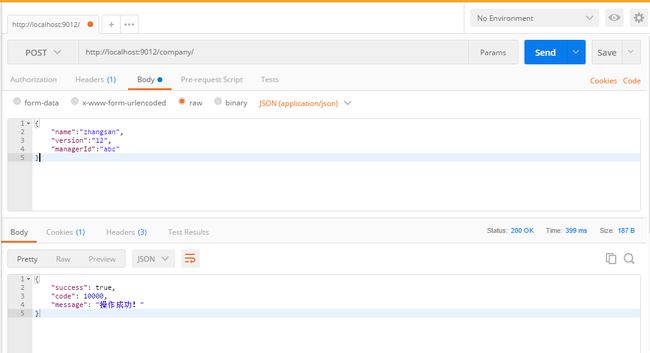
使用postman测试企业接口
公共异常处理
为了使我们的代码更容易维护,同时给用户最好的用户体验,有必要对系统中可能出现的异常进行处理。spring提供了@ControllerAdvice注解和@ExceptionHandler可以很好的在控制层对异常进行统一处理
- 添加自定义的异常
package com.ihrm.common.exception;
import com.ihrm.common.entity.ResultCode;
import lombok.Getter;
@Getter
public class CommonException extends RuntimeException {
private static final long serialVersionUID = 1L;
private ResultCode code = ResultCode.SERVER_ERROR;
public CommonException(){}
public CommonException(ResultCode resultCode) {
super(resultCode.message());
this.code = resultCode;
}
}- 配置公共异常处理
package com.ihrm.common.exception;
import com.alibaba.fastjson.JSON;
import com.ihrm.common.entity.Result;
import org.springframework.http.HttpStatus;
import org.springframework.web.bind.annotation.ControllerAdvice;
import org.springframework.web.bind.annotation.ExceptionHandler;
import org.springframework.web.bind.annotation.ResponseBody;
import javax.servlet.http.HttpServletRequest;
import javax.servlet.http.HttpServletResponse;
import java.io.IOException;
/**
* 全局异常处理
*/
@ControllerAdvice
public class BaseExceptionHandler {
@ResponseBody
@ExceptionHandler(value = Exception.class)
public Result error(HttpServletRequest request, HttpServletResponse response, Exception e) throws IOException {
e.printStackTrace();
if (e.getClass() == CommonException.class) {
CommonException ce = (CommonException) e;
return new Result(ce.getCode());
} else {
return Result.ERROR();
}
}
}跨域处理
跨域是什么?
浏览器从一个域名的网页去请求另一个域名的资源时,域名、端口、协议任一不同,都是跨域 。我们是采用前后端分离开发的,也是前后端分离部署的,必然会存在跨域问题。
怎么解决跨域?
很简单,只需要在controller类上添加注解@CrossOrigin 即可!这个注解其实是CORS的实现。 CORS(Cross-Origin Resource Sharing, 跨源资源共享)是W3C出的一个标准,其思想是使用自定义的HTTP头部让浏览器与服务器进行沟通,从而决定请求或响应是应该成功,还是应该失败。因此,要想实现CORS进行跨域,需要服务器进行一些设置,同时前端也需要做一些配置和分析。