zookeeper安装使用及工作原理分析
1. Zookeeper概念简介
Zookeeper是一个分布式协调服务;就是为用户的分布式应用程序提供协调服务,它是集群的管理者,监视着集群中各个节点的状态,根据节点提交的反馈进行下一步合理操作。
具体介绍:
A、zookeeper是为别的分布式程序服务的;
B、zookeeper本身就是一个分布式程序(只要有半数以上节点存活,zk就能正常服务)
C、zookeeper所提供的服务涵盖:主从协调、服务器节点动态上下线、统一配置管理、分布式共享锁、统一名称服务......
D、虽然说可以提供各种服务,但是zookeeper在底层其实只提供了两个功能:
管理(存储,读取,删除)用户程序提交的数据;
并为用户程序提供数据节点监听服务;
2. Zookeeper集群机制
Zookeeper集群的角色:一个Leader,多个follower。集群中半数以上机器存活,则集群可用。zookeeper适合装在奇数台机器上。
3. Zookeeper工作原理
Zookeeper的核心是原子广播,这个机制保证了各个Server之间的同步。实现这个机制的协议叫做Zab协议。Zab协议有两种模式,它们分别是崩溃恢复模式(选Leader)和消息广播模式(同步)。
当服务启动或者在Leader崩溃后,zk集群进入崩溃恢复模式,当Leader被选举处理,同时集群中已经有过半的机器与该Leader服务器完成状态同步(数据同步),zk集群退出崩溃恢复模式,进入消息广播模式。当新加入一台机器到集群中,如果此时集群已经存在一个Leader服务器在负责进行消息广播,那么新加入的服务器就会自觉地进入数据恢复模式,找到Leader服务器,并与其进行数据同步,然后进入消息广播模式。
Zookeeper在崩溃恢复模式中,通过选举机制产生一个Leader,多个Flollower。而监听机制是zookeeper对于应用最重要的特性。接下来重点介绍选举机制和监听机制。
3.1 zookeeper的选举机制(全新集群paxos)
以一个简单的例子来说明整个选举的过程:
假设有五台服务器组成的zookeeper集群,它们的id从1-5,同时它们都是最新启动的,也就是没有历史数据,在存放数据量这一点上,都是一样的。假设这些服务器依序启动,来看看会发生什么。
1)、服务器1启动,此时只有它一台服务器启动了,它发出去的报没有任何响应,所以它的选举状态一直是LOOKING状态;
2)、服务器2启动,它与最开始启动的服务器1进行通信,互相交换自己的选举结果,由于两者都没有历史数据,所以id值较大的服务器2胜出,但是由于没有达到超过半数以上的服务器都同意选举它(这个例子中的半数以上是3),所以服务器1、2还是继续保持LOOKING状态;
3)、服务器3启动,根据前面的理论分析,服务器3成为服务器1、2、3中的老大,而与上面不同的是,此时有三台服务器选举了它,所以它成为了这次选举的leader;
4)、服务器4启动,根据前面的分析,理论上服务器4应该是服务器1、2、3、4中最大的,但是由于前面已经有半数以上的服务器选举了服务器3,所以它只能接收当小弟的命了;
5)、服务器5启动,同4一样,当小弟。
3.2 非全新集群的选举机制(数据恢复)
那么,初始化的时候,是按照上述的说明进行选举的,但是当zookeeper运行了一段时间之后,有机器down掉,重新选举时,选举过程就相对复杂了。需要加入数据id、leader id和逻辑时钟。
数据id:数据新的id就大,数据每次更新都会更新id。
Leader id:就是我们配置的myid中的值,每个机器一个。
逻辑时钟:这个值从0开始递增,每次选举对应一个值,也就是说: 如果在同一次选举中,那么这个值应该是一致的;逻辑时钟值越大,说明这一次选举leader的进程更新。
选举的标准就变成:
1、逻辑时钟小的选举结果被忽略,重新投票
2、统一逻辑时钟后,数据id大的胜出
3、数据id相同的情况下,leader id大的胜出
根据这个规则选出leader。
3.3 zookeeper的watch机制
一个zk的节点可以被监控,包括这个目录中存储的数据的修改,子节点目录的变化,一旦变化可以通知设置监控的客户端,这个功能是zookeeper对于应用最重要的特性,通过这个特性可以实现的功能包括配置的集中管理、集群管理、分布式锁等等。
watch机制官方说明:一个Watch事件是一个一次性的触发器,当被设置了Watch的数据发生了改变的时候,则服务器将这个改变发送给设置了Watch的客户端,以便通知它们。
zookeeper机制的特点:
1) 一次性的触发器
当数据改变的时候,那么一个Watch事件会产生并且被发送到客户端中。但是客户端只会收到一次这样的通知,如果以后这个数据再次发生改变的时候,之前设置Watch的客户端将不会再次收到改变的通知,因为Watch机制规定了它是一个一次性的触发器。
2)发送给客户端
Watch的通知事件是从服务器发送给客户端的,是异步的,这就表明不同的客户端收到的Watch的时间可能不同,但是ZooKeeper有保证:客户端只有首先看到了监视事件后,才会感知到它所设置监视的znode节点数据发生了变化。例如:A=3,此时在上面设置了一次Watch,如果A突然变成了4,那么客户端会先收到Watch事件的通知,然后才会看到A=4。zookeeper客户端和服务端是通过Socket进行通信的,由于网络延迟或者其他因素可能导致不同的客户端在不同的时刻感知某一监视事件,但是不同的客户端所看到的一切具有一致的顺序。
3)被设置Watch的数据
Zookeeper可以维护两条监视链表:数据监视和子节点监视。
4. Zookeeper特性及数据结构
4.1 Zookeeper特性
① Zookeeper:一个leader,多个follower组成的集群;
② 全局数据一致:每个server保存一份相同的数据副本,client无论连接到哪个server,数据都是一致的;
③ 分布式读写,更新请求转发,由leader实施;
④ 更新请求顺序进行,来自同一个client的更新请求按其发送顺序依次执行;
⑤ 数据更新原子性,一次数据更新要么成功,要么失败;
⑥ 实时性,在一定时间范围内,client能读到最新数据。
4.2 zookeeper 数据结构
1、层次化的目录结构,命名符合常规文件系统规范;
2、每个节点在zookeeper中叫做znode,并且其有一个唯一的路径标识;节点znode可以包含数据和子节点(但是EPHEMERAL类型的节点不能有子节点);
3、客户端应用可以在节点上设置监视器;
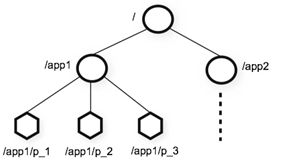
zk的数据结构图
4.3 节点类型
1. Znode有两种类型:
短暂(ephemeral)(断开连接自己删除)
持久(persistent)(断开连接不删除)
2. Znode有四种形式的目录节点(默认是persistent)
PERSISTENT
PERSISTENT_SEQUENTIAL(持久序列/test0000000019)
EPHEMERAL
EPHEMERAL_SEQUENTIAL
3. 创建znode时设置顺序标识,znode名称后会附加一个值,顺序号是一个单调递增的计数器,由父节点维护;
4. 在分布式系统中,顺序号可以被用于为所有的事件进行全局排序,这样客户端可以通过顺序号推断事件的顺序。
5. Zookeeper的shell命令行操作
运行zkCli.sh -server
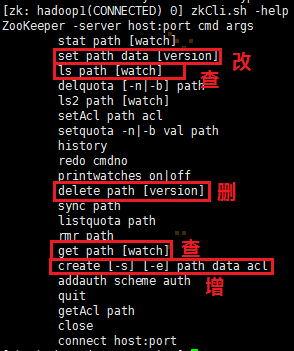
1、使用 ls / 命令来查看当前zookeeper中所包含的内容:
![]()
2、创建一个新的znode,使用create /zk myData。这个命令创建了一个新的znode节点"zk"以及与它关联的字符串:
![]()
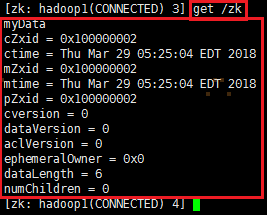
3、我们运行 get /zk 命令来确认znode是否包含我们所创建的字符串:
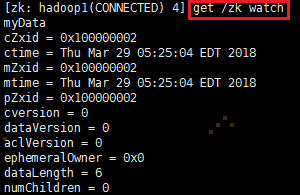
运行命令 get /zk watch 监听这个节点的变化,当另外一个客户端改变/zk时,它会打出下面的

4. 下面我们通过set命令来对zk所关联的字符串进行设置:
![]()
5. 下面我们将刚才创建的znode删除:
![]()
6. 删除节点:rmr
![]()
6.安装Zookeeper
6.1 机器部署
安装到3台虚拟机上,并安装好JDK
6.2 上传、解压重命名zookeeper安装包
使用xftp工具上传zookeeper安装包。
tar -zxvf zookeeper-3.4.5.tar.gz(解压)
mv zookeeper-3.4.5 zookeeper(重命名文件夹zookeeper-3.4.5为zookeeper)
6.3 修改环境变量
1、sudo vi /etc/profile(以root权限修改文件)
2、添加内容:
export ZOOKEEPER_HOME=/home/hadoop/zookeeper
export PATH=$PATH:$ZOOKEEPER_HOME/bin3、重新编译profile文件:
source /etc/profile
注意:安装有3台zookeeper的虚拟机都需要修改
6.4 修改zookeeper配置文件zoo.cfg,创建data、log文件夹以及添加myid文件
1、进入zookeeper文件夹conf目录,复制样例配置文件zoo_sample.cfg并改名
cd /opt/app/zookeeper-3.4.5/conf && cp zoo_sample.cfg zoo.cfg
2、vi zoo.cfg 编辑zoo.cfg文件并添加内容
注意:slave1,slave2,slave3为主机名
dataDir=/home/hadoop/zookeeper/data (存储数据文件夹)
server.1=slave1:2888:3888 (主机名, 心跳端口、数据端口)
server.2=slave2:2888:3888
server.3=slave3:2888:38883、编辑日志输出类型和输出目录
① 在zookeeper文件夹conf目录log4j.properties文件, 编辑log4j日志输出类型,此处设置为日志文件滚动:
cd /opt/app/zookeeper-3.4.5/conf && vi log4j.properties
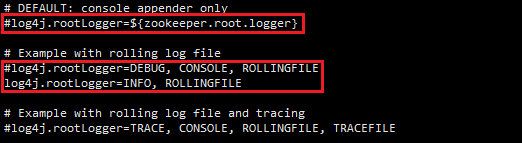
把控制台日志输出注释,把日志输出类型改为log4j.rootLogger=INFO, ROLLINGFILE
注意:在log4j.properties里面配置zookeeper.log.dir不管用

② 在zookeeper文件夹bin目录编辑zkEnv.sh文件,如下:
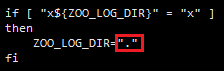
改为
4、创建data、log文件夹
cd /home/hadoop/zookeeper
mkdir -m 755 data
mkdir -m 755 log
5、在data文件夹下新建myid文件,myid的文件内容为:
cd data && vi myid
添加内容:
16.4 将配置好的zookeeper文件夹下发到其他机器上
scp -r /home/hadoop/zookeeper hadoop@slave2:/home/hadoop/
scp -r /home/hadoop/zookeeper hadoop@slave3:/home/hadoop/
6.5 修改其他机器的myid配置文件
到slave2上:修改myid为:2
到slave3上:修改myid为:3
6.6 启动(每台机器)
./zkServer.sh start